LabVIEW目标对象分类识别
Posted 不脱发的程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LabVIEW目标对象分类识别相关的知识,希望对你有一定的参考价值。
目录
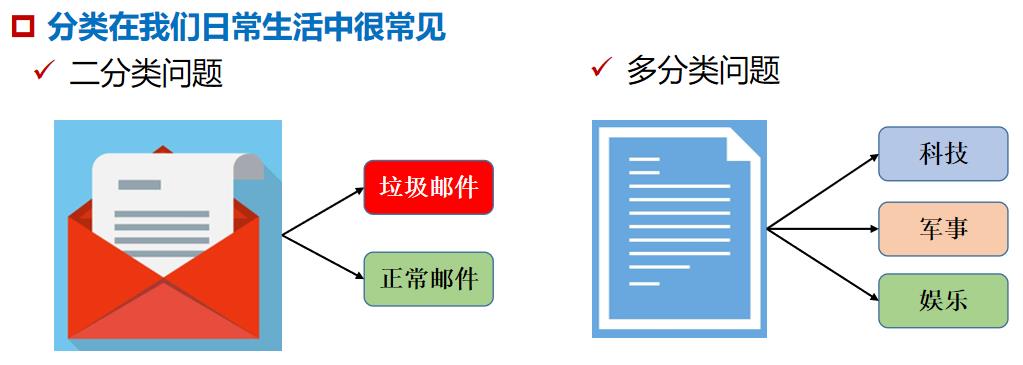
目标对象分类是指将未知样品的形状、颜色、纹理等显著特征组成的向量与代表某一类样本的特征向量(Feature Vector)进行比较,根据其匹配程度识别未知样品类别归属的过程。
目标对象分类是机器视觉领域非常活跃的研究方向,在工业领域有极其广泛的应用,例如对生产线上的零件按形状、颜色等特征分拣,统计具有某种特征的零件,或通过辨别目标的类别进行质量检测等。
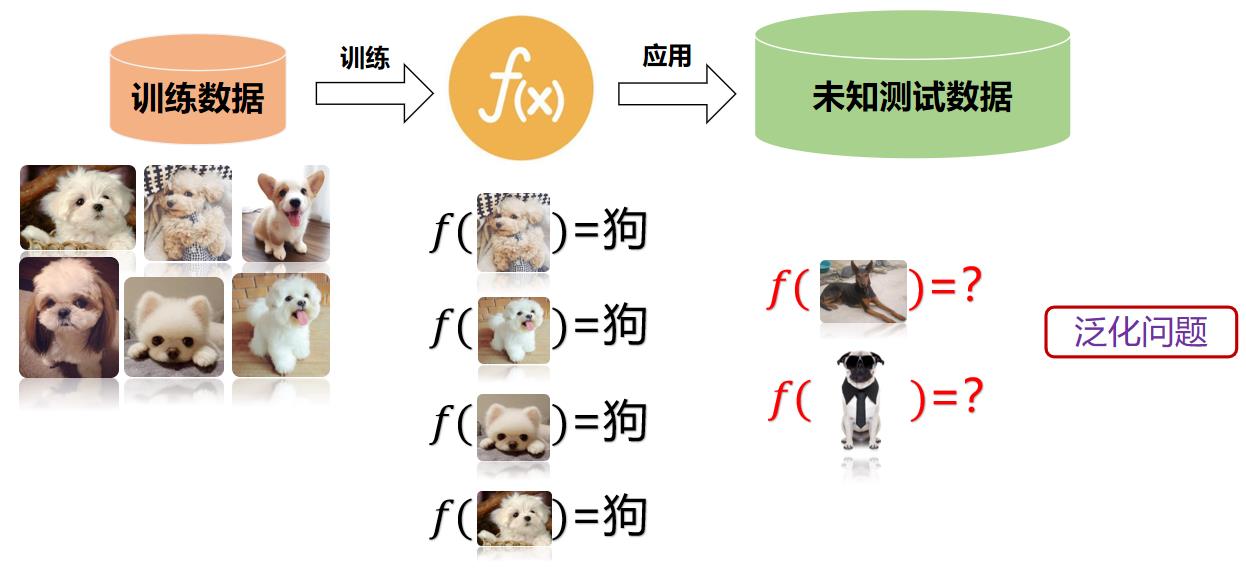
目标分类通常包括训练(Training,也称为学习)和分类(Classification)两个过程。
- 训练过程用于创建分类器(Classifier),包括样本收集、分类器配置(确定特征向量和设置控制参数)、样本训练、分类器评测和保存等步骤,它既可以基于已有样本集合(Sample Set)一次性完成,也可以通过不断向样本集添加样本来渐进完成。训练过程完成后会得到包含各样本特征向量值及其类别归属信息的分类器。一般来说,样本集中属于同一类别的样本应具有相似的特征向量值,而类间距则应足够大。
- 分类过程包括图像预处理、特征提取、特征计算、特征分类及分类结果评测等步骤。分类结束后,未知类别的样本被设置某一类别标记。
下图分别显示了训练和分类两个阶段的流程图:
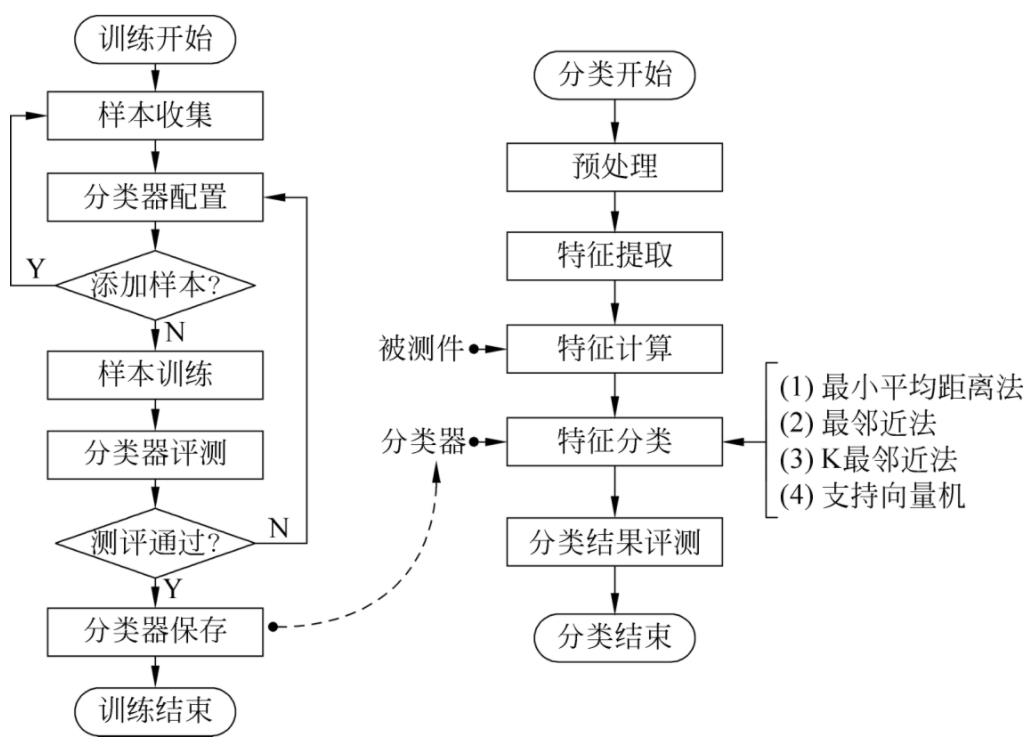
1、训练过程(创建分类器)
