MySQL 分布式集群探索-MGR-组复制性能
Posted shark_西瓜甜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL 分布式集群探索-MGR-组复制性能相关的知识,希望对你有一定的参考价值。
组复制性能
本节介绍如何使用可用的配置选项从您的团队中获得最佳性能。
1 微调组通信线程
加载组复制插件时,组通信线程(GCT)在循环中运行。GCT接收来自组和插件的消息,处理仲裁和故障检测相关任务,发送一些保持活动状态的消息,并处理来自/到服务器/组的传入和传出事务。GCT在队列中等待传入消息。没有消息时,GCT等待。在某些情况下,在实际进入睡眠之前,将此等待时间配置为稍长一点(执行活动等待)可能是有益的。这是因为另一种选择是操作系统从处理器中切换出GCT并进行上下文切换。
要强制GCT执行活动等待,请使用group_replication_poll_spin_loops选项,该选项使GCT循环,在实际轮询队列以获取下一条消息之前,不对配置的循环数执行任何相关操作。
例如:
mysql> SET GLOBAL group_replication_poll_spin_loops= 10000;
2 消息压缩
对于在线组成员之间发送的邮件,默认情况下,组复制启用邮件压缩。是否压缩特定消息取决于您使用 group_replication_compression_threshold 系统变量配置的阈值。有效负载大于指定字节数的消息将被压缩。
默认压缩阈值为1000000字节。您可以使用以下语句将压缩阈值增加到2MB,例如:
STOP GROUP_REPLICATION;
SET GLOBAL group_replication_compression_threshold = 2097152;
START GROUP_REPLICATION;
如果将group_replication_compression_threshold阈值设置为零,则禁用消息压缩。
组复制使用LZ4压缩算法压缩组中发送的消息。请注意,LZ4压缩算法支持的最大输入大小为2113929216字节。此限制低于group_replication_compression_threshold 系统变量的最大可能值,该系统变量与XCom接受的最大消息大小相匹配。因此,LZ4最大输入大小是消息压缩的实际限制,当启用消息压缩时,无法提交超过此大小的事务。对于LZ4压缩算法,请不要为group_replication_compression_threshold 阈值设置大于2113929216字节的值。
组复制不要求所有组成员上的group_replication_compression_threshold 阈值相同。但是,建议在所有组成员上设置相同的值,以避免不必要的事务回滚、消息传递失败或消息恢复失败。
在组中发送的消息的压缩发生在组通信引擎级别,在数据移交给组通信线程之前,因此它发生在mysql用户会话线程的上下文中。如果消息负载大小超过组group_replication_compression_threshold 阈值设置的阈值,则事务负载将在发送到组之前进行压缩,并在收到时进行解压缩。收到消息后,成员检查消息信封以验证其是否被压缩。如果需要,则成员在将事务交付到上层之前解压缩事务。此过程如下图所示。
图 压缩架构
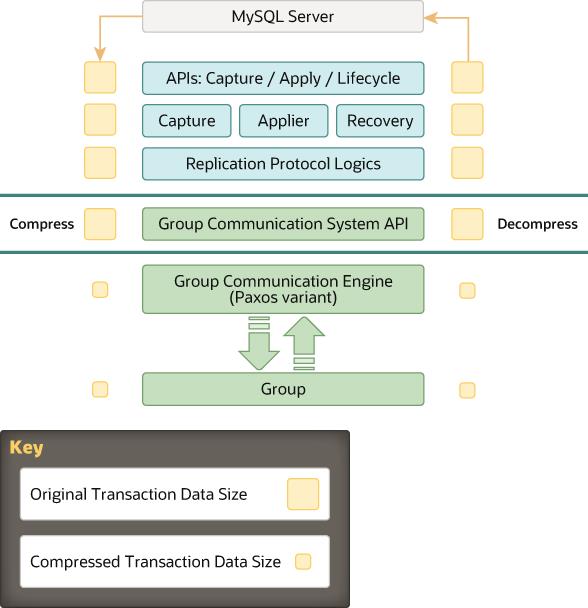
当网络带宽成为瓶颈时,消息压缩可以在组通信级别提供高达30-40%的吞吐量改进。对于负载下的大型服务器组,这一点尤为重要。组中N个参与者之间互连的TCP对等性质使发送方发送相同数量的数据N次。此外,二进制日志可能表现出较高的压缩比。这使得压缩成为包含大型事务的组复制工作负载的一项引人注目的功能。
