吴恩达-第一课第二周1-7节总结-医学深度学习模型的评估汇总
Posted Tina姐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴恩达-第一课第二周1-7节总结-医学深度学习模型的评估汇总相关的知识,希望对你有一定的参考价值。
医学深度学习模型的评估汇总
本周我们将深入探讨医学深度学习模型的评估。在医学上,由于决策具有很高的影响力,我们关心的是准确地了解模型何时对患者起作用,什么时候不起作用。
您将学习一下指标,包括:敏感性(sensitivity)、特异性(specificity)、预测值(predictive values)和ROC曲线。
这些是评估医疗环境中模型的 关键因素。在这节课中,我们首先讨论度量的准确性。从准确度的角度来看,我们将了解如何在医学评估中得出核心概念的敏感性和特异性。
在本课的第二部分,我们将讨论预测值,它可以帮助医疗专业人员进行临床决策。
accuracy
为了回答一个模型有多好的问题,我们将从准确度(accuracy)开始。
当计算测试集的准确度时,我们会考虑模型正确分类的总样本的比例。
A
c
c
u
r
a
c
y
=
正
确
分
类
的
样
本
总
样
本
Accuracy = \\frac{正确分类的样本}{总样本}
Accuracy=总样本正确分类的样本
让我们用一个例子来说明准确度的计算。

这里我们有10个例子的测试集。其中8个normal,2个disease。
假设我们有一个模型,对所有10个病人都是阴性的(normal)。这当然不是一个有用的模型,但请注意,它使所有正常的例子都是正确的。
因此,10个例子中有8个是正确的,精确度为0.8。

新增一个模型2,正确地预测了两个疾病实例的阳性,也将其中两个正常的例子预测为阳性。现在我们可以计算模型2的精度,我们会再一次发现,10个例子中有8个是正确的,模型2的精度是0.8。
所以我们有两个精度为0.8的模型。尽管我们还没有对此进行正式化,但我们感觉到模型2可能比模型1更有用,因为它至少试图区分健康和疾病患者。
条件概率准确度
让我们进一步了解一下精度指标。我们将了解如何使用准确度来导出其他有用的评估指标,如敏感性和特异性。

首先,我们将把准确性解释为模型预测正确的概率。我们可以把这个概率分解为两个概率之和。即模型预测正确且患者患有疾病的概率 + 模型正确且患者正常的概率。
条件概率定律允许我们进一步扩展。作为提醒,条件概率定律说,a和B的概率是给定B的概率乘以B的概率(如图)。
我们可以将其应用于第一项将其展开到此处,并将其应用于第二项将其展开到此处。我们可以解释这些术语。如果患者患有该病,则正确的概率意味着我们预测为阳性。

所以我们可以用假设病人有疾病时预测阳性的概率来代替这个。同样,当病人正常时,正确的概率意味着我们预测了阴性,所以我们可以用假定病人正常时预测阴性的概率来代替这个(最后一个公式)。
看似有点绕,多读两遍就理解了
敏感性-特异性-患病率
上个图中,箭头指出两个非常重要的指标,即敏感性(真阳性率)和特异性(真阴性率)。
敏感性:在所有患病的人数中,有多少患者被预测出来。
特异性:在所有正常的患者中,有多少患者预测出来的也是正常。
患病率(prevalence):一个病人在人群中患病的概率称为患病率。
正常的概率就是1减去患病的概率或者1减去患病率。
因此,我们可以根据敏感性、特异性和患病率得到准确度。
准
确
度
=
敏
感
性
∗
患
病
率
+
特
异
性
∗
(
1
−
患
病
率
)
准确度=敏感性*患病率 + 特异性*(1-患病率)
准确度=敏感性∗患病率+特异性∗(1−患病率)
为什么这个有用?这个方程使我们可以把准确度看作是敏感性和特异性的加权平均值。与敏感性相关的权重为患病率,与特异性相关的权重为1-患病率。
让我们用一个例子来看看。
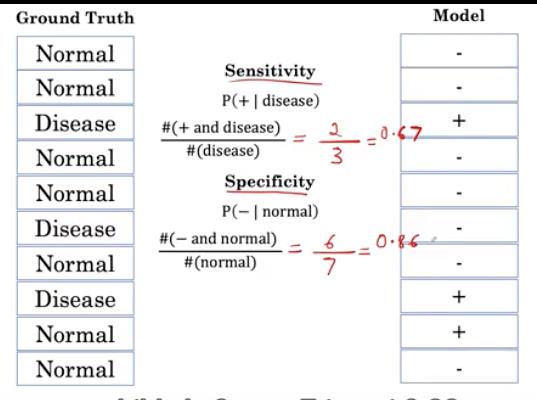
首先,我们计算敏感度。
- 敏感度的分子为:ground truth中为疾病的,同时在model中是”+“的个数为2
- 敏感度的分母为:ground truth中为疾病的总数=3
- 特异性的分子为: ground truth中为正常的,同时在model是”—“的个数为6
- 特异性的分母为:ground truth中为正常的总数=7
这就是敏感性和特异性的计算。

