MySQL中InnoDB存储引擎索引的示例分析
Posted Chihiro.511
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL中InnoDB存储引擎索引的示例分析相关的知识,希望对你有一定的参考价值。
本文主要为大家分享的是MySQL中InnoDB存储引擎索引的示例分析,由于内容条例清晰,且具有一定的参考价值,感兴趣的朋友不妨来看看!接下来,就跟着小杜一起进入主题吧!
概述
在数据库当中,索引就跟树的目录一样用来加快数据的查找速度,对于一个SQL查询操作,根据索引快速过滤掉不符合要求的数据并定位到符合要求的数据,从而不需要扫描整个表来获取所需的数据。
在innodb存储引擎中,主要是基于B+树来实现索引,在非叶子节点存放索引关键字,在叶子节点存放数据记录或者主键索引(或者说是聚簇索引)中的主键值,所有的数据记录都在同一层,叶子节点,即数据记录直接之间通过指针相连,构成一个双向链表,从而可以方便地遍历到所有的或者某一范围的数据记录。
B树,B+树
B树和B+树都是多路平衡搜索树,通过在每个节点存放更多的关键字和通过旋转、分裂操作来保持树的平衡来降低树的高度,从而减少数据检索的磁盘访问量。
B+树相对于B树的一个主要的不同点是B+的叶子节点通过指针前后相连,具体为通过双向链表来前后相连,所以非常适合执行范围查找。具体可以参考:
数据结构-树(三):多路搜索树B树、B+树
innodb存储引擎的聚簇和非聚簇索引都是基于B+树实现的。
主键索引
innodb存储引擎使用主键索引作为表的聚簇索引,聚簇索引的特点是非叶子节点存放主键作为查找关键字,叶子节点存放实际的数据记录本身(也称为数据页),从左到右以关键字的顺序,存放数据记录,故聚簇索引其实就是数据存放的方式,所以每个表只能存在一个聚簇索引,innodb存储引擎的数据表也称为索引组织表。
结构如下:

在查询当中,如果是通过主键来查找数据,即使用explain分析SQL的key显示PRIMARY时,查找效率是最高的,因为叶子节点存放的就是数据记录本身,所有可以直接返回,而不需要像非聚簇索引一样需要通过额外回表查询(在主键索引中)获取数据记录。
其次是对于ORDER BY排序操作,不管是正序ASC还是逆序DESC,如果ORDER BY的列是主键,则由于主键索引对应的B+树本身是有序的, 故存储引擎返回的数据就是已经根据主键有序的,不需要在mysql服务器层再进行排序,提高了性能,如果通过explain分析SQL时,extra显示Using filesort,则说明需要在MySQL服务器层进行排序,此时可能需要使用临时表或者外部文件排序,这种情况一般需要想办法优化。
对于基于主键的范围查找,由于聚簇索引的叶子节点已经根据主键的顺序,使用双向链表进行了相连,故可以快速找到某一范围的数据记录。
辅助索引
辅助索引也称为二级索引,是一种非聚簇索引,一般是为了提高某些查询的效率而设计的,即使用该索引列查询时,通过辅助索引来避免全表扫描。由于辅助索引不是聚簇索引,每个表可以存在多个辅助索引,结构如下:
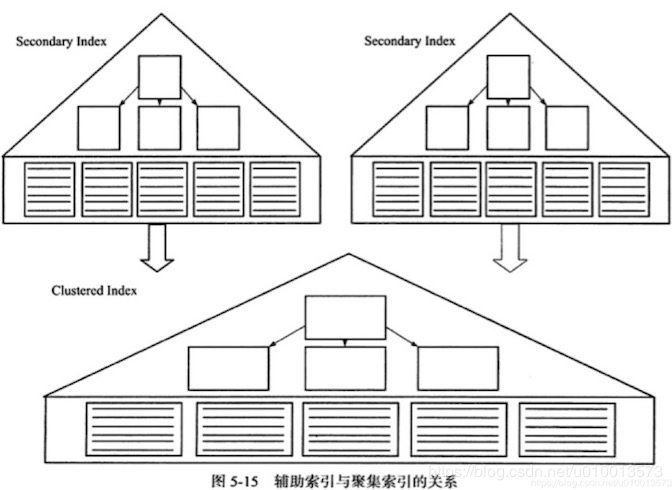
辅助索引的非叶子节存放索引列的关键字,叶子节点存放对应聚簇索引(或者说是主键索引)的主键值。即通过辅助索引定位到需要的数据后,如果不能通过索引覆盖所需列,即通过该辅助索引列来获取该次查询所需的所有数据列,则需要通过该对应聚簇索引的主键值定位到在聚簇索引中的主键,然后再通过该主键值在聚簇索引中找到对应的叶子页,从而获取到对应的数据记录,所以整个过程涉及到先在辅助索引中查找,再在聚簇索引(即主键索引)中查找(回表查询)两个过程。
举个例子:
1.辅助索引对应的B+树的高度为3,则需要3次磁盘IO来定位到叶子节点,其中叶子节点包含对应聚簇索引的某个主键值;
2.然后通过叶子节点的对应聚簇索引的主键值,在聚簇索引中找到对应的数据记录,即如果聚簇索引对应的B+树高度也是3,则也需要3次磁盘IO来定位到聚簇索引的叶子页,从而在该叶子页中获取实际的数据记录。
以上过程总共需要进行6次磁盘IO。故如果需要回表查询的数据行较多,则所需的磁盘IO将会成倍增加,查询性能会下降。所以需要在过滤程度高,即重复数据少的列来建立辅助索引。
Cardinality:索引列的数据重复度
由以上分析可知,通过辅助索引进行查询时,如果需要回表查询并且查询的数据行较多时,需要大量的磁盘IO来获取数据,故这种索引不但没有提供查询性能,反而会降低查询性能,并且MySQL优化器在需要返回较多数据行时,也会放弃使用该索引,直接进行全表扫描。所以辅助索引所选择的列需要是重复度低的列,即一般查询后只需要返回一两行数据。如果该列存在太多的重复值,则需要考虑放弃在该列建立辅助索引。
具体可以通过:SHOW INDEX FROM 数据表,的Cardinality的值来判断:

