Apache Spark 编译打包过程
Posted 终回首
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Spark 编译打包过程相关的知识,希望对你有一定的参考价值。
版本:
Ubuntu 20.04.2 LTS
Apache Maven 3.6.3
JDK 1.8
R 3.1.1
注意:必须安装提前安装Maven、JDK、R
建议使用linux编译,实在没有linux环境,可以用win10的WSL
1 下载源码
# 下载源码,推荐这样下载
git clone https://github.com/apache/spark.git
# 查看所有的tag,每个tag都是一个版本
git tag
# 切换到指定版本,这里我要编译的版本是2.4.0(如果需要其他版本就切换到其他版本)
git checkout v2.4.0
2 编译源码
编译的目的是下载好jar包
# 进入到源码的根目录
cd /opt/os_ws/spark
# 设置maven使用更多内存,不设置的话会内存溢出
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
# 执行编译命令
./build/mvn -Phadoop-3.1 -Dhadoop.version=3.1.1 -Pyarn -Phive -Phive-thriftserver -DskipTests clean package
- -Phadoop-3.1 -Dhadoop.version=3.1.1 -Pyarn
指定hadoop的版本为3.1.1(如果需要不同的版本就指定需要的版本);指定可用yarn提交; - -Phive -Phive-thriftserver
指定支持hive - -DskipTests
指定跳过测试 - clean package
清空上一次打的jar包再打包
执行成功,编译完成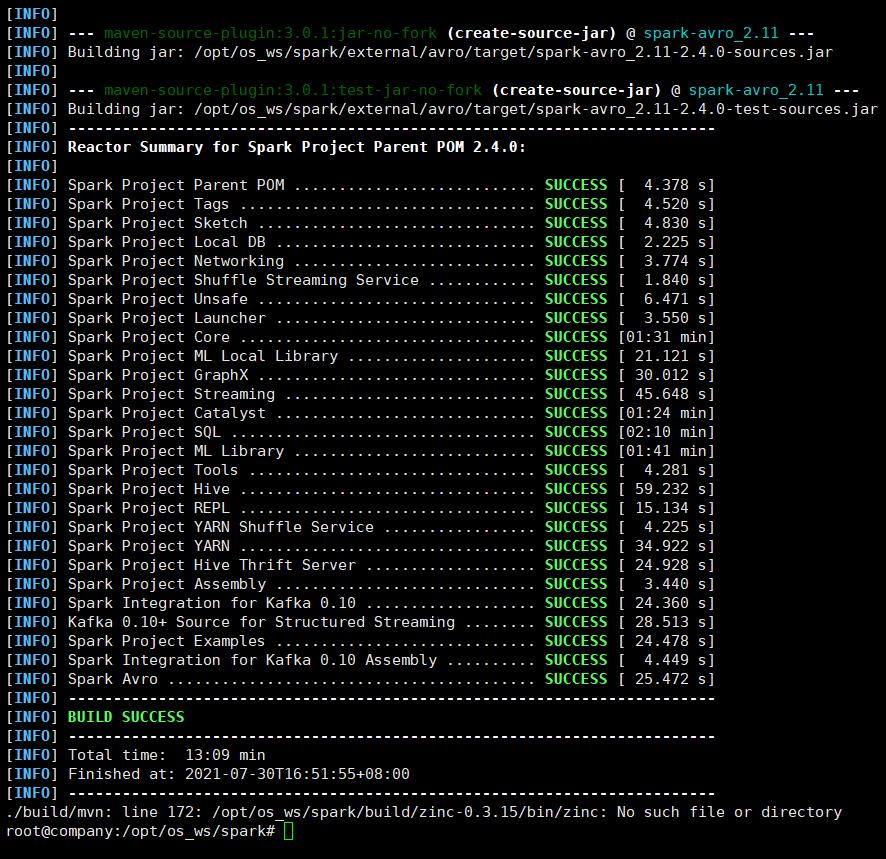
3 构建可部署版本
3.1 修改mvn路径
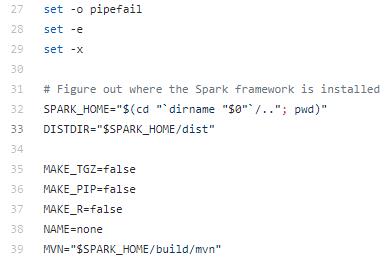
默认的mvn路径指向$SPARK_HOME/build/mvn,这里要改成自己安装的mvn路径
vim ./dev/make-distribution.sh
修改mvn命令的路径为自己安装的路径
修改前
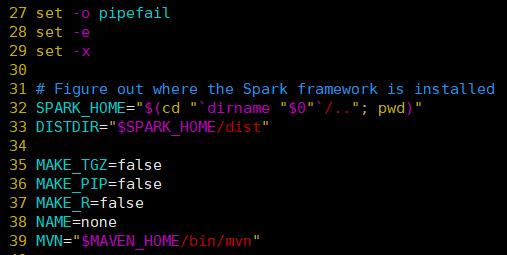
修改后
3.2 执行打包命令
./dev/make-distribution.sh --name hadoop3.1.1 --tgz -Psparkr -Phadoop-3.1 -Dhadoop.version=3.1.1 -Phive -Phive-thriftserver -Pyarn
经过十几分钟终于执行成功了
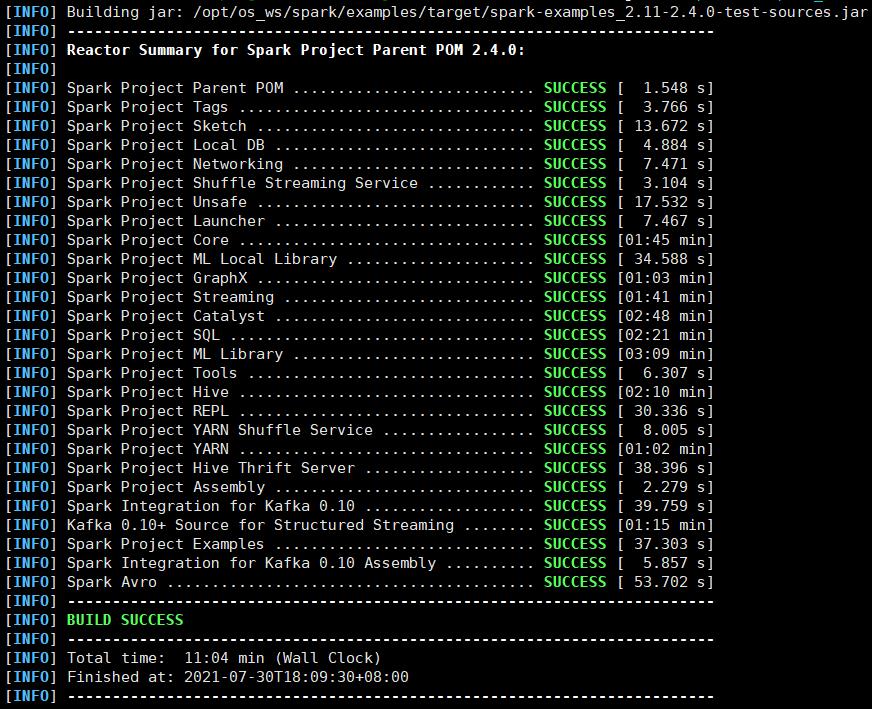
打包好的安装包就在根目录下

终于可以拿去部署了!
参考资料
http://spark.apache.org/docs/2.4.0/building-spark.html#buildmvn
以上是关于Apache Spark 编译打包过程的主要内容,如果未能解决你的问题,请参考以下文章