LeCun带两位UC伯克利华人博士提出「循环参数生成器」
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LeCun带两位UC伯克利华人博士提出「循环参数生成器」相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :新智元
近日,LeCun带领两位来自UC伯克利的华人博士共同发表了一份关于如何减少参数冗余问题的论文,团队提出的RPG循环参数生成器,在减少骨干参数的同时,也依然能获得比SOTA更好的性能。
模型压缩,我所欲也,模型性能,亦我所欲也;
二者不可得兼?
且慢,小孩子才做选择!
虽说参数数量越多,模型性能越好,但显然过参数化的模型太占用资源。
尤其是GPT-3,参数高达1750亿个!
为解决这一问题,研究人员试图从不同角度来减少参数的冗余,包括神经网络剪枝、参数正则化、模型量化、网络结构搜索、循环模型……
这些方法尝试从预训练的大型神经网络中删去不重要的参数,实现对大模型的压缩。
近日,LeCun的研究团队就发表了一篇题为「循环参数生成器」(Recurrent Parameter Generators)的论文。
其中,循环参数生成器可以被看作是模型压缩的一种逆向方法,其目的不是从一个大的模型中去除多余的参数,而是将更多的信息挤压到少量的参数中。

论文地址:https://arxiv.org/pdf/2107.07110.pdf
论文主要带来了三点贡献:
1. 循环参数生成器 (RPG)能使用任意数量的参数来构建给定的神经网络。
2. 在给定的压缩率下,RPG与SOTA的模型剪枝方法相比,实现了同等甚至更好的性能。
3. 通过破坏权重共享,RPG与几种循环权重共享模型相比,拥有更强的性能。
参数更少,更灵活
在标准神经网络中,所有参数都是相互独立的,所以,模型越深,也就变得越大。
而RPG则在一个环中共享一组固定的参数,并利用它们来生成神经网络中不同部分的参数。

模型的第三部分(黄色)开始与环中的第一部分(红色)重叠,所有后面的层可能会多次共享生成的参数。
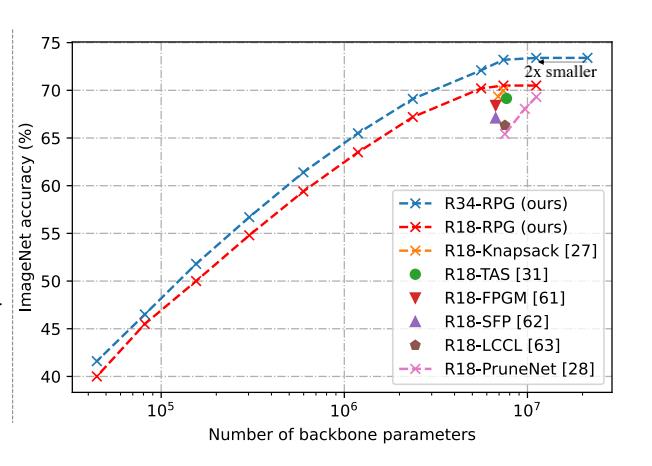
以ResNet34为例,应用RPG后,只需要骨干参数的一半,也能够实现相同的ImageNet top-1的精度。
研究发现,即使在单个标量值级别,参数也可以在深度网络架构的另一个任意位置重新使用,不会对模型性能产生明显影响。
而出乎意料的是,对于相同参数能够分配到网络的多个随机位置问题,能够通过深度网络的反向传播训练来解决,同样也不会对模型性能产生明显影响
因此作者表示,要想有高性能,并不代表着大型神经网络就要过度参数化。
此外,将Resnet18模型一个卷积层的权重数量减少4.72倍也能达到ImageNet top-1精度的67.2%。
从某种意义上说,RPG可以看作是一种自动模型剪枝技术,探索精度与参数之间的最优解。
而除了灵活性之外,其压缩结果往往与SOTA剪枝方法相当,甚至要更好。
即使将Resnet18骨干参数减少到36K,也就是减少了约300倍,Resnet18仍然可以达到ImageNet top-1精度的40.0%。
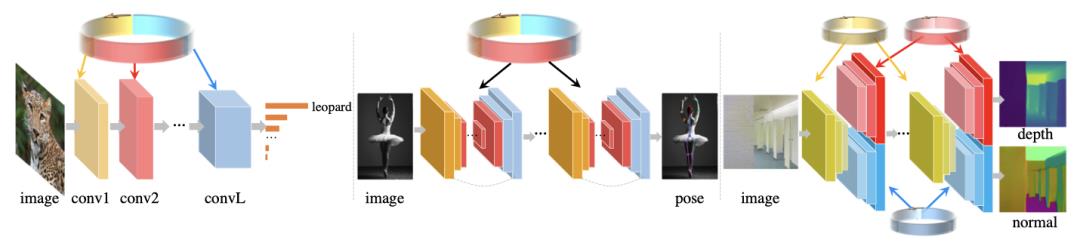
包括图像分类(左)、人体姿势估计(中)和多任务(右)
循环参数生成器
为了实现更好的参数容量,作者引入了一种均匀的采样策略。
假设正在构建一个深度卷积神经网络,它包含L个不同的卷积层。让K1, K2, ...... , KL是相应的L个卷积核。
并创建一个单一的参数集W∈RN,用它来为每个卷积层生成相应的参数。
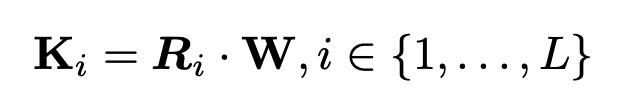
其中Ri是一个固定的预定义生成矩阵,用于从W中生成Ki,其中{Ri}和W即为循环参数生成器(RPG)。
此外,W的梯度是每个卷积层的梯度的线性叠加。根据链式规则可以得到W的梯度是:
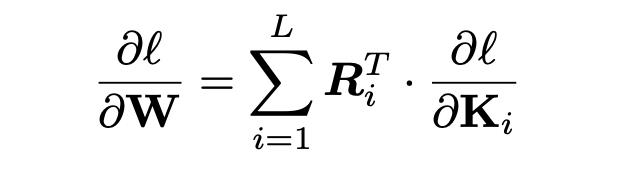
不同规模的循环参数生成器
除了创建一个在所有层中全局共享的RPG。作者还提出了在块和子网络规模上创建局部RPG。
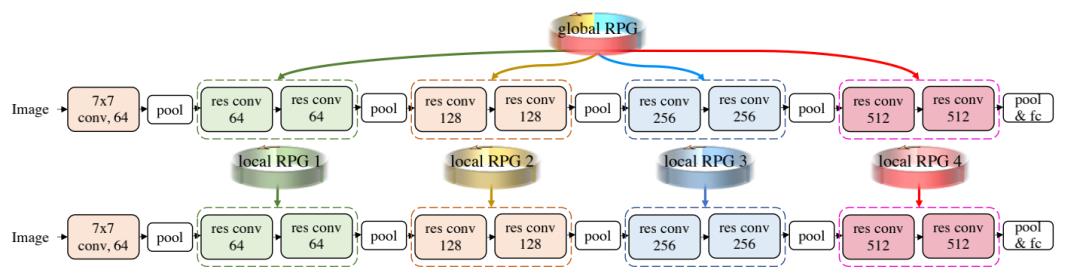
一个全局RPG为整个ResNet18生成卷积核;4个局部RPG分别负责为ResNet18的模块生成卷积核
以ResNet18为例, ResNet18有4个构建块,其中每个块有2个残差卷积模块。
为了在块规模上叠加ResNet18,作者创建了四个局部RPG。每个RPG都在相应的构建块内共享,其中RPG的大小是灵活的,可由用户决定。
许多任务可以重新使用子网络或循环网络,因为它们通过迭代完善和改进了预测。
通常而言,在重复使用子网络时,权重是共享的,但这可能不是最优方案。
因为不同阶段的子网络迭代会改进预测,共享权重也可能会限制适应不同阶段的学习能力。另一方面,完全不共享权重还会极大增加模型大小。
因此作者尝试将不同的子网络与一个或多个RPG进行叠加。经过叠加的子网络可以有更小的模型尺寸,而不同子网络的参数会发生变化,而不是直接复制粘贴。
图像分类
在进行CIFAR测试时,批大小为128,权重衰减为5e-4,初始学习率为0.1,gamma为0.1,epoch为60、120和160。
在进行ImageNet测试时,批次大小为256,权重衰减为3e-5,初始学习率为0.3,每75 epochs的gamma为0.1。
作为隐含模型的代表,深度均衡模型可以通过额外的优化寻找固定点来减少模型的冗余度。
与MDEQ相比,RPG可以在CIFAR10上将精度提高3.4% - 5.8%,在CIFAR100上提高3% - 5.9%。
推理时间方面,RPG则比MDEQ少15-25倍,因为MDEQ在训练期间需要额外的时间来解决平衡问题。