训练是目标分类的两个过程之一,它主要用于生成包含各个样本特征向量值及其类别归属信息的分类器。分类器基于事先收集的训练样本集来创建,其中每个样本的类别归属已知。样本集确定后,就要对分类器进行配置,以确定训练过程所依据的特征向量并设置控制参数。
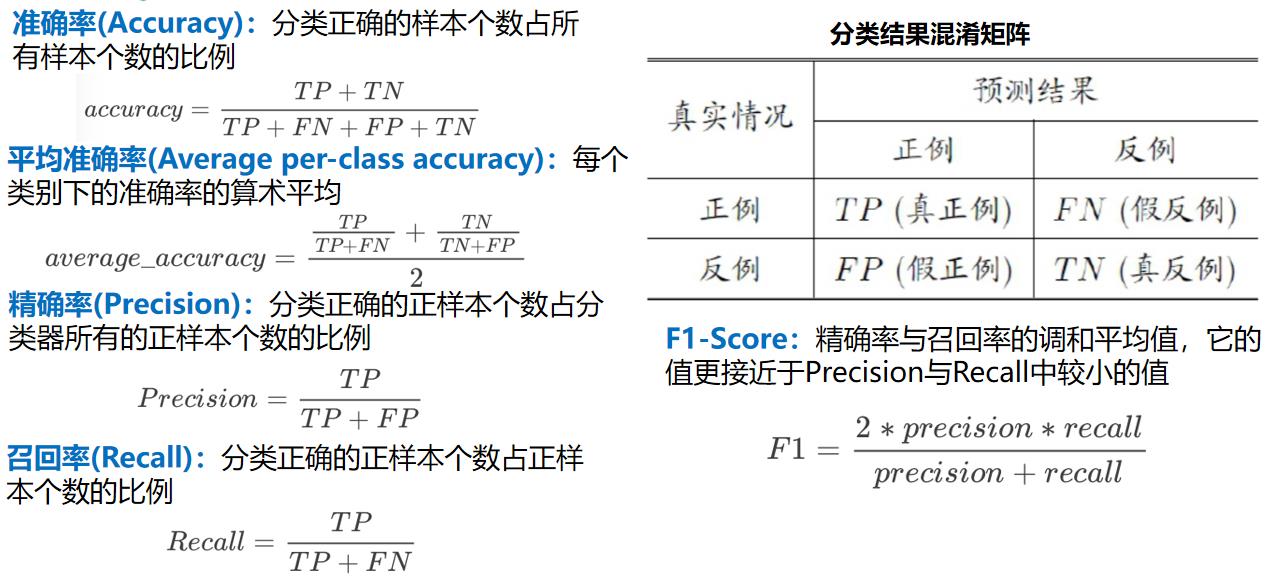
训练时,系统会计算和记录每个样本的特征向量值,并对样本进行分类,同时记录样本的类别信息。训练阶段结束后,分类器可输出各类中样本的数量、类标记、类内分离度以及类间距等信息。若要得知分类器的优劣,可通过计算分类器的可预测性(Predictability)、准确性(Accuracy)和交叉验证的稳定性(CrossValidation Stability)指标对分类器进行定量评价。
下图对分类器的创建和操作相关的关键信息进行了汇总:

1.1、目标对象数据样本
用于训练的样本集合中的样本可以一次性收集完成,也可以渐进增减的方式来收集。

- 若收集的样本类别归属已知,就可直接为样本设置类标签(Class Label)。否则,则要通过聚类(Clustering)过程对样本进行归类。
- 若所有参与训练的样本都有类标签,则称训练为有监督(Supervised)训练;若样本均无类标签,则称训练为无监督(Unsupervised)训练;
- 若样本和其归属的类别信息并不完全,则训练过程称为半监督(Semi-Supervised)训练,例如只有部分样本有明确的类标签,或仅已知样本可能得归属的几种类信息,但尚未确定每个样本的类别归属等。
样本集合的优劣可以通过类内分离度(Intraclass Deviation)和类间距(Interclass Distance)两个指标来衡量。由于样本集合中属于同一类别的样本一般具有相似的特征向量值,因此同一类内的样本分离度应较小,而类与类之间的距离应足够大。
