一篇文章彻底搞定跨集群跨版本distcp的使用
Posted 涤生手记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一篇文章彻底搞定跨集群跨版本distcp的使用相关的知识,希望对你有一定的参考价值。
1.DistCp是是什么?
distcp是一个hdfs提供的工具。看官网关于distcp工具的描述:
- distcp(分布式复制)是一种用于大型集群间/集群内复制的工具,且支持不同hadoop版本间的数据传输复制。
- 它使用 MapReduce 来实现其分布、错误处理和恢复以及报告。它将文件和目录列表扩展为map任务的输入(一个只有map没有reduce的mapreduce任务),每个任务将复制源列表中指定的文件的一个分区。
2.DistCp的生产使用
注意distcp支持大型集群间/集群内部数据的复制,对于集群间的数据复制要注意源集群和目标集群的hadoop版本是否一致,如果不一致,复制的方式是不一致的,这个版本主要针对大版本的一致性性,如hadoop1.x,hadoop2.x,hadoop3.x之间的区别,对于小版本没有关系,本质是看版本之间使用的协议是否一致。
对于集群内的复制就没有什么区别了,用法跟hadoop cp差不多。因为Distcp实际开发中也主要是针对跨集群之间的数据传输。
2.1 Distcp语法与参数解析
2.1.1.distcp标准格式与参数
#将10.90.48.127上的文件传输到指定10.90.50.53上同名目录
hadoop distcp hdfs://10.90.48.127:8020/user/hive/warehouse/dm_smssdk_master.db/log_device_phone_dedup/ \\
hdfs://10.90.50.53:8020/user/hive/warehouse/dm_smssdk_master.db/log_device_phone_dedup/- 注意,上面10.90.48.127和10.90.50.53都是两个集群的主namenode的ip,故distcp源ip和目标ip要和对应actvie的namenode的ip保持一致,因为它是复制指定namespace空间下的文件所以要去找namenode.
- 端口这块要和namenode配置的通信端口一致fs.default.name, fs.defaultFS,不同集群可能配置的端口不一致,以实际为准。
- 源集群和目标集群在执行传输数据时,要有同名的hadoop用户,并且具有对应的权限。
- 相关distcp参数可以互相搭配使用
- 注意,使用hdfs协议的distcp即可以在源集群也可以在目标集群执行,在哪个集群执行使用哪个集群的资源。
| distcp核心参数 | 参数含义 | 补充 |
