游戏开发创新Unity狗屁不通文章生成器阐述点赞的意义,可生成文字长图保存到本地(Unity | 附源码 | Text转Texture长图 | 详细教程)
Posted 林新发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了游戏开发创新Unity狗屁不通文章生成器阐述点赞的意义,可生成文字长图保存到本地(Unity | 附源码 | Text转Texture长图 | 详细教程)相关的知识,希望对你有一定的参考价值。



文章目录
一、前言
嗨,大家好,我是新发。
我在GitHub上看到了一个名字叫BullshitGenerator(狗屁不通文章生成器)的项目,地址:https://github.com/menzi11/BullshitGenerator
有接近1.5k的星星,我下载下来玩了一下,有点意思,不过它是使用Python和javascript写的,嘛,那我来做一个Unity版的吧,顺便把文字生成长图的功能也做一下~
二、流程概览
首先,我们要测试一下BullshitGenerator的功能,看它做了什么;
接着,查看BullshitGenerator的源码,看它是怎么做的;
最后,我们使用Unity来实现,并进行拓展,比如生成文字长图。

三、BullshitGenerator项目测试
1、项目下载
BullshitGenerator项目地址:https://github.com/menzi11/BullshitGenerator
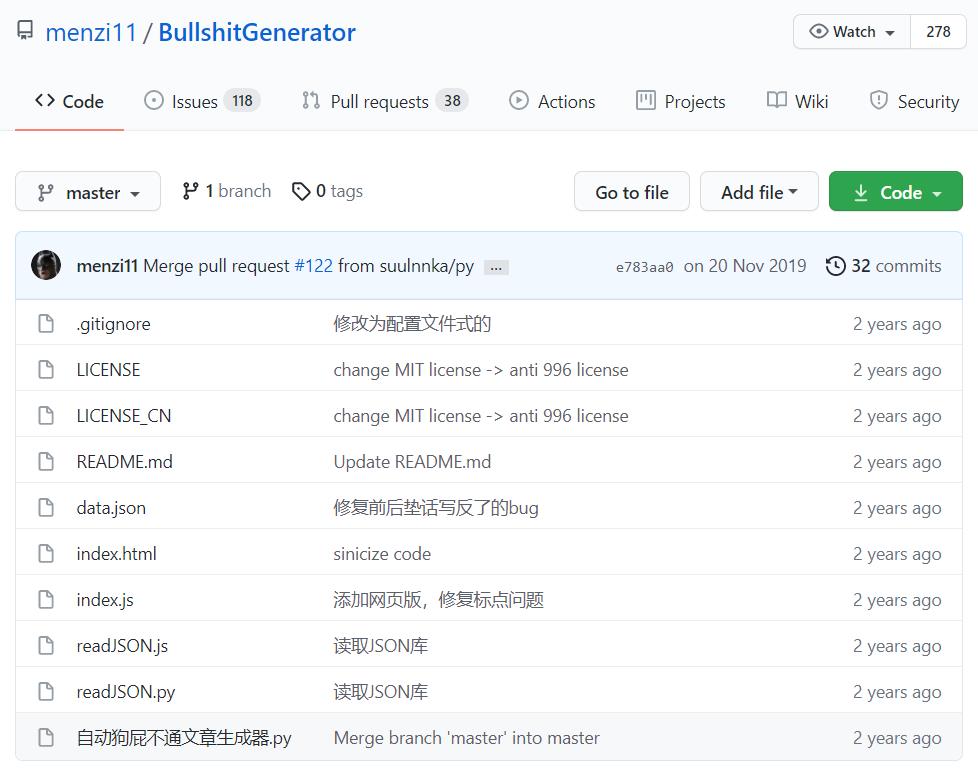
下载下来后,可以看到它提供了两个版本的实现:Python和JavaScript,
2、测试JavaScript版
我们先来玩一下JavaScript版的,使用浏览器打开index.html,
在主题输入框中输入文章主题,点击生成按钮,它就可以生成一篇狗屁不通的文章,

3、测试Python版
现在我们来玩下python版的,使用python执行这个自动狗屁不通文章生成器.py,
输入文章主题,按回车,即可生成一篇狗屁不通的文章,

四、BullshitGenerator源码分析
1、JavaScript版源码分析
我们使用文本编辑器打开index.html,
1.1、定义变量(配置表)
它首先定义了几个列表,其实就是配置表,
注:作者使用
中文做为变量名和函数名,一开始看有点不大习惯~
let 论述 = [
"现在,解决主题的问题,是非常非常重要的。 所以, ",
...
]
let 名人名言 = [
"伏尔泰曾经说过,不经巨大的困难,不会有伟大的事业。这不禁令我深思",
...
]
let 后面垫话 = [
"这不禁令我深思。 ",
...
]
let 前面垫话 = [
"曾经说过",
...
