NLP实战 | 使用《人民的名义》的小说原文训练一个word2vec模型
Posted AI算法攻城狮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP实战 | 使用《人民的名义》的小说原文训练一个word2vec模型相关的知识,希望对你有一定的参考价值。
《人民的名义》的小说原文下载地址
https://github.com/jxq0816/algorithm-model/blob/master/word2vec-gensim/in_the_name_of_people.txt
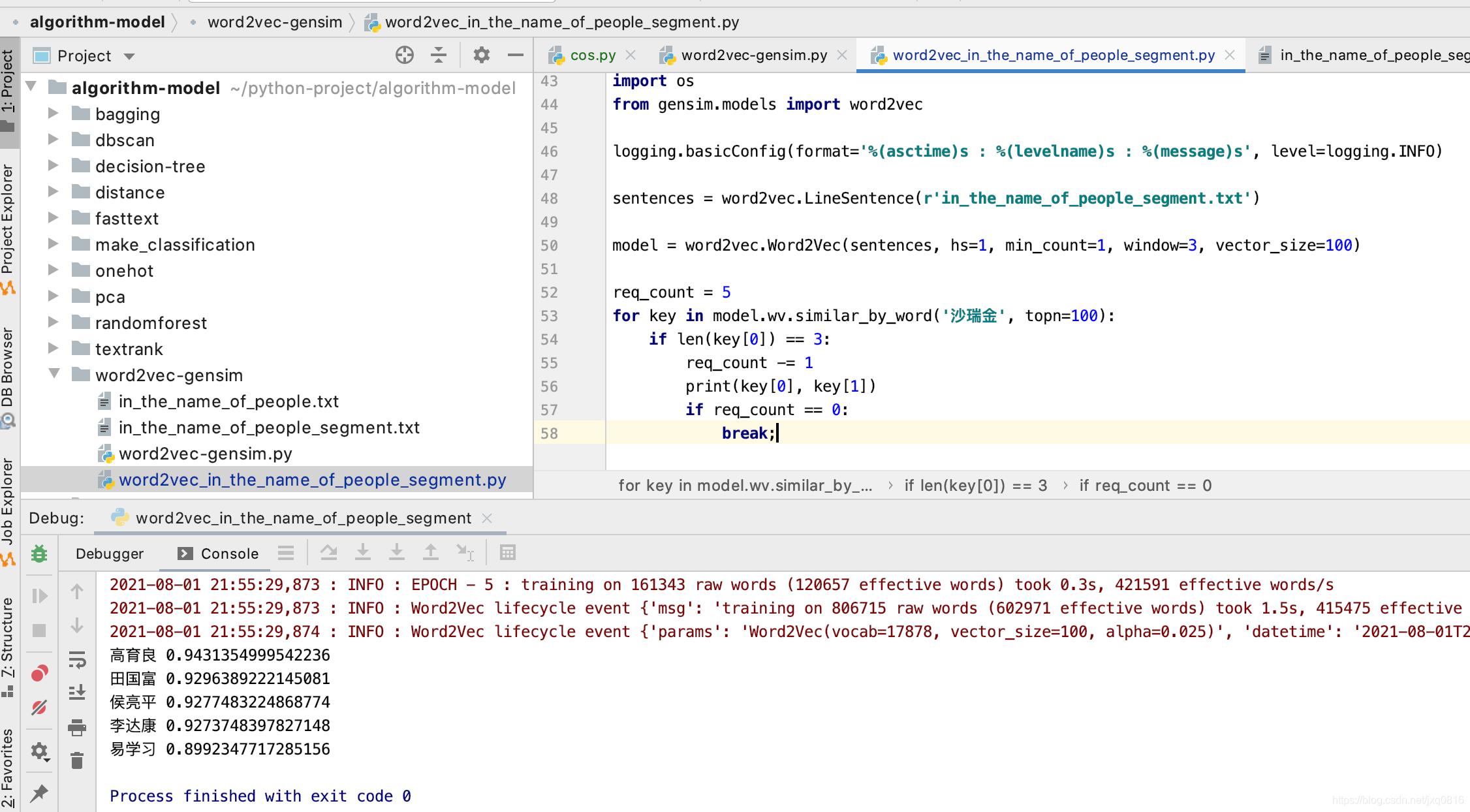
拿到了原文,我们首先要进行分词,这里使用结巴分词完成。这里直接给出分词的代码,分词的结果,我们放到另一个文件中。代码如下, 加入下面的一串人名是为了结巴分词能更准确的把人名分出来。
# encoding = utf-8
import jieba
import jieba.analyse
jieba.suggest_freq(\'沙瑞金\', True)
jieba.suggest_freq(\'田国富\', True)
jieba.suggest_freq(\'高育良\', True)
jieba.suggest_freq(\'侯亮平\', True)
jieba.suggest_freq(\'钟小艾\', True)
jieba.suggest_freq(\'陈岩石\', True)
jieba.suggest_freq(\'欧阳菁\', True)
jieba.su以上是关于NLP实战 | 使用《人民的名义》的小说原文训练一个word2vec模型的主要内容,如果未能解决你的问题,请参考以下文章