Flask学习(了解一下)
Posted Zephyr丶J
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flask学习(了解一下)相关的知识,希望对你有一定的参考价值。
flask学习
项目需要,来简单了解一下flask,目标能看懂项目代码就行
课程链接:https://www.bilibili.com/video/BV1w64y1d7ZE?from=search&seid=10597422289705144433
学习思想:
感觉说的很好

目标

Flask框架介绍
核心: Werkzeug 、 Jinja2
轻 : 只提供核心


Flask扩展包


虚拟环境的创建安装(跳过)


Flask程序编写
app对象是工程抽象出来的对象,这个对象做全局统一的管理,管理路由信息,配置信息和试图信息

from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
if __name__ == '__main__':
app.run()
初始化参数
Flask传入的第一个参数import_name的作用是寻找整个工程目录
app = Flask(__name__) # 传入的这个__name__是一个变量,Flask接收的它的值,类型是字符串
# 这里传入的是一个模块的名字,是以字符串的形式传进去的,__name__代表当前的工程目录。
#当然也可以传其他工程目录,但是通常都是当前工程

一个存放静态文件,一个存放模板文件
可以看下初始化的参数
def __init__(
self,
import_name: str,
static_url_path: t.Optional[str] = None,
static_folder: t.Optional[str] = "static",
static_host: t.Optional[str] = None,
host_matching: bool = False,
subdomain_matching: bool = False,
template_folder: t.Optional[str] = "templates",
instance_path: t.Optional[str] = None,
instance_relative_config: bool = False,
root_path: t.Optional[str] = None,
应用程序配置参数


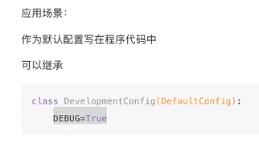
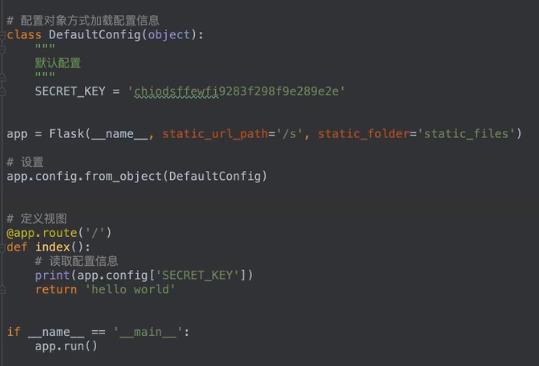
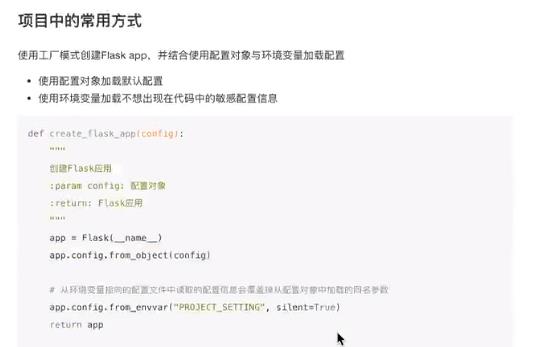
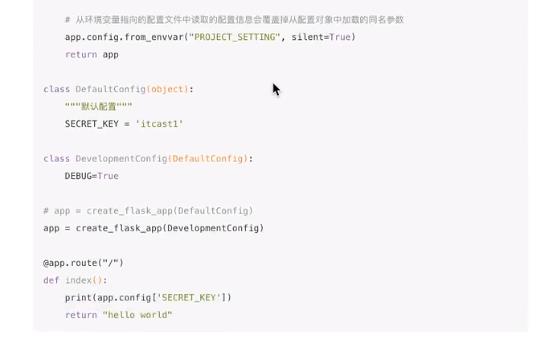
从配置对象中加载
可以继承,优点是可以复用;但是把敏感数据暴露了

从配置文件中加载
优点:独立配置文件,保留敏感数据
缺点:文件路径固定,不灵活
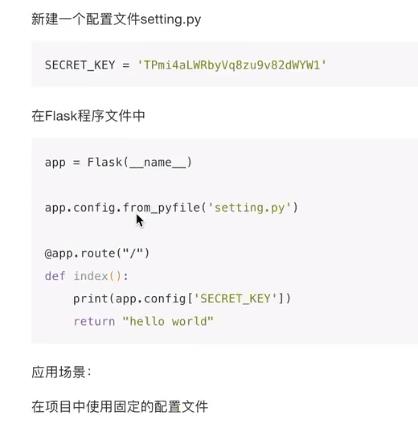
写一个配置文件,然后用下面的语句调用

