C语言编译过程,满满的干货!!!
Posted SuchABigBug
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C语言编译过程,满满的干货!!!相关的知识,希望对你有一定的参考价值。
程序环境和预处理
一、程序翻译和运行环境
翻译环境:在翻译环境中,我们写的源代码转换为可执行的机器指令,让机器能够看的懂,模块包括预处理,汇编,编译和链接最终生成的可执行程序.exe或者 a.out
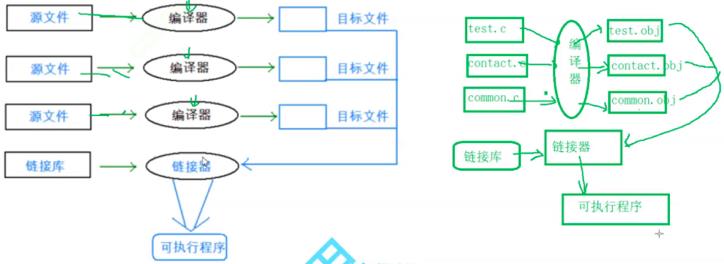
- 每个源文件通过编译分别转换成目标代码(.o文件)
- 每个目标文件由一个链接器(linker)捆绑在一起,形成一个可执行程序
- Linker同时也会引入标准C函数任何被该程序所引用的函数,包括个人的程序库,将其需要的函数也链接到程序中
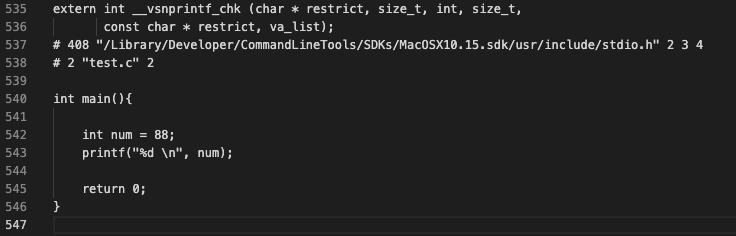
预处理阶段:
#include <stdio.h>
#define globalVal 88
int main(){
// 这个是注释comment
int num = globalVal;
printf("%d \\n", num);
return 0;
}
我们到预编译阶段停止,把预编译后的结果写到test文件中

我们可以看到#include <stdio.h>被替换为源代码,变量globalVal被替换成了数字88,同时注释也被删除
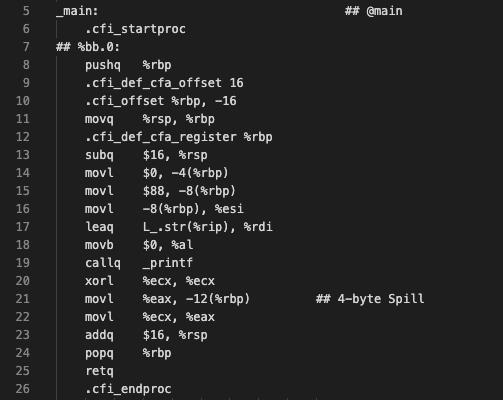
编译阶段:
把C语言代码转化成汇编代码
- 语法分析
- 词法分析
- 语义分析
- 符号汇总
用-S进行转换并写入test文件中

下图为生成的test.s文件中的内容
汇编阶段
编译器中的最后一个阶段,把汇编代码转换成了机器指令(二进制)
- 生成符号表
- 生成.o文件是elf格式,我们可以用readelf来查看这个table

