归约分组与分区,深入讲解JavaStream终结操作
Posted Java-桃子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了归约分组与分区,深入讲解JavaStream终结操作相关的知识,希望对你有一定的参考价值。
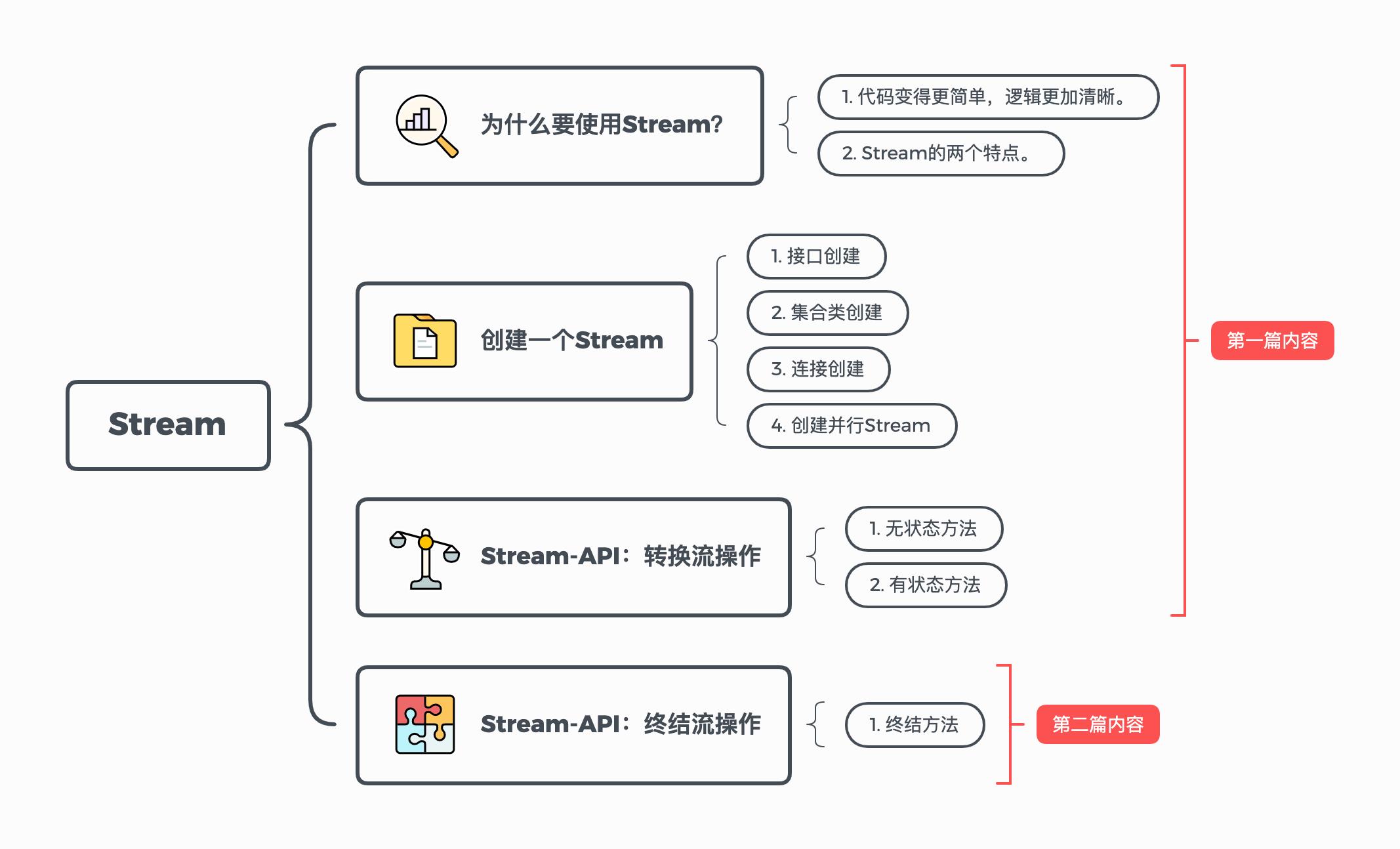
思维导图镇楼,先感谢大家对我上一篇文的积极点赞,助我完成KPI😄。
上一篇中给大家讲了Stream的前半部分知识——包括对Stream的整体概览及Stream的创建和Stream的转换流操作,并对Stream一些内部优化点做了简明的说明。
虽迟但到,今天就来继续给大家更Stream第二部分知识——终结操作,由于这部分的API内容繁多且复杂,所以我单开一篇给大家细细讲讲,我的文章很长,请大家忍耐一下。
正式开始之前,我们先来说说聚合方法本身的特性(接下来我将用聚合方法代指终结操作中的方法):
-
聚合方法代表着整个流计算的最终结果,所以它的返回值都不是Stream。
-
聚合方法返回值可能为空,比如filter没有匹配到的情况,JDK8中用Optional来规避NPE。
-
聚合方法都会调用evaluate方法,这是一个内部方法,看源码的过程中可以用它来判定一个方法是不是聚合方法。
ok,知晓了聚合方法的特性,我为了便于理解,又将聚合方法分为几大类:
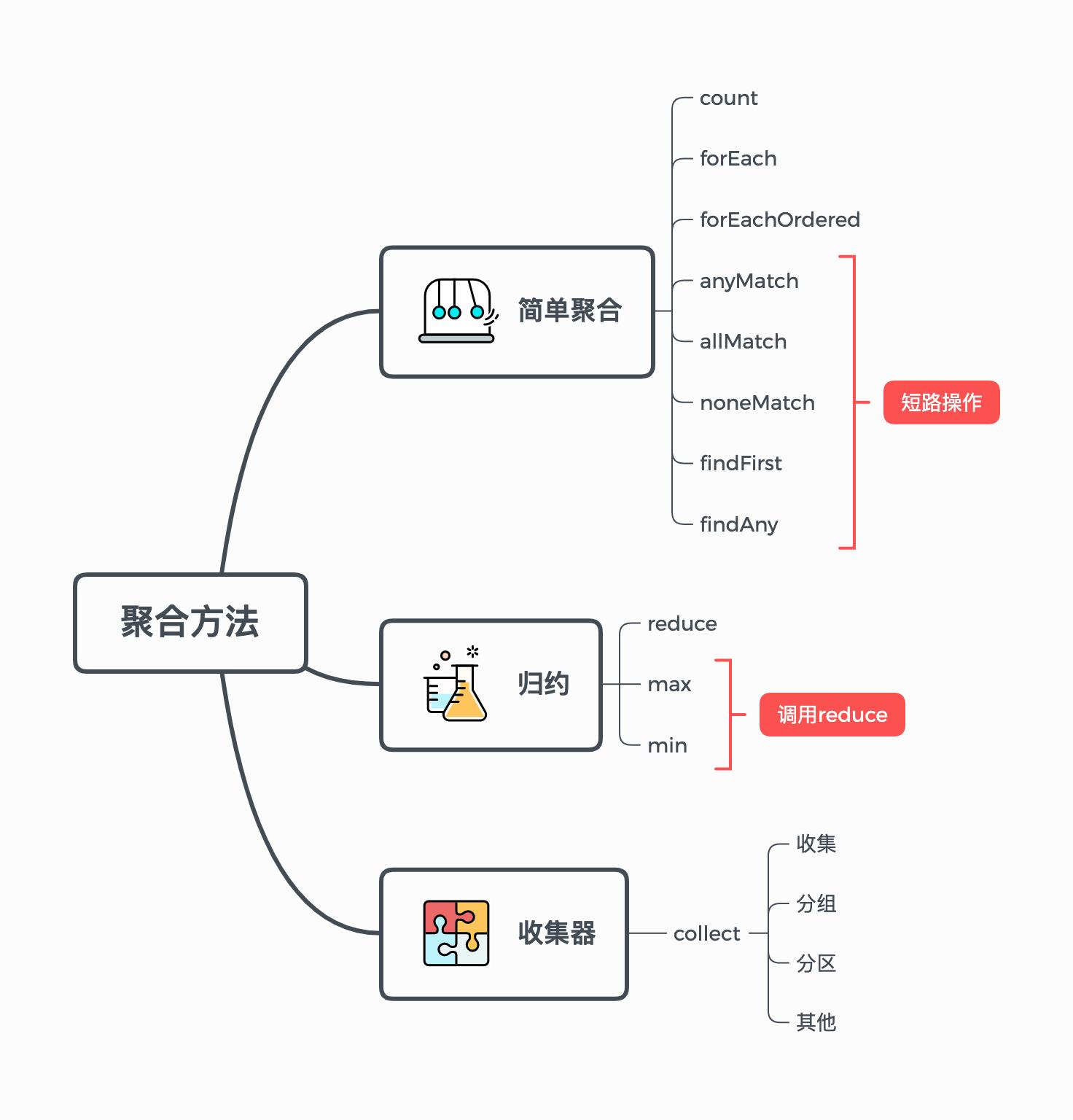
其中简单聚合方法我会简单讲解,其它则会着重讲解,尤其是收集器,它能做的实在太多了。。。
Stream的聚合方法是我们在使用Stream中的必用操作,认真学习本篇,不说马上就能对Stream得心应手,起码也可以行云流水吧😄

1. 简单聚合方法
第一节嘛,先来点简单的。
Stream的聚合方法比上一篇讲过的无状态和有状态方法都要多,但是其中也有一些是喵一眼就能学会的,第一节我们先来说说这部分方法:
-
count():返回Stream中元素的size大小。 -
forEach():通过内部循环Stream中的所有元素,对每一个元素进行消费,此方法没有返回值。 -
forEachOrder():和上面方法的效果一样,但是这个可以保持消费顺序,哪怕是在多线程环境下。 -
anyMatch(Predicate predicate):这是一个短路操作,通过传入断言参数判断是否有元素能够匹配上断言。 -
allMatch(Predicate predicate):这是一个短路操作,通过传入断言参数返回是否所有元素都能匹配上断言。 -
noneMatch(Predicate predicate):这是一个短路操作,通过传入断言参数判断是否所有元素都无法匹配上断言,如果是则返回true,反之则false。 -