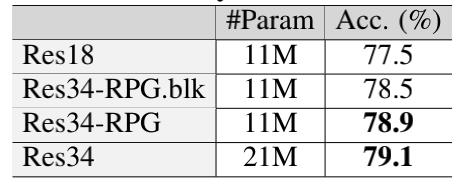
与ResNet相比,拥有全局RPG的ResNet-RPG在相同的参数大小下取得了更高的精度。
而ResNet-RPG34只用了ResNet34骨干参数的50%就达到了相同的精度73.4%。

令人意外的是,作者发现在CIFAR100上达到36%的精度只需8K骨干参数。
此外,ResNet34-RPG比ResNet18-RPG实现了更高的精度,这表明时间复杂度的增加提升了模型的性能。

与相同参数数量的标准ResNet18相比,局部RPG网络可以将精度提升1.0%。相比之下,全局RPG在精度上提升了1.4%。
也就是说,参数均匀分布的全局RPG在精度上会比多个局部RPG高0.4%。
作者简介

Jiayun Wang,2018年毕业于西安交通大学电子工程系,如今是UC伯克利分校视觉科学项目博士候选人,研究领域为计算机视觉,导师是Stella Yu。

Yubei Chen,2012年获得清华大学电气工程系学士学位,后加入UC伯克利分校的EECS系和伯克利人工智能研究所 (BAIR),攻读博士学位,在Bruno Olshausen教授指导下研究生成式无监督学习模型。
就读UC伯克利期间,获得了EECS硕士学位和数学硕士学位。
2012年曾获得NSF GRFP奖学金,此外还担任NeurIPS、ICLR、ICML、AAAI等大会的论文审稿人。
参考资料:
https://arxiv.org/pdf/2107.07110.pdf
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于LeCun带两位UC伯克利华人博士提出「循环参数生成器」的主要内容,如果未能解决你的问题,请参考以下文章
不用亲手搭建型了!华人博士提出few-shot NAS,效率提升10倍
不用亲手搭建型了!华人博士提出few-shot NAS,效率提升10倍