datax源码环境搭建
Posted 犀牛饲养员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了datax源码环境搭建相关的知识,希望对你有一定的参考价值。
datax源码环境搭建
写在前面
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 mysql、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
我最近打算花点时间,深度研究下DataX的源码。按照我以前看源码的经验,我一般都会在本地搭建好调试环境,通过debug的方式调试。
环境
这里是说我的本地环境。
- macOS big sur
- jdk8
- idea 2021.01
- Apache Maven 3.x
- python 2.6.x
下载源码并编译
git clone https://github.com/alibaba/DataX.git
然后倒入idea,配置好maven,jdk等,用maven 进行编译。可能会遇到几个错误。
错误1
Could not find artifact org.pentaho:pentaho-aggdesigner-algorithm:jar:5.1.5-jhyde in alimaven (http://maven.aliyun.com/nexus/content/groups/public/)
这个问题我通过在maven的settings.xml里加了多加了两个镜像解决,
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云spring插件仓库</name>
<url>https://maven.aliyun.com/repository/spring-plugin</url>
</mirror>
<mirror>
<id>repo2</id>
<name>Mirror from Maven Repo2</name>
<url>https://repo.spring.io/plugins-release/</url>
<mirrorOf>central</mirrorOf>
</mirror>
错误2
[ERROR] Failed to execute goal on project oscarwriter: Could not resolve dependencies for project com.alibaba.datax:oscarwriter:jar:0.0.1-SNAPSHOT: Could not find artifact com.oscar:oscar:jar:7.0.8 at specified path /Users/malu/Documents/code/idea_study/DataX/oscarwriter/src/main/lib/oscarJDBC.jar -> [Help 1]
这个是因为,pom文件引用了这个jar,
<dependency>
<groupId>com.oscar</groupId>
<artifactId>oscar</artifactId>
<version>7.0.8</version>
<scope>system</scope>
<systemPath>${basedir}/src/main/lib/oscarJDBC.jar</systemPath>
</dependency>
这个oscar可能是阿里内部的存储或者第三方提交的插件,正常应该在源码里面加上这个jar包的,不过也没关系,我们把oscard相关的注释掉就可以了,反正也不会用到。
首先去项目根目录下的pom.xml搜索oscar把相关的注释掉。然后到package.xml做同样的操作,再编译就可以了。
我是解决了这两个错误后,就可以编译打包通过了。打包好的文件在
{项目目录}/core/target/datax
我的目录下包含如下几个文件:
- bin
- conf
- job
- lib
- script
- tmp
运行
生产模式
有两种运行方式,线上一般会通过执行datax.py进行datax任务的启动。
进入上面打包好的bin目录,执行作业
$ python datax.py job/{YOUR_JOB.json}
json文件就是我们定义的任务模版,里面描述了数据库的类型(reader和writer),数据库地址等信息。比如一个mysql2mysql的json大概是这样的:
{
"job":{
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"column":[
"id",
"name"
],
"connection":[
{
"jdbcUrl":[
"jdbc:mysql://127.0.0.1:3306/dq"
],
"table":[
"table1"
]
}
],
"password":"123456",
"username":"root"
}
},
"writer":{
"name":"mysqlwriter",
"parameter":{
"column":[
"id",
"name"
],
"connection":[
{
"jdbcUrl":"jdbc:mysql://ip地址:端口/test",
"table":[
"table2"
]
}
],
"password":"123456",
"username":"root"
}
}
}
],
"setting":{
"speed":{
"channel":"1"
}
}
}
}
接着来看下datax.py是干啥的,它源码不长,main方法是入口,如下:
if __name__ == "__main__":
printCopyright()
parser = getOptionParser()
options, args = parser.parse_args(sys.argv[1:])
if options.reader is not None and options.writer is not None:
generateJobConfigTemplate(options.reader,options.writer)
sys.exit(RET_STATE['OK'])
if len(args) != 1:
parser.print_help()
sys.exit(RET_STATE['FAIL'])
startCommand = buildStartCommand(options, args)
# print startCommand
child_process = subprocess.Popen(startCommand, shell=True)
register_signal()
(stdout, stderr) = child_process.communicate()
sys.exit(child_process.returncode)
流程概括如下:
- 打印datax版权信息
- 获取参数解析器解析参数
- 构建启动命令
- 启动java子进程
后面会有专门的文章详细分析这个datax.py,这里不多说。
如果你打包好直接运行
$ python datax.py job/{YOUR_JOB.json}
会报错如下:
WARN ConfigParser - 插件[mysqlreader,mysqlwriter]加载失败,1s后重试... Exception:Code:[Framework-12], Description:[DataX插件初始化错误, 该问题通常是由于DataX安装错误引起,请联系您的运维解决 .]. - 插件加载失败,未完成指定插件加载:[mysqlwriter, mysqlreader]
2021-06-22 14:41:28.120 [main] ERROR Engine -
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[Framework-12], Description:[DataX插件初始化错误, 该问题通常是由于DataX安装错误引起,请联系您的运维解决 .]. - 插件加载失败,未完成指定插件加载:[mysqlwriter, mysqlreader]
at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:26)
at com.alibaba.datax.core.util.ConfigParser.parsePluginConfig(ConfigParser.java:142)
at com.alibaba.datax.core.util.ConfigParser.parse(ConfigParser.java:63)
at com.alibaba.datax.core.Engine.entry(Engine.java:137)
at com.alibaba.datax.core.Engine.main(Engine.java:204)
因为我打好包的这个目录下没有plugin目录,datax没法加载插件。参考项目目录下的dataxPluginDev.md文件建目录,然后拷贝对应插件目录下编译好的jar包等文件即可。
mac下有可能还会遇到下面这个错误,
WARN ConfigParser - 插件[mysqlreader,mysqlwriter]加载失败,1s后重试... Exception:Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/Users/malu/Documents/code/idea_study/DataX/core/target/datax/plugin/reader/.DS_Store/plugin.json]不存在. 请检查您的配置文件.
