JVM内存溢出原理及案例分析
Posted 七月的小尾巴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM内存溢出原理及案例分析相关的知识,希望对你有一定的参考价值。
前言
再程序中,什么是内存溢出呢?什么情况下会出现内存溢出呢?
内存溢出原理
一般来说,程序中出现内存溢出是非常严重的,一但出现内存溢出,会导致程序无法正常运行。一般再程序中,内存溢出分为两种:一种是 堆内存溢出。一种是永久代溢出。
-
堆内存溢出:
堆内存中存在大量的对象,这些对象都被引用,当所有对象占用空间达到堆内存的最大值,就会出现内存溢出OutOfMemory:java heap space
其实当内存满的时候,程序会触发GC,但是GC之后发现内存都被占用无法进行回收,导致无法腾出空间,内存空间不足,这个时候就会内存溢出。 -
永久代溢出:
类的一些信息,如类名、访问修饰符、字段描述、方法描述等,所占用空间大于永久代最大值,就会出现OutOfMemoryError:PermGen space
永久代溢出的情况通常来说非常少见,会有一种情况就是假设我们代码中的一些静态对象本身就又100M,但是我们只给他分配了50M,内存不够用,那么再启动的时候,就会报错内存溢出。这个问题非常好解决,我们只需要加大永久代的内存即可。
JAVA8移除了永久代,使用了元空间替代,所以JAVA8之后就没有永久代溢出了。
通常出现堆内存,都是程序中代码的设计存在一定问题,哪怕你加大堆内存,但是只能暂时性的缓解,但是内存溢出只是时间问题。
内存溢出的检测方法
jdk/bin 目录下提供了非常多的内存溢出的图形化监控工具,如 Jconsole、 Jvisualvm。或者我们也可以通过命令行的形式进行检测。
Jstat -gcutil pid 1000 100
Jmap -histo pid|head -20
Jmao -heap pid
// FullGC 频率:建议单次FullGC时间<200ms,如果说FullGC超过200ms,是有一定的优化空间的。
注意这里指的是FullGC,不是YoungGC
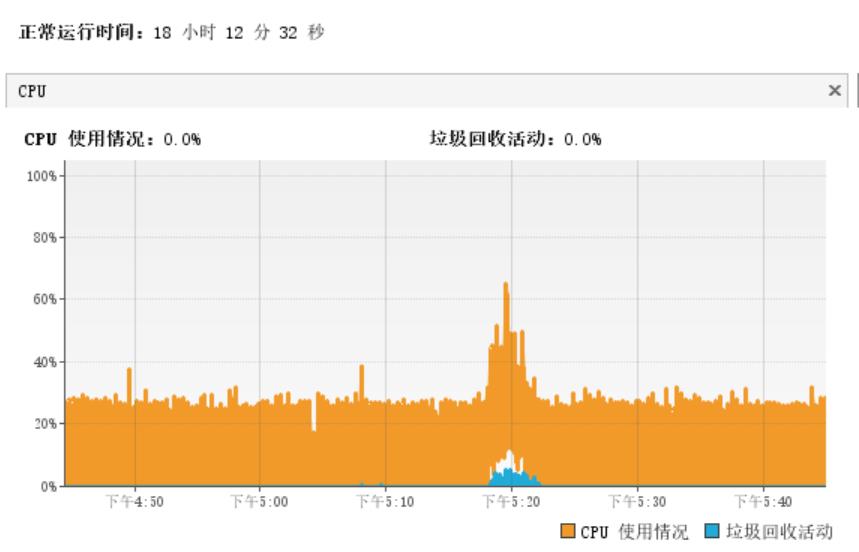
