Python程序设计 实验4:字典集合的应用
Posted 上山打老虎D
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python程序设计 实验4:字典集合的应用相关的知识,希望对你有一定的参考价值。
1. 列表与集合:
参考exp4.1.py,比较列表和集合在一些操作上所需要时间的差别。
分析:
首先创建列表和集合,并获取开始时间,再检查一个元素是否在集合或列表内。再获取结束时间,两时间做差即为程序运行的消耗时间,将运行时间输出即可。
同理也可测得删除元素的时间。
编程并实现:
import time
# 代码1:创建列表
list1 = []
for i in range(0, 10**8):
list1.append(i)
# 代码2:创建集合
set1 = set()
for i in range(0, 10**8):
set1.add(i)
startTime = time.time() # 开始时间
# 代码3:检查一个元素是否在一个集合里
flag = 8*10**7 in set1
endTime = time.time() # 结束时间
runTime = float((endTime - startTime) * 1000)
# 代码4:输出结果
print("Time cost for check items in set:")
print(runTime)
startTime = time.time() # 开始时间
# 代码5:检查一个元素是否在一个列表里
flag = 8*10**7 in list1
endTime = time.time() # 结束时间
runTime = float((endTime - startTime) * 1000)
# 代码6:输出结果
print("Time cost for check items in list:")
print(runTime)
# 代码7:仿照上面例子,测试集合与列表中删除元素在时间上的差别
startTime = time.time() # 开始时间
list1.remove(8*10**7)
endTime = time.time() # 结束时间
runTime = float((endTime - startTime) * 1000)
print("Time cost for delete items in list:")
print(runTime)
startTime = time.time() # 开始时间
set1.remove(8*10**7)
endTime = time.time() # 结束时间
runTime = float((endTime - startTime) * 1000)
print("Time cost for delete items in set:")
print(runTime)
由于小数据量级下时间消耗较短,小于时间测量函数的精度,因此需要选择较大数据进行测试。因此本实验中选择了
1
0
8
10^8
108作为数据量级。首先创建列表与集合。分别进行大数据下的创建赋值。并选择查找较大数据进行测验。最后删除数据完成对结果进行测验。
运行并测试:
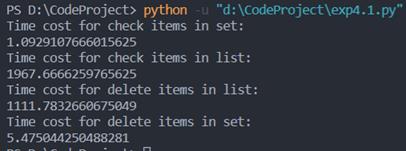
可以发现,对元素查找与删除时,集合所消耗的时间均远小于列表所需时间。
2. 统计关键字
统计文本 ofdm_tx_main.py中Python关键字出现的次数。关键字包括
“and”, “as”, “assert”, “break”, “class”, “continue”, “def”, “del”, “elif”, “else”, “except”, “False”, “finally”, “for”, “from”, “global”, “if”, “import”, “in”, “is”, “lambda”, “None”, “nonlocal”, “not”, “or”, “pass”, “raise”, “return”, “True”, “try”, “while”, “with”, “yield”
小提示:
可使用以下函数删除文本中的标点符号,即把标点符号变成" ",
import string
def removePunctuations(word):
for ch in word:
if ch in string.punctuation:
word = word.replace(ch, " ")
return word
分析:
首先创建关键字字典用于统计每个出现的关键词次数。
然后按行读入文件,并对输入流文件进行判断,如果为空行则进行下一行的处理,如果为EOF结束符,则结束处理。
对于每个读入的行,首先将标点符号修改为空格。再利用split对每个单词完成切分,并存放在一个列表中。再次遍历列表去除空字符串和换行符后,将列表中每个字符串与建立字典中键值一一对应,如果存在则键值所指的值加一。循环处理所有文件后输出结果字典即可。
编程并实现:
import string
# 去除标点空格以及换行
def removePunctuations(word):
# 去除标点符号
for ch in word:
if ch in string.punctuation or ch == '\\n':
word = word.replace(ch, " ")
# 利用空格完成切分
temp = word.split(' ')
# 倒序查找空列表或仅有换行列表并丢弃
for i in range(len(temp)-1, -1, -1):
# 判空
if len(temp[i]) == 0:
del temp[i]
continue
# 判换行
if temp[i] == '\\n':
del temp[i]
return temp
# 建立关键字字典
word_dic = {"and": 0, "as": 0, "assert": 0, "break": 0, "class": 0, "continue": 0, "def": 0, "del": 0, "elif": 0, "else": 0, "except": 0, "False": 0, "finally": 0, "for": 0, "from": 0, "global": 0,
"if": 0, "import": 0, "in": 0, "is": 0, "lambda": 0, "None": 0, "nonlocal": 0, "not": 0, "or": 0, "pass": 0, "raise": 0, "return": 0, "True": 0, "try": 0, "while": 0, "with": 0, "yield": 0}
# 读入文件
inputFile = open("ofdm_tx_main.py", "r")
