还在直接操作Redis?赶快来试试它....
Posted Java知音_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了还在直接操作Redis?赶快来试试它....相关的知识,希望对你有一定的参考价值。
点击关注公众号,实用技术文章及时了解
有些人还在直接用Jedis操作Redis数据库,但这种方式非常不方便,而且很不灵活。用Spring Boot整合Redis之后,既能非常方便地操作Redis数据库,Spring Boot又可以自由地在Lettuce或Jedis等技术之间自由切换。
目前Jedis操作Redis已经趋于淘汰,而是应该使用Lettuce。Spring Data Redis模块默认使用Lettuce。
由于Spring Data是高层次的抽象,而SpringData Redis只是属于底层的具体实现,因此Spring Data Redis也提供了与前面Spring Data完全一致的操作。
归纳起来,Spring Data Redis大致包括如下几方面功能。
DAO接口只需继承CrudRepository,Spring Data Redis能为DAO组件提供实现类。
Spring Data Redis支持方法名关键字查询,只不过Redis查询的属性必须是被索引过的。
Spring Data Redis同样支持DAO组件添加自定义的查询方法—通过添加额外的接口,并为额外的接口提供实现类,Spring Data Redis就能将该实现类中的方法“移植”到DAO组件中。
Spring Data Redis同样支持Example查询。
需要说明的是,Spring Data Redis支持的方法名关键字查询功能不如JPA强大,这是由Redis底层决定的—Redis不支持任何查询,它是一个简单的key-value数据库,它获取数据的唯一方式就是根据key获取value。因此它不能支持GreaterThan、LessThan、Like等复杂关键字,它只能支持如下简单的关键字。
And:比如在接口中可以定义“findByNameAndAge”。
Or:比如“findByNameOrAge”。
Is、Equals:比如“findByNameIs”“findByName”“findByNameEquals”。这种表示相同或相等的关键字不加也行。
Top、First:比如“findFirst5Name”“findTop5ByName”,实现查询前5条记录。
那问题来了,Spring Data操作的是数据类(对JPA则是持久化类),那么它怎么处理数据类与Redis之间的映射关系呢?其实很简单,SpringData Redis提供了如下两个注解。
@RedisHash:该注解指定将数据类映射到Redis的Hash对象。@TimeToLive:该注解修饰一个数值类型的属性,用于指定该对象的超时时长。
此外,Spring Data Redis还提供了如下两个索引化注解。
@Indexed:指定对普通类型的属性建立索引,索引化后的属性可用于查询。@GeoIndexed:指定对Geo数据(地理数据)类型的属性建立索引。
在理解了Spring Data Redis的设计之后,接下来通过示例来介绍Spring Data Redis的功能和用法。
首先依然是创建一个Maven项目,然后让其pom.xml文件继承spring-boot-starter-parent,并添加spring-boot-starter-data-redis.jar依赖和commons-pool2.jar依赖。由于本例使用SpringBoot的测试支持来测试DAO组件,因此还添加了spring-boot-starter-test.jar依赖。具体可以参考本例的pom.xml文件。
先为本例定义application.properties文件,用来指定Redis服务器的连接信息。
程序清单
spring.redis.host=localhost
spring.redis.port=6379
# 指定连接Redis的DB1数据库
spring.redis.database=1
# 连接密码
spring.redis.password=32147
# 指定连接池中最大的活动连接数为20
spring.redis.lettuce.pool.maxActive = 20
# 指定连接池中最大的空闲连接数为20
spring.redis.lettuce.pool.maxIdle=20
# 指定连接池中最小的空闲连接数为2
spring.redis.lettuce.pool.minIdle = 2
下面定义本例用到的数据类。
程序清单
@RedisHash("book")
public class Book
{
// 标识属性,可用于查询
@Id
privateInteger id;
// 带@Indexed注解的属性被称为“二级索引”,可用于查询
@Indexed
privateString name;
@Indexed
privateString description;
privateDouble price;
// 定义它的超时时长
@TimeToLive(unit = TimeUnit.HOURS)
Longtimeout;
// 省略getter、setter方法和构造器
...