下面我们可以看下方这张图,这张图主要是监控CPU和垃圾回收活动的一张关系图。我们可以看到正常情况下,我的cpu是非常平稳的,但是当程序中出现了一次GC(下方图中的蓝色区域),CPU会高。那么我们可以由此知道,当程序中出现GC的情况下,CPU也会发生一定的波动。 FullGC的话,cpu波动还会更大。
因此如果我们程序再某一个时间段的波动特别大的情况下,可能是因为它正在做GC。同理当我们发现响应时间、TPS的波动特别大的情况下,也有可能是因为GC,因此我们要做性能监控和分析。
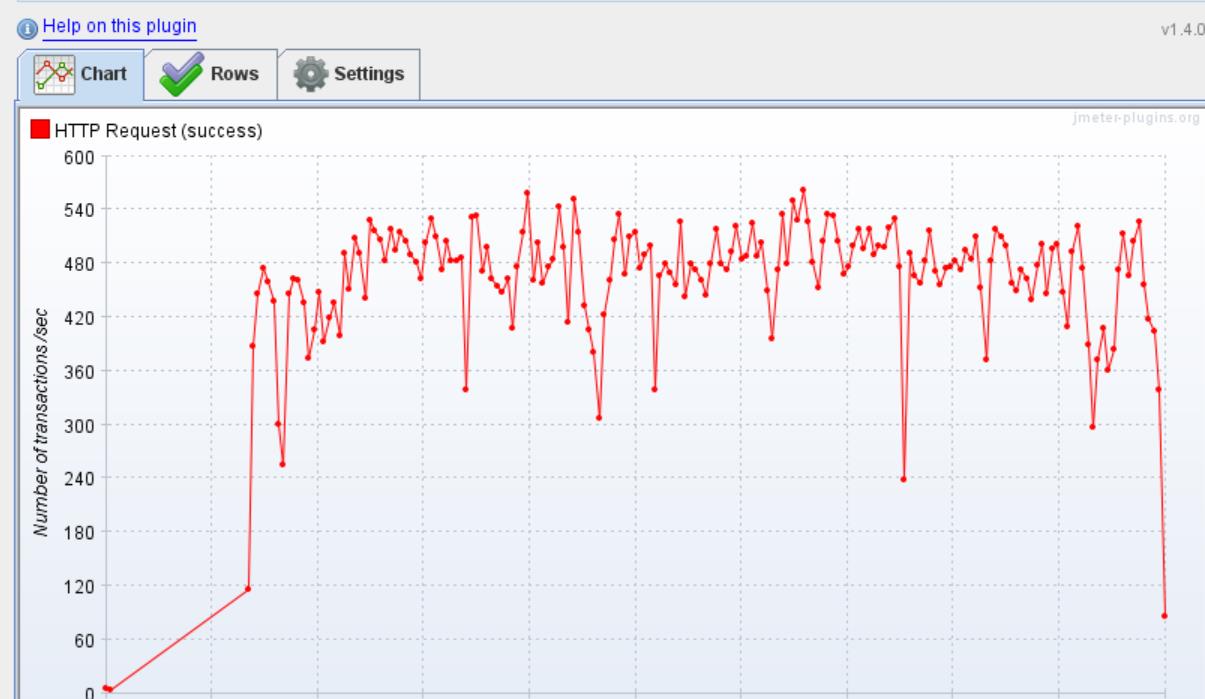
可以看到程序再做GC的时候,这张TPS折线图,TPS也是非常不稳定的,有时候甚至降到240。
JVM相关参数配置说明
- Xms2048m,初始堆大小,因为JVM配置的堆内存越大,则垃圾回收的时间越长,因此一般建议小于物理内存的1/4,默认值为物理内存的1/64
- Xmx2048,最大堆内存,建议与-Xms保持一致,默认值为物理内存的1/4
- Xmn512m: 新生代大小,建议不超过堆内存的1/2
- Xss256k,线程堆堆大小,建议512k或者1024k,之前遇到一个问题就是配置的堆内存太小,导致项目无法正常启动
- XX:Permsize=256m,永久代初始值,默认值为物理内存的1/64,如果是JAVA8以上的话,参数需要对应的改变。
- XX:MaxPermSize=256m,永久代最大值,默认值为物理内存的1/4
- XX:SurvivorRatio=8:年轻代中Eden区和Survior区的比例,默认为8:1,即Eden(8)
From Space(1), ToSpace(1)
- XX:+UseConcMarkSweepGC:开启CMS垃圾回收器
- XX:MaxTenuringThreshold=15:晋升到老年代的对象年龄,每个对象坚持过一次MinorGC后对象年龄+1,默认值是15,年龄超过15就会进入老年代,改参数在串行GC时有效
- XX:PretenureSizeTgreshould=3145728:单位字节,只对Serial和ParNew两款收集器有效,新生代采用Parallel Scavenge GC时有效,大于这个值的对象直接在老年代进行分配。
1、上方建议堆内存初始大小和堆内存大小建议保持一致的主要原因是,因为假设我们初始内存是1G,最大内存是2G,那么当我们初始内存不够用的情况下,系统会进行一次扩容,一次扩容会设计到内存的重新分配和技术,扩容一次会导致性能下降,因此为了避免这个问题,我们将初始内存和最大内存设置的一致,这样就不会进行扩容。
