评分卡应用 - 利用Toad进行有监督分箱(卡方分箱/决策树分箱)
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了评分卡应用 - 利用Toad进行有监督分箱(卡方分箱/决策树分箱)相关的知识,希望对你有一定的参考价值。
toad是针对工业届建模而开发的工具包,针对风险评分卡的建模有针对性的功能。toad持续更新优化中,本教程针对toad的各类主要功能进行介绍,
包括:
- EDA相关功能
- 如何使用toad高效分箱并进行特征筛选
- WOE转化
- 逐步回归特征筛选
- 模型检验和评判
- 标准评分卡转化和输出
- 其他功能
中文教程:toad使用教程
文章目录
1 Toad — EDA 工具
虽然没有pandas_profiling那么完整,但是已经不错了
用于检测数据情况(EDA)。输出每列特征的统计性特征和其他信息,主要的信息包括:缺失值、unique values、数值变量的平均值、离散值变量的众数。
toad.detect(train)[:10]
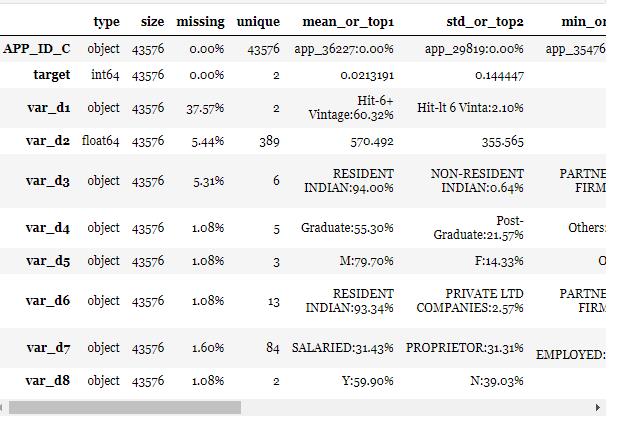
- 正样本占比2.2%:target的mean是0.0219479
- 部分特征有缺失值,且缺失值不等:注意missing列。
- 数值型变量和离散型变量有若干个,部分离散型变量的unique values较多,有10多个甚至84个:离散型变量的unique列。
2 变量的iv值 —— quality
2.1 IV值解读
其中IV值( 参考:二元分类特征的选择:IV值):
IV值衡量了某个特征对目标的影响程度,其基本思想是根据该特征所命中黑白样本的比率与总黑白样本的比率,来对比和计算其关联程度,计算公式如下:

其中Distribution Good(i)表示i分组命中白样本的占比,如果用#good(i)表示i分组命中的样本数,#good(T)表示所有的白样本总量,则 Distribution Good(i) = #good(i) / #good(T)。
当我们计算出特征的IV值后,该如何去解释它的预测能力。
或者说,当IV值取到多大时,我们才选择这个特征。这里给出一个经验参考表:
| IV值 | 预测能力 |
|---|---|
| < 0.02 | 无预测能力 |
| 0.02 ~ 0.1 | 较弱的预测能力 |
| 0.1 ~ 0.3 | 预测能力一般 |
| 0.3 ~0.5 | 较强的预测能力 |
| > 0.5 | 可疑 |
并不是IV值越大越好,当IV值大于0.5时,我们需要对这个特征打个疑问,因为它过于太好而显得不够真实。
通常我们会选择IV值在[0.1-0.5]这个范围的特征。
可能不同场景在取值的细节上会有所不同,比如某些风控团队会将IV值大于0.05的特征也纳入考虑范畴,而学术界则有观点认为选择0.1~0.3这个范围会更好。
2.2 toad.quality
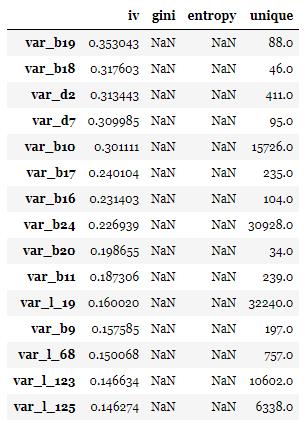
输出每个变量的iv值,gini,entropy,和unique values,结果以iv值排序。
”target”为目标列,
”iv_only”决定是否只输出iv值。
注意:1. 对于数据量大或高维度数据,建议使用iv_only=True 2. 要去掉主键,日期等高unique values且不用于建模的特征
to_drop = ['APP_ID_C','month'] # 去掉ID列和month列
toad.quality(data.drop(to_drop,axis=1),'target',iv_only=True)[:15]
3 如何使用toad高效分箱并进行特征筛选
toad.selection.select(dataframe, target=’target’, empty=0.9, iv=0.02, corr=0.7, return_drop=False, exclude=None):
根据缺失值占比,iv值,和高相关性进行变量筛选,赋值为:
- (1)empyt=0.9: 若变量的缺失值大于0.9被删除
- (2)iv=0.02: 若变量的iv值小于0.02被删除
- (3)corr=0.7: 若两个相关性高于0.7时,iv值低的变量被删除
- (4)return_drop=False: 若为True,function将返回被删去的变量列
- (5)exclude=None: 明确不被删去的列名,输入为list格式
如下面的cell,没有变量由于缺失值高被删除,大量变量因为低iv值被删除,部分相关性高的变量被删除。从165个特征中选出了32个变量。
train_selected, dropped = toad.selection.select(train,target = 'target', empty = 0.5, iv = 0.05, corr = 0.7, return_drop=True, exclude=['APP_ID_C','month'])
print(dropped)
print(train_selected.shape)
