Tensorflow 2 实战(kears)- 双层RNN/LSTM/GRU
Posted muxinzihan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tensorflow 2 实战(kears)- 双层RNN/LSTM/GRU相关的知识,希望对你有一定的参考价值。
Tensorflow 2 实战(kears)- 双层RNN/LSTM/GRU
一、背景介绍
1.1、数据集简介
本次实战使用数据集为 “IMDB” , 数据集内容为 “两极分化的评论”;该数据集共50000条,其中训练集25000条、测试集25000条;数据集分为两个类别(正面评价为1、负面评价为0),训练集和测试集都包含50%的正面评价和50%的负面评价。该数据集已经经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
1.2、模型简介
RNN解决了普通模型不适合处理序列数据的问题(例如:序列数据样本长度不一、参数过多、不能分享从序列不同位置学到的特征等问题)。
LSTM(长短期记忆网络)解决了由于梯度消失引起的RNN记忆力不好的问题。
GRU与LSTM类似,但GRU计算量要小一些,有助于构建更加庞大的项目。
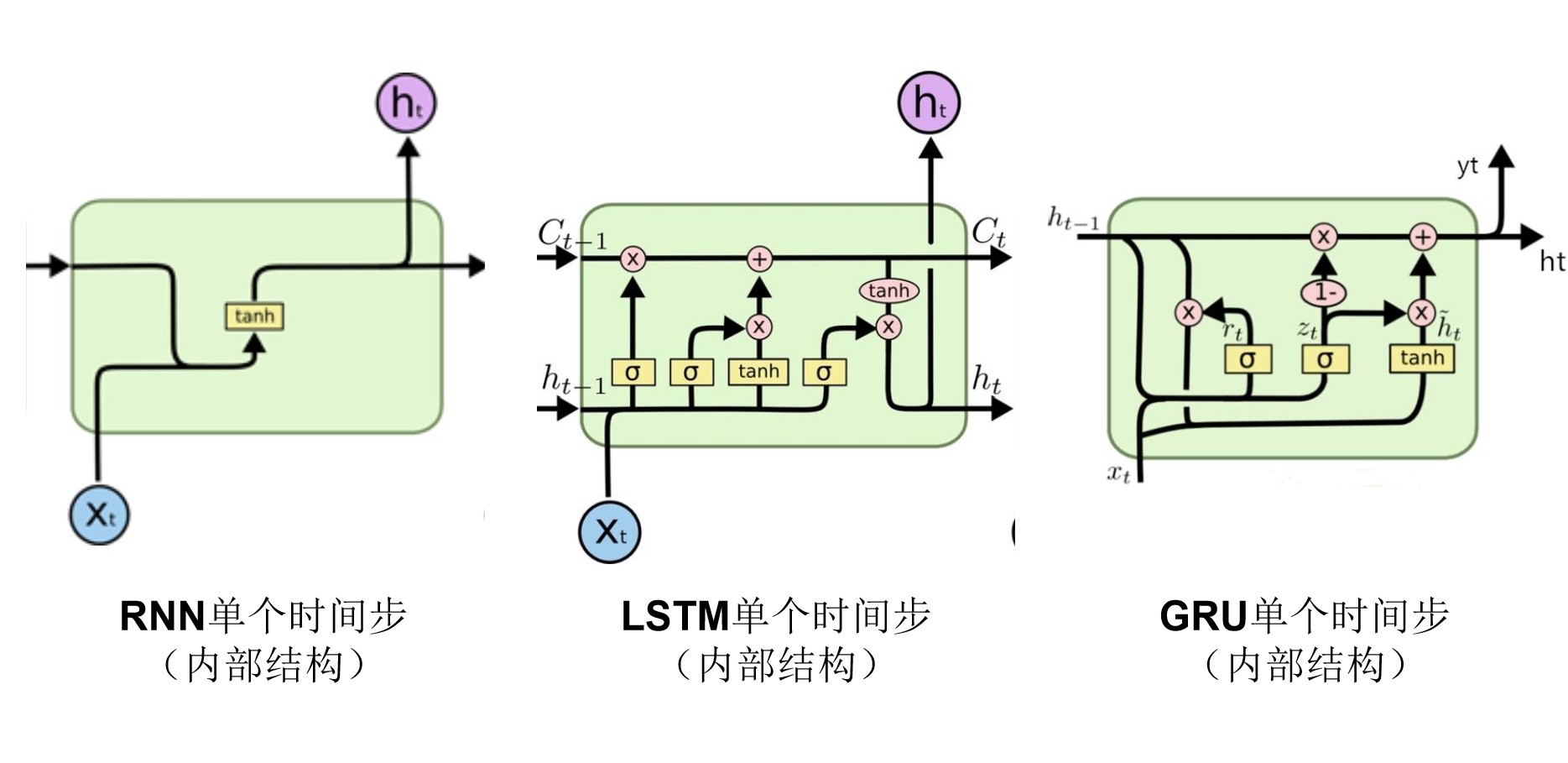
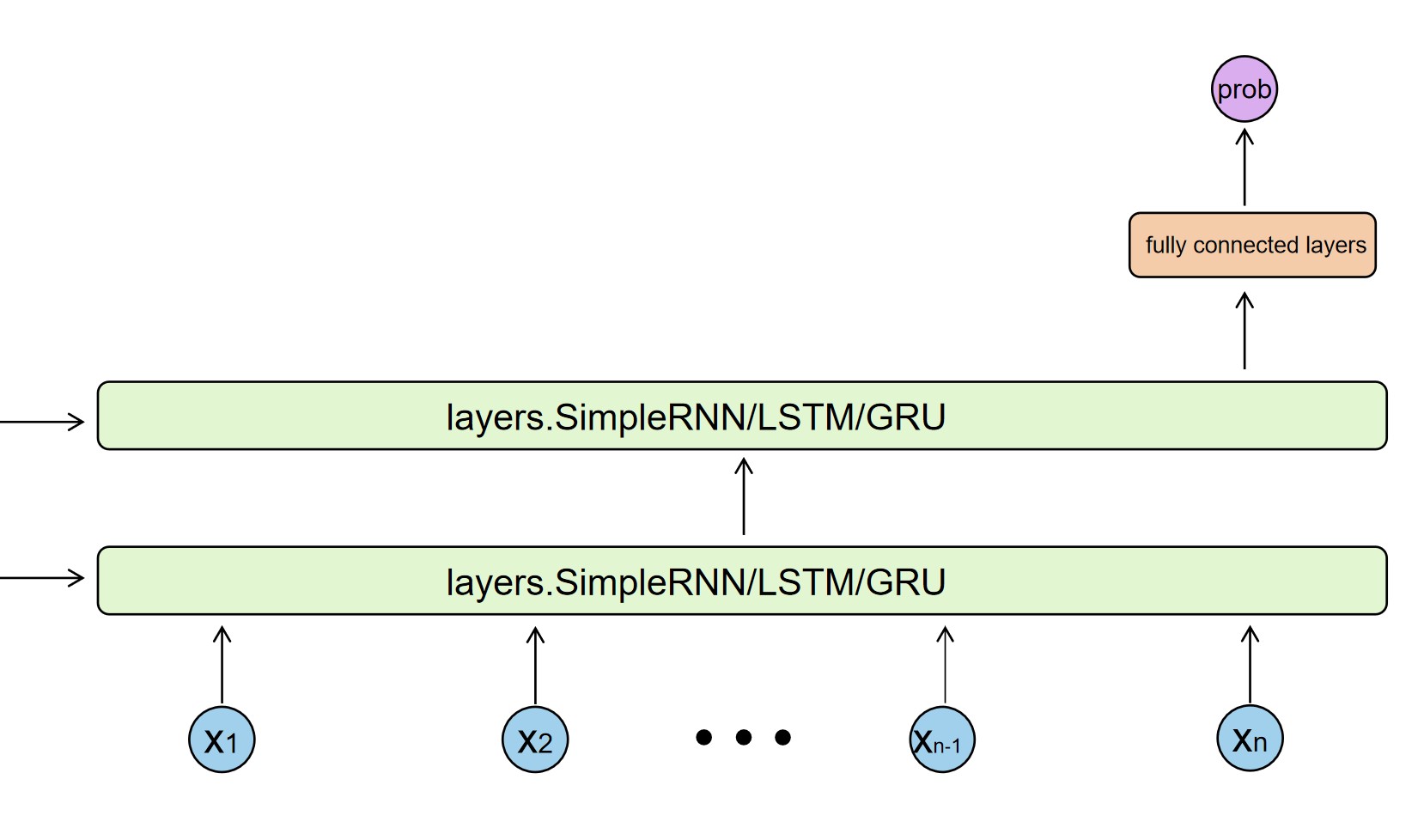
1.2.1、实战模型(共三层)由一个“双层RNN/LSTM/GRU"及 “一个全连接层”构成
- 双层RNN/LSTM/GRU的输入为经过数据预处理的 “词向量” ,输出为“最后一层“中”最后一个时间步“的结果向量(句子编译的结果)。
- 全连接层的输入为“双层RNN/LSTM/GRU的输出”,输出为类别的概率。
1.2.2、实战模型使用两种方式编写“双层RNN/LSTM/GRU”中的层
- 一种为:“每一层” 中使用 “RNN/LSTM/GRU单个时间步” 串联的方式实现,如下:

- 另一种为: “每一层” 中直接使用tf.kears中“layers.SimpleRNN/LSTM/GRU” 实现,如下:
二、双层RNN/LSTM/GRU实战代码
2.1、双层RNN/LSTM/GRU-单个时间步
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
tf.random.set_seed(22)
np.random.seed(22)
assert tf.__version__.startswith('2.')
batchsz = 128
# total_words为常见单词数量,此处仅保留训练数据的前10000个最常见出现的单词,低频单词将被舍弃(0不代表任何特定的词,而是用来编码任何未知单词)
total_words = 10000
#max_review_len为句子的最大长度
max_review_len = 80
#词向量的长度
embedding_len = 100
#加载数据集
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# x_train:[b, 80]
# x_test: [b, 80]
#pad_sequences对句子进行padding(maxlen:任何大于此值的句子将被截断,小于则补0)
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
#构造数据集
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