2、如果你的是Java8以上的话,java8从JVM移除了PermGen(永久代),使用Metaspace(元空间)来替代永久代,需要更改配置
-XX:MetaspaceSize = 256m
-XX: MAXMetaspace = 256m
CMS相关参数
-XX:+UseConcMarkSweepGC:默认关闭,ParNew+CMS+Serial old,当CMS收集器出现,ConcurrentModeFailure错误(JVM预留空间不足以容纳程序使用)采用后备收集器SerialOld
-XX:CMSInitiatingOccua=pancyFraction=80:CMS收集器在老年代空间使用多少时触发FullGC,默认为92
-XX:+UseCMSCompactAtFullCollention:CMS收集器在fullGC是开启内存碎片的压缩,默认关闭
-XX:CMSFullGCBeforeCompaction=8:执行多少次不压缩FullGC后,进行一次压缩,默认是0(代表每次FullGC都进行压缩)
-XX:+UseCMSInitiatingOccpancyOnly:使用手动定义初始化定义开始,禁止hostpot自行触发CMS GC
-XX:ParallelGCThreads=8:并发手机器的线程数,此值最好配置与处理数目相等,同样适用于CMS
日志参数
-XX:+HeapDumpOnOutOfMemoryError:当发生内存溢出时,进行堆内存dunp-XX:+PrintGCDetails:打印GC的详细信息
在做稳定性测试的时候,会非常容易出现内存溢出,有可能跑十几个小时出现内存溢出的时候,我们并没有关注到,这个时候就可以配置日志,生成dump文件。
命令行监控内存溢出
监控JVM GC情况
jstat -gcutil pid 1000 100
// 其中1000是ms单位,指的是一秒,100指的是监控次数
// 这个命令指的就是监控一秒内监控100次JVM的GC情况
首先我们用greo命令获取tomcat的进程ID,然后通过上方命令行监控JVM的GC情况。
这里的监控数据,需要堆JVM有一定的了解,如果不清楚,可以看我的这篇博客:链接: 《JVM内存结构和垃圾回收机制》.