]
接着封装一些必要的函数,我来一一讲解一下~
1.2、随便取一句
使用一个Math.random函数生成一个0~1的随机数,乘以列表长度,再使用Math.floor函数向下取整,得到一个列表的随机索引,最后根据索引从列表中取值。
function 随便取一句(列表){
let 坐标 = Math.floor( Math.random() * 列表.length );
return 列表[坐标];
}
1.3、随便取一个数
从最小值和最大值之间随机取一个数,这个是用来做概率随机的,
function 随便取一个数(最小值 = 0,最大值 = 100){
let 数字 = Math.random()*( 最大值 - 最小值 ) + 最小值;
return 数字;
}
1.4、来点名人名言
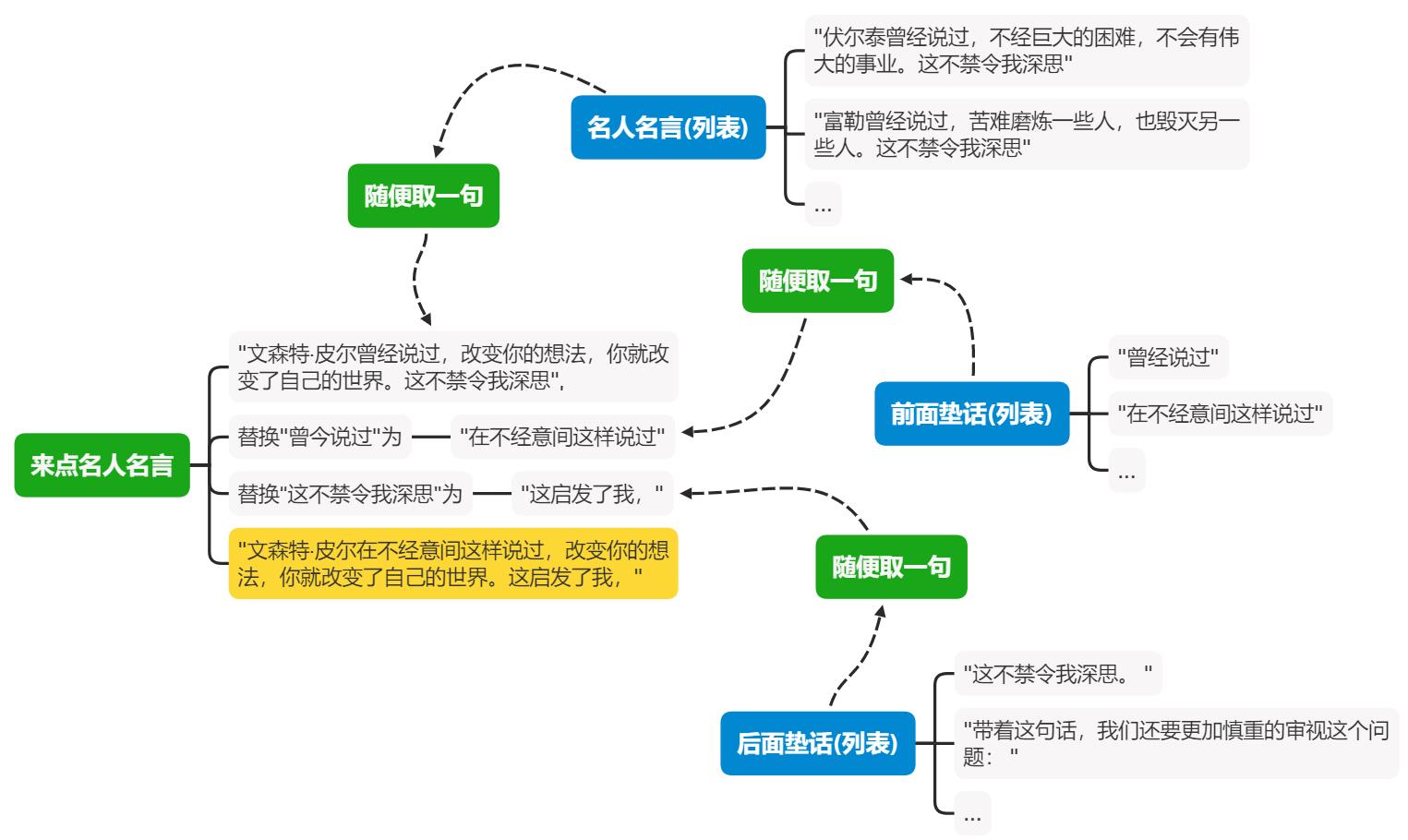
先从名人名言列表中随机取一句,然后把这句话中的关键字“曾经说过”替换为前面垫话列表的随机一句,再把关键字“这不禁令我深思”替换为后面垫话列表的随机一句话,
function 来点名人名言(){
let 名言 = 随便取一句(名人名言)
名言 = 名言.replace("曾经说过", 随便取一句(前面垫话) )
名言 = 名言.replace("这不禁令我深思", 随便取一句(后面垫话) )
return 名言
}
画成图:
1.5、来点论述
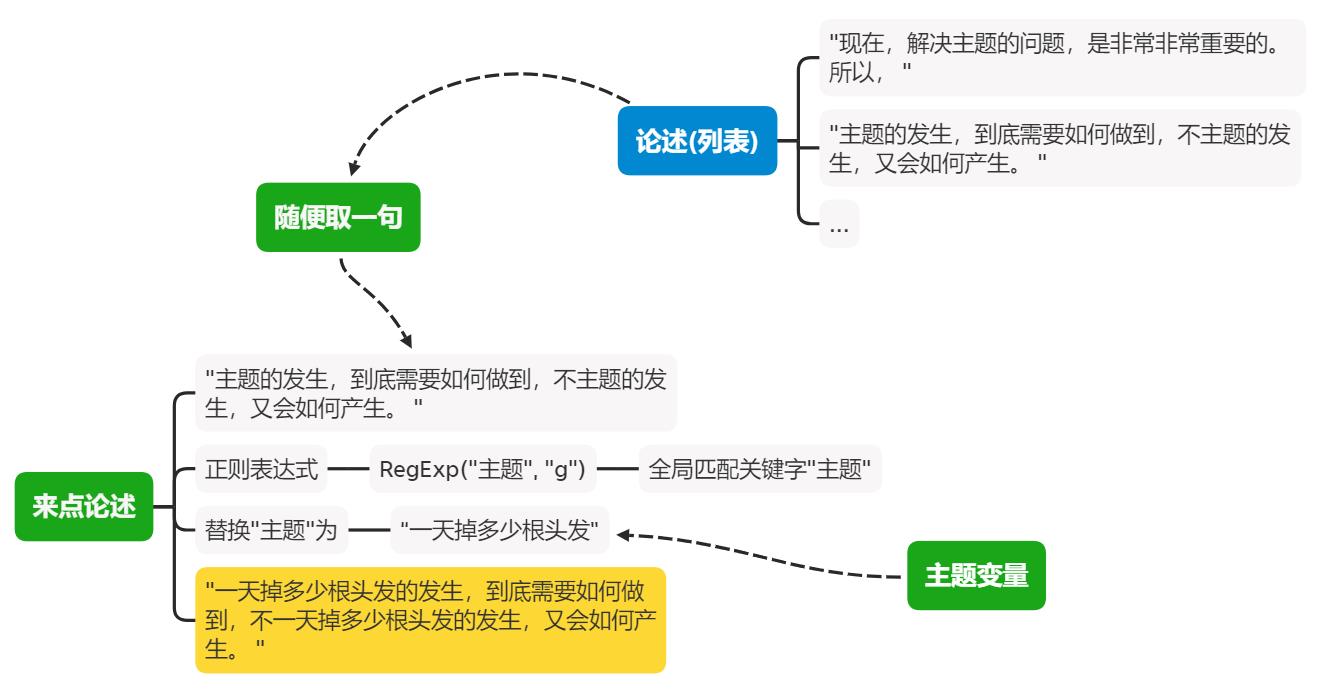
从论述列表中随机取一句,把关键字"主题"替换为我们的主题变量,注意这里用到了正则表达式,RegExp("主题", "g")是一个正则表达式,g表示全局匹配,即把句子中所有的关键字"主题"都进行匹配,比如我们取到一句论述:"主题的发生,到底需要如何做到,不主题的发生,又会如何产生。 ",这句论述中是有两个"主题"关键字的,我们将其替换为我们的主题变量,假设我们的主题变量为:"一天掉多少根头发",那么替换后的句子就是:"一天掉多少根头发的发生,到底需要如何做到,不一天掉多少根头发的发生,又会如何产生。 "。
