Matlab基于灰狼算法改进BP神经网络实现数据预测
Posted Matlab技术工作室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Matlab基于灰狼算法改进BP神经网络实现数据预测相关的知识,希望对你有一定的参考价值。
一、 BP神经网络预测算法简介
说明:1.1节主要是概括和帮助理解考虑影响因素的BP神经网络算法原理,即常规的BP模型训练原理讲解(可根据自身掌握的知识是否跳过)。1.2节开始讲基于历史值影响的BP神经网络预测模型。
使用BP神经网络进行预测时,从考虑的输入指标角度,主要有两类模型:
1.1 受相关指标影响的BP神经网络算法原理
如图一所示,使用MATLAB的newff函数训练BP时,可以看到大部分情况是三层的神经网络(即输入层,隐含层,输出层)。这里帮助理解下神经网络原理:
1)输入层:相当于人的五官,五官获取外部信息,对应神经网络模型input端口接收输入数据的过程。
2)隐含层:对应人的大脑,大脑对五官传递来的数据进行分析和思考,神经网络的隐含层hidden Layer对输入层传来的数据x进行映射,简单理解为一个公式hiddenLayer_output=F(w*x+b)。其中,w、b叫做权重、阈值参数,F()为映射规则,也叫激活函数,hiddenLayer_output是隐含层对于传来的数据映射的输出值。换句话说,隐含层对于输入的影响因素数据x进行了映射,产生了映射值。
3)输出层:可以对应为人的四肢,大脑对五官传来的信息经过思考(隐含层映射)之后,再控制四肢执行动作(向外部作出响应)。类似地,BP神经网络的输出层对hiddenLayer_output再次进行映射,outputLayer_output=w *hiddenLayer_output+b。其中,w、b为权重、阈值参数,outputLayer_output是神经网络输出层的输出值(也叫仿真值、预测值)(理解为,人脑对外的执行动作,比如婴儿拍打桌子)。
4)梯度下降算法:通过计算outputLayer_output和神经网络模型传入的y值之间的偏差,使用算法来相应调整权重和阈值等参数。这个过程,可以理解为婴儿拍打桌子,打偏了,根据偏离的距离远近,来调整身体使得再次挥动的胳膊不断靠近桌子,最终打中。
再举个例子来加深理解:
图一所示BP神经网络,具备输入层、隐含层和输出层。BP是如何通过这三层结构来实现输出层的输出值outputLayer_output,不断逼近给定的y值,从而训练得到一个精准的模型的呢?
从图中串起来的端口,可以想到一个过程:坐地铁,将图一想象为一条地铁线路。王某某坐地铁回家的一天:在input起点站上车,中途经过了很多站(hiddenLayer),然后发现坐过头了(outputLayer对应现在的位置),那么王某某将会根据现在的位置离家(目标Target)的距离(误差Error),返回到中途的地铁站(hiddenLayer)重新坐地铁(误差反向传递,使用梯度下降算法更新w和b),如果王某某又一次发生失误,那么将再次进行这个调整的过程。
从在婴儿拍打桌子和王某某坐地铁的例子中,思考问题:BP的完整训练,需要先传入数据给input,再经过隐含层的映射,输出层得到BP仿真值,根据仿真值与目标值的误差,来调整参数,使得仿真值不断逼近目标值。比如(1)婴儿受到了外界的干扰因素(x),从而作出反应拍桌(predict),大脑不断的调整胳膊位置,控制四肢拍准(y、Target)。(2)王某某上车点(x),过站点(predict),不断返回中途站来调整位置,到家(y、Target)。
在这些环节中,涉及了影响因素数据x,目标值数据y(Target)。根据x,y,使用BP算法来寻求x与y之间存在的规律,实现由x来映射逼近y,这就是BP神经网络算法的作用。再多说一句,上述讲的过程,都是BP模型训练,那么最终得到的模型虽然训练准确,但是找到的规律(bp network)是否准确与可靠呢。于是,我们再给x1到训练好的bp network中,得到相应的BP输出值(预测值)predict1,通过作图,计算Mse,Mape,R方等指标,来对比predict1和y1的接近程度,就可以知道模型是否预测准确。这是BP模型的测试过程,即实现对数据的预测,并且对比实际值检验预测是否准确。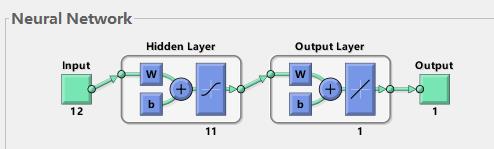
图一 3层BP神经网络结构图
1.2 基于历史值影响的BP神经网络
以电力负荷预测问题为例,进行两种模型的区分。在预测某个时间段内的电力负荷时:
一种做法,是考虑 t 时刻的气候因素指标,比如该时刻的空气湿度x1,温度x2,以及节假日x3等的影响,对 t 时刻的负荷值进行预测。这是前面1.1所说的模型。
另一种做法,是认为电力负荷值的变化,与时间相关,比如认为t-1,t-2,t-3时刻的电力负荷值与t时刻的负荷值有关系,即满足公式y(t)=F(y(t-1),y(t-2),y(t-3))。采用BP神经网络进行训练模型时,则输入到神经网络的影响因素值为历史负荷值y(t-1),y(t-2),y(t-3),特别地,3叫做自回归阶数或者延迟。给到神经网络中的目标输出值为y(t)。
二、灰狼算法
1 前言:
灰狼优化算法(Grey Wolf Optimizer,GWO)由澳大利亚格里菲斯大学学者 Mirjalili 等人于2014年提出来的一种群智能优化算法。该算法受到了灰狼捕食猎物活动的启发而开发的一种优化搜索方法,它具有较强的收敛性能、参数少、易实现等特点。近年来受到了学者的广泛关注,它己被成功地应用到了车间调度、参数优化、图像分类等领域中。
2 算法原理:
灰狼隶属于群居生活的犬科动物,且处于食物链的顶层。灰狼严格遵守着一个社会支配等级关系。如图:
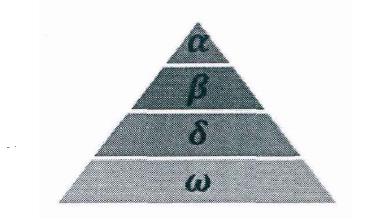
社会等级第一层:狼群中的头狼记为  , 狼主要负责对捕食、栖息、作息时间等活动作出决策。由于其它的狼需要服从 狼的命令,所以 狼也被称为支配狼。另外, 狼不一定是狼群中最强的狼,但就管理能力方面来说, 狼一定是最好的。
, 狼主要负责对捕食、栖息、作息时间等活动作出决策。由于其它的狼需要服从 狼的命令,所以 狼也被称为支配狼。另外, 狼不一定是狼群中最强的狼,但就管理能力方面来说, 狼一定是最好的。
社会等级第二层: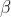 狼,它服从于 狼,并协助 狼作出决策。在 狼去世或衰老后, 狼将成为 狼的最候选者。虽然 狼服从 狼,但 狼可支配其它社会层级上的狼。
狼,它服从于 狼,并协助 狼作出决策。在 狼去世或衰老后, 狼将成为 狼的最候选者。虽然 狼服从 狼,但 狼可支配其它社会层级上的狼。
社会等级第三层: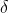 狼,它服从 、 狼,同时支配剩余层级的狼。 狼一般由幼狼、哨兵狼、狩猎狼、老年狼及护理狼组成。
狼,它服从 、 狼,同时支配剩余层级的狼。 狼一般由幼狼、哨兵狼、狩猎狼、老年狼及护理狼组成。
社会等级第四层: 狼,它通常需要服从其它社会层次上的狼。虽然看上去 狼在狼群中的作用不大,但是如果没有 狼的存在,狼群会出现内部问题如自相残杀。
狼,它通常需要服从其它社会层次上的狼。虽然看上去 狼在狼群中的作用不大,但是如果没有 狼的存在,狼群会出现内部问题如自相残杀。
GWO 优化过程包含了灰狼的社会等级分层、跟踪、包围和攻击猎物等步骤,其步骤具体情况如下所示。
1)社会等级分层(Social Hierarchy)当设计 GWO 时,首先需构建灰狼社会等级层次模型。计算种群每个个体的适应度,将狼群中适应度最好的三匹灰狼依次标记为 、 、 ,而剩下的灰狼标记为 。也就是说,灰狼群体中的社会等级从高往低排列依次为; 、 、 及 。GWO 的优化过程主要由每代种群中的最好三个解(即 、 、 )来指导完成。
2)包围猎物( Encircling Prey )灰狼捜索猎物时会逐渐地接近猎物并包围它,该行为的数学模型如下:
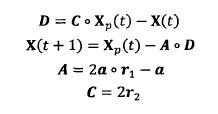
式中:t 为当前迭代次数:。表示 hadamard 乘积操作;A 和 C 是协同系数向量;Xp 表示猎物的位置向量; X(t) 表示当前灰狼的位置向量;在整个迭代过程中 a 由2 线性降到 0; r1 和 r2 是 [0,1] 中的随机向量。
3)狩猎( Hunring)
灰狼具有识别潜在猎物(最优解)位置的能力,搜索过程主要靠 、 、 灰狼的指引来完成。但是很多问题的解空间特征是未知的,灰狼是无法确定猎物(最优解)的精确位置。为了模拟灰狼(候选解)的搜索行为,假设 、 、 具有较强识别潜在猎物位置的能力。因此,在每次迭代过程中,保留当前种群中的最好三只灰狼( 、 、 ),然后根据它们的位置信息来更新其它搜索代理(包括 )的位置。该行为的数学模型可表示如下:
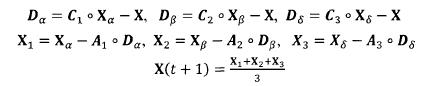
式中: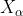 、
、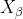 、
、 分别表示当前种群中 、 、 的位置向量;X表示灰狼的位置向量;