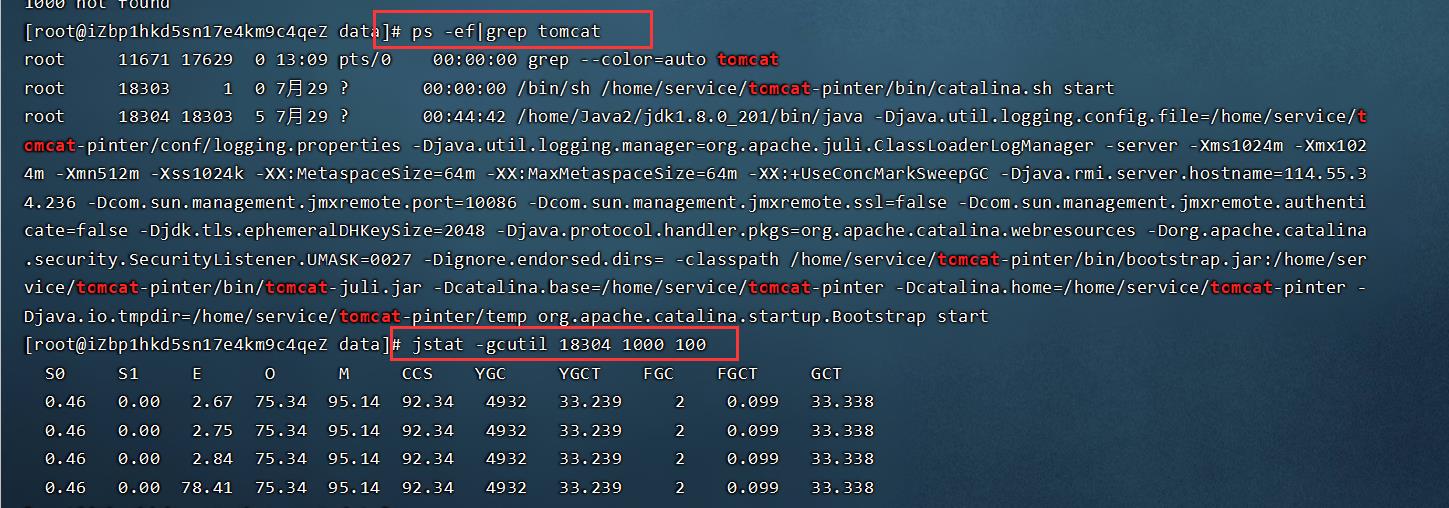
参数说明:
- S0、S1:主要是新生代中的survivor区域,当新生代中Eden区域内存不足的时候,会做一次GC,主要会清理Eden 和 S0或S1区域的内存数据。以KB为单位
- E:指的是新生代中的Eden,以KB为单位
- O:指的是old
- M:metespace
- YGC:YoungGC 的次数
- FGC:FullGC 的次数
- YFCT:YoungGC所花费的时间,如上方图中,我们的YGCT总共用了33m左右,一共执行了4932次,那么平均每次所用的时间6.6ms左右
- FGCT:指的FullGC所用的时间,可以从上方图中看出,我的FGC就执行了2次,但是用了0.099m,平均每次FGC用的时间大概实在49.5ms左右,由此可见,FGC的处理速度是非常慢的,我们程序需要尽量避免FGC
- GCT:YGC+FGC所用的总共时间
内存溢出案例分析
图形化工具监控:
这里我们监控JVM,用到的是JDK中提供的图形化监控工具, Jvisualvm。关于这个工具的使用,大家可以看这篇博客:链接: 《JAVA进程监控》
下面我们来针对一个接口做稳定性测试,通常大部分接口内存溢出的情况都是在稳定性测试中发现的,我们需要在程序运行很长一段时间后才会发现内存溢出的情况。
这是我们程序运行一段时间后,我们可以看到TPS非常不稳定,有时候会从400多降到200多。
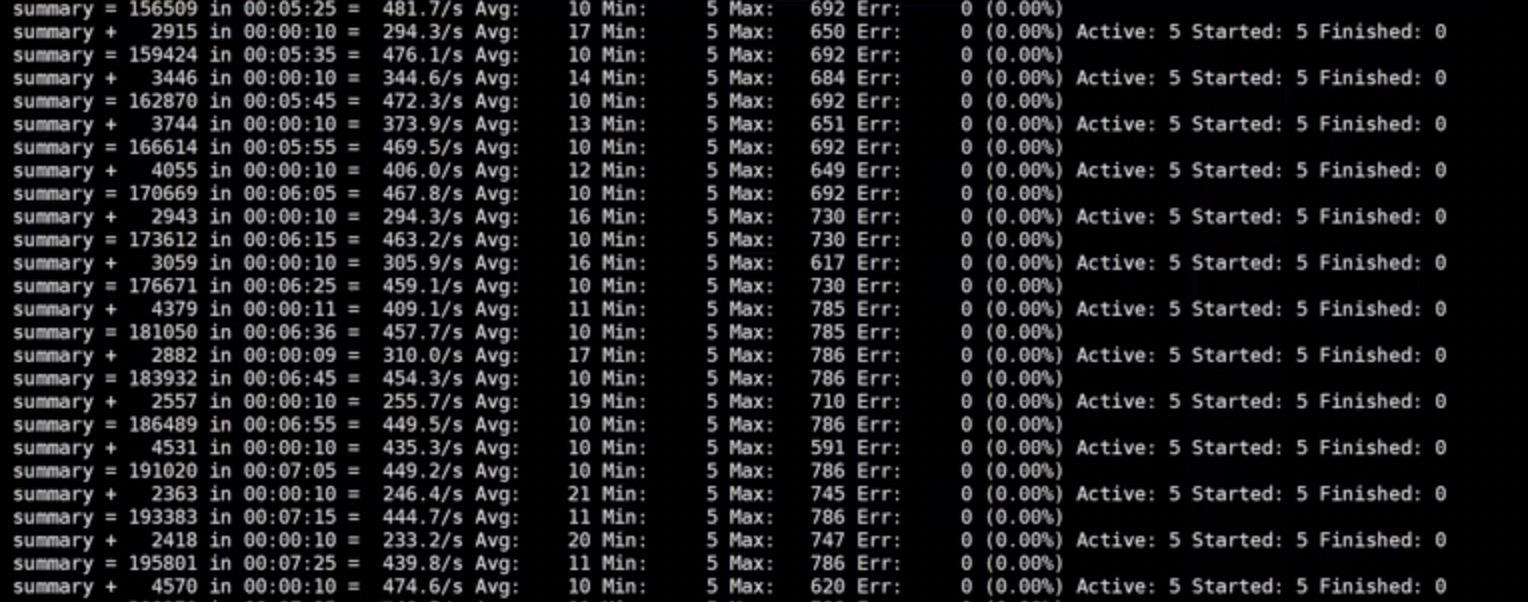
然后我们在看看Jvisualvm工具检测到情况。
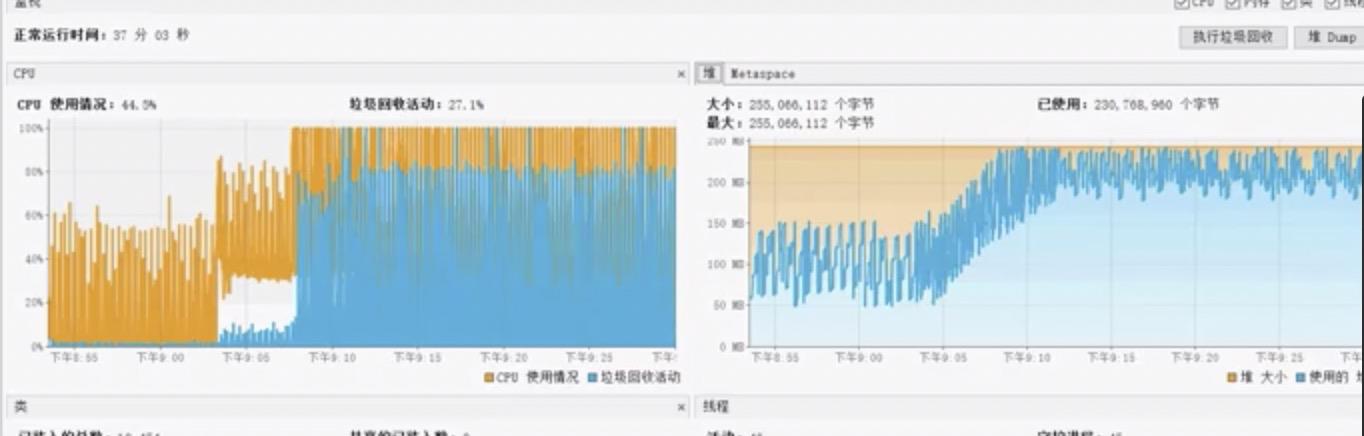
可以发现程序在频繁的进行GC,并且cpu也非常高了。我们来看右边的堆内存折线图,可以看到前面还是非常平缓有规律的,但是到后面,波动就变的非常大,通常这种情况,我们就需要判断是否出现了内存溢出的情况。
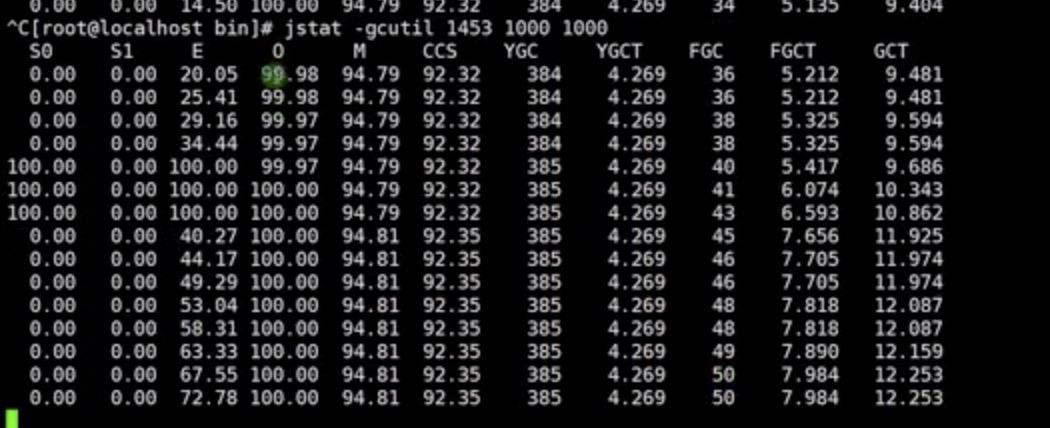
