Optimism Rollup原理详解
Posted 跨链技术践行者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Optimism Rollup原理详解相关的知识,希望对你有一定的参考价值。
Optimism Rollup是目前最流行的以太坊L2解决方案。本文将解释Optimism Rollup每个设计决策背后的动机, 剖析Optimism的系统实现,并提供指向每个分析组件的相应代码的链接,适用于希望了解Optimism解决方案的 工作原理并评估所提议系统的性能和安全性的开发人员。
1、软件重用原则在Optimism Rollup中的重要性
以太坊已经围绕其开发者生态系统发展了护城河。开发人员的技术栈包括:
- Solidity/ Vyper:这是两种最流行的智能合约编程语言,有很多工具链围绕它们构建,例如 Ethers、Hardhat、 dapp、slither等。
- 以太坊虚拟机:最流行的区块链虚拟机,其内部设计比任何其他区块链VM都要好得多。
- Go-ethereum:主流以太坊协议实现,采用率 > 75%,经过了广泛的测试。
由于Optimism Rollup将以太坊作为其第1层,因此如果我们可以无需修改即可重用现有工具,那就太好了。 这将改善开发人员的体验,因为开发人员无需学习新技术。虽然已经多次提出,但是我想强调软件重用 的另一个含义:安全性。
2、Optimistic虚拟机
Optimism Rollup依赖于使用欺诈证明来防止发生无效的状态转换。这需要在以太坊上执行Optimsim交易。简而言之, 如果交易结果存在争议,例如修改了Alice的ETH余额,Alice将尝试在以太坊上重放该确切的交易,以证明那里的 结果是正确的。但是,如果某些EVM操作码依赖于系统范围内的参数,这些参数可能随时都会改变,例如加载或存储状态或 获取当前时间戳,则它们在L1和L2上的行为将不同。
因此,Optimsim的第一个技术,就是处理L1上的L2争端的机制,该机制保证可以重现在L1上执行L2事务时存在的 任何“上下文”,并且在理想情况下不引入太多开销。
目标是实现一个沙盒环境,可确保在L1和L2之间确定性地执行智能合约。
Optimism的解决方案是Optimistic虚拟机。OVM是通过将上下文相关的EVM操作码替换为其对应的OVM操作码来实现的。
一个简单的例子是:
- L2交易调用TIMESTAMP操作码,例如返回1610889676
- 一个小时后,由于某种原因,交易都必须在以太坊L1上重放
- 如果要在EVM中正常执行该交易,则TIMESTAMP操作码将返回1610889676 +3600。这不是我们希望的,因为这将导致交易执行上下文的变化。
- 在OVM中,在L2上执行交易时,TIMESTAMP操作码将替换为ovmTIMESTAMP,因此将显示正确值的操作码。
所有与上下文相关的EVM操作码在OVM核心合约在ExecutionManager中都有一个对应的ovm{OPCODE}。合约的执行是从EM的 入口点run函数开始的。这些操作码也已修改为可以与可插拔状态数据库交互,其作用我们将在“欺诈证明”部分中进行介绍。
某些在OVM中“无意义”的操作码会通过Optimism的SafetyChecker合约禁用,Optimism合约采用静态分析技术,可以有效地 判断合约是否OVM安全并返回1或0。
请查阅附录部分以了解每个被修改/禁用的EVM操作码。
Optimism Rollup看起来像这样:

上图中问号标注的组件将在下面的欺诈证明部分说明,但在此之前,我们需要进一步解释一些基础知识。
3、Optimisitic Solidity编译器
现在我们有了OVM沙箱,接下来要做的就是将智能合约编译为OVM字节码。下面是一些可选的方案:
- 发明一种新的可以编译为OVM的智能合约语言:这个思路很容易被放弃,因为它需要从头开始重新做所有事情,而且 我们已经就这一点达成一致,即尽可能重用已有的技术栈。
- 将EVM字节码转换为OVM字节码:已尝试但由于复杂性而被放弃。
- 修改Solidity和Vyper编译器以生成OVM字节码。
Optimism当前使用的方法是第三种,Optimsim更改了socl大约500行代码。
Solidity编译器的工作原理是将Solidity转换为Yul,然后转换为EVM指令,最后转换为字节码。Optimism所做的更改 既简单又优雅:对于每个操作码,在编译为EVM汇编后,如有必要,尝试以ovm变体“重写”它(如果被禁止则抛出错误)。
解释起来有点复杂,下面让我们比较一个简单合约的EVM和OVM字节码:

用solc编译一下:
1 2 | $ solc C.sol --bin-runtime --optimize --optimize-runs 200 6080604052348015600f57600080fd5b506004361060285760003560e01c8063c298557814602d575b600080fd5b60336035565b005b60008054600101905556fea264697066735822122001fa42ea2b3ac80487c9556a210c5bbbbc1b849ea597dd6c99fafbc988e2a9a164736f6c634300060c0033 |
我们可以反汇编此代码看一下得到的汇编代码,括号内表示Program Counter:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | ...
[025] 35 CALLDATALOAD
...
[030] 63 PUSH4 0xc2985578 // id("foo()")
[035] 14 EQ
[036] 60 PUSH1 0x2d // int: 45
[038] 57 JUMPI // jump to PC 45
...