2021-06-22 16:30:20.825 [main] ERROR Engine -
这个删除对应目录下的.DS_Store文件即可。
运行之后,如果出现类似下面这种,就是成功过了。
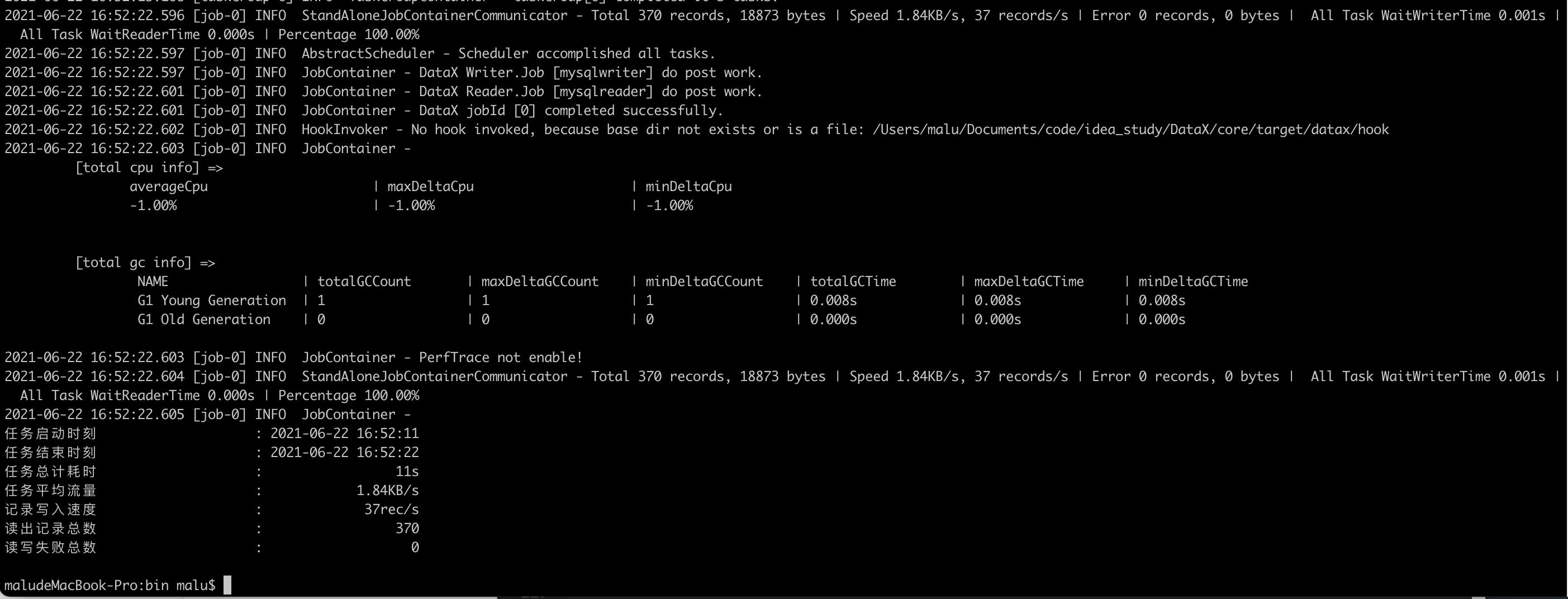
debug模式
还有一种是debug调试,看源码用这种模式运行再好不过了。这个配置也比较简单,只需要在idea里配置vm options和运行参数即可。
vm options填写示例(换成自己的目录):
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/Users/malu/Documents/code/idea_study/DataX/core/target/datax/log
-Ddatax.home=/Users/malu/Documents/code/idea_study/DataX/core/target/datax
-Dlogback.configurationFile=/Users/malu/Documents/code/idea_study/DataX/core/target/datax/conf/logback.xml
program args 填写示例(换成自己的目录):
-mode standalone -jobid -1 -job /Users/malu/Documents/code/idea_study/DataX/core/target/datax/job/mysql2mysql.json
以上是关于datax源码环境搭建的主要内容,如果未能解决你的问题,请参考以下文章