理解Substrate数据存储的底层实现Merkle Patricia Trie
Posted 跨链技术践行者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理解Substrate数据存储的底层实现Merkle Patricia Trie相关的知识,希望对你有一定的参考价值。
[TOC]
通过本文,你会了解到:
- 区块链应用为什么使用Merkle Tree的数据结构;
- Substrate采用的Patricia Merkle Trie的特点和应用。
Merkle Tree介绍
Merkle Tree是一种数据结构,用来验证计算机之间存储和传输数据的一致性,如果不使用这一数据结构,一致性的验证需要消耗大量的存储和网络资源,如比对计算机之间的所有数据;使用Merkle Tree,只需要比对merkle root(根节点)就可以达到相同的效果。整个过程,简单的描述如下:
- 将数据通过哈希之后放置在叶子节点之中;
- 将相邻两个数据的哈希值组合在一起,得出一个新的哈希值;
- 依次类推,直到只有一个节点也就是根节点;
- 在验证另外的计算机拥有和本机相同的数据时,只需验证其提供的根节点和自己的根节点一致即可。
Merke Tree使用了加密哈希算法来快速验证数据一致性,常用的加密哈希算法有SHA-256,SHA-3,Blake2等,它们可以做到,
- 相同的输入有相同的输出;
- 对任意数据可以实现快速计算;
- 从哈希值无法推断出原信息;
- 不会碰撞(即不同输入对应相同输出);
- 输入即使只有很小的改变,输出也会有极大不同。

在区块链应用Bitcoin网络中,存储的数据为转移Bitcoin的交易,如“Alice发送给Bob 5个比特币”,通过使用Merkle Tree,除了上面提到的验证各个节点之间的数据一致性,还可以用来快速验证一个交易是否属于某个区块。轻节点只需要下载很少的数据就可以验证交易的有效性,例如下图所示,用户要验证交易T(D)在某个区块之中,需要依赖的数据仅仅是HC, HAB, HEFGH, 和 merkle root即HABCDEFGH。
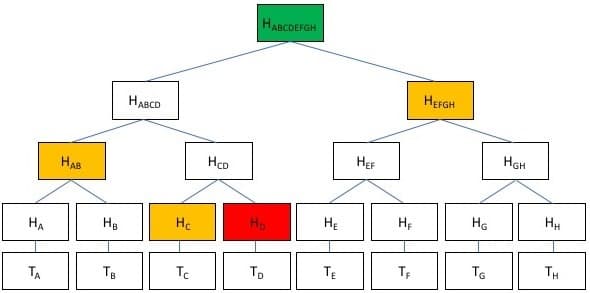
Merkle Patricia Trie原理
Trie
Patria Trie也是一种树形的数据结构,也称为Prefix Tree,Radix Tree,或者简称为Trie,最早来源于英文单词 retrieve,可以发音为try,常用的使用场景包括:
- 搜索引擎的自动补全功能;
- IP路由等。

Trie的特点是,某节点的key是从根节点到该节点的路径,即不同的key有相同前缀时,它们共享前缀所对应的路径。这种数据结构,可用于快速查找前缀相同的数据,内存开销较少。如以下数据及对应的trie表示为:
| key | value |
|---|---|
| to | 7 |
| tea | 3 |
| ted | 4 |
| ten | 12 |
| A | 15 |
| i | 11 |
| in | 5 |
| inn | 9 |

Substrate使用base-16,即每个节点最多有16个子节点:

MPT
Merkle Patricia Trie(下面简称MPT),在Trie的基础上,给每个节点计算了一个哈希值,在Substrate中,该值通过对节点内容进行Blake2运算取得,用来索引数据库和计算merkle root。也就是说,MPT用到了两种key的类型。
一种是Trie路径所对应的key,由runtime模块的存储单元决定。使用Substrate开发的应用链,它所拥有的各个模块的存储单元会通过交易进行修改,成为链上状态(简称为state)。每个存储单元的状态都是通过键值对以trie节点的形式进行索引或者保存的,这里键值对的value是原始数据(如数值、布尔)的SCALE编码结果,并作为MPT节点内容的一部分进行保存;key是模块、存储单元等的哈希组合,且和存储数据类型紧密相关,如:
- 单值类型(即Storage Value),它的key是
Twox128(module_prefix) ++ Twox128(storage_prefix); - 简单映射类型(即map),可以表示一系列的键值数据,它的存储位置和map中的键相关,即
Twox128(module_prefix) + Twox128(storage_prefix) + hasher(encode(map_key)); - 链接映射类型(即linked_map),和map类似,key是
Twox128(module_prefix) + Twox128(storage_prefix) + hasher(encode(map_key));它的head存储在Twox128(module) + Twox128("HeadOf" + storage_prefix); - 双键映射类型(即double_map),key是
twox128(module_prefix) + twox128(storage_prefix) + hasher1(encode(map_key1)) + hasher2(encode(map_key2))。
计算key所用到 Twox128 是一种非加密的哈希算法,计算速度非常快,但去除了一些严格的要求,如不会碰撞、很小的输入改变导致极大的输出改变等,从而无法保证安全性,适用于输入固定且数量有限的场景中。module_prefix通常是模块的实例名称;storage_prefix通常是存储单元的名称;原始的key通过SCALE编码器进行编码,再进行哈希运算,这里的哈希算法是可配置的,如果输入来源不可信如用户输入,则使用Blake2(也是默认的哈希算法),否则可以使用Twox。
另一种是数据库存储和计算merkle root使用的key,可以通过对节点内容进行哈希运算得到,在键值数据库(即RocksDB,和LevelDB相比,RocksDB有更多的性能优化和特性)中索引相应的trie节点。
Trie节点主要有三类,即叶子节点(Leaf)、有值分支节点(BranchWithValue)和无值分支节点(BranchNoValue);有一个特例,当trie本身为空的时候存在唯一的空节点(Empty)。根据类型不同,trie节点存储内容有稍许不同,通常会包含header、trie路径的部分key、children节点以及value。下面举一个具体例子。
Trie路径的key和value如下表所示:

将上表的数据展示为trie的结构之后得到下图:

图上所示内容的说明如下:
- 这里使用不同的header值来表示不同的节点类型,即01表示叶子节点,10表示无值的分支节点,11表示有值的分支节点。
- 为了提高存储和查找的效率,Substrate使用的MPT和基本的trie不同的是,并不是trie path key的每一位都对应一个节点,当key的连续位之间没有分叉时,节点可以直接使用该连续位。对于叶子节点,连续位可以是trie path key的最后几位;对于分支节点,连续位是从当前位开始到出现分叉位结束。
- 之前提到过,Substrate采用了base-16的trie结构,即一个分支节点最多可以有16个子节点。
接着,我们来添加每个节点的哈希:

首先计算出叶子节点的哈希值,它们被上一级的分支节点所引用,用来在数据库中查找对应的节点;然后计算分支节点的哈希值,直至递归抵达根节点,这里用到的哈希算法是Blake2。
数据库的物理存储大致如下:
| key | value |
|---|---|
| Hroot | encode(root_node) |
| H00 | encode(node_00) |
| H01 | encode(node_01) |
| H02 | encode(node_02) |
| H03 | encode(node_03) |
| H04 | encode(node_04) |
数据库中存储的key是上面所计算的节点哈希;存储的value是节点内容的特定编码,对于节点中保存的值是对应的SCALE编码结果。
RocksDB提供了column的概念,用来存储互相隔离的数据。例如,HEADER column存储着所有的区块头;BODY column存储着所有的区块体,也就是所有的存储单元状态。
Child Trie
Substrate还提供child trie这样的数据结构,它也是一个MPT。Substrate的应用链可以有很多child trie,每个child trie有唯一的标识进行索引,它们可以彼此隔离,提升存储和查询效率。State trie或者main trie的叶子节点可以是child trie的根哈希,来保存对应child trie的状态。Child trie的一个典型应用是Substrate的contracts功能模块,每一个智能合约对应着自己唯一的child trie。
区块裁剪
区块的无限增长往往给去中心的节点造成较大的存储消耗,通常只有少数的节点需要提供过往历史数据,大部分节点在能够确保状态最终性之后,可以将不需要的区块数据删除,从而提升节点的性能。Substrate也内置了裁剪的功能,示意图如下:

在区块13中,只有node-4的值从04变为40,其哈希也跟着改变,而其它节点的数据并没有变化,所以新的区块根节点可以复用原有节点,仅仅更新发生变化的节点。假设区块13已经具有最终性,那么区块12中的node-4就可以删除掉。Substrate默认的区块生成算法是BABE或者Aura,而最终性是通过GRANDPA来决定的,在网络稳定的情况下,仅保留一定数量的最新区块是可行的。
总结
本文介绍了区块链应用必不可少Merkle Tree,以及Substrate采用的Patricia Merkle Trie的不同之处。需要说明的是,Substrate还提供了强大的cache功能,来提升读写效率。
引用
Allow updating configuration of changes tries
Trie Data Structure | Insert and search
Understanding the ethereum trie
Diving into Ethereum’s world state
Merkle Tree & Merkle Root Explained
更多
Substrate官方文档:https://substrate.dev/
Parity介绍:https://www.parity.io/
Substrate源码:https://github.com/paritytech/substrate
Polkadot源码:https://github.com/paritytech/polkadot
以上是关于理解Substrate数据存储的底层实现Merkle Patricia Trie的主要内容,如果未能解决你的问题,请参考以下文章