HashMap核心源码分析
Posted 可持续化发展
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap核心源码分析相关的知识,希望对你有一定的参考价值。
基本原理
补充笔记:
笔记1
(1)数组和链表对比,
内存布局,查找性能,内存大小,扩容灵活度,插入/删除节点,

(2)散列表
整合两种数据结构的优势,既可以用索引,动态扩容方便。


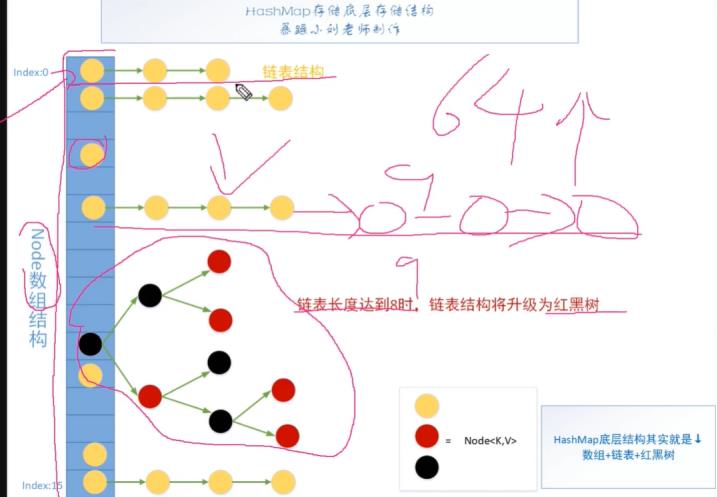
为什么要引入红黑树?
为了解决链化过长的问题,提高查找效率。
hashmap的扩容原理
为什么要扩容?长度为16的时候,由于存放的元素过多,get方法的效率就降低了。扩容后,以空间换时间,提高了查找的效率。如果插入的数据很多的话,散列表就退化成线性查询了。扩容后,桶位就更多了。
源码分析
重要属性


数组的最大长度不能超过1<<30


没有形成链表的时候,查询时间复杂度为O(1),形成链表后,链表很长,查询时间复杂度就变为O(N)了。链表长度超过8后,就有可能被升级为树。


 哈希表
哈希表


往哈希表中插入/删除元素才算修改次数。替换元素不算修改次数。


一般使用默认的0.75。
构造方法
/**
* Returns a power of two size for the given target capacity.
* tableSizeFor作用:返回一个大于等于当前值cap的一个数字,并且这个数字一定是2的次方数。
* cap = 10
* n = 10 - 1 => 9
* 0b1001 | 0b0100 => 0b1101
* 0b1101 | 0b0011 => 0b1111
* 0b1111 | 0b0000 => 0b1111
*
* 0b1111 => 15
*
* return 15 + 1;
* 为什么要cap - 1呢?因为假设cap为16,如果cap不减1的话,经过位运算后,会得到的数为32,是正确值的2倍,
* 因为16的二进制位数比15多了一位。
* cap = 16
* n = 16;
* 0b10000 | 0b01000 =>0b11000
* 0b11000 | 0b00110 =>0b11110
* 0b11110 | 0b00001 =>0b11111
* =>0b11111 => 31
* return 31 + 1;
*
* 0001 1101 1100 => 0001 1111 1111 + 1 => 0010 0000 0000 一定是2的次方数
*这个算法的目的是将任意一个数字(不管他的二进制是什么样的),通过位或运算后,再加1,得到一个2的次方数。这是为了确定创建的数组长度。
*/