findFirst():这是一个短路操作,返回Stream中的第一个元素,Stream可能为空所以返回值用Optional处理。 -
findAny():这是一个短路操作,返回Stream中的任意一个元素,串型流中一般是第一个元素,Stream可能为空所以返回值用Optional处理。
虽然以上都比较简单,但是这里面有五个涉及到短路操作的方法我还是想提两嘴:
首先是findFirst()和findAny()这两个方法, 由于它们只需要拿到一个元素就能方法就能结束,所以短路效果很好理解。
接着是anyMatch方法,它只需要匹配到一个元素方法也能结束,所以它的短路效果也很好理解。
最后是allMatch方法和noneMatch,乍一看这两个方法都是需要遍历整个流中的所有元素的,其实不然,比如allMatch只要有一个元素不匹配断言它就可以返回false了,noneMatch只要有一个元素匹配上断言它也可以返回false了,所以它们都是具有短路效果的方法。
2. 归约
2.1 reduce:反复求值
第二节我们来说说归约,由于这个词过于抽象,我不得不找了一句通俗易懂的解释来翻译这句话,下面是归约的定义:
将一个Stream中的所有元素反复结合起来,得到一个结果,这样的操作被称为归约。
注:在函数式编程中,这叫做折叠( fold )。
举个很简单的例子,我有1、2、3三个元素,我把它们俩俩相加,最后得出6这个数字,这个过程就是归约。
再比如,我有1、2、3三个元素,我把它们俩俩比较,最后挑出最大的数字3或者挑出最小的数字1,这个过程也是归约。
下面我举一个求和的例子来演示归约,归约使用reduce方法:
Optional<Integer> reduce = List.of(1, 2, 3).stream()
.reduce((i1, i2) -> i1 + i2);
复制代码首先你可能注意到了,我在上文的小例子中一直在用俩俩这个词,这代表归约是俩俩的元素进行处理然后得到一个最终值,所以reduce的方法的参数是一个二元表达式,它将两个参数进行任意处理,最后得到一个结果,其中它的参数和结果必须是同一类型。
比如代码中的,i1和i2就是二元表达式的两个参数,它们分别代表元素中的第一个元素和第二个元素,当第一次相加完成后,所得的结果会赋值到i1身上,i2则会继续代表下一个元素,直至元素耗尽,得到最终结果。
如果你觉得这么写不够优雅,也可以使用Integer中的默认方法:
Optional<Integer> reduce = List.of(1, 2, 3).stream()
.reduce(Integer::sum);
复制代码这也是一个以方法引用代表lambda表达式的例子。
你可能还注意到了,它们的返回值是Optional的,这是预防Stream没有元素的情况。
你也可以想办法去掉这种情况,那就是让元素中至少要有一个值,这里reduce提供一个重载方法给我们:
Integer reduce = List.of(1, 2, 3).stream()