| -m <num_maps> | 同时启动的最大map数 -m 50,启动50个map | 指定要复制数据的map数。请注意,更多的map数不一定会提高吞吐量。因为DistCp 的最小工作单位是文件。即,一个文件仅由一个map处理。将map数量增加到超过文件数量的值不会产生性能优势。启动的地图数量将等于文件数量。 |
| -overwrite | 覆盖目的地的数据 | 跟hive overwrite用法一样 |
| -update | 如果源数据和目标数据的大小、块大小或校验和不同,则覆盖它,使用-update仅复制更改的文件。 | 这种主要用来更新复制,如果源数据和目标数不一致,则更新复制数据,将目标数据覆盖了。这种非常使用比如传输中途失败了,然后重传,不需要重头再传,有点类似断点续传。 |
| -bandwidth | 指定传输过程每个map的带宽,以 MB/秒为单位。 -bandwidth 100,每个map最多使用100Mb带宽。 | 主要用来限制复制时节点使用的带宽,防止影响生产正常任务的执行,尤其对于带宽紧张的集群。每个地图将被限制为仅消耗指定的带宽。 |
| -numListstatusThreads | 用于构建文件列表的线程数 | 最多 40 个线程,一般不指定。 |
| -skipcrccheck | 是否跳过源路径和目标路径之间的 CRC 检查。 | 一般跳过,不然复制很慢。但是跳过会存在数据安全性降低的情况。 |
| -direct | 直接写入目标路径 | 当目标是对象存储时,可用于避免可能非常昂贵的临时文件重命名操作。一般不建议使用。一般实际传输都是先创建临时文件,最后mv重命名一下即可。 |
其他相关参数,参考官方文档:disctcp 官网使用介绍
2.2跨集群不跨版本distcp使用hdfs协议传输
1.控制map个数,不校验,更新模式传输。注意这里设置了用户使用队列。
hadoop distcp -Dmapreduce.job.queuename=root.yarn_data_compliance \\
-update -skipcrccheck -m 100 \\
hdfs://10.90.48.127:8020/user/hive/warehouse/dm_smssdk_master.db/log_device_phone_dedup/ \\
hdfs://10.90.50.53:8020/user/hive/warehouse/dm_smssdk_master.db/log_device_phone_dedup/
2.3跨集群跨HDFS版本的distcp使用webhdfs传输
