谷歌大脑拿着2015年的扩散模型称霸图像合成,评分接近完美
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谷歌大脑拿着2015年的扩散模型称霸图像合成,评分接近完美相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :新智元
自然图像合成(Natural Image Synthesis)是一类应用广泛的机器学习任务,但在不同的应用场景中都存在多种多样的设计难点。
一个典型的应用场景是图像超分辨率,根据低分辨率图像和高分辨率图像训练模型可以还原低分辨率图像。超分辨率有许多应用,可以恢复旧的家庭肖像,改善医疗成像系统。另一个图像合成任务是类条件图像生成,该任务通过训练模型从输入类标签生成样本图像。生成的样本图像可用于提高下游模型的图像分类、图像分割等任务的性能。

一般来说,这些图像合成任务是由深度生成模型来完成的,利如 GANs(对抗生成网络)、 VAEs (变分自编码器)和自回归模型。
但这些生成式模型在困难的、高分辨率的数据集上合成高质量的样本时,都有不同的缺陷。例如,GANs经常在训练过程中不稳定收敛或产生模式崩溃现象,而自回归模型的合成速度通常很慢。
鉴于其他模型有各种各样的缺点,最初在2015年提出的扩散模型(diffusion models)又重新回到了科研人员的视野之中。扩散模型训练稳定,并且在图像和音频生成上,都有不错的生成质量。与其他类型的深层生成模型相比,扩散模型也存在缺点,但它的优点更让人心动。
扩散模型通过逐步加入高斯噪声来强化训练数据的多样性,逐渐消除数据中的细节直到它变成纯粹的噪声,然后训练一个神经网络来逆转这个加入噪声的过程,运行这个反向的加入噪声过程合成数据从纯噪声逐渐去噪,直到能够生成一个干净的样本。这个合成过程可以解释为一个优化算法,沿着数据密度的梯度下降产生相似的样本。
Google Brain 提出了两种扩散模型图像合成质量的拓展方法ーー基于重复细化的超分辨率模型SR3 (Super-Resolution via Repeated Refinements)和基于类条件的级联扩散模型CDM (Cascaded Diffusion Models)。
结果表明,通过放大(scale up)扩散模型和精心选择的数据增强技术,可以显著超越现有的方法。具体而言,SR3获得了健壮的图像超分辨率结果,在人类评估中超过了 GANs。CDM 生成的高保真 ImageNet 样本在 FID 分数和分类精度分数上均大大超过 biggandeep 和 VQ-VAE2。
SR3是一种超分辨率扩散模型,它的输入是一张低分辨率图像,从纯噪声中构建相应的高分辨率图像。该模型训练的图像损坏的过程中,噪声逐步加入到一个高分辨率的图像,直到只剩下纯噪声。训练结束后,模型已经学会从纯噪声开始逐步消除噪声,最后通过输入低分辨率图像来达到生成高分辨率图像的目的。

通过大规模的训练,SR3在缩放低分辨率图像的4x-8x 分辨率时,对人脸图像和自然图像的超分辨率任务取得了较好的基准结果。这些超分辨率模型可以进一步叠加在一起,以提高有效的超分辨率比例因子,例如,叠加一个64x64→256x256和一个256x256→1024x1024人脸超分辨率模型,以完成一个64x64→1024x1024的超分辨率任务。
研究人员比较了 SR3与现有的方法,使用人工评价究的方法进行了一个两种选择的强迫选择实验(Two-Alternative Forced Choice Experiment, 2AFC),当被问到“你猜哪张图片是来自相机的?”时,被试被要求在参考高分辨率图片和模型输出之间做出选择。通过混淆率来衡量模型的性能(评分者选择模型输出而不是参考图像,完美的算法可以达到50% 的混淆率)。
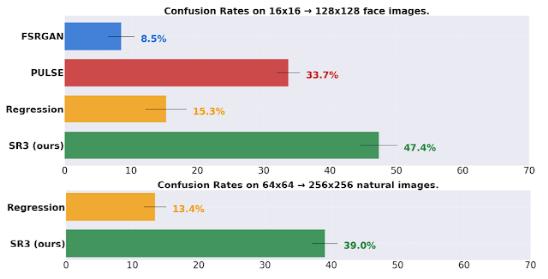
双选择强迫选择(Two-alternative forced choice,2AFC)是一种测量人、儿童或婴儿或动物对某种特定感官输入刺激的敏感性的方法,通过观察者对两种感官输入的选择模式和响应时间。例如,为了确定一个人对暗光的敏感程度,观察者将接受一系列实验,其中暗光随机地出现在显示器的顶部或底部。每次试验结束后,观察者都会回答“最高”或“最低”。不允许观察者说“我不知道”,或者“我不确定”,或者“我什么都没看见”。在这个意义上,观察者的选择是被迫在两个选择之间。
CDM 是一种基于 ImageNet 数据训练的类别条件(class-conditional)扩散模型,用于生成高分辨率的自然图像。由于 ImageNet 是一个困难的、高熵的数据集,所以研究人员将 CDM 建成了一系列的多扩散模型。这种级联方法涉及在几种空间分辨率上将多种生成模型连接在一起: 一种生成低分辨率数据的扩散模型,然后是一系列 SR3超分辨率扩散模型,这些扩散模型逐渐将生成的图像的分辨率提高到最高分辨率。
如SR3模型中所述,级联可以提高高分辨率数据的质量和训练速度,CDM进一步强调了扩散模型中的级联效应对于样品质量和下游任务的有效性。

在将 SR3模型引入到级联流水线中的同时,还引入了一种新的数据增强技术,即条件增强技术,进一步提高了 CDM 的样本质量结果。
虽然CDM中的超分辨率模型是根据数据集中的原始图像进行训练的,但在生成过程中,它们需要对低分辨率基础模型生成的图像进行超分辨率训练,这种模型与原始图像相比可能质量不够高。这将导致超分辨率模型的训练测试分布不匹配。
条件增强是指对级联流水线中每个超分辨率模型的低分辨率输入图像进行数据增强。这些增强包括高斯噪声和高斯模糊,防止每个超分辨率模型过度拟合其低分辨率条件输入,最终生成更好的CDM更高的分辨率样本质量。

在有类别条件 ImageNet 生成方面,CDM 生成的高保真样本在 FID 评分和分类准确率方面均优于 BigGAN-deep 和 VQ-VAE-2。CDM是一个纯粹的生成模型,不借助分类器来提高样本质量。
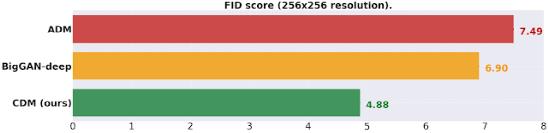
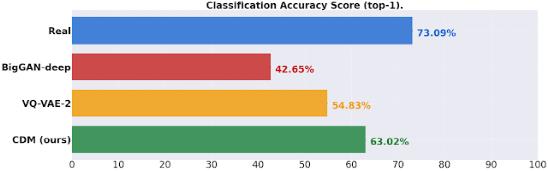
通过 SR3和 CDM,Google Brain的研究人员已经将扩散模型的性能推向了超分辨率和类条件 ImageNet 生成基准的最新水平。
参考资料:https://ai.googleblog.com/2021/07/high-fidelity-image-generation-using.html?m=1
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于谷歌大脑拿着2015年的扩散模型称霸图像合成,评分接近完美的主要内容,如果未能解决你的问题,请参考以下文章