从环境变量中加载
独立文件,保护敏感;灵活,文件路径不固定
缺点:不方便,记得设置环境变量
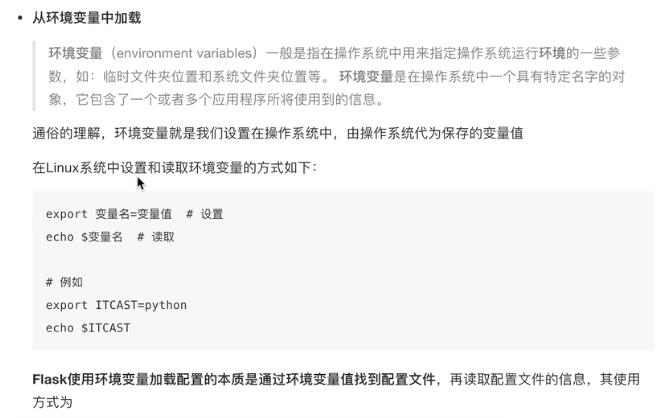

(这里silent写错了)

这里我在代码中将silent设置为True,然后在终端运行,可以显示出网址,但是访问会出错,显示如下。原因是没有给Project环境变量赋值
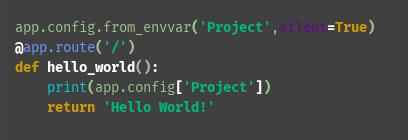

但是即使给环境变零赋值了,直接在pycharm中运行(不是终端)还是不行,因为设置的环境变量是有生命周期的,在pycharm中是不起作用的。这让我想起了前两天设置git的时候,也是在系统中设置了git的环境变量,但是在pycharm、idea中还是不能用,需要在软件中再进行配置,在右上角点击设置一下
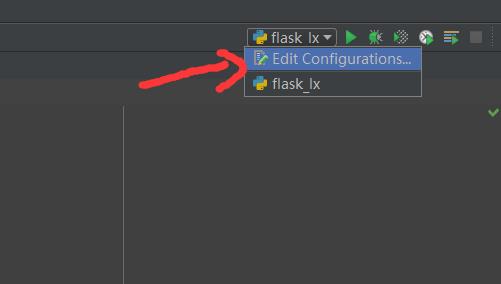
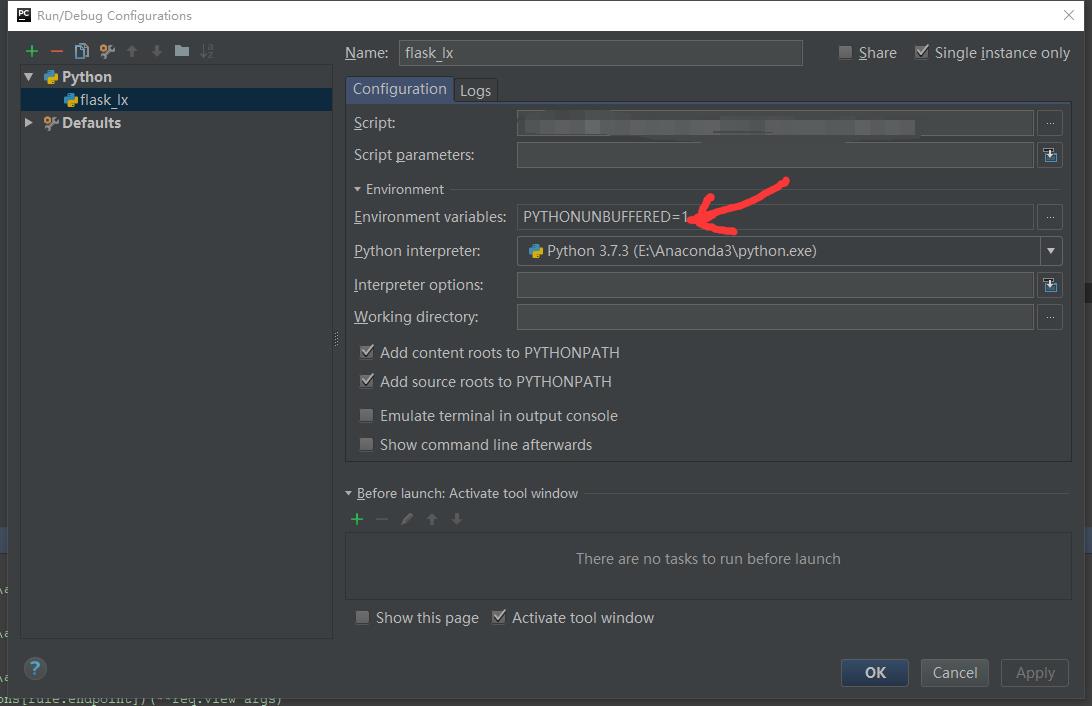
工程中Flask配置的实践方法
配置对象和配置环境变量同时使用
app.run参数