[045] 60 PUSH1 0x33
[047] 60 PUSH1 0x35 // int: 53
[049] 56 JUMP // jump to PC 53
...
[053] 60 PUSH1 0x00
[055] 80 DUP1
[056] 54 SLOAD // load the 0th storage slot
[057] 60 PUSH1 0x01
[059] 01 ADD // add 1 to it
[060] 90 SWAP1
[061] 55 SSTORE // store it back
[062] 56 JUMP
...
|
上述汇编代码的意思是,如果calldata匹配函数foo()的选择器,则使用SLOAD操作码载入0x00处的存储变量, 加上0x01,最后将结果使用SSTORE操作码存回去。听起来不错!
在OVM中看起来如何?首先用修改后的solc编译:
1 2 | $ osolc C.sol --bin-runtime --optimize --optimize-runs 200 60806040523480156100195760008061001661006e565b50505b50600436106100345760003560e01c8063c298557814610042575b60008061003f61006e565b50505b61004a61004c565b005b6001600080828261005b6100d9565b019250508190610069610134565b505050565b632a2a7adb598160e01b8152600481016020815285602082015260005b868110156100a657808601518282016040015260200161008b565b506020828760640184336000905af158601d01573d60011458600c01573d6000803e3d621234565260ea61109c52505050565b6303daa959598160e01b8152836004820152602081602483336000905af158601d01573d60011458600c01573d6000803e3d621234565260ea61109c528051935060005b60408110156100695760008282015260200161011d565b6322bd64c0598160e01b8152836004820152846024820152600081604483336000905af158601d01573d60011458600c01573d6000803e3d621234565260ea61109c5260008152602061011d56 |
得到的字节码更长了,让我们再次反汇编一下,看看有什么变化:
1 2 3 4 5 6 7 8 9 10 11 | ...
[036] 35 CALLDATALOAD
...
[041] 63 PUSH4 0xc2985578 // id("foo()")
[046] 14 EQ
[047] 61 PUSH2 0x0042
[050] 57 JUMPI // jump to PC 66
...
[066] 61 PUSH2 0x004a
[069] 61 PUSH2 0x004c // int: 76
[072] 56 JUMP // jump to PC 76
|
这一部分还是检查是否匹配指定的函数选择器,让我们看看之后会发生什么。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | ...
[076] 60 PUSH1 0x01 // Push 1 to the stack (to be used for the addition later)
[078] 60 PUSH1 0x00
[080] 80 DUP1
[081] 82 DUP3
[082] 82 DUP3
[083] 61 PUSH2 0x005b
[086] 61 PUSH2 0x00d9 (int: 217)
[089] 56 JUMP // jump to PC 217
...
[217] 63 PUSH4 0x03daa959 // <---| id("ovmSLOAD(bytes32)")
[222] 59 MSIZE // |
[223] 81 DUP2 // |
[224] 60 PUSH1 0xe0 // |
[226] 1b SHL // |
[227] 81 DUP2 // |
[228] 52 MSTORE // |
[229] 83 DUP4 // |
[230] 60 PUSH1 0x04 // | CALL to the CALLER's ovmSLOAD
[232] 82 DUP3 // |
[233] 01 ADD // |
[234] 52 MSTORE // |
[235] 60 PUSH1 0x20 // |
[237] 81 DUP2 // |
[238] 60 PUSH1 0x24 // |
[240] 83 DUP4 // |
[241] 33 CALLER // |
[242] 60 PUSH1 0x00 // |
[244] 90 SWAP1 // |
[245] 5a GAS // |
[246] f1 CALL // <---|
[247] 58 PC // <---|
[248] 60 PUSH1 0x1d // |
[250] 01 ADD // |
[251] 57 JUMPI // |
[252] 3d RETURNDATASIZE // |
[253] 60 PUSH1 0x01 // |
[255] 14 EQ // |
[256] 58 PC // |
[257] 60 PUSH1 0x0c // |
[259] 01 ADD // |
[260] 57 JUMPI // | Handle the returned data
[261] 3d RETURNDATASIZE // |
[262] 60 PUSH1 0x00 // |
[264] 80 DUP1 // |
[265] 3e RETURNDATACOPY // |
[266] 3d RETURNDATASIZE // |
[267] 62 PUSH3 0x123456 // |
[271] 52 MSTORE // |
[272] 60 PUSH1 0xea // |
[274] 61 PUSH2 0x109c // |
[277] 52 MSTORE // <---|
|
上面代码包含很多操作,要点在于这里不是使用SLOAD操作码,而是构造一个栈以便执行CALL操作码。 调用的接收者通过CALLER操作码被压入栈。每一个调用都是来自EM,因此实际上CALLER是调用EM的有效方法。 调用的数据以ovmSLOAD(bytes32)函数的选择器开头,接下来是参数(在这个示例中,就是占用32字节的字)。 之后,将处理返回的数据并将其添加到内存中。
让我们继续:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | ...