1.2、目标对象分类器配置
确定了训练的样本数据集后,就需要对分类器进行配置,以确定训练过程对样本进行分类时所依据的特征向量,设置特征提取过程的参数,以及训练过程是否要对样本的尺度、旋转和镜像保持不变性等。
由于训练过程和分类过程需要使用相同的特征向量,因此确定训练样本集特征向量的过程实际上就是为整个训练和分类过程指定特征向量的过程。
对机器视觉分类系统来说,样本特征向量通常由二值化后的颗粒特征、目标的颜色、纹理或其他自定义的特征构成,以颜色和纹理构建特征向量的分类器配置较为直接。
基于自定义特征向量的分类器需要事先从图像中提取特征,构建自定义的特征向量。基于颗粒特征向量的分类器则根据预定义的特征向量,在保持尺度、旋转和镜像不变的情况下,根据目标形状对其进行分类。
以下以基于颗粒特征向量的分类器为例,介绍分类器的配置。
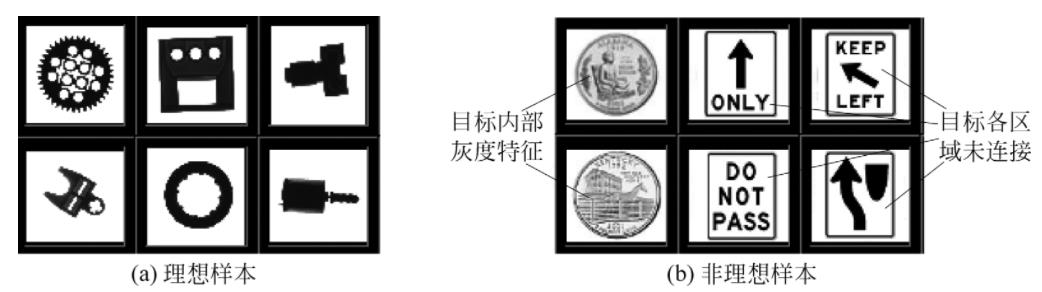
一般来说,基于颗粒特征向量的分类器能对满足以下3个条件的样本进行准确分类:
- 机器视觉光源为背光照射方式;
- 图像中样本各部分相互连通;
- 图像中样本各部分为实心填充,不含其他灰度特征。
下图给出了基于颗粒特征向量进行分类的系统中理想样本和非理想样本的实例。
Nl Vision使用8个颗粒分析的特征来构建颗粒特征向量,以实现对样本或被测目标按其形状的训练和分类。也就是说,Nl Vision基于颗粒特征向量的函数,内置了对目标按形状进行分类的特征向量。
用于构建特征向量的8个颗粒特征如下表所示:
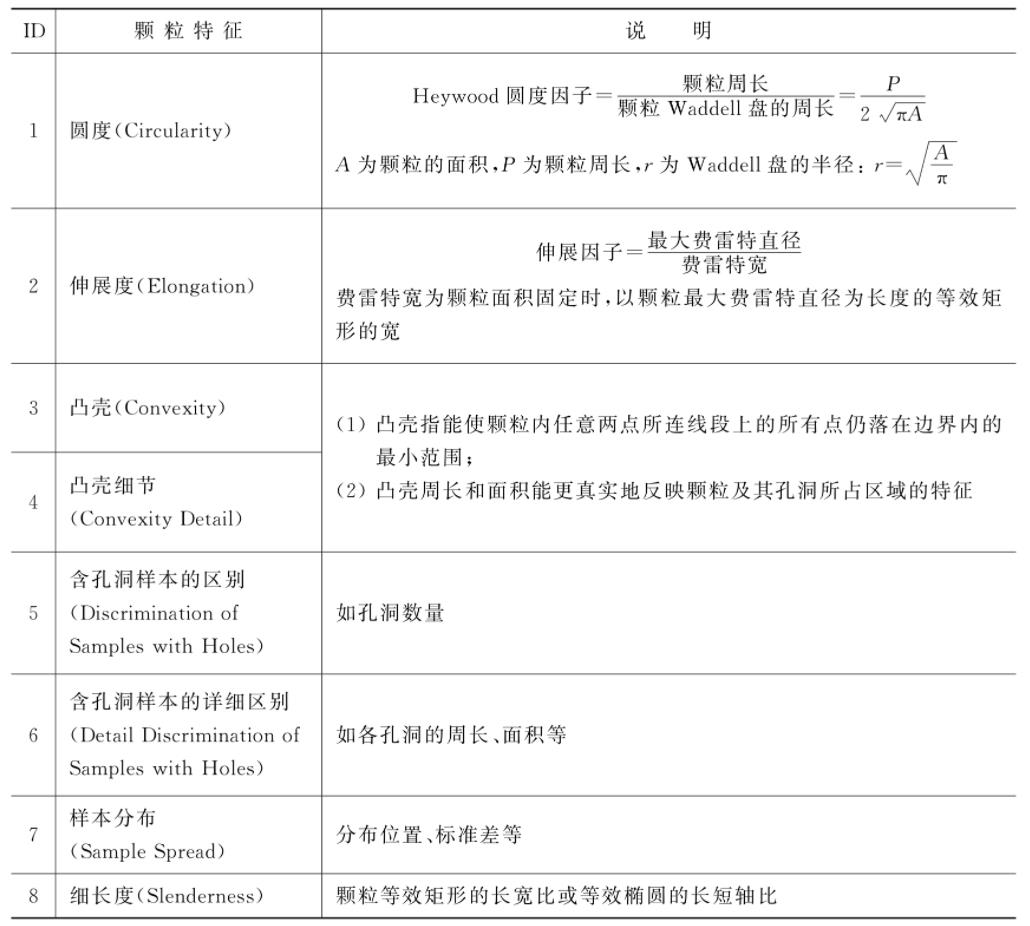