function 来点论述(){
let 句子 = 随便取一句(论述);
句子 = 句子.replace(RegExp("主题", "g"),主题);
return 句子;
}
画个图:
1.6、增加段落
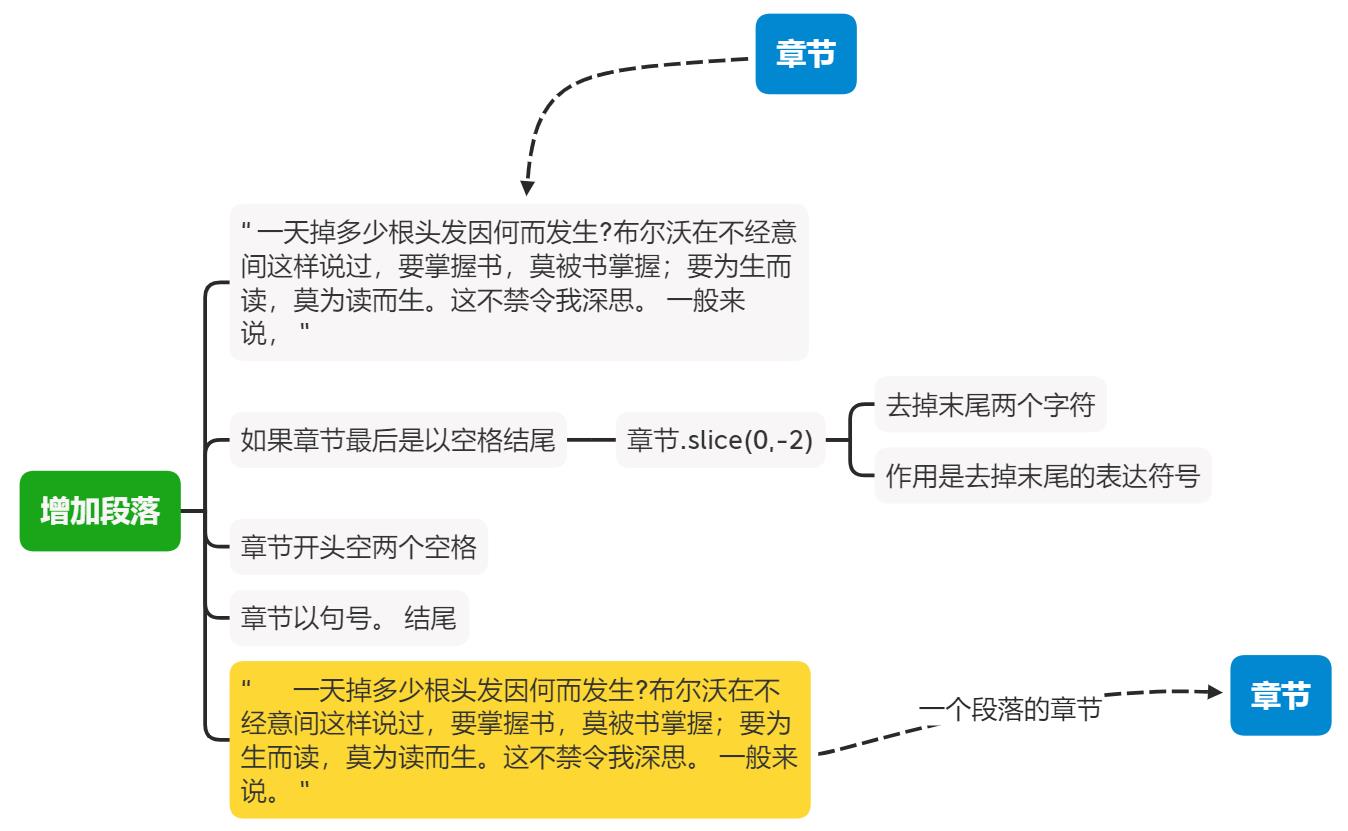
检查当前章节的文本的最后是否是一个空格,如果是,把章节的最后两个字符去掉:章节.slice(0,-2),为什么要这样做呢?因为配置的论述和后面垫话的末尾都是一个标点符号然后留一个空格,比如:"每个人都不得不面对这些问题。 在面对这种问题时, ",如果在以此句作为章节的最后一句,则需要把,(空格)替换为句号。,章节的开头要空两个空格:" " + 章节 + "。 "。
function 增加段落(章节){
if(章节[章节.length-1] === " "){
章节 = 章节.slice(0,-2)
}
return " " + 章节 + "。 "
}
画个图:
1.7、生成文章
获取input的输入作为主体变量,
文章文字长度小于6000字的情况下一直循环执行:
5%的概率且文章字数大于200字时,生成新的章节;
15%的概率随机一句名人名言;
80%的概率随机一句论述;
每个章节都塞入到文章中;
最后显示文章文本到浏览器中。
function 生成文章(){
主题 = $('input').value
let 文章 = []
for(let 空 in 主题){
let 章节 = "";
let 章节长度 = 0;
while( 章节长度 < 6000 ){
let 随机数 = 随便取一个数();
if(随机数 < 5 && 章节.length > 200){