[297] 82 DUP3
[298] 01 ADD // Adds the 3rd item on the stack to the ovmSLOAD value
[299] 52 MSTORE
[308] 63 PUSH4 0x22bd64c0 // <---| id("ovmSSTORE(bytes32,bytes32)")
[313] 59 MSIZE // |
[314] 81 DUP2 // |
[315] 60 PUSH1 0xe0 // |
[317] 1b SHL // |
[318] 81 DUP2 // |
[319] 52 MSTORE // |
[320] 83 DUP4 // |
[321] 60 PUSH1 0x04 // |
[323] 82 DUP3 // |
[324] 01 ADD // | CALL to the CALLER's ovmSSTORE
[325] 52 MSTORE // | (RETURNDATA handling is omited
[326] 84 DUP5 // | because it is identical to ovmSSLOAD)
[327] 60 PUSH1 0x24 // |
[329] 82 DUP3 // |
[330] 01 ADD // |
[331] 52 MSTORE // |
[332] 60 PUSH1 0x00 // |
[334] 81 DUP2 // |
[335] 60 PUSH1 0x44 // |
[337] 83 DUP4 // |
[338] 33 CALLER // |
[339] 60 PUSH1 0x00 // |
[341] 90 SWAP1 // |
[342] 5a GAS // |
[343] f1 CALL // <---|
...
|
类似于将SLOAD调整到外部调用ovmSLOAD,SSTORE也调整到外部调用ovmSSTORE。调用的数据不同,因为ovmSSTORE 需要两个参数,即存储插槽和要存储的值。下面是两者的比较:

实际上,我们先调用Execution Manager的ovmSLOAD方法,然后再调用其ovmSTORE方法,而不是SLOAD和SSTORE。
通过比较EVM与OVM的执行(我们仅显示执行的SLOAD一部分),我们可以看到通过Execution Manager进行的虚拟化:

这种虚拟化技术有一个“陷阱”:
会导致更快达到合约大小上限 :通常,以太坊合约的字节码最大24KB 。使用Optimistic Solidity Compiler编译的 合约最终比原来大,这意味着必须重构接近24KB限制的合约,以便其OVM大小仍适合24KB限制,因为它们需要在以太坊 主网上执行。
4、Optimistic Geth
以太坊最流行的实现是go-ethereum(即geth)。让我们看看通常如何在Geth中执行交易。
在每个块上,调用状态处理器的Process方法,该方法对每个交易执行ApplyTransaction方法。在内部,交易被转换为 消息,消息被应用于当前状态,最后将新产生的状态存储回数据库中。
此核心数据流在Optimistic Geth上保持不变,但进行了一些修改以保持交易“对OVM友好”:
修改1:通过Sequencer入口点的OVM消息
交易被转换为OVM消息。由于除去了消息的签名,因此消息数据被修改为包括交易签名以及原始交易的其余字段。to字段 将替换为“Sequencer入口点”合约的地址。这样做是为了使交易格式紧凑,因为它将被发布到以太坊,并且我们已经确定, 好紧凑伸缩性就越好。
修改2:通过执行管理器的OVM沙箱
为了通过OVM沙箱运行交易,必须将它们发送到Execution Manager的run 功能。不要求用户仅提交符合该限制的交易, 所有消息都被修改为在内部发送到Execution Manager。这里很简单:消息的to字段被替换为执行管理器的地址,并且消息 的原始数据被打包为参数传入run。
这可能有点不直观,因此我们提供了代码以给出一个具体示例:https : //github.com/gakonst/optimism-tx-format。
修改3:拦截对状态管理器的调用
StateManager是一个特殊的合约,在Optimistic Geth 上并不存在。仅在欺诈证明期间部署它。细心的读者会注意到, 当打包参数以进行run调用时,Optimism的geth还将打包一个硬编码的State Manager地址。这就是最终被用作任何 ovmSSTORE或ovmSLOAD(或类似)调用的最终目的地的原因。在L2上运行时,以State Manager合约为目标的所有消息 都将被拦截,并且它们被连接为直接与Geth的StateDB对话(或不执行任何操作)。