.reduce(0, (i1, i2) -> i1 + i2);
复制代码如上例,在二元表达式前面多加了一个参数,这个参数被称为初始值,这样哪怕你的Stream没有元素它最终也会返回一个0,这样就不需要Optional了。
在实际方法运行中,初始值会在第一次执行中占据i1的位置,i2则代表Stream中的第一个元素,然后所得的和再次占据i1的位置,i2代表下一个元素。
不过使用初始值不是没有成本的,它应该符合一个原则:accumulator.apply(identity, i1) == i1,也就是说在第一次执行的时候,它的返回结果都应该是你Stream中的第一个元素。
比如我上面的例子是一个相加操作,则第一次相加时就是0 + 1 = 1,符合上面的原则,作此原则是为了保证并行流情况下能够得到正确的结果。
如果你的初始值是1,则在并发情况下每个线程的初始化都是1,那么你的最终和就会比你预想的结果要大。
2.2 max:利用归约求最大
max方法也是一个归约方法,它是直接调用了reduce方法。
先来看一个示例:
Optional<Integer> max = List.of(1, 2, 3).stream()
.max((a, b) -> {
if (a > b) {
return 1;
} else {
return -1;
}
});
复制代码没错,这就是max方法用法,这让我觉得我不是在使用函数式接口,当然你也可以使用Integer的方法进行简化:
Optional<Integer> max = List.of(1, 2, 3).stream()
.max(Integer::compare);
复制代码哪怕如此,这个方法依旧让我感觉到很繁琐,我虽然可以理解在max方法里面传参数是为了让我们自己自定义排序规则,但我不理解为什么没有一个默认按照自然排序进行排序的方法,而是非要让我传参数。
直到后来我想到了基础类型Stream,果然,它们里面是可以无需传参直接拿到最大值:
OptionalLong max = LongStream.of(1, 2, 3).max();
复制代码果然,我能想到的,类库设计者都想到了~
注 :OptionalLong是Optional对基础类型long的封装。
2.3 min:利用归约求最小
min还是直接看例子吧:
Optional<Integer> max = List.of(1, 2, 3).stream()
.min(Integer::compare);
复制代码它和max区别就是底层把 > 换成了 <,过于简单,不再赘述。
3. 收集器
第三节我们来看看收集器,它的作用是对Stream中的元素进行收集而形成一个新的集合。
虽然我在本篇开头的时候已经给过一张思维导图了,但是由于收集器的API比较多所以我又画了一张,算是对开头那张的补充:
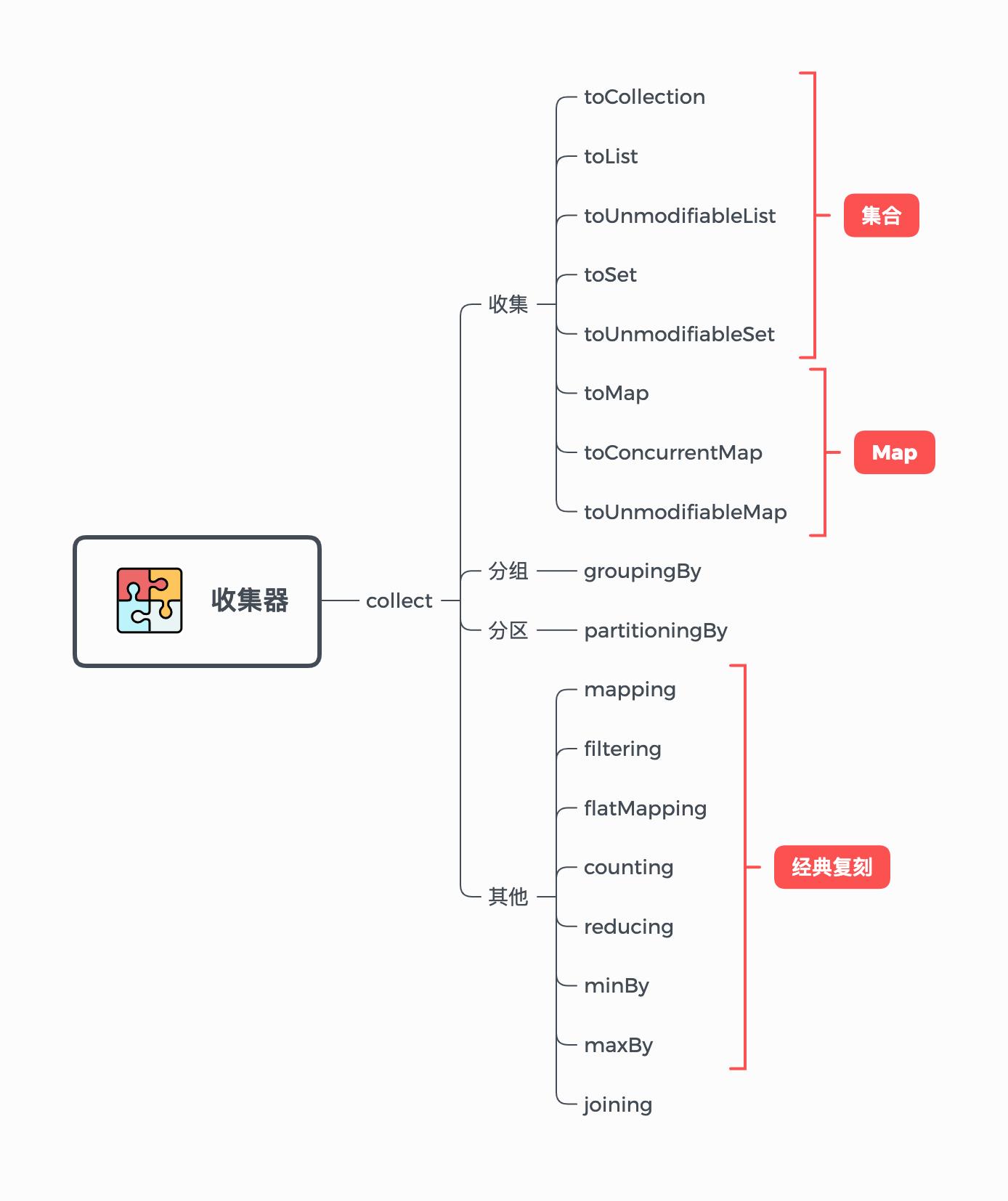
收集器的方法名是collect,它的方法定义如下:
<R, A> R collect(Collector<? super T, A, R> collector);
复制代码顾名思义,收集器是用来收集Stream的元素的,最后收集成什么我们可以自定义,但是我们一般不需要自己写,因为JDK内置了一个Collector的实现类——Collectors。
3.1 收集方法
通过Collectors我们可以利用它的内置方法很方便的进行数据收集:
比如你想把元素收集成集合,那么你可以使用toCollection或者toList方法,不过我们一般不使用toCollection,因为它需要传参数,没人喜欢传参数。
你也可以使用toUnmodifiableList,它和toList区别就是它返回的集合不可以改变元素,比如删除或者新增。
再比如你要把元素去重之后收集起来,那么你可以使用toSet或者toUnmodifiableSet。
接下来放一个比较简单的例子:
// toList
List.of(1, 2, 3).stream().collect(Collectors.toList());
// toUnmodifiableList
List.of(1, 2, 3).stream().collect(Collectors.toUnmodifiableList());
// toSet
List.of(1, 2, 3).stream().collect(Collectors.toSet());
// toUnmodifiableSet
List.of(1, 2, 3).stream().collect(Collectors.toUnmodifiableSet());
复制代码以上这些方法都没有参数,拿来即用,toList底层也是经典的ArrayList,toSet 底层则是经典的HashSet。
也许有时候你也许想要一个收集成一个Map,比如通过将订单数据转成一个订单号对应一个订单,那么你可以使用toMap():
List<Order> orders = List.of(new Order(), new Order());
Map<String, Order> map = orders.stream()
.collect(Collectors.toMap(Order::getOrderNo, order -> order));
复制代码toMap() 具有两个参数:
-
第一个参数代表key,它表示你要设置一个Map的key,我这里指定的是元素中的orderNo。
-
第二个参数代表value,它表示你要设置一个Map的value,我这里直接把元素本身当作值,所以结果是一个Map<String, Order>。
你也可以将元素的属性当作值:
List<Order> orders = List.of(new Order(), new Order());