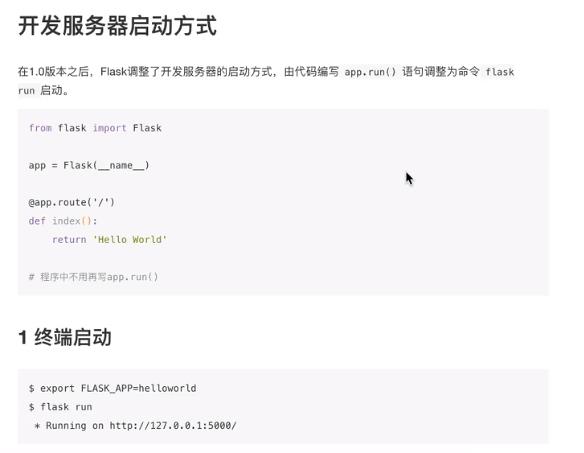
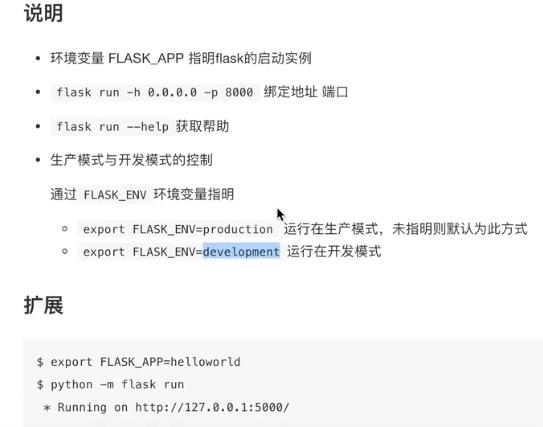
要想让pycharm运行起来,需要使用 python -m flask run
需要在刚刚设置环境变量的地方,设置启动方式,在箭头指向的栏,输入 -m flask run
(这是我的版本,比较老)
路由

这里需要指定环境变量FLASK_APP才能用这个命令查看路由信息


这里json.dumps是以json的方式返回

请求方式
如果用不允许的请求访问,那么会返回405:method not allowed

GET
OPTIONS(自带):简化版的GET请求,用于询问服务器接口信息的,比如接口允许的请求方式,允许的请求源头域名
CORS跨域:由中间件拦截浏览器发送的第一个options请求,然后去白名单中比对,
如果是允许的,那么就response一个正确的响应,告诉客户端可以请求,然后浏览器就会发送第二次真实的请求
HEAD(自带) 简化的GET请求,只返回GET请求处理时的响应头,不返回响应体
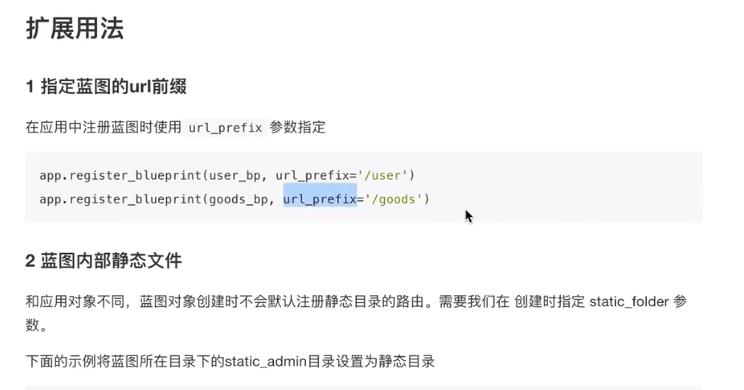
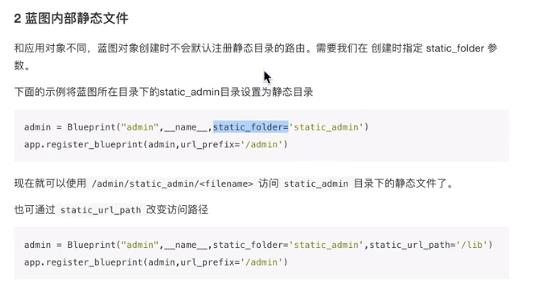
蓝图



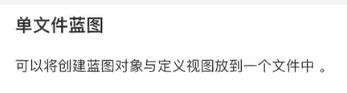

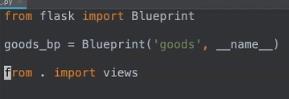
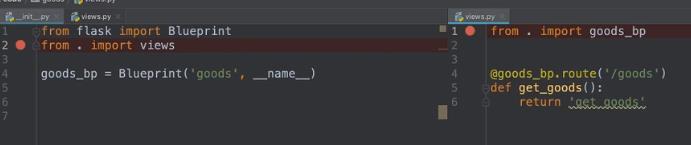
在init文件中,将视图在最后导入,否认会出现循环引用问题,如第二个图