初始扩容阈值:大于等于定义时传进来的初始容量且是最小的2的次方数。
初始容量为7,初始阈值为8。
初始容量为8,初始阈值为8。
初始容量为9,初始阈值为16。
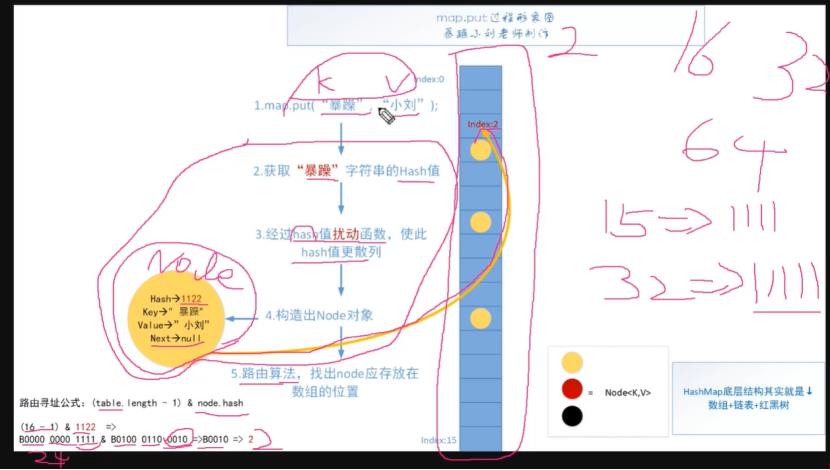
put方法
往hash表中插入一个数据,是这样的:先计算出key的hashcode,经过一个扰动函数得到一个hash。具体实现是:key的hashcode与hashcode无符号右移16位做异或运算。使得hashcode高16位参与路由寻址的运算。为了在这个数组长度还比较小的时候(16,32,64),让hashcode的高16位参与路由寻址运算,使低16位具有高16位的特征。
hash值 & (数组长度-1),就找到了对应的位置index。这个扰动函数就是hash(key)方法。
如果key是null的话,得到的hash值为0。这样的话,这个K/V就会放在数组的0索引位置。
找到位置之后,开始分情况讨论了:
hashMap是延迟初始化逻辑的,第一次调用putVal时才会初始化hashMap对象中的最耗费内存的散列表。(为了避免浪费空间)
情况(1):寻址找到的桶位 刚好是 null,这个时候,直接将当前k-v=>node 扔进去就可以了。
情况(2):桶位中已有的那个元素,与当前插入的元素的key完全一致,后续需要进行替换操作。
情况(3):桶里面的元素已经树化成红黑树了。
情况(4):桶里的元素形成链化。而且链表的头元素与要插入的key不一致。就开始迭代查找。如果迭代到最后都没有找到key相同的节点,就put到链尾。然后检查是否到达树化阈值8(如果链表长度超过8,就可能会树化)。如果迭代时找到了相同的key,就进行替换。
最后,散列表结构被修改的次数+1、size容量自增。并检查size是否大于扩容阈值。
如果是替换操作,put方法会返回旧value。如果是插入操作,就返回null。
链表树化的条件:1.链表的长度要超过8。2、table数组的长度要大于或等于MIN_TREEIFY_CAPACITY(64)。这两个条件都满足时,这条链表才会树化。
如果仅仅满足链表长度超过8,就会发生扩容,调用resize()方法。