# 循环进行处理
while True:
# 按行读入
line = inputFile.readline()
if not line:
break
if line == '\\n':
continue
# 对非空行进行处理
wordlist = removePunctuations(line)
for temp in wordlist:
if temp in word_dic.keys():
word_dic[temp] += 1
print(word_dic)
inputFile.close()
①定义去除标点空格的函数,利用replace完成将标点符号替换成空格的操作。其次,利用空格和换行符对读入的行完成切分。再对每个切分字符串进行判断,如果为空或换行,则删除。
②定义关键字字典,完成对各个关键字的匹配计数。
③通过输入流读入整个文件,并利用循环依次处理每一行。如果读入的为换行符,则继续读入下一行。如果读入的是EOF结束符,则结束读取。其余情况则为读入有效字符,进行下一步处理。
④对于每个有效读入行,先调用定义的函数对空格以及标点等进行处理并存入列表中。遍历列表的每一项,如果在所创建的字典键值中,则对应计数值加一,否则继续下一个有效读入的处理。
⑤完成所有的处理后输出结果。
运行并测试:

{‘and’: 3, ‘as’: 0, ‘assert’: 0, ‘break’: 0, ‘class’: 3, ‘continue’: 0, ‘def’: 9, ‘del’: 0, ‘elif’: 2, ‘else’: 7, ‘except’: 1, ‘False’: 6, ‘finally’: 0, ‘for’: 3, ‘from’: 6, ‘global’: 1, ‘if’: 17, ‘import’: 8, ‘in’: 5, ‘is’: 2, ‘lambda’: 1, ‘None’: 4, ‘nonlocal’: 0, ‘not’: 3, ‘or’: 1, ‘pass’: 1, ‘raise’: 1, ‘return’: 2, ‘True’: 6, ‘try’: 1, ‘while’: 2, ‘with’: 0, ‘yield’: 0}
3. 统计电话号码中的数字出现次数
编写函数 NumberFrequencies(tel_num), tel_num 为 区号-电话号码 格式(如 0755-26536114),返回一个字典保存数字0~9 出现的次数,字典的键为数字,值为数字出现的次数。
分析:
首先创建关键字字典用于统计每个出现的关键词次数。
然后获取输入,并设置标志变量用于忽略掉区号中的数字,只统计电话号码中的数字。最后将电话号码的每一位存入字典中,全部程序运行完毕后输出结果即可。
编程并实现:
# 定义统计函数
def NumberFrequencies(tel_num):
# 忽略掉连接符前的数字
flag = False
for i in range(0, len(tel_num)):
if not flag and tel_num[i] == '-':
flag = True
continue
if not flag:
continue
# 对应字典值加一
word_dic[tel_num[i]] += 1
# 建立关键字字典
word_dic = {str(i): 0 for i in range(0,10)}
str = input("Please input the telephone number:")
NumberFrequencies(str)
print(word_dic)
①定义统计函数,获取输入的电话号之后,从头依次进行判断,设置一标志变量用于存是否读到分隔符。
②如果未读到分隔符则将一直读入,直到读入分隔符。读入分隔符后便将对应字典值加一直至处理完毕。
③处理完后即输出完整字典
运行并测试:
运行程序,并输入“0755-26536114”

{‘0’: 0, ‘1’: 2, ‘2’: 1, ‘3’: 1, ‘4’: 1, ‘5’: 1, ‘6’: 2, ‘7’: 0, ‘8’: 0, ‘9’: 0}
4. 字典的理解:
回答以下问题
(1)以下哪些字典创建是有效的,哪些是无效的?解释原因。
d = {[1, 2]:1, [3, 4]:3}
d = {(1, 2):1, (3, 4):3}
d = {{1, 2}:1, {3, 4}:3}
d = {"12":1, "34":3}
分析:
通过实际运行并分析可以得到相应结果如下:
①d = {[1, 2]:1, [3, 4]:3}
无效,因为字典的键必须为可哈希对象。列表不可哈希。
②d = {(1, 2):1, (3, 4):3}
有效。每个元组为对应的键。
③d = {{1, 2}:1, {3, 4}:3}
无效,因为字典的键必须为可哈希对象。集合不可哈希。
④d = {“12”:1, “34”:3}
有效。每个字符串为对应的键。
(2)基于以下代码,回答问题:
D={"what":22, "are":11, "you":14, "doing":5, "next":9, "Saturday?":4}
sum1 = []
sum2 = 0
for x in D.items():
sum1 = 【代码 1】
sum2 = 【代码 2】
问题 1: 如果 sum1 为
[(‘what’, 22), (‘are’, 11), (‘you’, 14), (‘doing’, 5), (‘next’, 9), (‘Saturday?’, 4)],
那么【代码 1】应该是什么?
分析:
即将字典转换为对应列表,可以通过调用系统函数完成。因此可以填入如下代码:
sum1 = list(D.items())
问题 2: 如果【代码 2】分别是
(a) sum2 = sum2 + D[x[0]]
(b) sum2 = sum2 + x[1]
sum2的结果分别是什么?
分析:
都输出65。
a通过访问键值对对应值进行访问并求和。b通过直接访问值进行求和。故最后输出均为65
5. 堆的理解
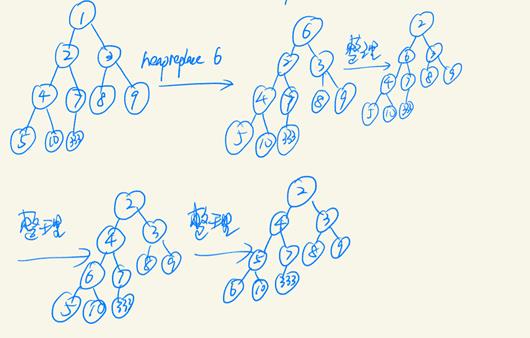
描述课件中函数 heapreplace弹出堆中最小元素,同时插入新元素时,堆的变化过程(可手写拍照)。
分析:
即将堆顶元素替换为6后进行重新调整,具体过程见下。
实验结论
通过本次对字典与集合的应用,我学会并掌握了字典与集合操作上的异同,并学会了字典与集合的基本操作,学会了使用字典完成关键字的匹配等操作。
此外我也学习了堆等高级数据结构,并对如何进行堆排序的调整进行了练习。在本次实验过程中,我有如下两个启示:
- 测量较小运行时间时,可以通过运行较大数据或执行多次重复操作来延长运行时间来“以大见小”以完成测量。
- 输入时输入的一般为字符型,当需要存入字典时需注意字符型与整形的转换。
以上是关于Python程序设计 实验4:字典集合的应用的主要内容,如果未能解决你的问题,请参考以下文章