Flask Debug模式的作用
后端出现错误,会直接返回真实的错误信息给前端
修改代码后,自动重启开发服务器
处理请求
请求报文
起始行:请求方式/请求路径path(带参数)/http协议的版本号
请求头Content-Type:application/json
…
body
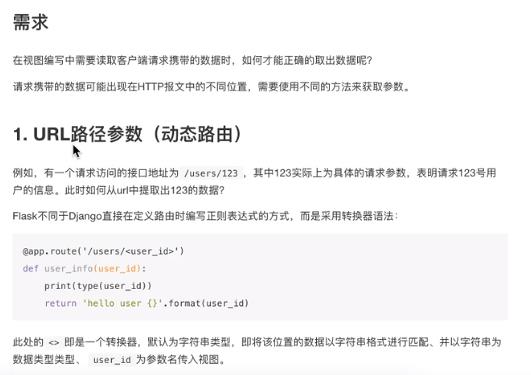
默认情况下没有设置匹配规则,那么就是String类型的
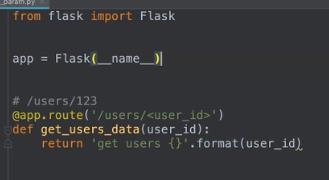
any是可选



注意 regex 名字是固定的



request 对象是一个全局对象,需要导入
data是body部分的原始数据
args 查询字符串
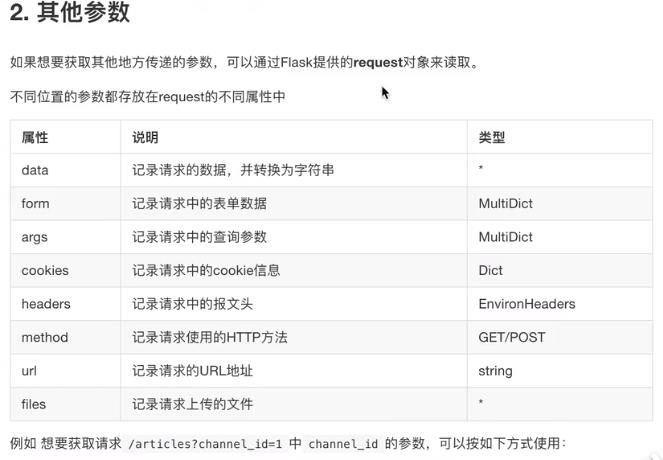
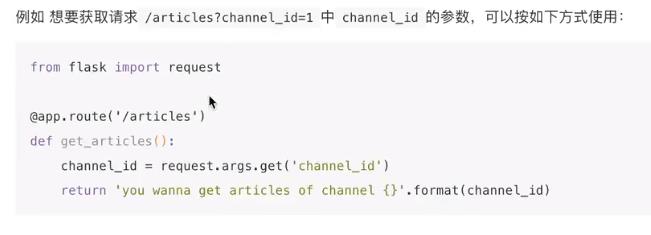
文件应该放在请求体中,get不允许携带请求体
files会将传入的二进制类型封装成为文件类型

处理响应
响应报文
HTTP/1.1 200 OK
Content-Type:application/json
…
body

返回模板render_template


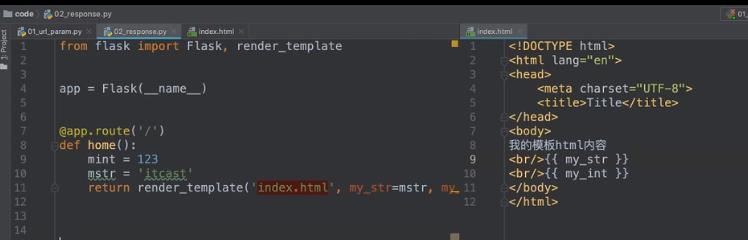
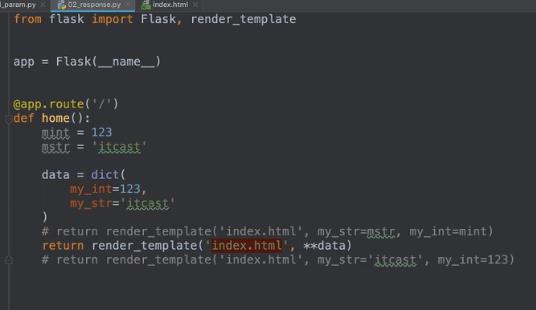
如果想直接传一个字典,那么写成**data,相当于my_str=‘itcast’,my_int=123
重定向