链接器阶段
翻译环境中的最后一个阶段,把生成的多个目标文件(.o文件)和库进行连接,合并段表和符号表的合并和符号表的重定位,如_main函数和其他的主函数可以通过ref table的地址进行链接
翻译环境总结:
预编译主要是进行的文本操作,如完成头文件的包含,#define的定义符号和宏的替换,最后注释删除。
接着就是编译阶段(把C语言转换成汇编代码),而汇编是把汇编指令转换成二进制指令最后生成我们的目标文件
然后多个源文件经过编译器处理生成的多个目标文件最后会经过链接器的处理生成我们的可执行程序
运行环境:用于实际执行代码
二、预处理详解
1. 预定义符号
__FILE__ //进行编译的源文件
__LINE__ //文件当前的行号
__DATE__ //文件被编译的日期
__TIME__ //文件被编译的时间
__STDC__ //如果编译器遵循ANSI C,其值为1,否则未定义
2. define 定义宏
#define int 888
这里建议后面不要加上semi colon,否则替换之后会报错
还有一个需要注意的是加上括号()以此避免优先级错误
比如:
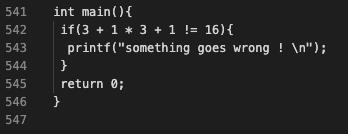
#define SQUARE(X) X * X
int main(){
if(SQUARE(3 + 1) != 16){
printf("something goes wrong ! \\n");
}
return 0;
}
我们预期这个结果是16,-E预编译后写入一个文件,这个被转换成了(3+1*3+1),那这个结果算出来肯定就不对了呀,所以正确的办法是在宏定义SQUARE的时候加上括号才能达到预期((X) * (X))。
3. #和##的区别
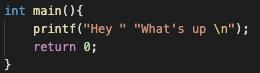
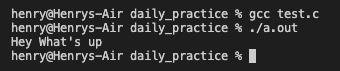
#就是把输入函数的参数转换成字符串,可以和宏一起用,如调用宏SQUARE(NUMISThree),可以这个变量名转换成字符串形式打印出来
如下图就是通过了#进行连接的:
##
此符号可以把位于它两边的符号合成一个符号,就相当于 linux下的cat操作 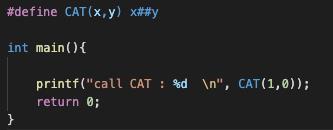

4. 宏和函数好坏比较
| 宏 | 函数 | |
|---|---|---|
| 代码长度 | 每次使用时,预处理阶段都会进行替换,一般stdio.h替换万后有五百多行 | 函数只出现一个地方,每次使用也都调用那个地方也就是我们说的符号表中函数的地址 |
| 执行速度 | 宏更快,可以看预处理阶段就直接替换就好 | 存在函数调用和返回的额外开销,相对慢 |
| 操作法优先级 | 容易搞混淆,就如我们上面的例子SQAURE(X),不加括号容易产生优先级错误 | 表达式的求值结果更容易预测 |
| 带有副作用的参数 | 宏与类型无关,只要对参数操作是合法的即可,不够严谨 | 但是函数就和类型息息相关,如果类型不同就会报错 |
| 调试 | 宏不方便调试,因为预处理阶段已经完成了转换 | 可以逐个调试 |
| 递归 | 宏不能递归 | 函数可以进行递归 |
而在C++中,有个函数叫内联(inline),即继承了宏的优点,也兼顾了函数的优点
5. 命名约定
可以在编译指令中进行变量声明
如 MAX_SIZE= 10
然后在程序中直接使用此变量名即可
6. 头文件中 < >和" "区别
本地文件包含,自定义的函数头文件使用 “ ”
库文件包含 < >
<> 和 “ ”包含头文件的本质是查找策略的区别, 双引号的查找策略是先在源文件所在目录下查找
如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件
7. 条件编译
条件编译的用处是防止文件中多次包含同一个库文件,那么在预处理阶段就多出现大量的冗余,因此我们可以用条件编译来判断此文件是否被重复用过,或者判断是运行macos文件,还是WIndows还是Linux。
第二种办法更简单就是在文件开头用#pragama once也能达到一样的效果
1.
#define __SHOWLINE__
2.
#ifdef __SHOWLINE__
XXX
XXX
#endif
3.
#if 0 // 敞亮表达式,用于mute内容,可供后期调试
XXX
XXX
#endif
4.
#if //多个分支的条件编译
#elif
#else
#endif
5.
#if defined(XXX)
等价于
#ifdef XXX
#if !defined(XXX)
等价于
#ifndef XXX
如果文章对你有帮助的话,给作者点个赞加个油,俺会更有动力的!😃
以上是关于C语言编译过程,满满的干货!!!的主要内容,如果未能解决你的问题,请参考以下文章