用聚类算法计算股票的支撑位和阻力位
Posted Python中文社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用聚类算法计算股票的支撑位和阻力位相关的知识,希望对你有一定的参考价值。

本文将向您展示如何使用不同的聚类算法计算股票支撑位和阻力位。
股票数据 - 我在 mongoDB 数据库中有股票数据。您还可以免费从雅虎财经获取这些数据。
Python 连接 MongoDB 设置
In [1]:
import pymongo
from pymongo import MongoClient
client_remote = MongoClient('mongodb://localhost:27017')
db_remote = client_remote['stocktdb']
collection_remote = db_remote.stock_data
从 MongoDB 获取股票数据
我将使用过去 60 天的 Google 公司股票 数据进行分析。
In [2]:
mobj = collection_remote.find({'ticker':'GOOGL'}).sort([('_id',pymongo.DESCENDING)]).limit(60)
为数据分析准备数据
我将使用 Pandas 和 Numpy 进行数据操作。让我们首先从 Mongo Cursor 对象获取数据到 Python 列表。
In [3]:
prices = []
for doc in mobj:
prices.append(doc['high'])
K-means聚类计算股票支撑位和阻力位
In [4]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import AgglomerativeClustering
对于 K-means聚类,我们需要将数据转换为 Numpy 数组格式。
In [5]:
X = np.array(prices)
对于K-means聚类来说,K-means聚类的数量非常重要。我们可以使用膝图找到最佳 K值,如下所示。
In [6]:
from sklearn.cluster import KMeans
import numpy as np
from kneed import KneeLocator
sum_of_sq_distances = []
K = range(1,10)
for k in K:
km = KMeans(n_clusters=k)
km = km.fit(X.reshape(-1,1))
sum_of_sq_distances.append(km.inertia_)
kn = KneeLocator(K, sum_of_sq_distances,S=1.0, curve="convex", direction="decreasing")
kn.plot_knee()
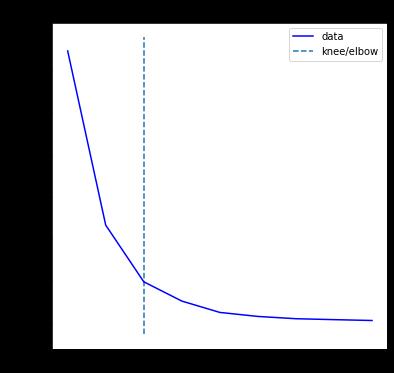
让我们使用 kn.knee 检查 K 的值
In [7]:
kn.knee
Out[7]:
3
In [8]:
kmeans = KMeans(n_clusters= kn.knee).fit(X.reshape(-1,1))
c = kmeans.predict(X.reshape(-1,1))
min_and_max = []
for i in range(kn.knee):
min_and_max.append([-np.inf,np.inf])
for i in range(len(X)):
cluster = c[i]
if X[i] > min_and_max[cluster][0]:
min_and_max[cluster][0] = X[i]
if X[i] < min_and_max[cluster][1]:
min_and_max[cluster][1] = X[i]
让我们检查聚类的最小值和最大值。
In [9]:
min_and_max
Out[9]:
[[2461.9099, 2365.55], [2687.98, 2508.0801], [2357.02, 2239.4399]]
上面显示了3个簇,每个簇都有最大值和最小值。