这个在浏览器中打开就直接是重定向的链接的界面
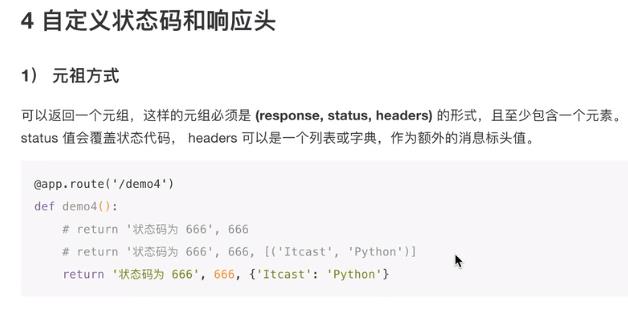
返回JSON
json.dumps() 和jsonify有什么区别
前者只是将数据转换成json格式,对应的相应头没有描述信息,可能还是文本的。它只是一个json序列化工具
但是后者会转换成json格式字符串,设置了响应头Content-Type:application/json
一般来说,在响应头部分应该写明响应体的部分是什么格式的

在浏览器打开后是如下界面:
Cookie
Cookie是什么?(百度百科)
Cookie 并不是它的原意“甜饼”的意思, 而是一个保存在客户机中的简单的文本文件, 这个文件与特定的 Web 文档关联在一起, 保存了该客户机访问这个Web 文档时的信息, 当客户机再次访问这个 Web 文档时这些信息可供该文档使用。由于“Cookie”具有可以保存在客户机上的神奇特性, 因此它可以帮助我们实现记录用户个人信息的功能, 而这一切都不必使用复杂的CGI等程序。
举例来说, 一个 Web 站点可能会为每一个访问者产生一个唯一的ID, 然后以 Cookie 文件的形式保存在每个用户的机器上。如果使用浏览器访问 Web, 会看到所有保存在硬盘上的 Cookie。在这个文件夹里每一个文件都是一个由“名/值”对组成的文本文件,另外还有一个文件保存有所有对应的 Web 站点的信息。在这里的每个 Cookie 文件都是一个简单而又普通的文本文件。透过文件名, 就可以看到是哪个 Web 站点在机器上放置了Cookie(当然站点信息在文件里也有保存)
https://jingyan.baidu.com/article/9f7e7ec0e5e8986f28155419.html
浏览器只认识报文
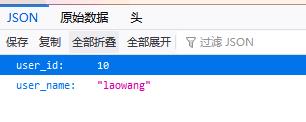
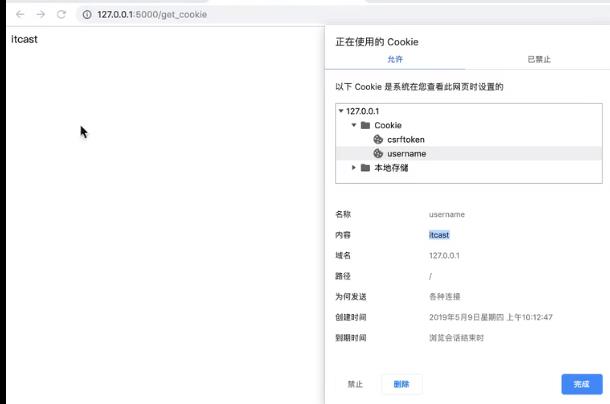
set_cookie方法修改了响应报文

浏览器中显示:
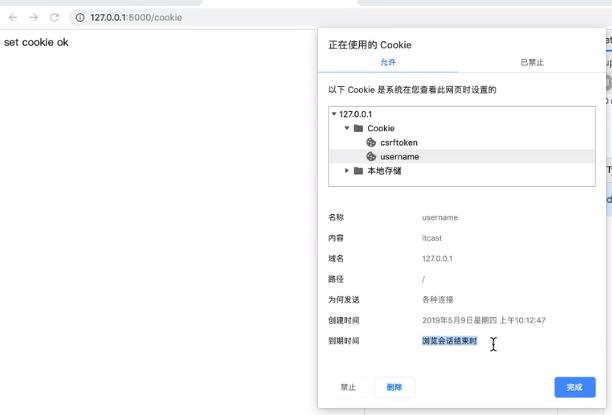
对应的响应报文:



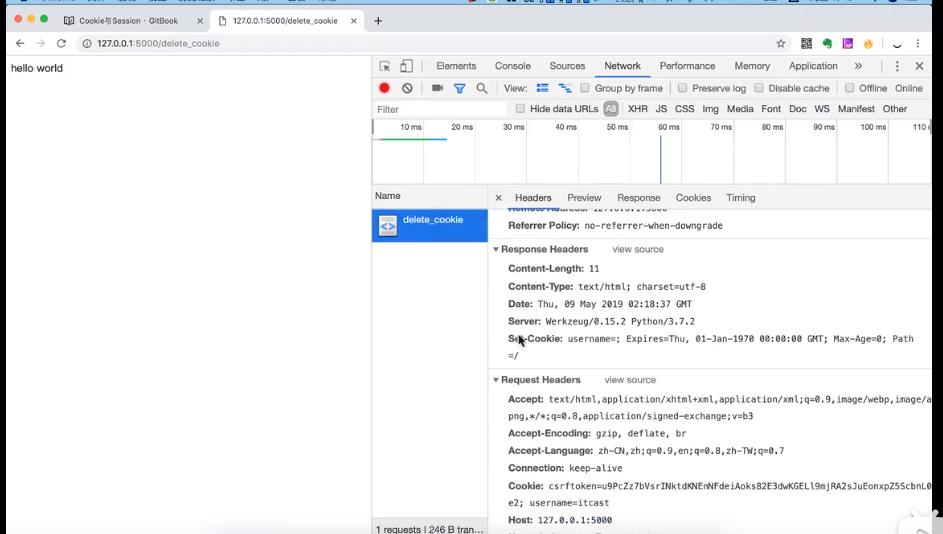
删除cookie的原理是将有限期设置成1970年1月1日,发现过期了, 就会自动清除
Session
session是什么?
https://jnshu.blog.csdn.net/article/details/79894570?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control

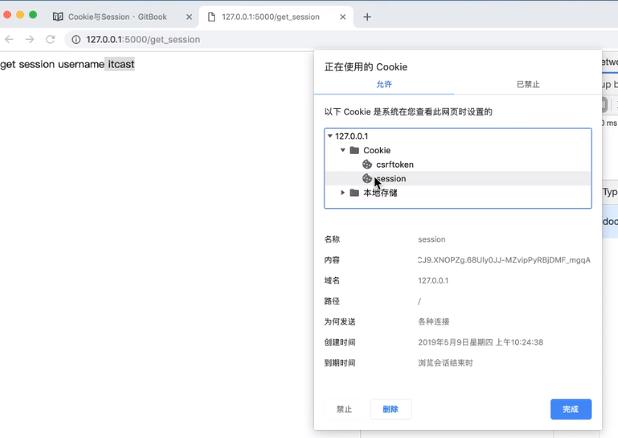
一个session对象可以有多个键值对


被保存在了浏览器缓存中
浏览器session
但是放在浏览器中,如果不引入后端redis存储,是不太安全的,防止不了用户去修改
只能加上一个签名,而这个签名就是配置的SECRET_KEY
可以看到下图保存的内容并不是我们输入的itcast,说明已经签过名了
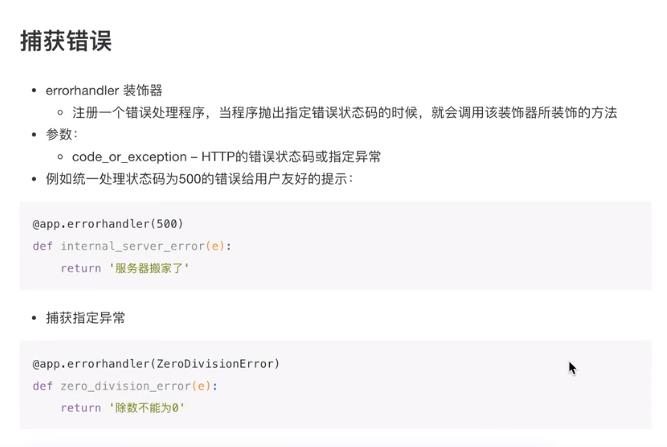
异常处理
5开头是服务器的错误,4是客户端的错误