}
上面的Book类使用了@RedisHash("book")修饰,这意味着将该类的实例映射到Redis中的key都会增加book前缀。
上面的id实例变量使用了@Id修饰,这表明它是一个标识属性,这一点和所有Spring Data的设计都是一样的。
上面的name、description两个实例变量使用了@Indexed修饰,这表明它们将会被“索引化”—其实就是为它们创建对应的key,后面会看到详细示例。
接下来定义本例中DAO组件的接口。
程序清单:
public interface BookDaoextends CrudRepository<Book, Integer>,
QueryByExampleExecutor<Book>
{
List<Book> findByName(Stringname);
List<Book> findByDescription(StringsubDesc);
}
正如从上面代码所看到的,该DAO接口继承了CrudRepository,这是Spring Data对DAO组件的通用要求。此外,该DAO接口还继承了QueryByExampleExecutor,这意味着它也可支持Example查询。
下面为该DAO组件定义测试用例,该测试用例的代码如下。
程序清单:
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.NONE)
public class BookDaoTest
{
@Autowired
private BookDaobookDao;
@Test
publicvoid testSaveWithId()
{
varbook = new Book("疯狂Python",
"系统易懂的Python图书,覆盖数据分析、爬虫等热门内容", 118.0);
// 显式设置id,通常不建议设置
book.setId(2);
book.setTimeout(5L); // 设置超时时长
bookDao.save(book);
}
@Test
publicvoid testUpdate()
{
// 更新id为2的Book对象
bookDao.findById(2)
.ifPresent(book -> {
book.setName("疯狂Python讲义");
bookDao.save(book);
});
}
@Test
publicvoid testDelete()
{
// 删除id为2的Book对象
bookDao.deleteById(2);
}
@ParameterizedTest
@CsvSource({"疯狂Java讲义, 最全面深入的Java图书, 129.0",
"SpringBoot终极讲义,无与伦比的SpringBoot图书, 119.0"})
publicvoid testSave(String name, String description, Double price)
{
varbook = new Book(name, description, price);
bookDao.save(book);
}
@ParameterizedTest
@ValueSource(strings= {"疯狂Java讲义"})
publicvoid testFindByName(String name)
{
bookDao.findByName(name).forEach(System.out::println);