Map<String, List<Item>> map = orders.stream()
.collect(Collectors.toMap(Order::getOrderNo, Order::getItemList));
复制代码这样返回的就是一个订单号+商品列表的Map了。
toMap() 还有两个伴生方法:
-
toUnmodifiableMap():返回一个不可修改的Map。
-
toConcurrentMap():返回一个线程安全的Map。
这两个方法和toMap() 的参数一模一样,唯一不同的就是底层生成的Map特性不太一样,我们一般使用简简单单的toMap() 就够了,它的底层是我们最常用的HashMap() 实现。
toMap() 功能虽然强大也很常用,但是它却有一个致命缺点。
我们知道HahsMap遇到相同的key会进行覆盖操作,但是toMap() 方法生成Map时如果你指定的key出现了重复,那么它会直接抛出异常。
比如上面的订单例子中,我们假设两个订单的订单号一样,但是你又将订单号指定了为key,那么该方法会直接抛出一个IllegalStateException,因为它不允许元素中的key是相同的。
3.2 分组方法
如果你想对数据进行分类,但是你指定的key是可以重复的,那么你应该使用groupingBy 而不是toMap。
举个简单的例子,我想对一个订单集合以订单类型进行分组,那么可以这样:
List<Order> orders = List.of(new Order(), new Order());
Map<Integer, List<Order>> collect = orders.stream()
.collect(Collectors.groupingBy(Order::getOrderType));
复制代码直接指定用于分组的元素属性,它就会自动按照此属性进行分组,并将分组的结果收集为一个List。
List<Order> orders = List.of(new Order(), new Order());
Map<Integer, Set<Order>> collect = orders.stream()
.collect(Collectors.groupingBy(Order::getOrderType, toSet()));
复制代码groupingBy还提供了一个重载,让你可以自定义收集器类型,所以它的第二个参数是一个Collector收集器对象。
对于Collector类型,我们一般还是使用Collectors类,这里由于我们前面已经使用了Collectors,所以这里不必声明直接传入一个toSet()方法,代表我们将分组后的元素收集为Set。
groupingBy还有一个相似的方法叫做groupingByConcurrent(),这个方法可以在并行时提高分组效率,但是它是不保证顺序的,这里就不展开讲了。