统一的捕获错误信息
如果在一个试图中报错了,在浏览器中会报服务器的错误
但是浏览器并不是立即返回的,而是会看程序中有没有给flask声明过这个异常,有没有这个错误的处理方式。如果声明过,提供了处理方式,会先调用这个处理方式,然后才会返回
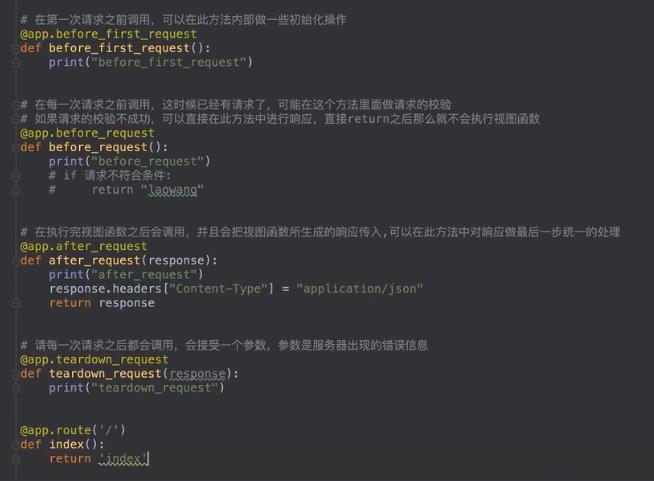
请求钩子hook
作用:中间件(中间层)的作用
请求的处理过程:pre_process -> view -> after_process
middleware1
middleware2
middleware3
请求进来的时候,中间层是从上到下,返回的时候是从下到上
每一个中间层可以理解为一个类,类里面有pre_proccess,和after_process,即前期处理方法和后期处理方法
有一个请求过来的时候,框架拿到这个请求,不是立即进入视图函数去执行
而是先找到中间件,在中间件中调用前期处理方法,执行完成之后,再进入视图执行;视图执行完之后,也并不是把视图执行完的对象response返回,而是给了后期处理方法
如果有多个中间层,那么先执行中间层1的前期处理方法,再执行中间层2的前期处理方法…然后执行view,再调用底层的后期处理方法…执行中间层1的后期处理方法
中间件处理不区分具体是哪个视图,对所有视图都生效
所有视图进来都要经历这样的过程,才能返回

打印出来的信息,符合刚刚描述的运行顺序

上下文
两个线程同时请求,那么该返回什么
虽然request和session是全局变量,但是在flask中反应出来的是线程内部的特征,跟整体没有关系




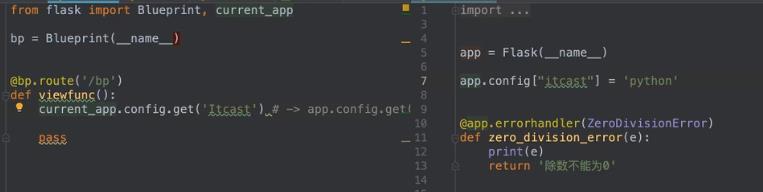
如果是多文件的时候,在子文件中并不好去用app,如果想去利用的话,就可以用代理人current_app,如下:
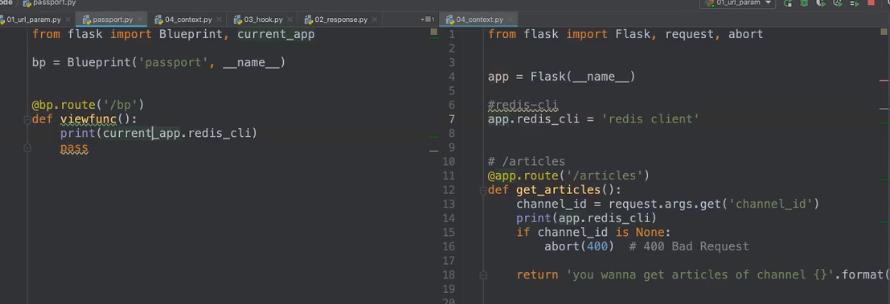
另一种应用场景:单一工程中绑定多个flask,不过一般不会这样写
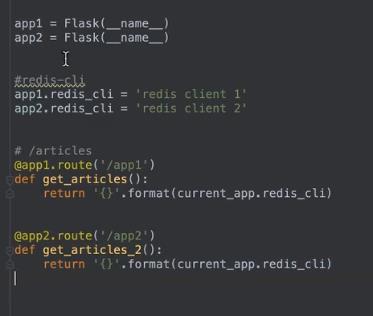
不过如果直接启动的话,是启动不起来的,因为一个模块里面有多个app,需要指明启动哪个