Cardinality表示索引列的唯一值的估计数量,如果跟数据行的数量接近,则说明该列存在的重复值少,列的过滤性较好;如果相差太大,即Cardinality / 数据行总数,的值太小,如性别列只包含“男”,“女”两个值,则说明该列存在大量重复值,需要考虑是否删除该索引。
覆盖索引
由于回表查询开销较大,故为了减少回表查询的次数,可以在辅助索引中增加查询所需要的所有列,如使用联合索引,这样可以从辅助索引中获取查询所需的所有数据(由于辅助索引的叶子页包含主键值,即使索引没有该主键值,如果只需返回主键值和索引列,则也会使用覆盖索引),不需要回表查询完整的数据行,从而提高性能,这种机制称为覆盖索引。
当使用explain分析查询SQL时,如果extra显示 using index 则说明使用了覆盖索引返回数据,该查询性能较高。
由于索引的存在会增加更新数据的开销,即更新数据时,如增加和删除数据行,需要通过更新对应的辅助索引,故在具体设计时,需要在两者之间取个折中。
联合索引与最左前戳匹配
联合索引是使用多个列作为索引,如(a,b,c),表示使用a,b,c三个列来作为索引,由B+树的特征可知,索引都是需要符合最左前戳匹配的,故其实相当于建立a,(a,b),(a,b,c)三个索引。
所以在设计联合索引时,除了需要考虑是否可以优化为覆盖索引外,还需要考虑多个列的顺序,一般的经验是:查询频率最高,过滤性最好(重复值较少)的列在前,即左边。
联合索引优化排序order by
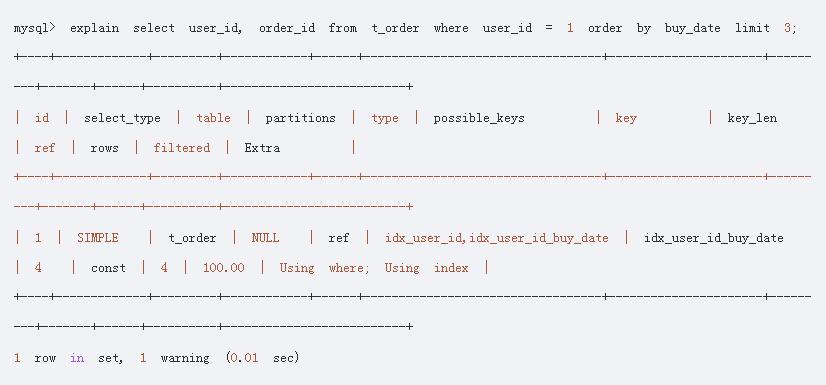
除此之外,可以考虑通过联合索引来减少MySQL服务端层的排序,如用户订单表包含联合索引(user_id, buy_date),单列索引(user_id):(注意这里只是为了演示联合索引,实际项目,只需联合索引即可,如上所述,(a,b),相当于a, (a,b)两个索引):

如果只是普通的查询某个用户的订单,则innodb会使用user_id索引,如下:

但是当需要基于购买日期buy_date来排序并取出该用户最近3天的购买记录时,则单列索引user_id和联合索引(user_id, buy_date)都可以使用,innodb会选择使用联合索引,因为在该联合索引中buy_date已经有序了,故不需要再在MySQL服务器层进行一次排序,从而提高了性能,如下:
如果删除idx_user_id_buy_date这个联合索引,则显示Using filesort:

以上就是关于“MySQL中InnoDB存储引擎索引的示例分析”的所有内容分享,相信大家看完之后都有一定的了解,如果还想了解更多相关知识,欢迎关注摩杜云行业资讯频道,更多精彩相关知识等着你来学习!如果觉得这篇文章不错的话,也可以分享给更多的人看到。感谢各位的阅读!
以上是关于MySQL中InnoDB存储引擎索引的示例分析的主要内容,如果未能解决你的问题,请参考以下文章