分别表示当前种群中 、 、 的位置向量;X表示灰狼的位置向量;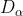 、
、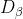 、
、 分别表示当前候选灰狼与最优三条狼之间的距离;当|A|>1时,灰狼之间尽量分散在各区域并搜寻猎物。当|A|<1时,灰狼将集中捜索某个或某些区域的猎物。
分别表示当前候选灰狼与最优三条狼之间的距离;当|A|>1时,灰狼之间尽量分散在各区域并搜寻猎物。当|A|<1时,灰狼将集中捜索某个或某些区域的猎物。
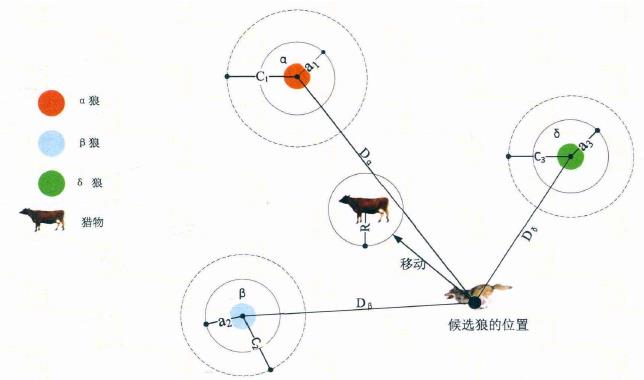
从图中可看出,候选解的位置最终落在被 、 、 定义的随机圆位置内。总的来说, 、 、 需首先预测出猎物(潜 在最优解)的大致位置,然后其它候选狼在当前最优兰只狼的指引下在猎物附近随机地更新它们的位置。
4)攻击猎物(Attacking Prey)构建攻击猎物模型的过程中,根据2)中的公式,a值的减少会引起 A 的值也随之波动。换句话说,A 是一个在区间[-a,a](备注:原作者的第一篇论文里这里是[-2a,2a],后面论文里纠正为[-a,a])上的随机向量,其中a在迭代过程中呈线性下降。当 A 在[-1,1]区间上时,则捜索代理(Search Agent)的下一时刻位置可以在当前灰狼与猎物之间的任何位置上。
5)寻找猎物(Search for Prey)灰狼主要依赖 、 、 的信息来寻找猎物。它们开始分散地去搜索猎物位置信息,然后集中起来攻击猎物。对于分散模型的建立,通过|A|>1使其捜索代理远离猎物,这种搜索方式使 GWO 能进行全局搜索。GWO 算法中的另一个搜索系数是C。从2)中的公式可知,C向量是在区间范围[0,2]上的随机值构成的向量,此系数为猎物提供了随机权重,以便増加(|C|>1)或减少(|C|<1)。这有助于 GWO 在优化过程中展示出随机搜索行为,以避免算法陷入局部最优。值得注意的是,C并不是线性下降的,C在迭代过程中是随机值,该系数有利于算法跳出局部,特别是算法在迭代的后期显得尤为重要。
三、部分代码
% Grey Wolf Optimizer
function [Alpha_score,Alpha_pos,Convergence_curve]=GWO(SearchAgents_no,Max_iter,lb,ub,dim,fobj)
% initialize alpha, beta, and delta_pos
Alpha_pos=zeros(1,dim);
Alpha_score=inf; %change this to -inf for maximization problems
Beta_pos=zeros(1,dim);
Beta_score=inf; %change this to -inf for maximization problems
Delta_pos=zeros(1,dim);
Delta_score=inf; %change this to -inf for maximization problems
%Initialize the positions of search agents
Positions=initialization(SearchAgents_no,dim,ub,lb);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%TRANSFORM HERE BY EQ1%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Convergence_curve=zeros(1,Max_iter);
l=0;% Loop counter
%%%%%%%%%%%%%%%%%%%%%%%%%%%%EVALUAGE J HERE F?RST FOR ALL X? EQ2%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Main loop STEP 3
while l<Max_iter
for i=1:size(Positions,1)
% Return back the search agents that go beyond the boundaries of the search space
Flag4ub=Positions(i,:)>ub;
Flag4lb=Positions(i,:)<lb;
Positions(i,:)=(Positions(i,:).*(~(Flag4ub+Flag4lb)))+ub.*Flag4ub+lb.*Flag4lb;