3.3 分区方法
接下来我将介绍分组的另一种情况——分区,名字有点绕,但意思很简单:
将数据按照TRUE或者FALSE进行分组就叫做分区。
举个例子,我们将一个订单集合按照是否支付进行分组,这就是分区:
List<Order> orders = List.of(new Order(), new Order());
Map<Boolean, List<Order>> collect = orders.stream()
.collect(Collectors.partitioningBy(Order::getIsPaid));
复制代码因为订单是否支付只具有两种状态:已支付和未支付,这种分组方式我们就叫做分区。
和groupingBy一样,它还具有一个重载方法,用来自定义收集器类型:
List<Order> orders = List.of(new Order(), new Order());
Map<Boolean, Set<Order>> collect = orders.stream()
.collect(Collectors.partitioningBy(Order::getIsPaid, toSet()));
复制代码3.4 经典复刻方法
终于来到最后一节了,请原谅我给这部分的方法起了一个这么土的名字,但是这些方法确实如我所说:经典复刻。
换言之,就是Collectors把Stream原先的方法又实现了一遍,包括:
-
map →
mapping -
filter →
filtering -
flatMap →
flatMapping -
count →
counting -
reduce →
reducing -
max →
maxBy -
**min ** →
minBy
这些方法的功能我就不一一列举了,之前的文章已经讲的很详尽了,唯一的不同是某些方法多了一个参数,这个参数就是我们在分组和分区里面讲过的收集参数,你可以指定收集到什么容器内。
我把它们抽出来主要想说的为什么要复刻这么多方法处理,这里我说说个人见解,不代表官方意见。
我觉得主要是为了功能的组合。
什么意思呢?比方说我又有一个需求:使用订单类型对订单进行分组,并找出每组有多少个订单。
订单分组我们已经讲过了,找到其每组有多少订单只要拿到对应list的size就行了,但是我们可以不这么麻烦,而是一步到位,在输出结果的时候键值对就是订单类型和订单数量:
Map<Integer, Long> collect = orders.stream()
.collect(Collectors.groupingBy(Order::getOrderType, counting()));
复制代码就这样,就这么简单,就好了,这里等于说我们对分组后的数据又进行了一次计数操作。
