机器学习:Sklearn库中linear_model线性模型中‘LinearRegression‘线性回归源码理解
Posted 天海一直在
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习:Sklearn库中linear_model线性模型中‘LinearRegression‘线性回归源码理解相关的知识,希望对你有一定的参考价值。
最近这段时间学习了机器学习中的线性模型,用自己定义的最小二乘法函数和sklearn中的linear_model方法完成了几个小实例,具体就是通过我们班同学的各科成绩来预测最后的平均绩点模型,但不清楚sklearn库中的源码就直接调用都有点不好意思了~~在这里主要还是想记录一下我对于LinearRegression的理解。
打开pycharm,安装好scikit-learn库后在Python-Package中可以找到scikit-learn,点开它会显示此库的一些信息。
点击文档-->Regression,官方文档里详尽写了sklearn中的各种模型的用法和实例。
这里不多赘述,直接上源码!!!
from sklearn import linear_model新建python文件后输入上行代码 ,按住Ctrl键左键点击linear_model就会进入_init_.py,在里面找到'LinearRegression',同样按住Ctrl键左键点击进入_base.py,此时看到的就是sklearn中线性回归模型的源码。
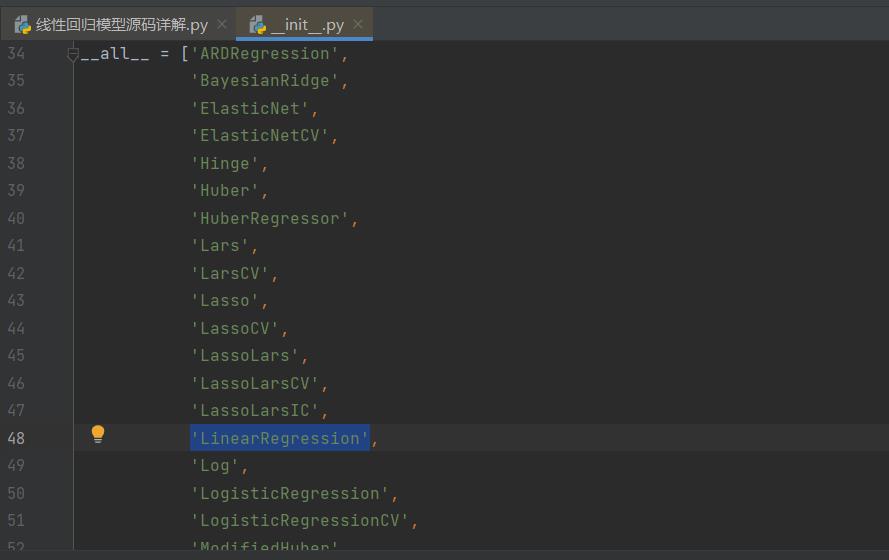
#################################从这里开始看 #################################
class LinearRegression(MultiOutputMixin, RegressorMixin, LinearModel):注释部分写有
一、简介
普通最小二乘法线性回归。
线性回归拟合一个系数为w = (w1,…wp)中观测目标之间的残差平方和(剩余平方和)最小数据集和线性逼近预测的目标。
二、参数(Parameters)
fit_intercepe:是否计算模型的截距,截距就是公式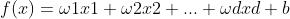 中的“b”,布尔类型,默认值为True
中的“b”,布尔类型,默认值为True
normalize:是否标准化,标准化可以使不同的特征具有相同的维度(尺度),布尔类型,默认值为False
copy_X:是否复制x,否则得出的x值将被正则化覆盖,布尔类型,默认值为True
n_jobs:用于计算的核数,设为-1时最快,int类型,默认值为1
positive:强制系数为正数。仅支持密集阵列。布尔类型,默认值为False
源码如下:
@_deprecate_positional_args
def __init__(self, *, fit_intercept=True, normalize=False, copy_X=True,
n_jobs=None, positive=False):
self.fit_intercept = fit_intercept
self.normalize = normalize
self.copy_X = copy_X
self.n_jobs = n_jobs
self.positive = positive三、属性(Attributes)
coef_:线性回归问题的系数,即公式中各特征x前的系数w。
rank_:矩阵X的秩,仅当' X '密集时可用
singular_:数组的形状(min(X, y))' X '的奇异值。仅当' X '密集时可用。
intercept_:线性模型中的独立项。截距b(或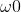 ),只能为数组型(array)和浮点数(float)型
),只能为数组型(array)和浮点数(float)型
属性我们可以这样用:
model = linear_model.LinearRegression()
model.fit(x_data, y_data)
print("系数w:", model.coef_)
print("偏置项b:", model.intercept_)运行代码后可在运行栏中观察到系数和偏置项的结果(有几个特征就有几个系数w)
系数w: [0.03835515 0.03039367]
偏置项b: -2.4193839868128992今天就为大家分享到这里,学习阶段,第一次写文章,不知道效果如何,有不足望指正!!!
以上是关于机器学习:Sklearn库中linear_model线性模型中‘LinearRegression‘线性回归源码理解的主要内容,如果未能解决你的问题,请参考以下文章