g对象虽然是应用上下文对象,但是跟请求是相关联的
在一个函数中,可能需要调用另一个方法,那么可能需要传递参数
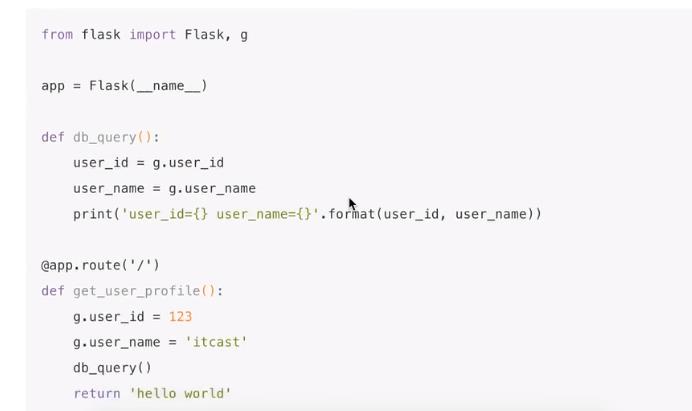
如果不用g对象的话,传递参数需要在函数声明中写出参数信息,但是如果使用g对象的话,相当于用一个容器保存了这些信息,直接可以在函数间传递
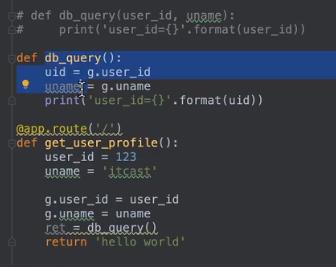

特定强制需求:用装饰器
所有视图的需求:请求钩子
请求 -> 请求钩子(尝试判断用户的身份,对于未登录用户不作处理,放行)用g对象保存用户身份信息 g.user_id
->普通视图处理
-> 强制登录视图 ->装饰器(没登录返回错误,登陆了放行)
第一步:请求钩子:
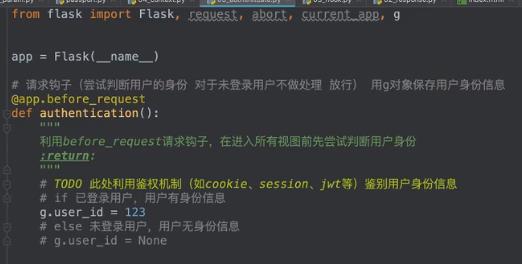
第二步:强制登录装饰器:
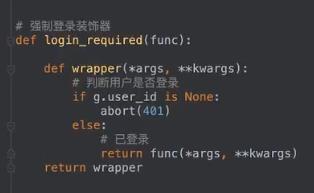
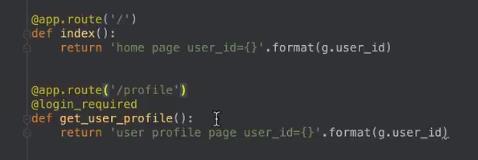
第三步:视图,强制登录的视图加上两个装饰器
多层装饰器怎么判断?上层装饰器将下层看成一个整体,进行装饰,这里就是login_required装饰了强制登录的视图,然后将它看成一个完整的视图,再绑定路由

例如在终端调试的时候,不会有上下文,如果直接用current_app会报错:

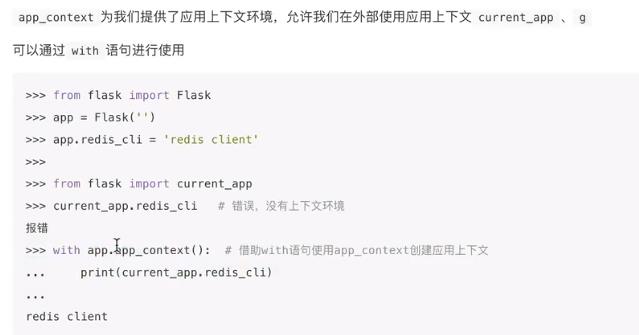
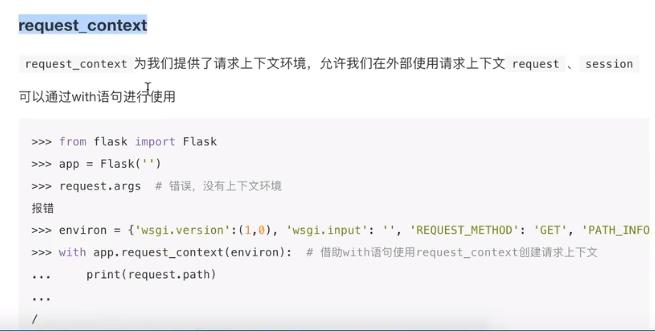
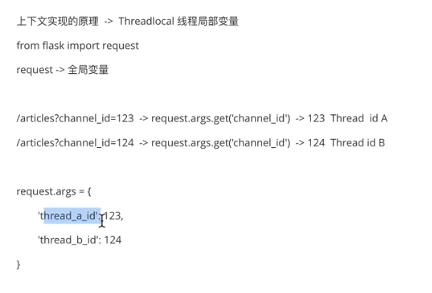
上下文实现的原理:ThreadLocal 线程局部变量
request ->全局变量
这里可以将request的args当成一个字典,里面存储了线程id和对应值的键值对
以上是关于Flask学习(了解一下)的主要内容,如果未能解决你的问题,请参考以下文章