Nl Vision将基于颗粒特征创建的特征向量称为形状描述符(Shape Descriptor)。根据训练和分类过程对目标尺度不变性(Scale lnvariant)、旋转不变性(RotationInvariant)或镜像对称不变性(Mirror Symmetry lnvariant)的要求,形状描述符可以由上表中8个特征中的一个或多个构成。
Nl Vision基于形状描述符进行样本训练或目标分类时,支持旋转、尺度和镜像对称不变性。也就是说,训练或分类过程仅根据与形状相关的特征进行,即使目标已被旋转、缩放或镜像对称,只要其形状特征未发生变化,都能被正确训练和分类。
下图给出了一个基于形状描述符的训练或分类过程,支持尺度、旋转和镜像对称不变性的示例。

1.3、目标对象分类器训练
完成分类器的配置后,就可以对样本集合中的各个样本进行训练。
训练过程实际是计算各个样本特征向量的值并按照分类方法对该值进行归类的过程。
常用的分类方法包括最邻近法(Nearest Neighbor)、K-邻近法(K-Nearest Neighbor,KNN)、最小平均距离(Minimum Mean Distance)和支持向量机 (Support Vector Machine,SVM)4种。
1.4、目标对象分类器输出和评估
根据以上几节论述,在对分类器的训练过程结束后,应确定下列与分类器和样本相关的信息:
- 样本集中的样本被训练为哪几类;
- 每类中样本的数量;
- 每个类中样本的分离度;
- 类与类的间距;
- 分类器所使用分类方法(引擎)的相关信息等。
因此,正常情况下这些信息都应在分类器训练过程结束后作为分类器的输出信息提供给其他程序代码使用。在程序运行过程中,这些信息可由程序代码引用分类器会话获得。若要离线使用这些信息,则需要将它们保存在分类器文件中,以备后续读取访问。