上面的这个例子可能不对明显,当我们需要对最后收集之后的数据在进行操作时,一般我们需要重新将其转换成Stream然后操作,但是使用Collectors的这些方法就可以让你很方便的在Collectors中进行数据的处理。
再举个例子,还是通过订单类型对订单进行分组,但是呢,我们想要拿到每种类型订单金额最大的那个,那么我们就可以这样:
List<Order> orders = List.of(new Order(), new Order());
Map<Integer, Optional<Order>> collect2 = orders.stream()
.collect(groupingBy(Order::getOrderType,
maxBy(Comparator.comparing(Order::getMoney))));
复制代码更简洁,也更方便,不需要我们分组完之后再去一一寻找最大值了,可以一步到位。
再来一个分组之后,求各组订单金额之后的:
List<Order> orders = List.of(new Order(), new Order());
Map<Integer, Long> collect = orders.stream()
.collect(groupingBy(Order::getOrderType, summingLong(Order::getMoney)));
复制代码不过summingLong这里我们没有讲,它就是一个内置的请和操作,支持Integer、Long和Double。
还有一个类似的方法叫做averagingLong看名字就知道,求平均的,都比较简单,建议大家没事的时候可以扫两眼。
该结束了,最后一个方法joining(),用来拼接字符串很实用:
List<Order> orders = List.of(new Order(), new Order());
String collect = orders.stream()
.map(Order::getOrderNo).collect(Collectors.joining(","));
复制代码这个方法的方法名看着有点眼熟,没错,String类在JDK8之后新加了一个join() 方法,也是用来拼接字符串的,Collectors的joining不过和它功能一样,底层实现也一样,都用了StringJoiner类。
4. 总结
终于写完了。
在这篇Stream中终结操作中,我提了Stream中的所有聚合方法,可以说你看完了这篇,Stream的所有聚合操作就掌握个七七八八了,不会用没关系,就知道有这个东西了就行了,不然在你的知识体系中Stream根本做不了XX事,就有点贻笑大方了。
当然,我还是建议大家在项目中多多用用这些简练的API,提升代码可读性,也更加简练,被review的时候也容易让别人眼前一亮~
以上是关于归约分组与分区,深入讲解JavaStream终结操作的主要内容,如果未能解决你的问题,请参考以下文章