在写本文的时候,谷歌的股价是2687.98(当日最高点),正好也是52周来的最高点。因此,基于上述聚类,我们可以说2687.98是阻力位,下一个支撑水平是2508.0801。下一个支持级别是2461.9099、2365.55、2357.02、2239.4399。
记住,这些支撑位和阻力位将根据数据范围和聚类参数K的值而变化。
用层次聚类计算股票支撑位和阻力位
In [10]:
mobj = collection_remote.find({'ticker':'GOOGL'}).sort([('_id',pymongo.DESCENDING)]).limit(60)
prices = []
for doc in mobj:
prices.append(doc['high'])
另一种可以使用的方法是凝聚聚类,即层次聚类。
凝聚聚类是一种自底向上的方法,它将子聚类合并以找出大的数据聚类。
层次聚类对股票滚动数据很有用。
让我们创建一个20天的滚动数据,用于计算最大值和最小值。
In [11]:
df = pd.DataFrame(prices)
max = df.rolling(20).max()
max.rename(columns={0: "price"},inplace=True)
min = df.rolling(20).min()
min.rename(columns={0: "price"},inplace=True)
需要以下步骤以两列格式准备数据。
In [12]:
maxdf = pd.concat([max,pd.Series(np.zeros(len(max))+1)],axis = 1)
mindf = pd.concat([min,pd.Series(np.zeros(len(min))+-1)],axis = 1)
maxdf.drop_duplicates('price',inplace = True)
mindf.drop_duplicates('price',inplace = True)
让我们使用n_clusters=3值来表示聚类数量。
In [13]:
F = maxdf.append(mindf).sort_index()
F = F[ F[0] != F[0].shift() ].dropna()
# Create [x,y] array where y is always 1
X = np.concatenate((F.price.values.reshape(-1,1),
(np.zeros(len(F))+1).reshape(-1,1)), axis = 1 )
cluster = AgglomerativeClustering(n_clusters=3,
affinity='euclidean', linkage='ward')
cluster.fit_predict(X)
F['clusters'] = cluster.labels_
F2 = F.loc[F.groupby('clusters')['price'].idxmax()]
# Plotit
fig, axis = plt.subplots()
for row in F2.itertuples():
axis.axhline( y = row.price,
color = 'green', ls = 'dashed' )
axis.plot( F.index.values, F.price.values )
plt.show()
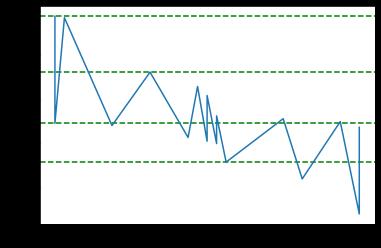
现在让我们绘制聚类。如下图所示,找到了两个聚类。如果考虑到谷歌今天的收盘价2638.00,我们可以说2687.98是阻力位,2357.02是支撑位。
In [14]:
F2
Out[14]:
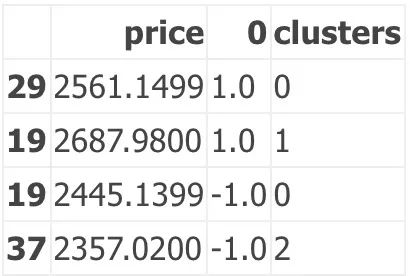
这里需要注意的一点是,只有2个聚类的价格是2357.02,这并不是很多。要查看是否可以找到更多的聚类,我们必须增加源数据中的价格点数量,或者增加聚类数量,或者缩小滚动窗口。
让我们将聚类的数量增加到5,看看会发生什么。
In [15]:
F = maxdf.append(mindf).sort_index()
F = F[ F[0] != F[0].shift() ].dropna()
# Create [x,y] array where y is always 1
X = np.concatenate((F.price.values.reshape(-1,1),