章节 = 增加段落(章节);
文章.push(章节);
章节 = "";
}else if(随机数 < 20){
let 句子 = 来点名人名言();
章节长度 = 章节长度 + 句子.length;
章节 = 章节 + 句子;
}else{
let 句子 = 来点论述();
章节长度 = 章节长度 + 句子.length;
章节 = 章节 + 句子;
}
}
章节 = 增加段落(章节);
文章.push(章节);
}
let 排版 = "<div>" + 文章.join("</div><div>") + "</div>";
$("#论文").innerHTML = 排版;
}
画个图:

到这里,JavaScript的源码我们就分析完了,其实整个逻辑很直接,不饶弯子,相信大家看一看就能看懂。下面我们再来看看Python版的源码吧~
2、Python版源码分析
我们使用文本编辑器打开自动狗屁不通文章生成器.py。
2.1、读取配置
可以看到,开头是使用readJSON模块来读取data.json配置,存到变量中,
import os, re
import random,readJSON
data = readJSON.读JSON文件("data.json")
名人名言 = data["famous"] # a 代表前面垫话,b代表后面垫话
前面垫话 = data["before"] # 在名人名言前面弄点废话
后面垫话 = data['after'] # 在名人名言后面弄点废话
废话 = data['bosh'] # 代表文章主要废话来源
我们可以打开data.json看看,
格式是这样的:
{
"title":"主题",
"famous":[
"爱迪生a,天才是百分之一的勤奋加百分之九十九的汗水。b",
"查尔斯·史a,一个人几乎可以在任何他怀有无限热忱的事情上成功。b",
...