对于寻求整体代码更改的人们来说,最好的方法是搜索UsingOVM并比较geth 1.9.10的差异。
修改4:基于epoch的批次而不是块
OVM没有块,它仅维护交易的有序列表。因此,没有区块gas限制的概念;取而代之的是,根据时间段(称为epoch)限制 总的gas消耗率。在执行交易之前,要检查是否需要启动一个新的epoch,在执行之后,将其gas小号添加到该epoch所使用 的累积gas用量上。对于Equenecer提交的交易和“ L1至L2”交易,每个epoch都有单独的gas限制。任何超过gas限值的交易 将提前返回。这意味着操作员可以在一个链上批次中发布多个具有不同时间戳的交易(时间戳由Sequencer定义,但有一些 限制,我们将在“数据可用性批处理”部分中说明)。
修改5:Rollup同步服务
该同步服务是一个新的进程运行,它与“正常” GETH同时运行。Rollup同步服务负责监视以太坊日志,对其进行处理, 并通过geth的worker注入要在L2状态下应用的相应L2交易。
5、Optimistic Rollup
Optimistic Rollup的主要特性包括:
- OVM作为其运行时/状态迁移函数
- 拥有单个Sequencer的Optimistic Geth作为L2客户端
- 在以太坊上部署的Solidity智能合约用于:
- 数据可用性
- 争议解决和欺诈证明,我们将深入研究实现数据可用性层的智能合约,并探索端到端的欺诈证明流程。
数据可用性批次
如前所述,交易数据被压缩,然后发送到L2上的Sequencer Entrypoint合约。然后,Sequencer负责“汇总”这些交易, 并在以太坊上发布数据,提供数据可用性,以便即使Sequencer消失了,也可以启动新的Sequencer以从中断的地方继续。
依靠以太坊实现该逻辑的智能合约称为权威交易链(CTC:Canonical Transaction Chain)。权威交易链是一个追加型 日志,它代表Rollup链的“正式历史”(所有交易以及其顺序)。交易可以由Sequencer等提交给CTC。为了保留L1的抗审查 能力,任何人都可以将交易提交到此队列,并在一定滞后期之后将其包括在CTC中。
CTC为每批发布的L2交易提供数据可用性。可以通过两种方式创建批处理:
- 预计每隔几秒钟,Sequencer就会检查接收到的新交易,将它们分批汇总,以及所需的任何其他元数据。然后,他们 利用appendSequencerBatch将该数据发布到以太坊。这是由批处理提交者服务自动完成的。
- 当Sequencer审查其用户或当用户执行从L1到L2的交易,用户需要调用enqueue和appendQueueBatch,这会强制在CTC中 包含交易
这里的一个极端情况是:如果Sequencer广播了一个批次,则用户可以强制包含涉及与该批次冲突的状态的交易,从而 可能使该批次的某些交易无效。为了避免这种情况,我们引入了时间延迟,在此延迟之后可以由非Sequencer帐户将批处理 追加到队列中。对此进行考虑的另一种方法是,给利用appendeSequencerBatcher添加的交易一个“宽限期”,否则用户 使用appendQueueBatch。
鉴于大多数交易预计将通过Sequencer提交,因此有必要深入研究批处理结构和执行流程。
你可能会注意到,appendSequencerBatch没有任何参数。批次以紧密打包的格式提交,而使用ABI编码和解码则效率要 低得多。它使用内联汇编来对calldata进行切片,并以预期的格式将其解压缩。
一个批次由以下部分组成:
- 批次头
- 批处理上下文(> = 1,请注意:此上下文与我们在上面的“ OVM”部分中提到的消息/交易/全局上下文不同)
- 交易(> = 1)
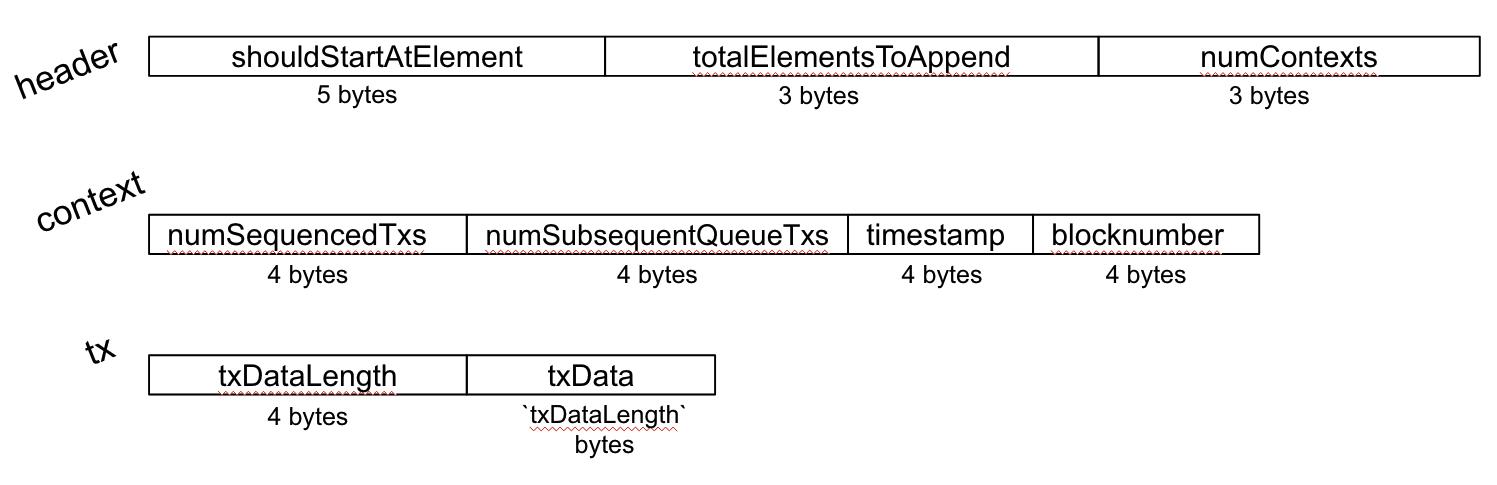
批次头指定了上下文的数量,因此序列化的批处理看起来像是 [header, context1, context2, …, tx1, tx2, … ]
该函数继续执行以下两项操作:
- 验证所有与上下文相关的不变量是否适用
- 根据已发布的交易数据创建默克尔树
如果通过了上下文验证,则该批次将转换为OVM链批次头,然后将其存储在CTC中。
存储的批次头包含该批次的merkle根,这意味着证明已包含交易是提供针对针对CTC中存储的merkle根进行验证的 merkle证明的简单问题。
这里的自然问题是:这似乎太复杂了!为什么需要上下文?