现在让我们来看看这组人群中疾病的患病率(流行率): ground truth中疾病数量/总例数=3/10=0.3
现在,利用敏感性、特异性和患病率之间的关系,我们也可以得到准确度为0.8。
我们可以用准确度的公式来确认一下。
准确度=预测正确的样本/总样本=8/10=0.8
因此,我们已经介绍了两个可以用来评估诊断性人工智能模型的指标,包括敏感性和特异性,我们已经看到了它们与准确性的关系。
PPV NPV
敏感性告诉我们,如果我们知道患者患有疾病,模型预测为阳性的概率是多少?
在临床上,使用人工智能模型的医生可能会对另一个问题感兴趣。如果模型预测病人是阳性的,那么他们实际患上疾病的概率是多少?这被称为模型的正预测值(positive predictive value)或 PPV。

同理
特异性是假设一个病人是正常的,模型预测为阴性的概率是多少?
如果模型预测为阴性,医生可能有兴趣知道患者实际正常的概率是多少?这被称为阴性预测值(negative predictive value)或 NPV。
让我们用一个例子来计算PPV和NPV。

图中已经给出了计算结果。
现在我们已经学习了PPV和NPV,敏感性和特异性,让我们看看它们是如何相互联系的。

为了了解它们之间的关系,我们将使用混淆矩阵。
混淆矩阵可以用表的形式来观察分类器的性能。行对应于实际情况(ground truth, GT),列对应于模型预测或模型输出。
表中的单元格对应于每个GT和模型预测组合对应的元素数量。
例如,在第一行第一列中,表示GT为Disease且模型输出为”+“的个数为2。这四个单元格的总和应该是样本总数,即10。
这四种计数通常被称为真阳性、假阳性、假阴性和真阴性。

我们已经看到了用计数来计算这些度量的公式。注意,它们直接对应于混淆矩阵中的单元格。所以我们可以用这四个术语来表示所有这些评估指标。
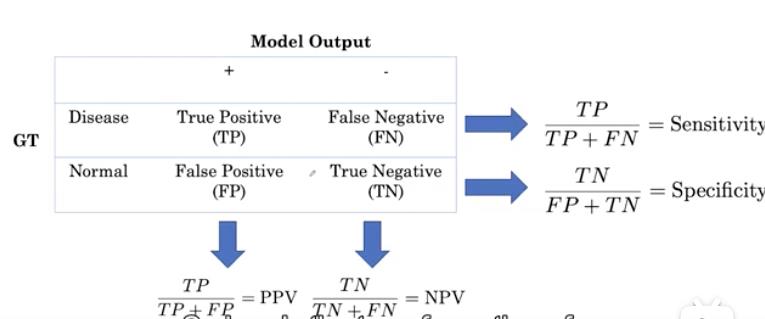
这里是公式的转换,使用混淆矩阵中的项。例如,PPV现在是真阳性除以真阳性加假阳性。
ROC 曲线
在本课中,我们将学习评估医学模型最有用的工具之一,ROC曲线。
我们将看到ROC曲线如何允许我们根据模型在不同决策阈值下的特殊性,直观地绘制模型的敏感性。

