有无索引的性能比较:mysql插入100万条数据后查询
Posted amcomputer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了有无索引的性能比较:mysql插入100万条数据后查询相关的知识,希望对你有一定的参考价值。
1 环境
win 7 +mysql8.0 +nvicat
内存12个G
2 建表
CREATE TABLEIF NOT EXISTS `app_user`(
id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT,
name varchar(50) NOT NULL,
email varchar(50) NOT NULL,
phone varchar(20) NOT NULL,
gender tinyint(4) unsigned DEFAULT 0,
password varchar(100) NOT NULL,
age tinyint(2) NOT NULL,
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
3 尝试插入1条
INSERT INTO app_user(name, email, phone,password)
VALUES(CONCAT('用户1'),'18888888@qq.com','1234567', FLOOR(RAND()*100));

4 写函数
/*
第一个语句 delimiter 将 mysql 解释器命令行的结束符由”;” 改成了”$$”,
让存储过程内的命令遇到”;” 不执行
*/
DELIMITER $$
CREATE FUNCTION mock_data()
RETURNS INT
DETERMINISTIC
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i<num DO
INSERT INTO `app_user`(`name`,`email`,`phone`,`gender`,`password`)VALUES(CONCAT('用户',i),'19224305@qq.com','123456789',FLOOR(RAND()*2), FLOOR(RAND()*100));
SET i=i+1;
END WHILE;
RETURN i;
END;$$
注意,5.0版本不需要DETERMINISTIC,8.0需要加这行命令。
5 执行函数
SELECT mock_data()$$ -- 执行此函数 生成一百万条数据
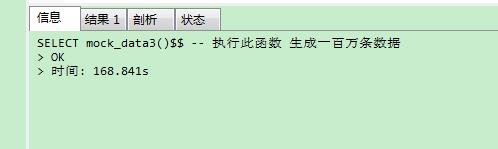
生成数据花了168秒,恐怖!!
查看下数据:
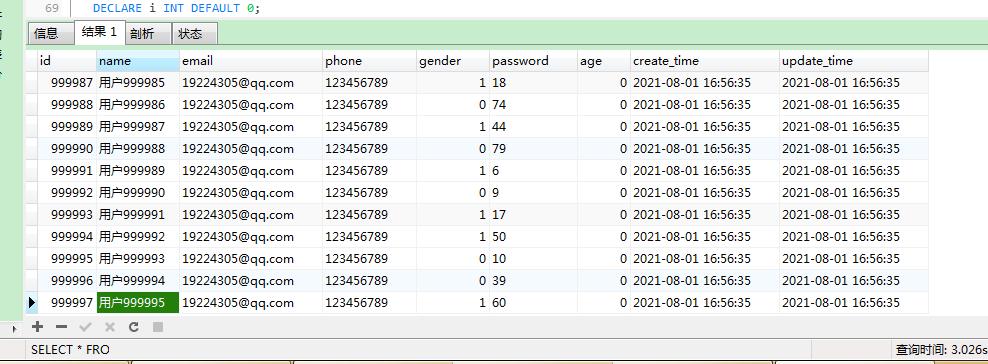
6 性能分析
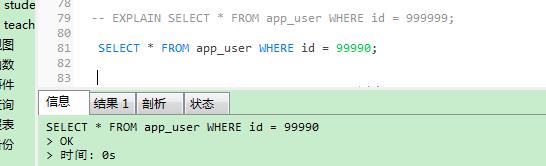
用主键查数据:
SELECT * FROM app_user WHERE id = 99990;
用非主键查数据:
SELECT * FROM app_user WHERE name = '用户9999';
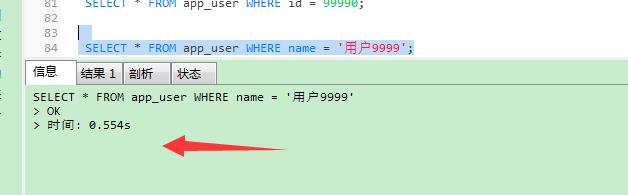
区别还是很明显的。在用户体验上,体现出有无索引的好处。
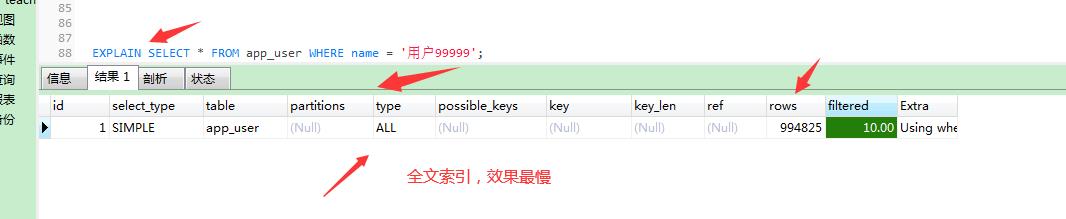
进一步分析:

使用,explain命令,查询了994825行才查到。
7 创建索引
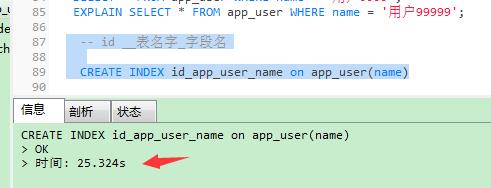
之前查询太慢了,试试给nam字段添加索引
-- id __表名字_字段名
CREATE INDEX id_app_user_name on app_user(name)
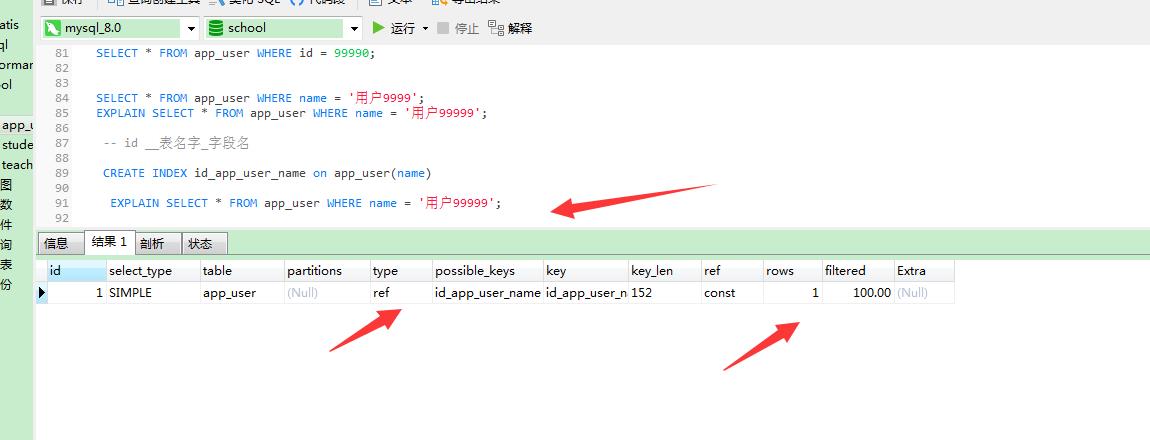
只查询了一行,速度变快了。原因是重新建了一颗索引树,空间换时间。
查询时间:
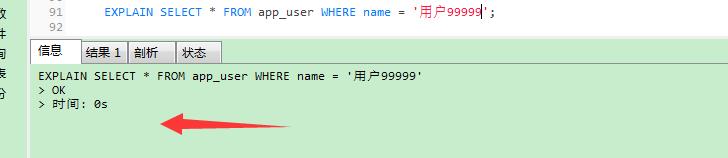
这就是建立索引的好处。
以上是关于有无索引的性能比较:mysql插入100万条数据后查询的主要内容,如果未能解决你的问题,请参考以下文章