上下文对于Sequencer来说是必要的,以便知道是否应在已排序交易之前或之后执行已排队的交易。让我们来看一个例子:
在时间T1,Sequencer已接收到2个交易,它们将包括在其批次中。在T2(> T1)用户也排队的交易时,将它添加到L1到 L2交易队列(但不将其添加到批次!)。在T2,Sequencer又接收到1个交易,另外2个交易也入队列。换句话说,待处理 交易的批处理看起来像:
1 | [(sequencer, T1), (sequencer, T1), (queue, T2), (sequencer, T2), (queue, T3), (queue, T4)] |
为了保持时间戳和块号信息,同时又保持序列化格式的紧凑性,我们使用了“上下文”,即Sequencer和排队交易之间的 共享信息集合。上下文必须严格增加块数和时间戳。在上下文中,所有Sequencer交易共享相同的块号和时间戳。 对于“队列交易”,将时间戳和块号设置为调用队列时的值。在这种情况下,该批交易的上下文为:
1 | [{ numSequencedTransactions: 2, numSubsequentQueueTransactions: 1, timestamp: T1}, {numSequencedTransactions: 1, numSubsequentQueueTransactions: 2, timestamp: T2}]
|
状态承诺
在以太坊中,每个交易都会导致对状态以及全局状态根的修改。通过在某个区块提供状态根并通过默克尔证明来 证明某个帐户在某个区块拥有一些ETH,以证明该账户的状态与所声明的值匹配。因为每个块包含多个交易,并且我们 只能访问状态根,所以这意味着我们只能在执行整个块后才声明状态。
一段历史:
在EIP98和Byzantium分叉之前,以太坊交易在每次执行后产生中间状态根,这些根通过交易收据提供给用户 删除中间状态根能够提高性能,虽然有一点小缺陷,因此很快就采用了它。EIP PR658中提供的其他动机解决了该问题: 收据的PostState字段(指示与tx执行后的状态相对应的状态根)被布尔状态字段(指示交易的成功状态)替换。
事实证明,警告并非无关紧要。EIP98写道:
所做的更改确实意味着,如果矿工创建了一个区块,其中一个状态转换的处理不正确,那么就不可能针对该交易 提供欺诈证明;相反,欺诈证明必须包含整个区块。
此更改的含义是,如果一个区块有1000个交易,并且你在第988个交易中检测到欺诈,则在实际执行你感兴趣的交易 之前,需要在前一个区块的状态之上运行987个交易,这会使欺诈证明效率极低。以太坊本身没有欺诈证明,所以没关系!
另一方面,Optimism的欺诈证据是至关重要的。在前面,我们提到Optimism没有区块,那只是个小谎言:Optimism有区块, 但是每个区块只有1个交易,我们称之为“微区块”。由于每个微块包含1个交易,因此每个块的状态根实际上是单个交易 产生的状态根。乌拉!我们已经重新引入了中间状态根,而不必对协议进行任何重大更改。当然,由于微块在技术上 仍然是块并且包含冗余的其他信息,因此当前当然具有恒定的性能开销,但是这种冗余可以在将来删除(例如,使所有 微块都具有0x0作为块哈希,并且仅填充RPC中的修剪字段以便向后兼容)。
现在,我们可以介绍状态承诺链(SCC:State Commitment Chain)。SCC包含状态根列表,在乐观情况下,该列表对应于 针对先前状态在CTC中应用每个交易的结果。如果不是这种情况,则欺诈验证过程将删除无效的状态根,然后删除所有 无效的状态根,以便可以为这些交易提出正确的状态根。
与CTC相反,SCC没有任何酷炫的数据表示形式。它的目的很简单:给定状态根列表,它会对其进行存储并保存批处理中 包含的中间状态根的merkle根,以供以后通过appendStateBatch用作欺诈证明。
欺诈证明
既然我们了解了OVM的基本概念以及将其状态锚定在以太坊上的支持功能,那么让我们深入探讨争端解决程序, 也就是欺诈证明。
Sequencer执行3件事:
- 接收用户提交的交易
- 批量汇总这些交易并将其发布在权威交易链中
- 在状态承诺链中将交易产生的中间状态根发布为状态批。
例如,如果在CTC中发布了8个交易,则对于每个状态从S1到S8的转换,在SCC中都会有8个状态根。
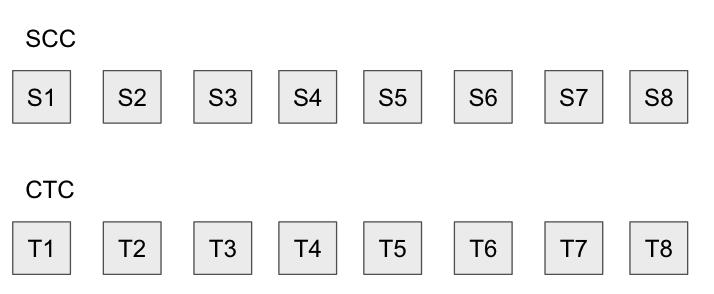
但是,如果Sequencer是恶意的,他们可以在状态Trie中将其帐户余额设置为1000万个ETH,这显然是非法的操作, 从而使状态根及其后面的所有状态根均无效。他们可以通过发布看起来像这样的数据来做到这一点:
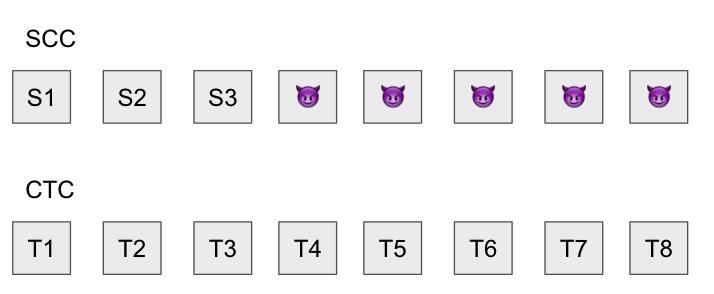
我们注定要失败吗?我们必须做点什么!