(np.zeros(len(F))+1).reshape(-1,1)), axis = 1 )
cluster = AgglomerativeClustering(n_clusters=5,
affinity='euclidean', linkage='ward')
cluster.fit_predict(X)
F['clusters'] = cluster.labels_
F2 = F.loc[F.groupby('clusters')['price'].idxmax()]
# Plotit
fig, axis = plt.subplots()
for row in F2.itertuples():
axis.axhline( y = row.price,
color = 'green', ls = 'dashed' )
axis.plot( F.index.values, F.price.values )
plt.show()
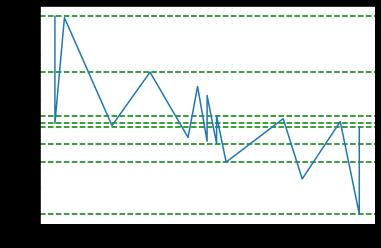
In [16]:
F2
Out[16]:
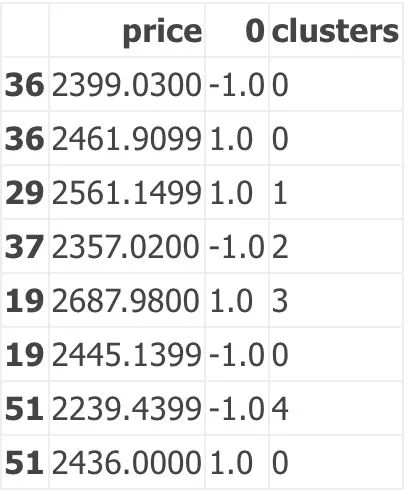
好的,这次我们以2239.43的价格获得了更多的聚类,这与今天2638的收盘价相去甚远。然而,基于3个聚类,阻力值看起来不错,为2687.98。
让我们把滚动窗口缩小一点。与其说是20天,不如说是10天。
In [17]:
df = pd.DataFrame(prices)
max = df.rolling(10).max()
max.rename(columns={0: "price"},inplace=True)
min = df.rolling(10).min()
min.rename(columns={0: "price"},inplace=True)
maxdf = pd.concat([max,pd.Series(np.zeros(len(max))+1)],axis = 1)
mindf = pd.concat([min,pd.Series(np.zeros(len(min))+-1)],axis = 1)
maxdf.drop_duplicates('price',inplace = True)
mindf.drop_duplicates('price',inplace = True)
F = maxdf.append(mindf).sort_index()
F = F[ F[0] != F[0].shift() ].dropna()
# Create [x,y] array where y is always 1
X = np.concatenate((F.price.values.reshape(-1,1),
(np.zeros(len(F))+1).reshape(-1,1)), axis = 1 )
cluster = AgglomerativeClustering(n_clusters=5,
affinity='euclidean', linkage='ward')
cluster.fit_predict(X)
F['clusters'] = cluster.labels_
F2 = F.loc[F.groupby('clusters')['price'].idxmax()]
# Plotit
fig, axis = plt.subplots()
for row in F2.itertuples():
axis.axhline( y = row.price,
color = 'green', ls = 'dashed' )
axis.plot( F.index.values, F.price.values )
plt.show()
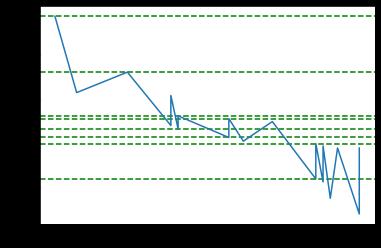
In [18]:
F2
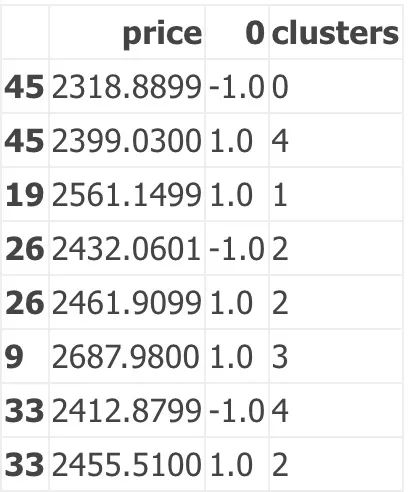
好的,这个数据看起来好多了。Google的阻力值约为2687.98,支撑位约为2399.03和2412.8799,这与支撑位约为2400相当接近。





点击下方阅读原文加入社区会员
以上是关于用聚类算法计算股票的支撑位和阻力位的主要内容,如果未能解决你的问题,请参考以下文章