}
@ParameterizedTest
@ValueSource(strings= {"最全面深入的Java图书"})
publicvoid testFindByDescription(String description)
{
bookDao.findByDescription(description).forEach(System.out::println);
}
@ParameterizedTest
@CsvSource({"疯狂Java讲义, 最全面深入的Java图书"})
publicvoid testExampleQuery1(String name, String description)
{
// 创建样本对象(probe)
vars = new Book(name, description, 1.0);
// 不使用ExampleMatcher,创建默认的Example
bookDao.findAll(Example.of(s)).forEach(System.out::println);
}
@ParameterizedTest
@ValueSource(strings= {"SpringBoot终极讲义"})
publicvoid testExampleQuery2(String name)
{
// 创建matchingAll的ExampleMatcher
ExampleMatchermatcher = ExampleMatcher.matching()
// 忽略null属性,该方法可以省略
//.withIgnoreNullValues()
.withIgnorePaths("description"); // 忽略description属性
// 创建样本对象(probe)
vars = new Book(name, "test", 1.0);
bookDao.findAll(Example.of(s,matcher)).forEach(System.out::println);
}
}
虽然上面DAO组件中只定义了两个方法,但由于DAO接口继承了CrudRepository和QueryByExampleExecutor,它们为DAO接口提供了大量方法。
运行上面的testSaveWithId()方法,该方法测试BookDao的save()方法,该方法运行完成后看不到任何输出。但打开AnotherRedis DeskTop Manager连接DB1,则可看到图1所示的数据。
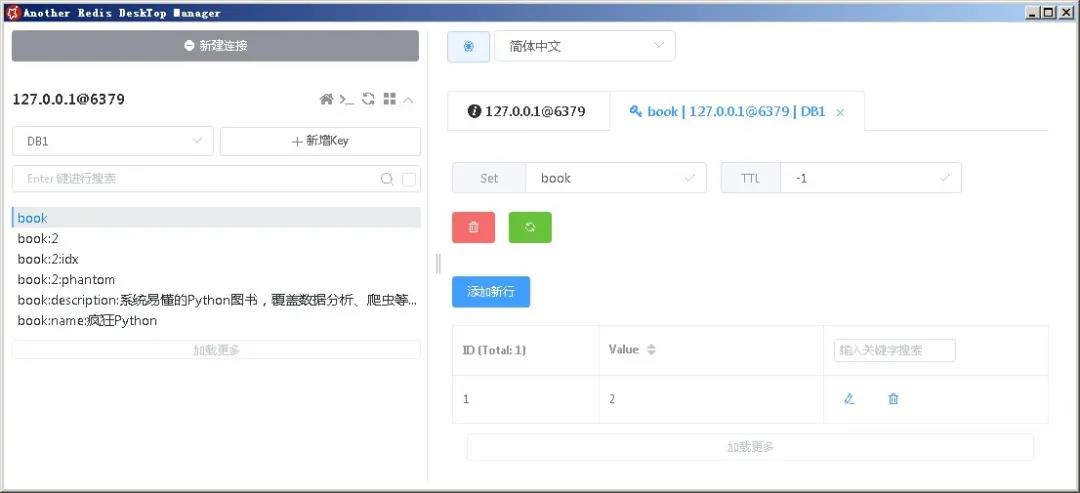
从图1可以看到,虽然程序只保存了一个Book对象,但Redis底层生成了大量key-value对,由于前面在Book类上增加了@RedisHash("book")注解,因此这些key的名字都以“book”开头。
先看名为“book”的key,图1显示了该key的内容,该key对应一个Set,该Set中的元素就是每个Book对象的标识属性值。由于此时系统中仅有一个Book对象,因此该key对应的Set中只有一个元素。
再看名为“book:标识属性值”(此处就是book:2)的key,图2显示了该key的内容。
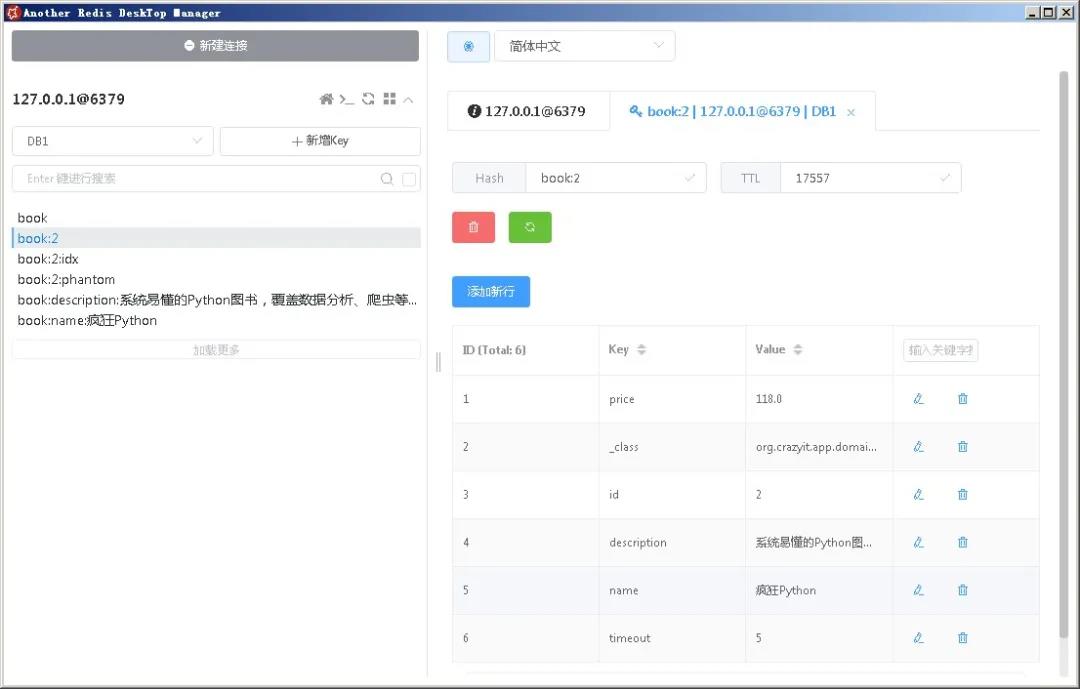