众所周知,Optimistic Rollup假定存在验证者:对于Sequencer发布的每个交易,验证者负责下载该交易并将其 应用于本地状态。如果一切都匹配,它们什么也不做,但是如果不匹配,那就有问题了!为了解决该问题,他们 将尝试在以太坊上重新执行T4以产生S4。然后,将修剪所有在S4之后发布的状态根,因为无法保证它对应于有效状态:
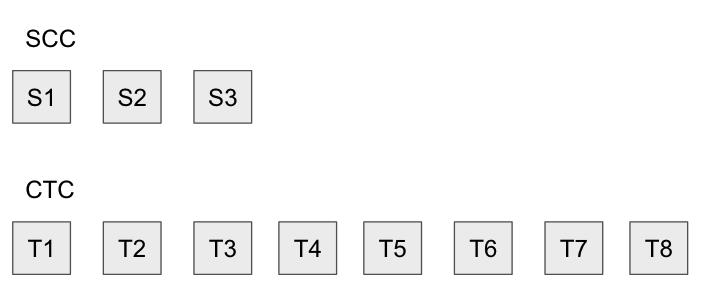
从较高层面来说,欺诈证明是“以S3作为我的开始状态,我想证明在S3上应用T4会导致S4,这与Sequencer发布的内容 不同(😈)。结果,我希望删除S4及其之后的所有内容。”
如何实施?
在图1中看到的是OVM在L2中以其“简单”执行模式运行。在L1上运行时,OVM处于防欺诈模式,并且启用了它的更多组件( 在L1和L2上都部署了Execution Manager和Safety Checker ):
- 欺诈验证者:负责协调整个欺诈证明验证过程的合约。它调用的状态迁移工厂来初始化一个新的欺诈证据, 如果证据造假成功,它将修剪这是从状态承诺链的争议点之后发布的任何批次。
- State Transitioner(状态转换程序):当使用前置状态的根创建争议并且有争议的交易时,由欺诈验证程序部署。 其职责是调出执行管理器,并根据规则忠实地执行链上交易,以为有争议的交易产生正确的事后状态根源。成功 执行的欺诈证明将导致状态转移器中的后状态根与状态承诺链中的状态根不匹配。状态转换器可以处于以下3种状态 中的任何一种:PRE EXECUTION, POST EXECUTION, COMPLETE。
- 状态管理器:用户提供的任何数据都存储在此处。这是一个“临时”状态管理器,仅部署用于欺诈证明,并且仅包含 有关有争议的交易涉及的状态的信息。
在防欺诈模式下运行的OVM如下所示:
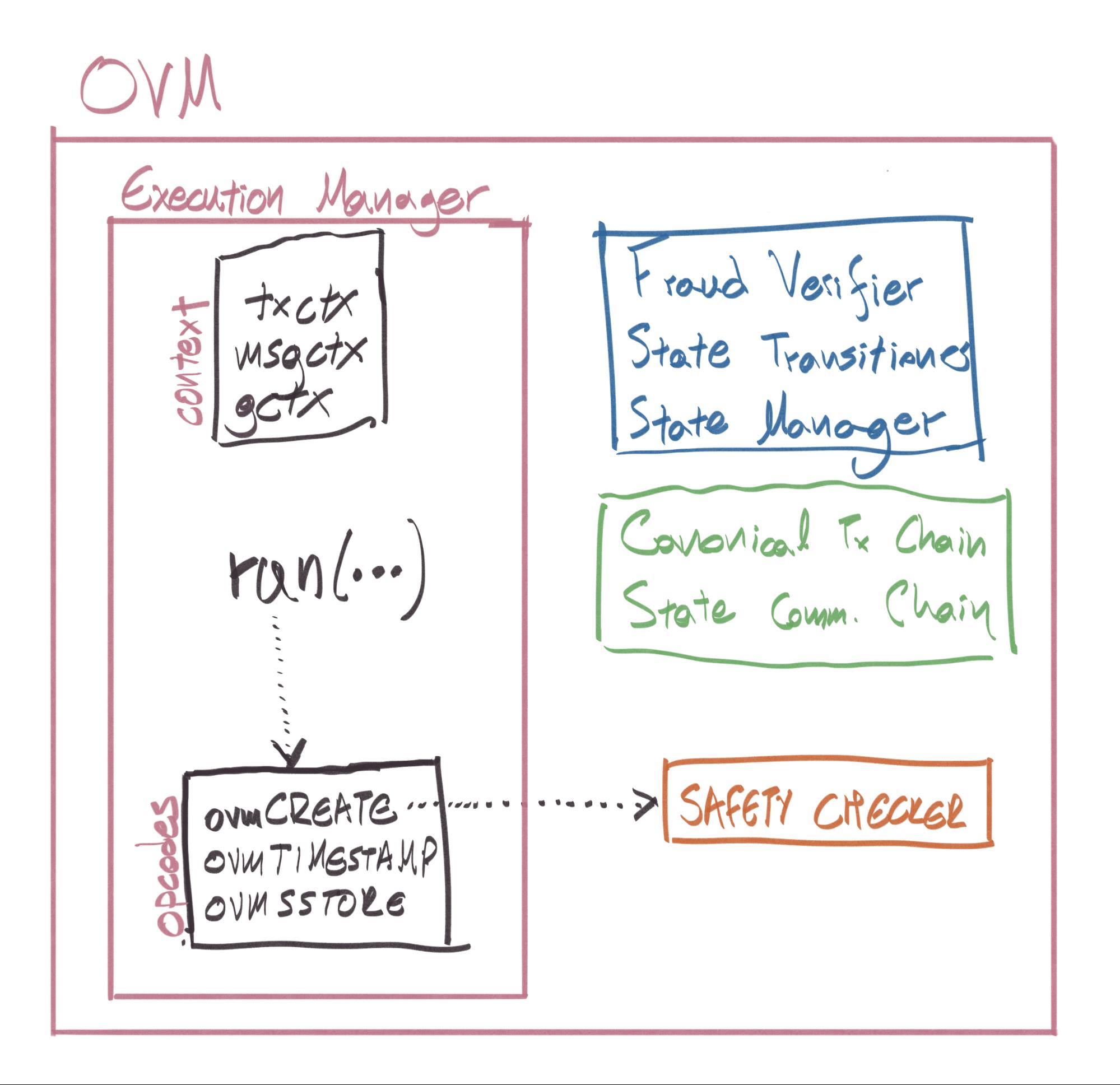
欺诈证明分为几个步骤:
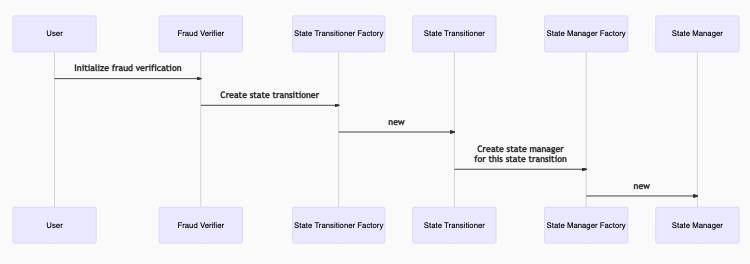
步骤1:声明您要争议的状态转换
- 用户调用欺诈验证者的initializeFraudVerification,提供状态前的根(及其在状态承诺链中的证明)和有争议的 交易(及其在交易链中的证明)。
- State Transitioner合约是通过State Transitioner工厂部署的。
