第一课第一周大作业-胸部14种疾病分类-代码详解
Posted Tina姐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一课第一周大作业-胸部14种疾病分类-代码详解相关的知识,希望对你有一定的参考价值。
深度学习胸部 X 射线诊断
本次作业文件:在第一课/第一课大作业/week1classification

欢迎来到课程 1 的第一个作业!
在这个任务中!您将通过使用 Keras 构建最先进的胸部 X 射线分类器来探索医学图像诊断。
你将学会一下内容:
- 预处理真实世界的 X 射线数据集
- 使用迁移学习重新训练 DenseNet 模型以进行 X 射线图像分类
- 学习一种处理类别不平衡的技术
- 通过计算 ROC 曲线的 AUC(曲线下面积)来衡量诊断性能
- 使用 GradCAM 可视化模型激活区域
作业目录
-
- 导入包和函数
-
- 加载数据集
- 2.1 防止数据泄露
- 练习 1 - 检查数据泄漏
- 2.2 准备图像
-
- 模型开发
- 3.1 解决类不平衡问题
- 练习 2 - 计算类频率
- 练习 3 - 加权损失
- 3.2 DenseNet121
- 4.training【可选】
- 4.1 在更大的数据集上训练
-
- 预测与评估
- 5.1 ROC 曲线和 AUROC
- 5.2 使用 GradCAM 可视化学习
注意: 在作业文件中,可以直接跳转到你感兴趣的章节。
导入包部分省略
1.3 数据集 (这里的序号对应代码里的序号)
对于这项任务,我们将使用 ChestX-ray8 数据集,其中包含 32717 名患者的 108,948 张正面 X 射线图像。
数据集中的每个图像都包含多个文本挖掘标签,可识别 14 种不同的病理状况。
这些反过来又可以被医生用来诊断 8 种不同的疾病。
我们将使用这些数据开发一个单一模型,该模型将为 14 种标记病理中的每一种提供二元分类预测。
换句话说,它将预测每种病理的“阳性”或“阴性”。
注意: 该数据集并不好下载,官网需提供邮箱,会把数据集链接发你邮箱,而且数据集较大。
我们为您提供了大约 1000 个图像子集。这些可以在存储在IMAGE_DIR变量中的文件夹路径中访问。
使用的图像可在下面三个csv文件里找到:
- nih/train-small.csv:来自我们数据集中的 875 张图像用于训练。
- nih/valid-small.csv:来自我们数据集中的 109 张图像用于验证。
- nih/test.csv:来自我们数据集中的 420 张图像用于测试。
如果你下载这部分数据集有困难,也可以不训练,我们已经提供了训练好的模型,可以直接测试。
1.3.0.1 class单词的含义
值得注意的是,在这些讨论中,'class'(类)一词多用。注意区别
-
我们有时将数据集中标记的 14 种病理状况中的每一种都称为一个类。
-
但是对于这些病理中的每一种,我们都试图预测某种情况是存在(即阳性结果)还是不存在(即阴性结果)。“正”或“负”(或 1 或 0 的数字物)这两个可能的标签通常也称为类。如正类和父类
-
此外,我们还使用该术语来指代 代码“类”,例如ImageDataGenerator类.
不过,从使用它的上下文中就应该能明白。
1.4.1 解决类不平衡
使用医疗诊断数据集的挑战之一是此类数据集中存在的大类不平衡。让我们绘制数据集中每个标签的频率:
plt.xticks(rotation=90)
plt.bar(x=labels, height=np.mean(train_generator.labels, axis=0))
plt.title("Frequency of Each Class")
plt.show()
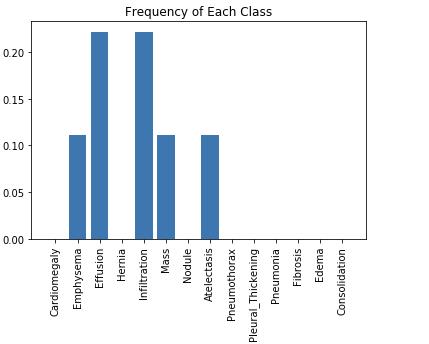
我们可以从这个图中看到,阳性病例的流行率在不同的病理中存在显着差异。