胸部x射线分类模型输出给定x射线的疾病概率。这个输出可以转换成使用阈值(threshold)或操作点的诊断。
当概率高于某个阈值时,我们将其解释为阳性或患者患有疾病。当概率低于临界值时,我们将其解释为阴性或患者没有患病。
例如,如果我们的概率分数是0.7,阈值是0.5,那么我们将把这个例子归类为阳性。
但是如果我们的概率分数是0.2,阈值是0.5,我们将把这个例子归为阴性。
我们对阈值的选择影响指标。例如,如果我们有一个阈值t为0,那么我们将把所有的图像都归为阳性。所以我们的敏感性是1,而特异性是零。
类似地,如果我们选择了一个阈值为1,我们会把所有的图像都归为阴性,所以我们的特异性将是1,而我们的敏感度将是零。
让我们更深入地研究我们选择的阈值(也称为操作点)是如何影响这些量的。
假设我们有一个15张胸部x光片的测试集,我们通过我们的模型得到输出概率或每一张的得分。

我们可以在0到1之间的一条数列上这15个输出值的分数线。现在这些x光片中有一部分是疾病,有些是正常的。所以让我们给它们涂上相应的颜色。这里的病是红色的,正常的是蓝色的。
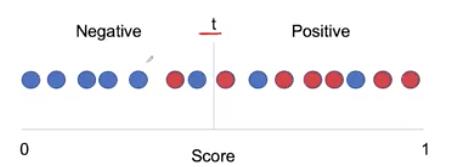
我们可以选择一个小值t作为阈值,它将阈值右侧的所有内容分类为阳性,将阈值左侧的所有内容分类为阴性。
现在我们可以计算模型的灵敏度和特异性。
这里,敏感度的分母是疾病的总数,我们可以把它算作红色的总数,也就是7。分子是多少个是正的,或者换句话说,在阈值的右边有多少是正的。
所以我们的灵敏度=6/7=0.85。
同样,特异性的分母是正常例子的总数,这里的蓝色圆圈总数是8。分子是多少是阴性的,或者换句话说,在阈值的左边有多少个阴性。
所以我们的特异性=6/8=0.75。
假设我们现在改变阈值,使其更高。我们现在期望,我们将更少的例子归类为阳性,更多的例子归类为阴性。
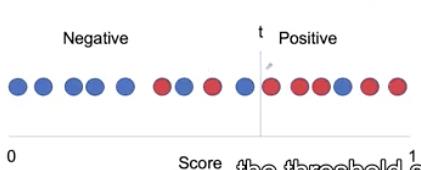
我们现在可以重新计算灵敏度和特异性。

请注意,敏感性下降了,因为分子下降了,特异性上升了,因为分子增加了,因为我们现在正确地将更多的正常患者分类,而错误地将更多的疾病患者分类。
我们可以将这一点发挥到极致,并将阈值设置为1。在这种情况下,敏感性将为零,因为没有一个例子被归类为阳性,而特异性将为1,因为所有的例子都被归类为阴性。
因此,我们通过设置不同的阈值,以特异性为横坐标,敏感性为纵坐标,就可以画出一条随阈值变化的曲线了。

文章持续更新,可以关注微信公众号【医学图像人工智能实战营】获取最新动态,一个关注于医学图像处理领域前沿科技的公众号。坚持已实践为主,手把手带你做项目,打比赛,写论文。凡原创文章皆提供理论讲解,实验代码,实验数据。只有实践才能成长的更快,关注我们,一起学习进步~
我是Tina, 我们下篇博客见~
白天工作晚上写文,呕心沥血
觉得写的不错的话最后,求点赞,评论,收藏。或者一键三连

以上是关于吴恩达-第一课第二周1-7节总结-医学深度学习模型的评估汇总的主要内容,如果未能解决你的问题,请参考以下文章
吴恩达-医学图像人工智能专项课程-第一课第一周6-10节总结+作业解读