- 通过状态管理工厂部署状态管理合约。它不会包含整个L2状态,而是仅填充交易所需的部分;你可以将其视为“部分状态管理员”。
State Transitioner现在处于PRE EXECUTION阶段。
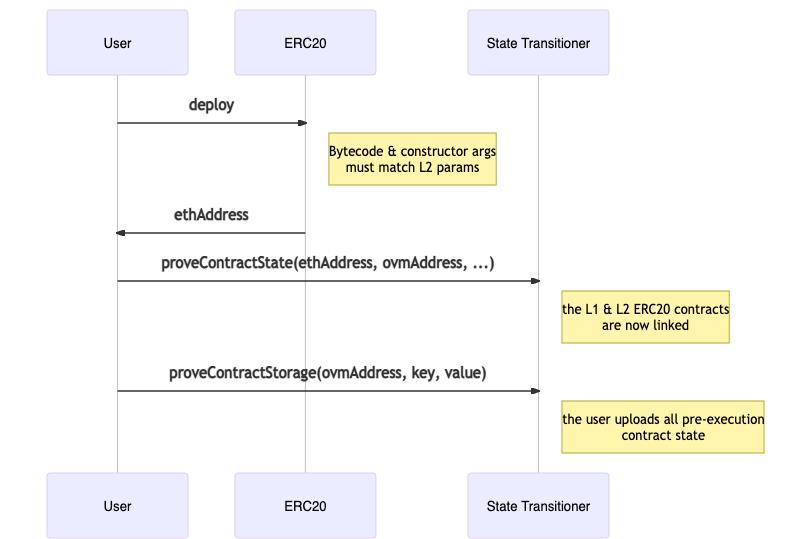
步骤2:上传所有交易状态
如果我们尝试直接执行有争议的交易,则该交易将立即失败,并显示INVALID_STATE_ACCESS错误,因为从步骤1开始, 在刚部署的L1状态管理器上未加载任何涉及的L2状态。OVM沙箱将检测是否SM尚未填充某些触摸状态,并强制首先加载 所有触摸状态需求。
例如,如果有争议的交易是简单的ERC20代笔转移,则初始步骤为:
- 在L1、L2上部署ERC20 :L2和L1合约的字节代码必须匹配,才能在L1和L2之间执行相同的操作。我们保证在字节码 前加一个“魔术”前缀,将其复制到内存中并存储在指定地址。
- 调用proveContractState:这会将L2 OVM合约与新部署的L1 OVM合同链接在一起(合约已部署并链接,但仍未加载存储)。链接是指将OVM地址用作映射中的键,其中值是包含合同帐户状态的结构。
- 调用proveStorageSlot:标准ERC20转账会减少发送者余额,增加接收者的余额。这将在执行交易之前上载接收方和发送方 的余额。对于ERC20,余额通常存储在映射中,因此根据Solidity的存储布局,键将为keccak256(slot + address)。
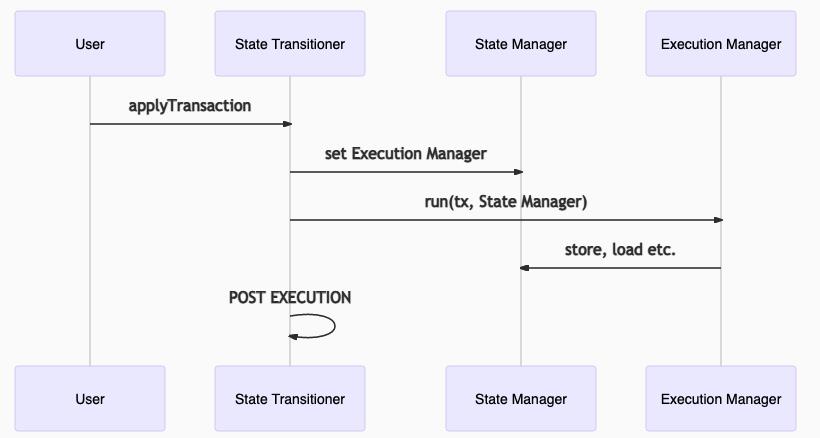
步骤3:一旦提供所有预状态,请运行交易
然后,用户必须通过调用State Transitioner的applyTransaction来触发交易的执行。在此步骤中,执行管理器开始使用 欺诈证明的状态管理器执行交易。执行完成后,状态转换程序过渡到该POST EXECUTION阶段。
步骤4:提供后期状态
在L1上执行期间(步骤3),合同存储位或帐户状态(例如,随机数)中的值将更改,这将导致状态转换程序的后状态根 更改。但是,由于状态转换器/状态管理器对不知道整个L2状态,因此它们无法自动计算新的后状态根。
为了避免这种情况,如果存储插槽或帐户状态的值发生更改,则将存储插槽或帐户标记为“ changed”,并增加未提交的 存储插槽或帐户的计数器。我们要求对于每个更改的项目,用户还必须提供L2状态的防弯证明,表明这确实是所观察到的 值。每次“提交”存储插槽更改时,都会更新合约帐户的存储根目录。在提交所有更改的存储插槽后,合约的状态也将提交, 从而更新过渡器的后状态root。对于发布的每个后期状态数据,该计数器相应地递减。