3 流量控制
组复制可确保只有在组中的大多数成员都已收到事务并就并发发送的所有事务之间的相对顺序达成一致后,才提交该事务。
如果对组的写入总数不超过组中任何成员的写入容量,则此方法效果良好。如果确实如此,并且一些成员的写入吞吐量低于其他成员,特别是低于writer成员,则这些成员可能会开始落后于writer。
让一些成员落后于团队会带来一些问题,特别是,对这些成员的读取可能会将非常旧的数据外部化。根据该成员落后的原因,组中的其他成员可能必须或多或少地保存复制上下文,以便能够满足慢速成员的潜在数据传输请求。
但是,复制协议中有一种机制,可以避免在应用的事务方面,快速成员和慢速成员之间存在太大的距离。这就是所谓的流量控制机制。它试图实现几个目标:
保持成员足够接近,使成员之间的缓冲和去同步成为一个小问题;
快速适应不断变化的条件,如不同的工作负载或团队中有更多的编剧;
为每个成员提供公平的可用写入容量份额;
为了避免浪费资源,不能降低超过严格必要的吞吐量。
考虑到组复制的设计,可以考虑两个工作队列来决定是否节流:(i)认证队列(ii)和在二进制日志应用程序队列上。每当其中一个队列的大小超过用户定义的阈值时,就会触发节流机制。仅配置:(i)是在认证机构还是在应用程序级别进行流控制,或者两者都进行流控制;以及(ii)每个队列的阈值是多少。
流量控制取决于两种基本机制:
对成员进行监控,以收集有关所有组成员的吞吐量和队列大小的一些统计信息,从而对每个成员应承受的最大写入压力进行有根据的猜测;
限制试图在每个时刻写入超出其可用容量公平份额的内容的成员。
探测和统计
监控机制的工作原理是让每个成员部署一组探测,以收集有关其工作队列和吞吐量的信息。然后,它定期将该信息传播给组,以便与其他成员共享该数据。
这些探测分散在插件堆栈中,允许建立度量,例如:
认证器队列大小;
复制应用程序队列大小;
经认证的交易总数;
成员中应用的远程事务的总数;
本地事务的总数。
计算上一个成员在本地执行的附加事务统计数据,以及该成员在上一个认证期间从另一个成员接收的附加事务数。
监控数据定期与组中的其他人共享。监视周期必须足够高,以允许其他成员决定当前的写入请求,但必须足够低,以使其对组带宽的影响最小。信息每秒共享一次,这段时间足以解决这两个问题。
组复制限制
根据在组中所有服务器上收集的指标,一个节流机制开始起作用,并决定是否限制成员执行/提交新事务的速率。
因此,从所有成员获取的度量是计算每个成员的容量的基础:如果成员有一个大队列(用于认证或应用程序线程),则执行新事务的容量应接近上一阶段认证或应用的容量。
组中所有成员的最低容量决定了组的实际容量,而本地事务的数量决定了有多少成员正在向其写入,因此,应该与多少成员共享该可用容量。
这意味着每个成员都有一个基于可用容量的既定写入配额,换句话说,就是它可以为下一个期间安全地发出的事务数。如果证明程序或二进制日志应用程序的队列大小超过用户定义的阈值,则通过节流机制强制执行写入程序配额。
配额将减少上一个期间延迟的事务数,然后再进一步减少10%,以允许触发问题的队列减小其大小。为了避免队列大小超过阈值后吞吐量大幅增加,在此之后,吞吐量每周期仅允许增加相同的10%。
当前的限制机制不会惩罚低于配额的事务,但会延迟完成超过配额的事务,直到监控期结束。因此,如果发出的写请求的配额非常小,则某些事务的延迟可能接近监视周期。
以上是关于MySQL 分布式集群探索-MGR-组复制性能的主要内容,如果未能解决你的问题,请参考以下文章