% Calculate objective function for each search agent
fitness=fobj(Positions(i,:));
% Update Alpha, Beta, and Delta
if fitness<Alpha_score
Alpha_score=fitness; % Update alpha
Alpha_pos=Positions(i,:);
end
if fitness>Alpha_score && fitness<Beta_score
Beta_score=fitness; % Update beta
Beta_pos=Positions(i,:);
end
if fitness>Alpha_score && fitness>Beta_score && fitness<Delta_score
Delta_score=fitness; % Update delta
Delta_pos=Positions(i,:);
end
end
a=2-l*((2)/Max_iter); % a decreases linearly fron 2 to 0
% Update the Position of search agents including omegas
for i=1:size(Positions,1)
for j=1:size(Positions,2)
r1=rand(); % r1 is a random number in [0,1]
r2=rand(); % r2 is a random number in [0,1]
A1=2*a*r1-a; % Equation (3.3)
C1=2*r2; % Equation (3.4)
D_alpha=abs(C1*Alpha_pos(j)-Positions(i,j)); % Equation (3.5)-part 1
X1=Alpha_pos(j)-A1*D_alpha; % Equation (3.6)-part 1
r1=rand();
r2=rand();
A2=2*a*r1-a; % Equation (3.3)
C2=2*r2; % Equation (3.4)
D_beta=abs(C2*Beta_pos(j)-Positions(i,j)); % Equation (3.5)-part 2
X2=Beta_pos(j)-A2*D_beta; % Equation (3.6)-part 2
r1=rand();
r2=rand();
A3=2*a*r1-a; % Equation (3.3)
C3=2*r2; % Equation (3.4)
D_delta=abs(C3*Delta_pos(j)-Positions(i,j)); % Equation (3.5)-part 3
X3=Delta_pos(j)-A3*D_delta; % Equation (3.5)-part 3
Positions(i,j)=(X1+X2+X3)/3;% Equation (3.7)
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%EVALUAGE J HERE F?RST FOR ALL X? EQ2%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
l=l+1;
Convergence_curve(l)=Alpha_score;
end
四、仿真结果

图2灰狼算法收敛曲线
测试统计如下表所示
| 测试结果 | 测试集正确率 | 训练集正确率 |
|---|---|---|
| BP神经网络 | 100% | 95% |
| GWO-BP | 100% | 99.8% |
五、参考文献
《基于BP神经网络的宁夏水资源需求量预测》
》》 喜欢可以关注我

以上是关于Matlab基于灰狼算法改进BP神经网络实现数据预测的主要内容,如果未能解决你的问题,请参考以下文章
BP数据预测基于matlab灰狼算法优化BP神经网络数据预测(多输入多输出)含Matlab源码 2026期
BP数据预测基于matlab灰狼算法优化BP神经网络数据预测(多输入多输出)含Matlab源码 2026期
DELM回归预测基于matlab灰狼算法改进深度学习极限学习机GWO-DELM数据回归预测含Matlab源码 1867期
DELM回归预测基于matlab灰狼算法改进深度学习极限学习机GWO-DELM数据回归预测含Matlab源码 1867期