因此,可以预期,在交易中涉及的所有合约的状态更改都已提交之后,结果后的状态根是正确的。

步骤5:完成状态转换并最终确定欺诈证明
完成状态转换是一个简单的completeTransition调用过程,它要求步骤4中的所有帐户和存储插槽都已提交(通过检查 未提交状态的计数器等于0来进行)。
最后,在Fraud Verifier合约上调用finalizeFraudVerification,该合约检查状态转换程序是否完成,如果是, 则调用deleteStateBatch,该方法它继续从SCC删除(包括)有争议的交易之后的所有状态根批处理。CTC保持不变, 因此原始交易将以相同顺序重新执行。

激励+债券
为了使系统保持开放并无需许可,SCC旨在允许任何人成为Sequencer并发布状态批。为避免SCC被垃圾数据淹没, 我们引入了1个限制:
Sequencer必须由债券管理器智能合约标记为抵押品。你需要存入固定金额的抵押品,并且可以在7天后提取该金额。
但是,在抵押后,恶意的提议者可以反复创建欺诈性的状态根源,希望没有人对此提出异议,从而使他们有钱。 如果忽略用户从Rollup和恶意Sequencer社交协调迁移的场景,那么这里的攻击成本极低。
该解决方案在L2系统设计中是非常标准的:如果成功证明了欺诈,则X%的提议者的保证金会被烧掉13,剩余的(1-X)% 会按比例分配给每个为第2步和第4步提供数据的用户。现在,Sequencer的背叛成本要高得多,并且假设它们的行为合理, 则有望创造足够的诱因来防止它们恶意行为。即使有争议状态没有直接影响他们,这也为用户提供了一个诱人的诱因, 使他们提交数据以证明欺诈行为。
nuisance gas
有一个单独的gas维度,称为“有害gas”,用于限制欺诈证明的净gas成本。特别是,L2 EVM gas成本表中未反映欺诈证明 建立阶段的证人数据(例如,默克尔证明)。ovmOPCODES针对nuisance gas需要另外付费,每当触摸一个新的存储槽或 帐户时,都会收取费用。如果消息尝试使用超出消息上下文允许范围的nuisance gas,则执行恢复。
以上是关于Optimism Rollup原理详解的主要内容,如果未能解决你的问题,请参考以下文章