#drop_remainder=True如果最后一个 “batch的大小” 小于 “batchsz的大小” 则丢弃掉(它的shape与我们固定的shape不一致,不利于训练)
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('x_test shape:', x_test.shape)
class MyRNN(keras.Model):
#定义层的实现
def __init__(self, units):
super(MyRNN, self).__init__()
# [b, 64]
#初始化c,a(LSTM)
self.state0 = [tf.zeros([batchsz, units]),tf.zeros([batchsz, units])]
self.state1 = [tf.zeros([batchsz, units]),tf.zeros([batchsz, units])]
# #初始化c(GRU)
# self.state0 = [tf.zeros([batchsz, units])]
# self.state1 = [tf.zeros([batchsz, units])]
# [b, 80] => [b, 80, 100]
#将词转为词向量(total_words:单词表大小, embedding_len:词向量长度,input_length:句子的最大长度)
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# [b, 80, 100] , units:输出空间的维度(正整数),即隐藏层神经元数量(这里是64)
# RNN: cell0 ,cell1
# #SimpleRNNcell RNN中的一个时间步
# self.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.5)
# self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.5)
#LSTMcell LSTM中的一个时间步
self.rnn_cell0 = layers.LSTMCell(units, dropout=0.5)
self.rnn_cell1 = layers.LSTMCell(units, dropout=0.5)
# #GRUcell GRU中的一个时间步
# self.rnn_cell0 = layers.LSTMCell(units, dropout=0.5)
# self.rnn_cell1 = layers.LSTMCell(units, dropout=0.5)
# fc全连接层,用于分类, [b, 80, 100] => [b, 64] => [b, 1]
self.outlayer = layers.Dense(1)
#实现前向过程
def call(self, inputs, training=None):
"""
net(x) net(x, training=True) :train mode 表示为train的计算过程(train阶段dropout会运行)
net(x, training=False): test 表示为test的计算过程(test阶段dropout不会运行)
:param inputs: [b, 80]
:param training:
:return:
"""
# [b, 80]
x = inputs
# embedding: [b, 80] => [b, 80, 100]
x = self.embedding(x)