4 toad分箱
4.1 卡方分箱
参考:【数据建模 特征分箱】特征分箱的方法
有监督的卡方分箱法(ChiMerge)
自底向上的(即基于合并的)数据离散化方法。
它依赖于卡方检验:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。
对于精确的离散化,相对类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。

4.2 决策树分箱
数据处理实战: Chimerge和决策树分箱
不同于Chimerge的自下而上, 决策树是自顶向下划分的, 但两者都是监督式分箱方法, 即都需要使用到标签变量。由于分箱时使用了类信息, 因此区间的边界更有可能定义在有帮助于提高分类准确率的地方。
4.3 toad调用函数
toad的分箱功能支持数值型数据和离散型分箱,默认分箱方法使用 卡方分箱。
c.fit(dataframe, y = ‘target’, method = ‘chi’, min_samples = None, n_bins = None, empty_separate = False)
- y: 目标列
- method: 分箱方法,支持’chi’ (卡方分箱), ‘dt’ (决策树分箱), ‘kmean’ , ‘quantile’ (等频分箱), ‘step’ (等步长分箱)
- min_samples: 每箱至少包含样本量,可以是数字或者占比
- n_bins: 箱数,若无法分出这么多箱数,则会分出最多的箱数
- empty_separate: 是否将空箱单独分开
一般来说,min_samples / n_bins 需要结合起来使用,可能更能够找到最佳分箱点
其他关联函数:
*查看分箱节点*:c.export()
*手动调整分箱*: c.load(dict)
*apply分箱结果*: c.transform(dataframe, labels=False):
- labels: 是否将分箱结果转化成箱标签。False时输出0,1,2…(离散变量根据占比高低排序),True输出(-inf, 0], (0,10], (10, inf)。
# initialise
c = toad.transform.Combiner()
# 使用特征筛选后的数据进行训练:使用稳定的卡方分箱,规定每箱至少有5%数据, 空值将自动被归到最佳箱。
c.fit(train_selected.drop(to_drop, axis=1), y = 'target', method = 'chi', min_samples = 0.05) #empty_separate = False
# 为了演示,仅展示部分分箱
print('var_d2:',c.export()['var_d2'])
print('var_d5:',c.export()['var_d5'])
print('var_d6:',c.export()['var_d6'])
输出的结果为:
var_d2: [747.0, 782.0, 820.0]
var_d5: [['O', 'nan', 'F'], ['M']]
var_d6: [['PUBLIC LTD COMPANIES', 'NON-RESIDENT INDIAN', 'PRIVATE LTD COMPANIES', 'PARTNERSHIP FIRM', 'nan'], ['RESIDENT INDIAN', 'TRUST', 'TRUST-CLUBS/ASSN/SOC/SEC-25 CO.', 'HINDU UNDIVIDED FAMILY', 'CO-OPERATIVE SOCIETIES', 'LIMITED LIABILITY PARTNERSHIP', 'ASSOCIATION', 'OVERSEAS CITIZEN OF INDIA', 'TRUST-NGO']]
简单来解读一下,
- var_d2是一个连续变量,那么分段就是,[0-747],[747-782],[782-820],[820-inf],就分为四段了
- var_d5是一个分类变量,那么就是分成两类
5 观察分箱并调整
toad.plot的module提供了一部分的可视化功能,帮助调整分箱节点。
toad.plot.bin_plot(dataframe, x = None, target = ‘target)
来看一个示例:
from toad.plot import bin_plot
col = 'sepal length (cm)'
bin_plot(c.transform(iris[[col,'target']], labels=True), x=col, target='target')
这里是单个特征sepal length (cm)跟target的关系:
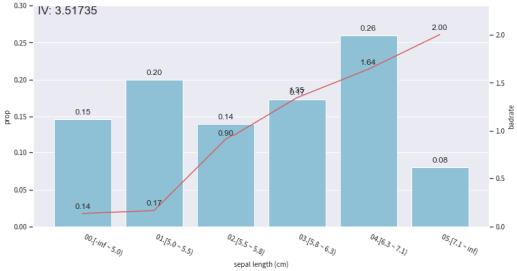
双坐标轴的意义:
- 蓝色bar代表了样本量占比,
- 红线代表了正样本占比(e.g. 坏账率),也就是target的汇总
6 WOE转化