resize方法
为什么需要扩容?
- 为了解决哈希冲突导致的链化影响查询效率的问题,扩容会缓解该问题。
网上教程中提到的 160.75=12,这个计算的情况是情况(1)。延迟初始化的时候,就会用到160.75=12,新的扩容阈值为12.
//oldCap:表示扩容之前table数组的长度
//new的时候,没有放数据,tab=null,第一次放数据的时候,调用了resize,oldTab为null。
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//oldThr:表示扩容之前的扩容阈值,触发本次扩容的阈值
int oldThr = threshold;
//newCap:扩容之后table数组的大小
//newThr:扩容之后,下次再次触发扩容的条件
int newCap, newThr = 0;
扩容这部分的源码:先是计算出扩容之后table数组的大小newCapacity和扩容之后,新的扩容阈值newThreshold。把新的扩容阈值赋给threshold。创建新的Node数组并赋给table。未初始化过,就返回新的table数组。初始化过的,就开始真正的扩容操作。
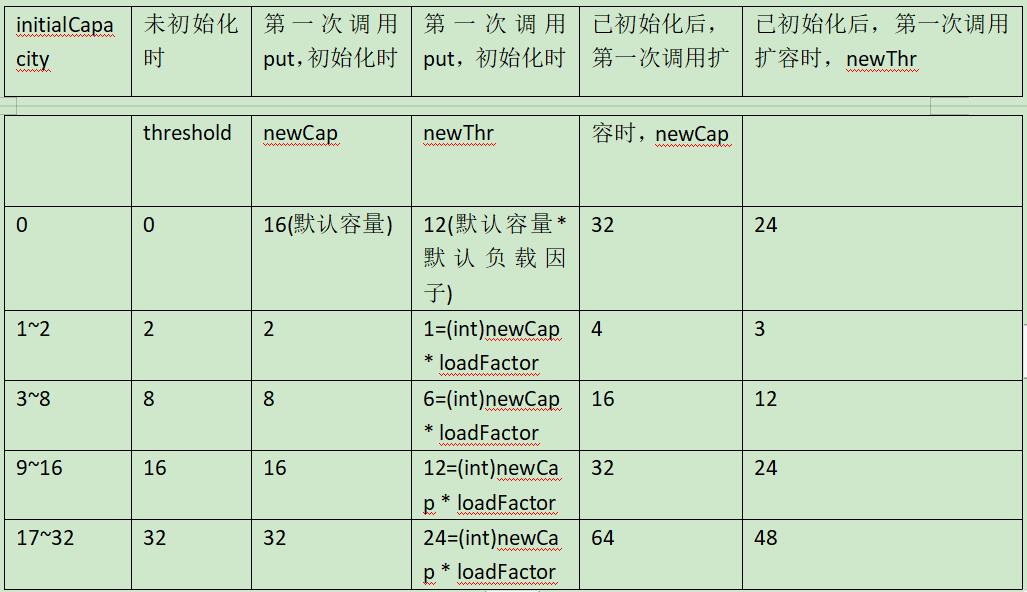
扩容的情况主要为下列几种:
情况(1),在new HashMap();且未初始化table时调用,newCapacity=16,newThreshold=12.返回创建的table数组。
情况(2),在new的时候有设置初始容量且未初始化的时候调用,newCapacity=旧的扩容阈值,newThreshold=(int)newCap * loadFactor,返回创建的table数组。
情况(3),初始化后,调用resize()。在put的过程中,如果当前桶里的元素已经链化了且新插入的节点被插在链尾,这条链表的长度大于树化阈值8,但table数组的长度小于最小树化容量MIN_TREEIFY_CAPACITY(64),则触发扩容。又或者如果putVal(…)方法执行到最后,++size 大于扩容阈值,则触发扩容。
对于引用类型的变量,null意味着它没有指向如何内存,没有指向任何东西。初始化后,table数组 != null ,table指向一个Node数组。
初始化后的扩容,就需要移动数据。这时的情况又细分为这几种:
情况(1), 当前桶位只有一个元素,从未发生过碰撞,这时直接计算出当前元素应存放在 新数组中的位置(e.hash & (newCap - 1)),然后扔进去。
情况(2),当前桶位已经树化了,它就要切割这个红黑树,会分为一棵大的树和一棵小的树,放在新table的对应位置。如果小的那棵树的节点数 <= UNTREEIFY_THRESHOLD(6),就会将树转化为链表。
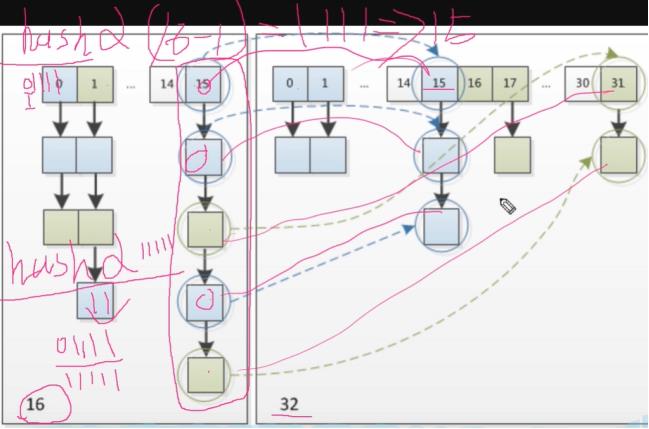
情况(3),桶位已经形成链表。会拆成高位链和低位链。低位链表:存放在扩容之后的数组的下标位置,与原来的数组的下标位置一致。比如说15->15。它的hash值 & 扩容之后的长度-1 得到的下标是一样的。高位链表:存放在扩容之后的数组的下表位置为 原来的数组下标位置 + 扩容之前数组的长度.比如说15->31。
高位链和低位链的图
get方法

get的过程分为下列几种情况:
情况(1),table数组没有初始化时,返回null。
情况(2),定位出来的桶位元素,就是要get的数据。
情况(3),定位到的桶位升级成了 红黑树。红黑树是二叉搜索树的变种,就按红黑树的查找方式,去找key相同的节点。如果找不到,就返回null。
情况(4),定位到的桶位形成链表。遍历查找。如果找不到就返回null。如果找到了,就返回Node的value。
remove方法

@param matchValue if true only remove if value is equal true的话,就是key和value都匹配才remove。
remove的过程分为下列几种情况:
情况(1),先看看table数组中有没有数据,如果没有数据,就返回null。
情况(2),当前桶位中的元素就是要删除的元素。将该元素.next放至桶位中。
情况(3),当前桶位升级为了红黑树。就走红黑树的查找和删除方法。
情况(4),当前桶位的元素链化了。按照链表的方式遍历查找并删除节点。
如果找到了,就删除并返回被删除的元素。如果找不到,就返回null。
replace方法
比较简单,就自己看源码吧。
以上是关于HashMap核心源码分析的主要内容,如果未能解决你的问题,请参考以下文章