从图2可以看到,“book:标识属性值”key所对应的是一个Hash,它完整地保存了整个Book对象的所有数据,这就是Redis性能非常好的原因—当程序要根据id获取某个Book对象时,Redis直接获取key为“book:id值”的value,这样就得到了该Book对象的全部数据。
前面还为Book对象的name、description属性添加了@Indexed注解,因此Spring Data还会为它们创建对应的key,从而实现高速查找。接下来看名为“book:name:疯狂Python”的key的内容,可以看到如图3所示的数据。
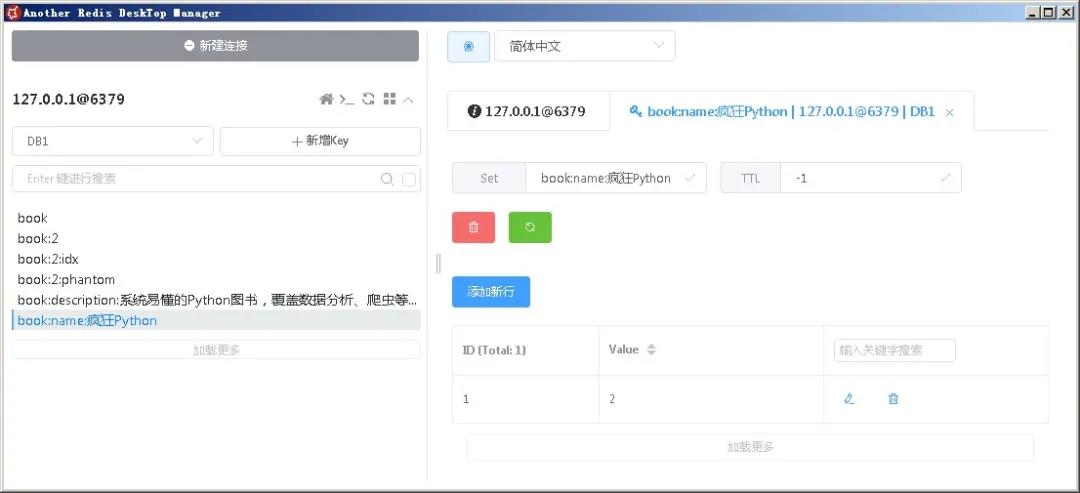
从图2可以看到,“book:name:疯狂Python”key对应的是一个Set,该Set的成员就是Book对象的id。此处为何要用Set呢?因为当程序保存多个Book对象时,完全有可能多个Book对象的name属性值都是“疯狂Python”,此时它们的id都需要由“book:name:疯狂Python”key所对应的Set负责保存,因此该key对应的是一个Set。
由此可见,当对数据类的某个属性使用@Indexed注解修饰之后,在保存该数据对象时就会为它保存一个名为“类映射名:属性名:属性值”的key,在该key对应的Set中将会添加该对象的标识属性。
最后来看key为“book:标识属性值:idx”的内容,可以看到如图4所示的数据。

从图4可以看到,key为“book:标识属性值:idx”的内容也是Set,它保存该对象所有额外的key。假如程序要查找name(假设name有@Indexed修饰)为“疯狂Python”的图书,Spring Data Redis底层会怎么做呢?
Spring Data Redis会直接获取“book:name:疯狂Python”key对应的Set,该Set中包含了所有name为“疯狂Python”的Book对象的id,然后遍历该Set的每个元素—每个元素都是一个id,接下来Spring Data Redis再获取“book:id值”对应的Hash对象,这样就获得了所有符合条件的Book对象。
在这个过程中,Spring Data Redis的两次操作都是通过key来获取value的,因此效率非常高,这都得益于SpringData Redis的优良设计和Redis的高效性能。
如果要保存一个所有属性都不用@Indexed修饰的Book对象,则只需要改变两个key。
book:在该key对应的Set中添加新Book对象的id。book:id:该key保存该Book对象的全部数据。
如果要保存一个有N个属性使用@Indexed修饰的Book对象,则需要改变如下key。
book:在该key对应的Set中添加新Book对象的id。book:id:该key对应的Hash对象保存了该Book对象的全部数据。book:id:idx:该key对应的Set保存了该Book对象所有额外的key。N个book:属性名:属性值:该key对应的Set保存了所有该属性都具有相同属性值的Book对象的id值。
以上内容摘自 《疯狂Spring Boot终极讲义》 ,阅读此书,写出自己的学习开发自己的自动配置和Starter组件。
此书正在京东、当当限时5折促销,欢迎扫码下单:

另外,小知这边照惯例送出五本,还是以抽奖的形式,运气不错的继续试试
以上是关于还在直接操作Redis?赶快来试试它....的主要内容,如果未能解决你的问题,请参考以下文章
还在手动部署springboot项目?不妨试试它,让你部署项目飞起来!