WOE转化在分箱调整好之后进行,步骤如下:
- 用调整好的Combiner转化数据: c.transform(dataframe, labels=False) 只会转化被分箱的变量
- 初始化woe transer: transer = toad.transform.WOETransformer()
- fit_transform: transer.fit_transform(dataframe, target, exclude = None)
- 训练并输出woe转化的数据,用于转化train/时间内数据
- target:目标列数据(非列名)
- exclude: 不需要被WOE转化的列 注意:会转化所有列,包括未被分箱transform的列,通过 ‘exclude’ 删去不要WOE转化的列,特别是target列
- *根据训练好的transer,转化test/OOT数据:*transer.transform(dataframe)
# 初始化
transer = toad.transform.WOETransformer()
# combiner.transform() & transer.fit_transform() 转化训练数据,并去掉target列
train_woe = transer.fit_transform(c.transform(train_selected), train_selected['target'], exclude=to_drop+['target'])
OOT_woe = transer.transform(c.transform(OOT))
print(train_woe.head(3))
7 用gbdt编码,用于gbdt + lr建模的前置
gbdt_transer = toad.transform.GBDTTransformer()
gbdt_transer.fit(final_data[col+['target']], 'target', n_estimators = 10, max_depth = 2)
gbdt_vars = gbdt_transer.transform(final_data[col])
gbdt_vars.shape
>>> (43576, 40)
8 一个完整的code示例
import pandas as pd
import numpy as np
import toad
from sklearn.datasets import load_iris
# 数据载入
iris = load_iris()
target = iris['target']
iris = pd.DataFrame(iris['data'],columns = iris['feature_names'])
iris['target'] = target
# 数据洞察
eda = toad.detect(iris)
qualitys = toad.quality(iris,'target',iv_only=True)
# 分箱
c = toad.transform.Combiner()
# 使用特征筛选后的数据进行训练:使用稳定的卡方分箱,规定每箱至少有5%数据, 空值将自动被归到最佳箱。
c.fit(iris, y = 'target', method = 'chi', min_samples = 0.05) #empty_separate = False
# 为了演示,仅展示部分分箱
c.export()
print('var_d2:',c.export()['var_d2'])
print('var_d5:',c.export()['var_d5'])
print('var_d6:',c.export()['var_d6'])
# 画分箱图
from toad.plot import bin_plot
# 看'var_d2'在时间内的分箱
col = 'sepal length (cm)'
bin_plot(c.transform(iris[[col,'target']], labels=True), x=col, target='target')
# bar代表了样本量占比,红线代表了正样本占比(e.g. 坏账率)
# GBDT + LR的树模型特征输出
col = 'sepal length (cm)'
gbdt_transer = toad.transform.GBDTTransformer()
gbdt_transer.fit(iris, 'target', n_estimators = 10, max_depth = 2)
gbdt_vars = gbdt_transer.transform(iris[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)',
'petal width (cm)']])
iris.shape,gbdt_vars.shape
以上是关于评分卡应用 - 利用Toad进行有监督分箱(卡方分箱/决策树分箱)的主要内容,如果未能解决你的问题,请参考以下文章