],
"bosh":[
"现在,解决x的问题,是非常非常重要的。所以,",
"我们不得不面对一个非常尴尬的事实,那就是,",
...
],
"before":[
"这不禁令我深思。",
"带着这句话,我们还要更加慎重的审视这个问题:",
...
],
"after":[
"曾经说过",
"在不经意间这样说过",
...
],
}
我们再看回readJSON.py脚本,只有一个函数,就是先判断一下配置文件是不是.json结尾的,然后open配置文件,把文件内容read进来,最后json.loads把配置的文本(json格式的字符串)转为python的字典并return,
def 读JSON文件(fileName=""):
import json
if fileName!='':
strList = fileName.split(".")
if strList[len(strList)-1].lower() == "json":
with open(fileName,mode='r',encoding="utf-8") as file:
return json.loads(file.read())
画个图:

2.2、对废话和名人名言进行洗牌
定义一个洗牌方法,然后对废话和名人名言进行洗牌,并返回迭代器,方便后续使用迭代器进行next操作,
重复度 = 2
def 洗牌遍历(列表):
global 重复度
池 = list(列表) * 重复度
while True:
random.shuffle(池)
for 元素 in 池:
yield 元素
下一句废话 = 洗牌遍历(废话)
下一句名人名言 = 洗牌遍历(名人名言)
注意,上面首先是把列表进行了2次重复,再进行洗牌。
例:
a = [1,2,3]
b = list(a) * 2
print(b)
# 输出[1, 2, 3, 1, 2, 3]
另外,上面用到了random.shuffle函数,它是将序列的所有元素随机排序(即洗牌)。
2.3、来点名人名言
使用next取出迭代器的下一个项,即下一句名人名言,然后对名言中的关键字"a"和"b"做替换:
"a"替换为随机一句前面垫话;