# rnn cell compute
# [b, 80, 100] => [b, 64]
state0 = self.state0
state1 = self.state1
# 创建双层RNN(按照“单词维度展开”串联时间步)
for word in tf.unstack(x, axis=1): # word: [b, 100]
# h1 = x*wxh+h0*whh
# out0: [b, 64]
out0, state0 = self.rnn_cell0(word, state0, training)
# out1: [b, 64]
out1, state1 = self.rnn_cell1(out0, state1, training)
# out: [b, 64] => [b, 1]
#“最后一层“中”最后一个时间步“的结果作为句子编译的结果
x = self.outlayer(out1)
# p(y is pos|x)
#对输出结果进行分类
prob = tf.sigmoid(x)
return prob
#训练模型
def main():
units = 64
epochs = 4
import time
t0 = time.time()
# MyRNN:网络的实例化,compile:网络的装载,fit:网络的训练,evaluate:网络的测试
model = MyRNN(units)
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics=['accuracy'])
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
t1 = time.time()
print('total time cost:', t1-t0)
if __name__ == '__main__':
main()
2.1、双层RNN/LSTM/GRU-layers.SimpleRNN/LSTM/GRU
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
tf.random.set_seed(22)
np.random.seed(22)
assert tf.__version__.startswith('2.')
batchsz = 128
#加载数据及数据预处理
# the most frequest words
total_words = 10000
max_review_len = 80
embedding_len = 100
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words)
# x_train:[b, 80]
# x_test: [b, 80]
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsz, drop_remainder=True)
print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train))
print('x_test shape:', x_test.shape)
class MyRNN(keras.Model):
#定义层的实现
def __init__(self, units):
super(MyRNN, self).__init__()
# 将词转为词向量(total_words:单词表大小, embedding_len:词向量长度,input_length:句子的最大长度)
# [b, 80] => [b, 80, 100]
self.embedding = layers.Embedding(total_words, embedding_len,