- 在Hernia(疝气)病理有积极的训练情况是约0.2%的比例最大的失衡。
- 但即使Infiltration(渗透)是不平衡最少的病理学,也只有 17.5% 的训练案例被标记为阳性。
理想情况下,我们将使用均衡的数据集训练我们的模型,以便正负训练案例对损失的贡献相等。
如果我们使用具有高度不平衡数据集的正常交叉熵损失函数,正如我们在这里看到的那样,那么算法将优先优化多数类(即在我们的例子中为阴性类),因为它对损失的贡献更大。
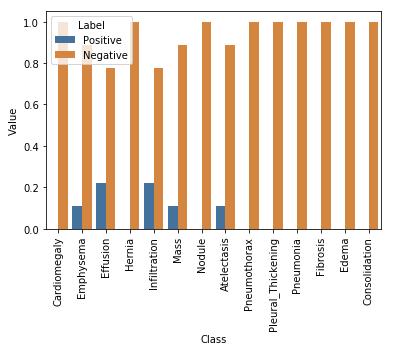
这里就要使用之前学过的类平衡方法(参见之前的教程,或者本节查看代码)
数据平衡前
数据平衡后
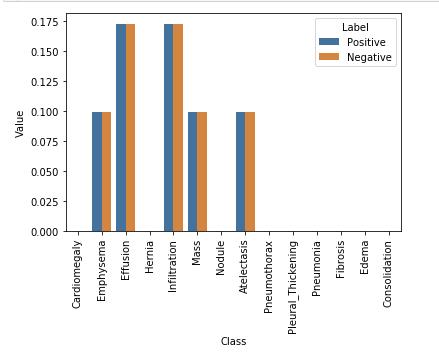
1.4.4 使用DenseNet121进行迁移学习
接下来,我们将使用预训练的 DenseNet121 模型,我们可以直接从Keras加载该模型,然后在其上添加两层:
- 一个
GlobalAveragePooling2D层从DenseNet121获得平均的最后一圈层。 - 一个
Dense具有sigmoid激活层的层,用于获取我们每个类的预测对数。
我们可以通过loss在compile()函数中指定参数来为模型设置我们的自定义损失函数。
# create the base pre-trained model
base_model = DenseNet121(weights='./nih/densenet.hdf5', include_top=False)
x = base_model.output
# add a global spatial average pooling layer
x = GlobalAveragePooling2D()(x)
# and a logistic layer
predictions = Dense(len(labels), activation="sigmoid")(x)
model = Model(inputs=base_model.input, outputs=predictions)
model.compile(optimizer='adam', loss=get_weighted_loss(pos_weights, neg_weights))
模型的训练省略~~~~,感兴趣可以训练来看看
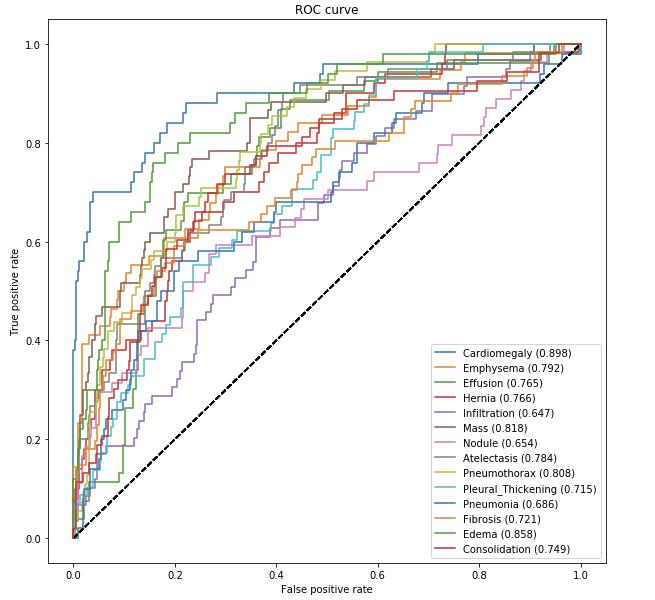
1.6.1 ROC 曲线 和 AUROC
现在我们将逐步介绍从 接收者操作特性 (Receiver Operating Characteristic, ROC) 曲线计算 曲线下面积(Area Under the Curve, AUC,也称为 AUROC 值)。
在 util.py 中的 util.get_roc_curve() 函数中提供了计算方法。这里直接调用
auc_rocs = util.get_roc_curve(labels, predicted_vals, test_generator)
1.6.2 使用GRAD-CAM 可视化
功能函数同样在 util.py 中提供。
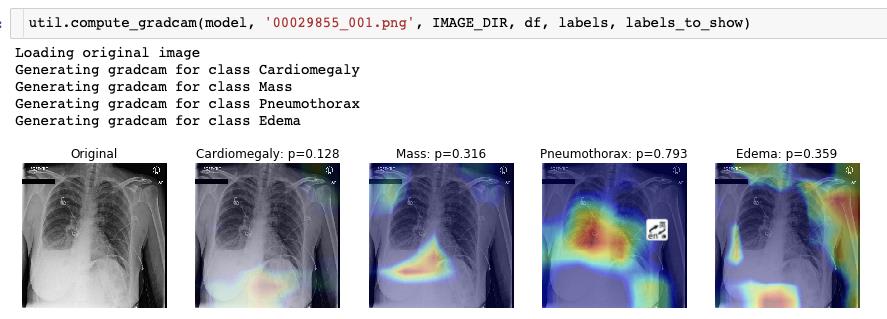
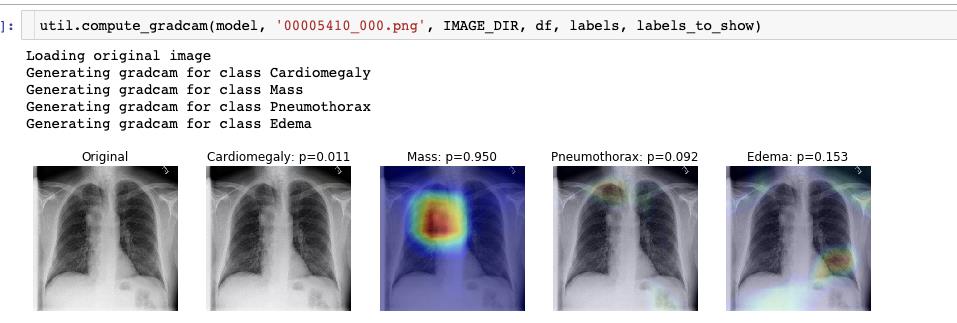
这部分大作业涉及到的内容自然是很多的,可能需要话3-7天的时间去细细咀嚼。本文只是把作业中涉及到的部分做一个展示,细节内容还是要自己看代码的。

文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持已实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连

以上是关于第一课第一周大作业-胸部14种疾病分类-代码详解的主要内容,如果未能解决你的问题,请参考以下文章