"b"替换为随机一句后面垫话;
def 来点名人名言():
global 下一句名人名言
xx = next(下一句名人名言)
xx = xx.replace("a", random.choice(前面垫话))
xx = xx.replace("b", random.choice(后面垫话))
return xx
注意,data.json配置表中的名人名(famous)言格式为:
"名人a,名言。b",
例:
"爱迪生a,天才是百分之一的勤奋加百分之九十九的汗水。b",
"查尔斯·史a,一个人几乎可以在任何他怀有无限热忱的事情上成功。b",
"培根说过,深窥自己的心,而后发觉一切的奇迹在你自己。b",
...
2.4、另起一段
另起一段就是给文章追加句号.,换行"\\r\\n",新段落开头空四个空格,
def 另起一段():
xx = ". "
xx += "\\r\\n"
xx += " "
return xx
2.5、main入口:生成文章
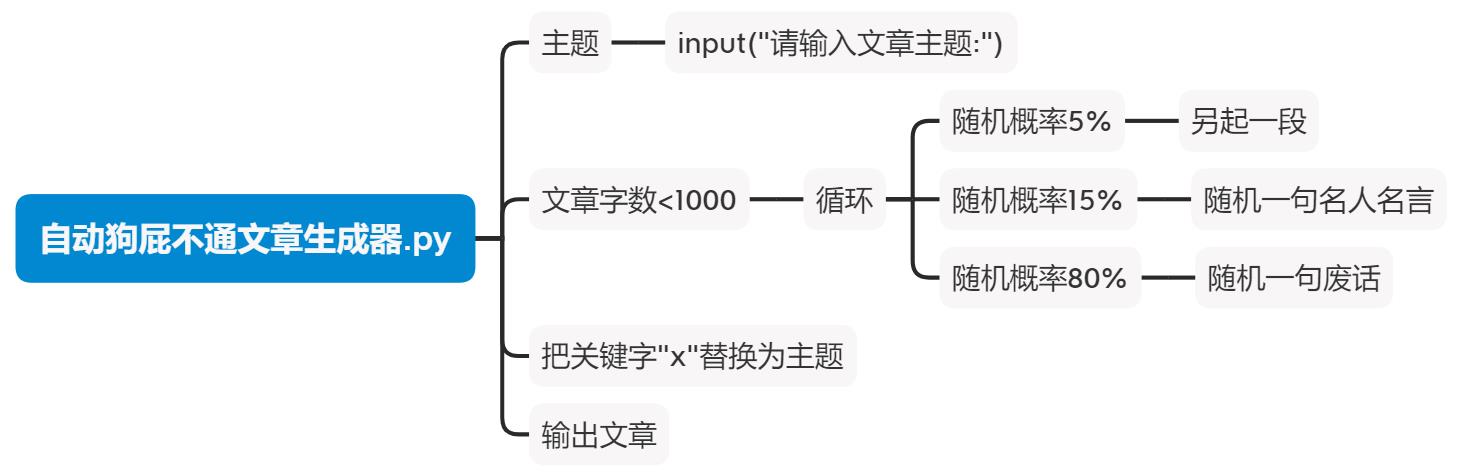
提示输入文章主题,当文章字数小于1000字时循环执行:5%的概率另起一段,15%的概率随机一句名人名言,80%的概率随机一句废话。
最后替换关键字"x"为主题,输出文章内容。
if __name__ == "__main__":
xx = input("请输入文章主题:")
for x in xx:
tmp = str()
while ( len(tmp) < 1000 ) :
分支 = random.randint(0,100)
if 分支 < 5:
tmp += 另起一段()
elif 分支 < 20 :
tmp += 来点名人名言()
else:
tmp += next(下一句废话)
tmp = tmp.replace("x",xx)
print(tmp)
画个图:
五、界面设计
好了,现在我们开始动手制作Unity版本的狗屁不通文章生成器吧~
我们先使用axure快速原型设计工具先简单设计一下界面,
六、UI素材获取
简单的UI素材资源我是在阿里巴巴矢量图库上找,地址:https://www.iconfont.cn/