可以基于对样本的分类训练结果来计算分类器对某一类的预测准度(Classifier Predictability)和分类准确性(Classifier Accuracy),并进而评价分类器的质量。分类器的预测准度是指将样本分类到某一指定类别时样本属于该指定类的概率。

假定分类器使用的样本集含有30个样本,其中属于A、B、C 3个类的样本各占10个。若某一分类器对样本集进行训练分类后的分布如下表所示,则依据样本分类分布表可计算分类器预测准度和分类准确性。
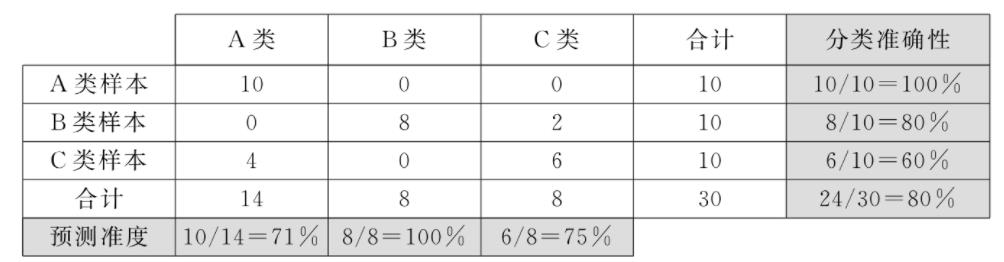
例如第一列中,分类至A类的14个样本中有10个来自A类的正确分类样本和4个来自C类的错误样本,由此可知,分类器对A类的预测准度为71%。表中的各行表示属于每类的样本被分类器分至不同类的情况。例如表中第二行,10个属于B类的样本有8个被正确分类,2个被错误地分至C类,因此分类器对B类的分类准确性为80%。
2、分类与识别
基于样本数据集完成训练过程后,即可得到包含样本数量、类别、特征以及分类方法等信息的分类器。而使用该分类器,就能将未知类别的目标与分类器中的样本进行比较,以实现目标的分类、统计或质量检测等应用。
目标的归类、分拣或统计的应用实现思路较为直接,一般使用训练得到的颜色、形状、纹理或自定义特征分类器对目标直接进行分类,并根据结果控制执行机构动作。例如,基于目标分类的质量检测应用则不仅需要使用训练得到的分类器对被测件进行分类识别,还要按照分类结果的可信度(ClassificationConfidence)和识别结果的可信度(ldentification Confidence)的大小来判断被测件的合格性。
以上是关于LabVIEW目标对象分类识别的主要内容,如果未能解决你的问题,请参考以下文章