下面我们在应用服务器上输入我们前面说到的jstat -gcutil pid 1000 100来查看YoungGC和FullGC的情况。打印出来的信息中我们可以看到old区域的内存已经100%满了,并且程序在频繁的执行FullGC,这种情况下,通常是有一定问题的,我们需要进行排查。
我们之前说过出现内存溢出的主要原因是因为有大量的内存存在堆内存中无法被回收,从而占满整个堆内存。那么我们可以沿着这个思路,去查看堆内存中哪些对象最多,那么这个就最有可能是我们内存溢出的罪魁祸首。
首先我们可以使用如下命令,查看jvm中类和对象的占用情况
jmap -histo pid|head -20
这个会把我们当前jvm中占用最多的20个类给打印出来。
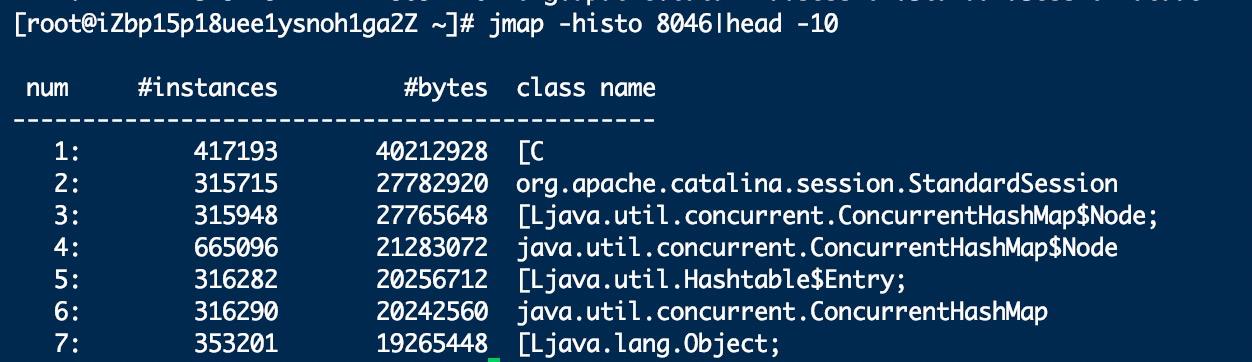
classname 中出现带中括号的都是一个数组。[C 指的是char[],通常java.util之类的都是jdk底层的我们不太需要关注,筛选出来剩下的,我们可以让开发排查他的业务代码,这个类是否有存在问题。