比如搜索按钮,
找一个形状合适的,可以进行调色,我一般是调成白色,
因为Unity中可以设置Color,这样我们只需要一个白色按钮就可以在Unity中创建不同颜色的按钮了。
弄点基础的美术资源,
七、创建Unity工程
创建一个2D模板的Unity工程,工程名我定为UnityBullshitGenerator,如下:
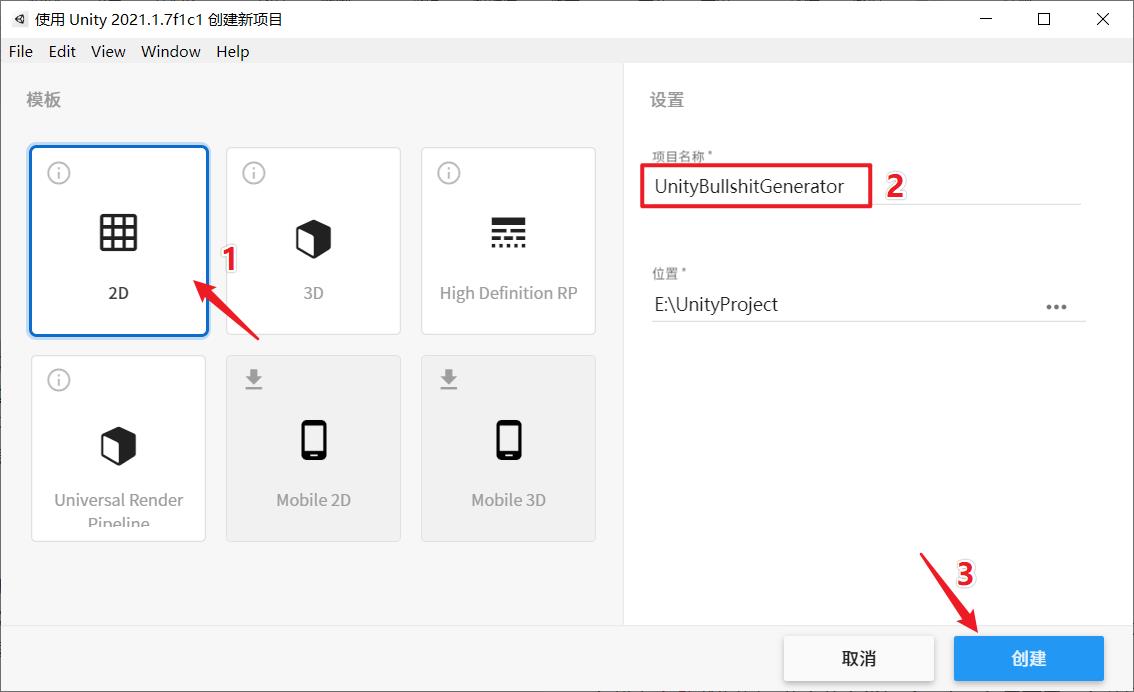
我想做成竖版的,Game视图分辨率设置为720*1280,
八、制作界面预设:MainPanel.prefab
把上面我们获取的UI素材导入到Unity工程中,放在Assets / Textures目录中,如下:

注意图片类型设置为Sprite (2D and UI),

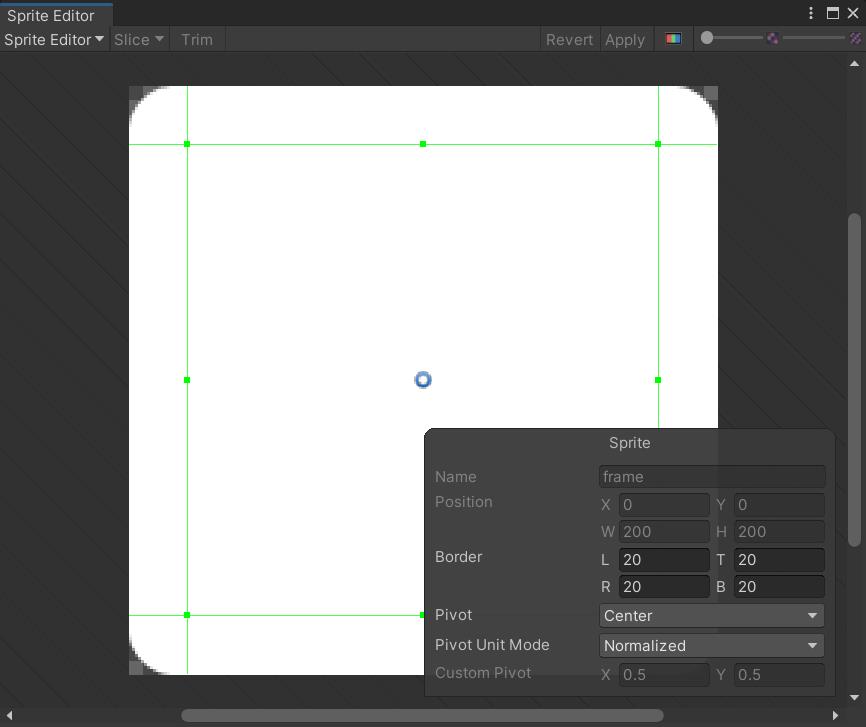
对部分特定的UI素材使用Sprite Editor进行九宫格切割,
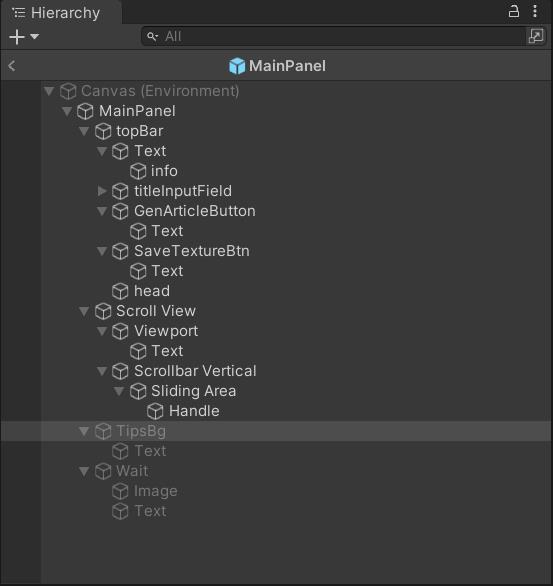
接着,使用UGUI制作界面预设:MainPanel.prefab,保存到Assets /Prefabs目录中,

预设节点结构如下:
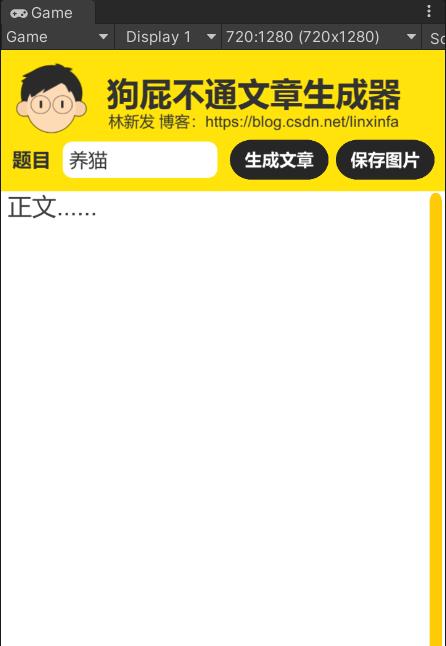
预设显示如下:
九、配置表:data.json
创建data.json,内容格式如下,可自行往配置中添加句子(注意有些句子是带可替换的字符的,比如a、b、x)
{
"title":"主题",
"famous":[
"爱迪生a,天才是百分之一的勤奋加百分之九十九的汗水。b",
"查尔斯·史a,一个人几乎可以在任何他怀有无限热忱的事情上成功。b",
...
],
"bosh":[
"现在,解决x的问题,是非常非常重要的。所以,",
"我们不得不面对一个非常尴尬的事实,那就是,",
...
],
"before":[
"这不禁令我深思。",
"带着这句话,我们还要更加慎重的审视这个问题:",
...
],
"after":[
"曾经说过",
"在不经意间这样说过",
...