input_length=max_review_len)
# [b, 80, 100],units:输出空间的维度(正整数),即隐藏层神经元数量(这里是64)
self.rnn = keras.Sequential([
# #创建双层RNN
# layers.SimpleRNN(units, dropout=0.5, return_sequences=True, unroll=True),
# layers.SimpleRNN(units, dropout=0.5, unroll=True)
#创建双层LSTM
#unroll:默认为False,为True可以加速RNN(占用大量内存),为True仅适用于短序列。
layers.LSTM(units, dropout=0.5, return_sequences=True, unroll=True),
layers.LSTM(units, dropout=0.5, unroll=True)
# #创建双层GRU
# layers.GRU(units, dropout=0.5, return_sequences=True, unroll=True),
# layers.GRU(units, dropout=0.5, unroll=True)
])
# fc全连接层,用于分类,[b, 80, 100] => [b, 64] => [b, 1]
self.outlayer = layers.Dense(1)
# 实现前向过程
def call(self, inputs, training=None):
"""
net(x) net(x, training=True) :train mode
net(x, training=False): test
:param inputs: [b, 80]
:param training:
:return:
"""
# [b, 80]
x = inputs
# embedding: [b, 80] => [b, 80, 100]
x = self.embedding(x)
# rnn cell compute
# x: [b, 80, 100] => [b, 64]
x = self.rnn(x)
# out: [b, 64] => [b, 1]
x = self.outlayer(x)
# p(y is pos|x)
prob = tf.sigmoid(x)
return prob
#训练模型
def main():
units = 64
epochs = 4
import time
t0 = time.time()
# MyRNN:网络的实例化,compile:网络的装载,fit:网络的训练,evaluate:网络的测试
model = MyRNN(units)
model.compile(optimizer = keras.optimizers.Adam(0.001),
loss = tf.losses.BinaryCrossentropy(),
metrics=['accuracy'])
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
t1 = time.time()
print('total time cost:', t1-t0)
if __name__ == '__main__':
main()
以上是关于Tensorflow 2 实战(kears)- 双层RNN/LSTM/GRU的主要内容,如果未能解决你的问题,请参考以下文章