或者通过Jvisualvm,进行远程堆dump,然后把dump文件下载下来,用jvisualvm打开进行分析,可以看到更直观的jvm中对象信息。
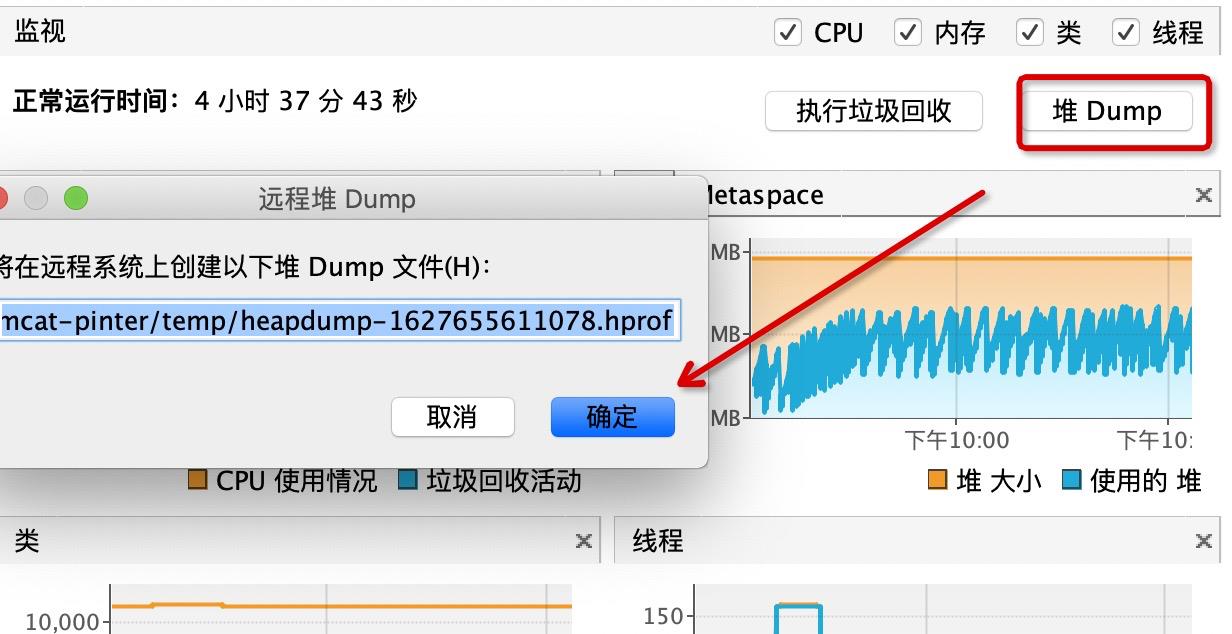
上方会提示把堆dump的文件下载到了tomcat的temp目录下。下面我们去Linux上可以看到temp文件下确实有个文件。

我们把这个文件下载到桌面然后打开,可以使用sz命令,但是这个命令需要安装,具体的可以看我之前的博客,或者百度。

选择我们刚下载下来的dump文件,打开,选择堆dump格式打开。
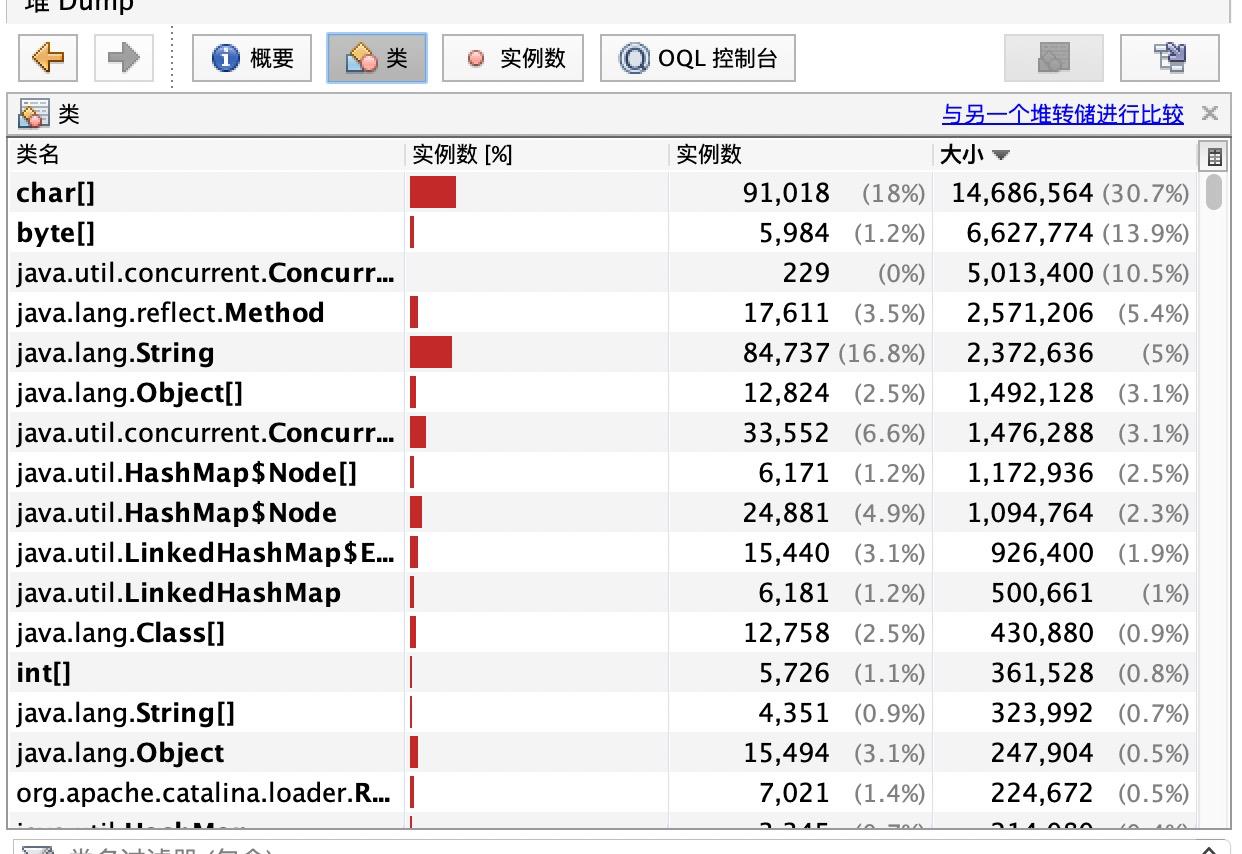
打开之后,我们可以点击类,下面我们可以筛选大小,看到占用内存最多的前几个类,这个和我们命令行模式下看到的数据是一样的。
下载堆文件dump还可以通过命令行的方式保存下来
jmap -dump:format=b,file=m.hdump pid
这个命令是对堆内存进行dump,以文件的形式进行保存下来,可以用jvisualvm等工具对文件进行分析。这个和前面的效果是一样的。
总结
从上面的观察中,我们可以总结出来内存泄露出现的现象,主要有以下这些:
- tps出现大幅度波动,并且慢慢降低,甚至降低到0,并且响应时间也随之波动,慢慢升高
- 通过
jstat命令可以看到,JVM中的old区域不断增减,FullGC非常频繁,对应的FullGC消耗的时间也不断增加。 - 通过
Jvisualvm可以看到,堆内存曲线不断上升,接近上限时,会变成一条直线。 - 日志报错:
java.lang.OutOfMemoryError:Java heap space - 在稳定性场景中,一定要关注JVM内存使用的情况,在长时间压测下,最容易出现内存溢出的问题。
以上是关于JVM内存溢出原理及案例分析的主要内容,如果未能解决你的问题,请参考以下文章