],
}
将data.json保存到Unity工程的Assets/Resources目录中:
十、程序代码
程序部分,分为Logic和View,Logic实现逻辑,View实现界面交互。

BullshitGenerator.cs和MainPanel.cs都很好写,难点是Utils.cs:文字如何转Texture2D(文字长图)。不要怕,稍作研究就可以做出来滴,我们先把简单的做了~
1、BullshitGenerator.cs脚本
在Assets / Scripts / Logic目录中创建BullshitGenerator.cs脚本,
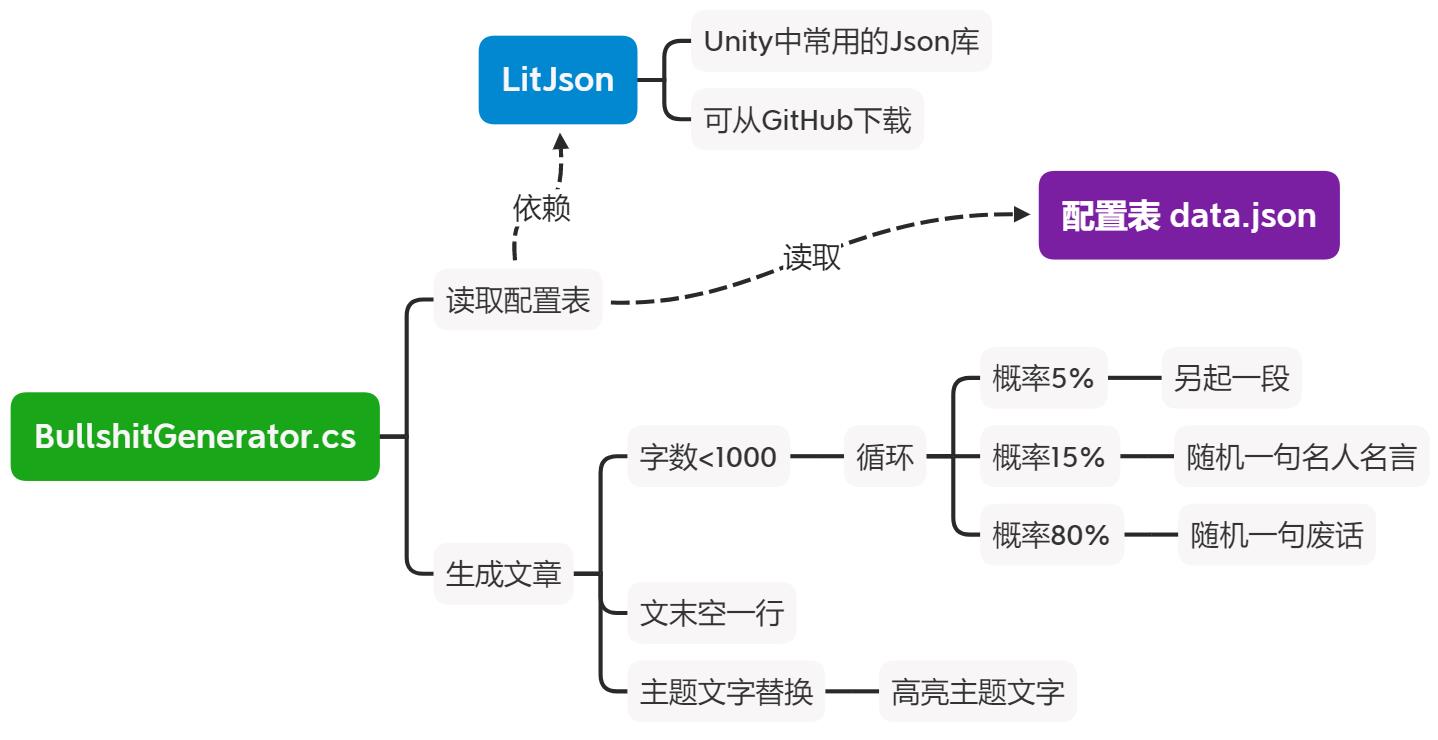
BullshitGenerator.cs脚本要具体做什么呢?首先画一下思维导图:
1.1、使用LitJson解析配置
我们要解析json格式的配置表,需要使用Json库,我推荐使用LitJson开源库,可以从GitHub上下载,LitJson开源项目地址:https://hub.fastgit.org/LitJSON/litjson
我们下载下来后,把src目录中的LitJson文件夹整个拷贝到我们Unity工程中,如下:
接着我们就可以在代码中使用LitJson了,使用时引用命名空间
using LitJson;
我们先定义一些容器,用于存放配置表的内容,
// BullshitGenerator.cs
/// <summary>
/// 名人名言
/// </summary>
private List<string> m_famous = new List<string>();
/// <summary>
/// 废话
/// </summary>
private List<string> m_bosh = new List<string>();
/// <summary>
/// 前面垫话
/// </summary>
private List<string> m_after = new List<string>();
/// <summary>
/// 后面垫话
/// </summary>
private List<string> m_before = new List<string>();
封装一个LoadCfg方法,实现配置表读取的逻辑,
// BullshitGenerator.cs
/// <summary>
/// 读取配置表
/// </summary>
public void LoadCfg()
{
// 读取配置文件(json格式的字符串)
var jsonText = Resources.Load<TextAsset>("data").text;
// 转为JsonData
var jd = JsonMapper.ToObject(jsonText);
// 名人名言
m_famous = JsonMapper.ToObject<List<string>>(jd["famous"].ToJson());
// 废话
m_bosh = JsonMapper.ToObject<List<string>>(jd["bosh"].ToJson());
// 前垫话
m_before = JsonMapper.ToObject<List<string>>(jd["before"].ToJson());
// 后垫话
m_after = JsonMapper.ToObject<List<string>>(jd["after"].ToJson());
}
1.2、List洗牌
为了让名人名言
以上是关于游戏开发创新Unity狗屁不通文章生成器阐述点赞的意义,可生成文字长图保存到本地(Unity | 附源码 | Text转Texture长图 | 详细教程)的主要内容,如果未能解决你的问题,请参考以下文章