为了在 Hadoop 的两个不同主要版本集群之间进行复制(例如在 2.X 和 3.X 之间),通常会使用 WebHdfsFileSystem。与之前的 HftpFileSystem 不同,由于 webhdfs 可用于读写操作,因此 DistCp 可以在源集群和目标集群上运行(HftpFileSystem。 这是一个只读文件系统,所以DistCp必须运行在目标端集群上,Hadoop3.x 已经对其废弃使用,使用webhdfs替代)
注意使用webhdfs时远程集群的URI格式为为webhdfs://<namenode_hostname>:<http_port>。在相同主要版本的 Hadoop 集群之间进行复制时(例如在 2.X 和 2.X 之间),使用 hdfs 协议以获得更好的性能。
案例1:cdh集群hadoop2.6往cdh hadoop3.3集群传输文件
hadoop distcp -update -skipcrccheck -m 50 \\
webhdfs://10.90.48.127:50070/user/hive/warehouse/dm_smssdk_master.db/log_device_phone_dedup/day=20210701 \\
webhdfs://10.90.50.54:9870/user/hive/warehouse/dm_smssdk_master.db/log_device_phone_dedup/day=20210701 如上,跨集群跨版本从10.90.28.127的hadoop2.6集群往10.90.50.54的hadoop3.3集群上传输文件,使用webhdfs协议。脚本运行在目标集群10.90.50.54上执行。当然也可以运行10.90.28.127上执行。注意这里两个集群的端口不一致,因为不同版本的端口不一致,以实际配置端口为准。
实际执行过程:
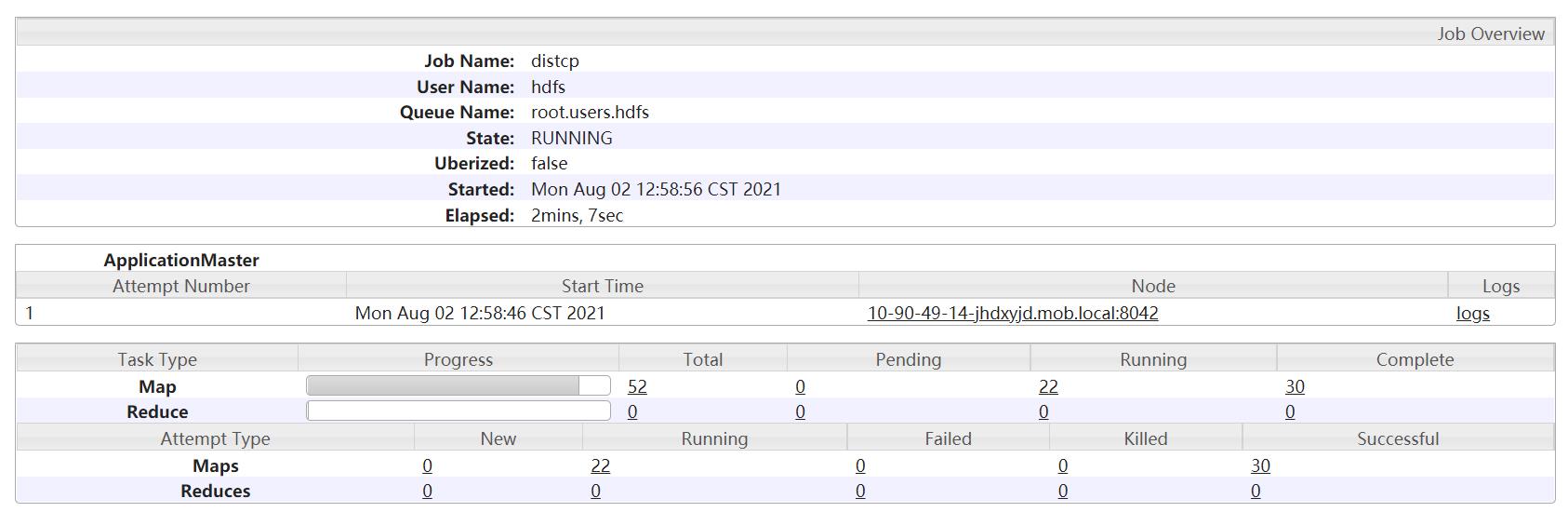
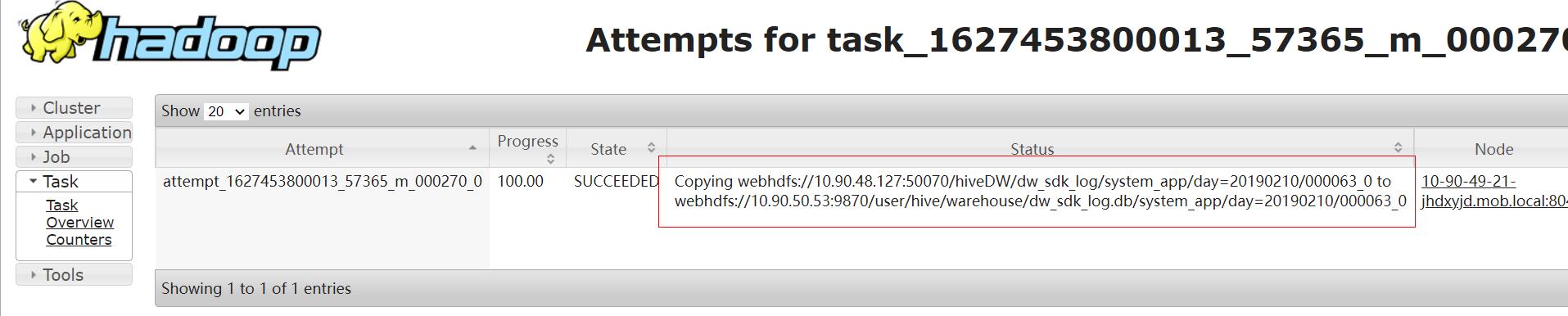
3.Distcp的其他介绍
3.1distcp支持同时配置多个数据源的传输复制
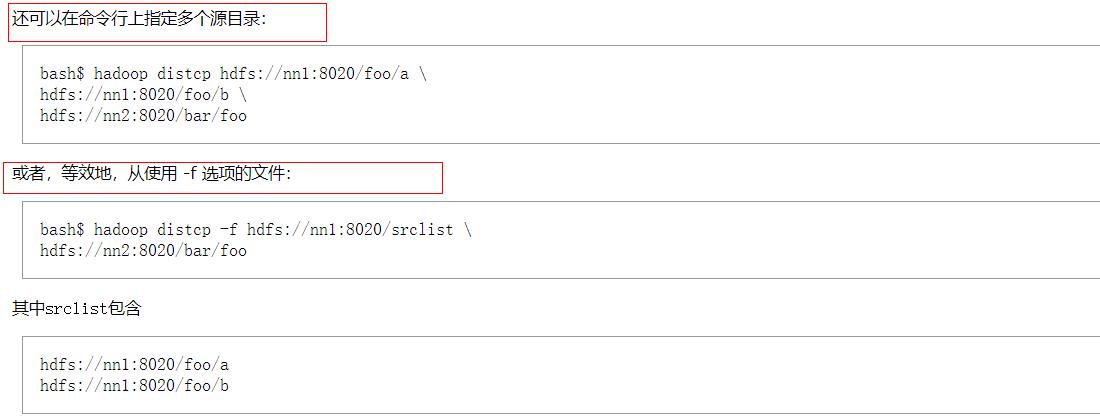
3.2 distcp的架构
新的hadoop3.x DistCp 的组件可以分为以下几类:基于此我们可以自定义distcp jar包,定制化文件传输使用。
- DistCp 驱动程序
- 复制列表生成器
- 输入格式和 Map-Reduce 组件
其他关于distcp的详细介绍与使用,可以参考官网
https://hadoop.apache.org/docs/stable/hadoop-distcp/DistCp.html
以上是关于一篇文章彻底搞定跨集群跨版本distcp的使用的主要内容,如果未能解决你的问题,请参考以下文章
一篇文章彻底掌握 HDFS 跨集群跨版本数据同步工具 hadoop disctp