Kibana:Kibana Query Language - KQL
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kibana:Kibana Query Language - KQL相关的知识,希望对你有一定的参考价值。
Kibana Query Language (KQL) 是一种使用自由文本搜索或基于字段的搜索过滤 Elasticsearch 数据的简单语法。 KQL 仅用于过滤数据,并没有对数据进行排序或聚合的作用。
KQL 能够在你键入时建议字段名称、值和运算符。 建议的性能由 Kibana 设置控制:
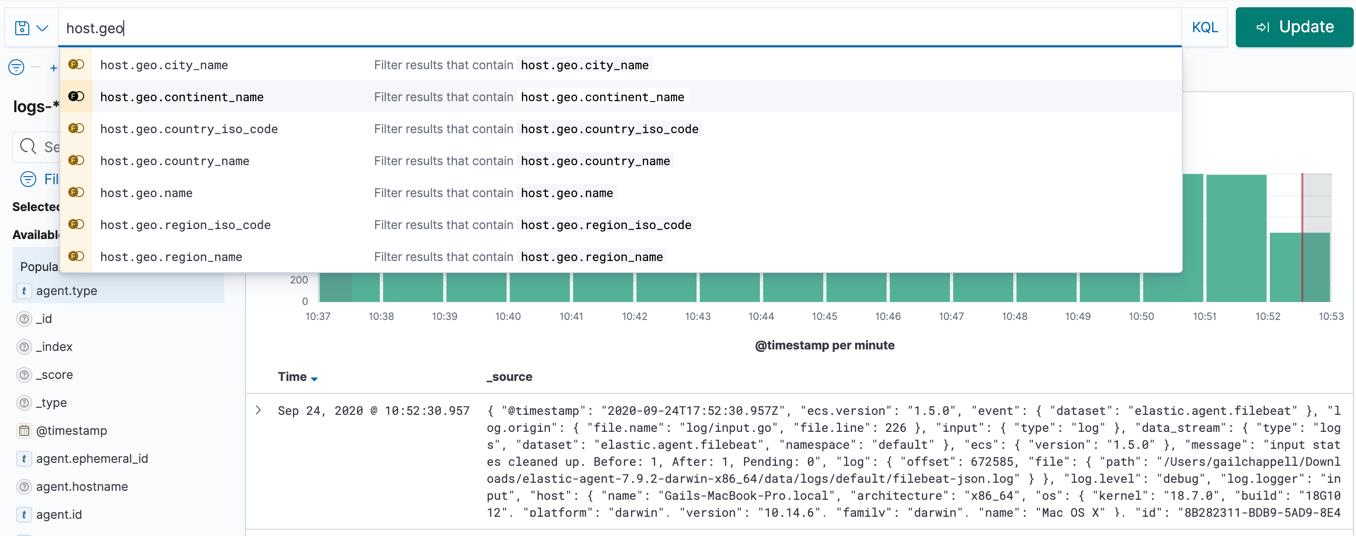
在上面的搜索框的右边,我们可以看到 KQL 字样。它表明当前的模式是 KQL 查询。
KQL 具有与 Lucene 查询语法不同的一组功能。 KQL 能够查询嵌套字段和脚本字段。 KQL 不支持正则表达式或模糊术语搜索。 要使用传统的 Lucene 语法,请单击搜索框右边的 KQL,然后关闭 KQL。
有关 KQL 的一些介绍,在我的另外一篇文章 “Kibana: 如何使用 Search Bar” 中有所介绍。
准备数据
在今天的练习中,我将使用 Kibana 自带的索引来做展示:

这样我们就在 Elasticsearch 中创建了一个叫做 kibana_sample_data_logs 的索引。
Terms query
术语查询使用精确的搜索术语。 空格分隔每个搜索词,并且只需要一个词来匹配文档。 使用引号表示短语匹配(phrase match)。
要使用精确搜索词进行查询,请输入字段名称,后跟 :,然后输入以空格分隔的值:

如上所示。在 response 中只要匹配其中的任何一个 200,400,或者 503,那么搜索的答案都会显示出来。
对于文本字段,无论顺序如何,这都将匹配任何值:

要查询确切的短语(phrase),请在值周围使用引号:
KQL 不需要字段名称。 如果未提供字段名称,则索引设置中的默认字段将匹配术语。 要跨字段搜索:
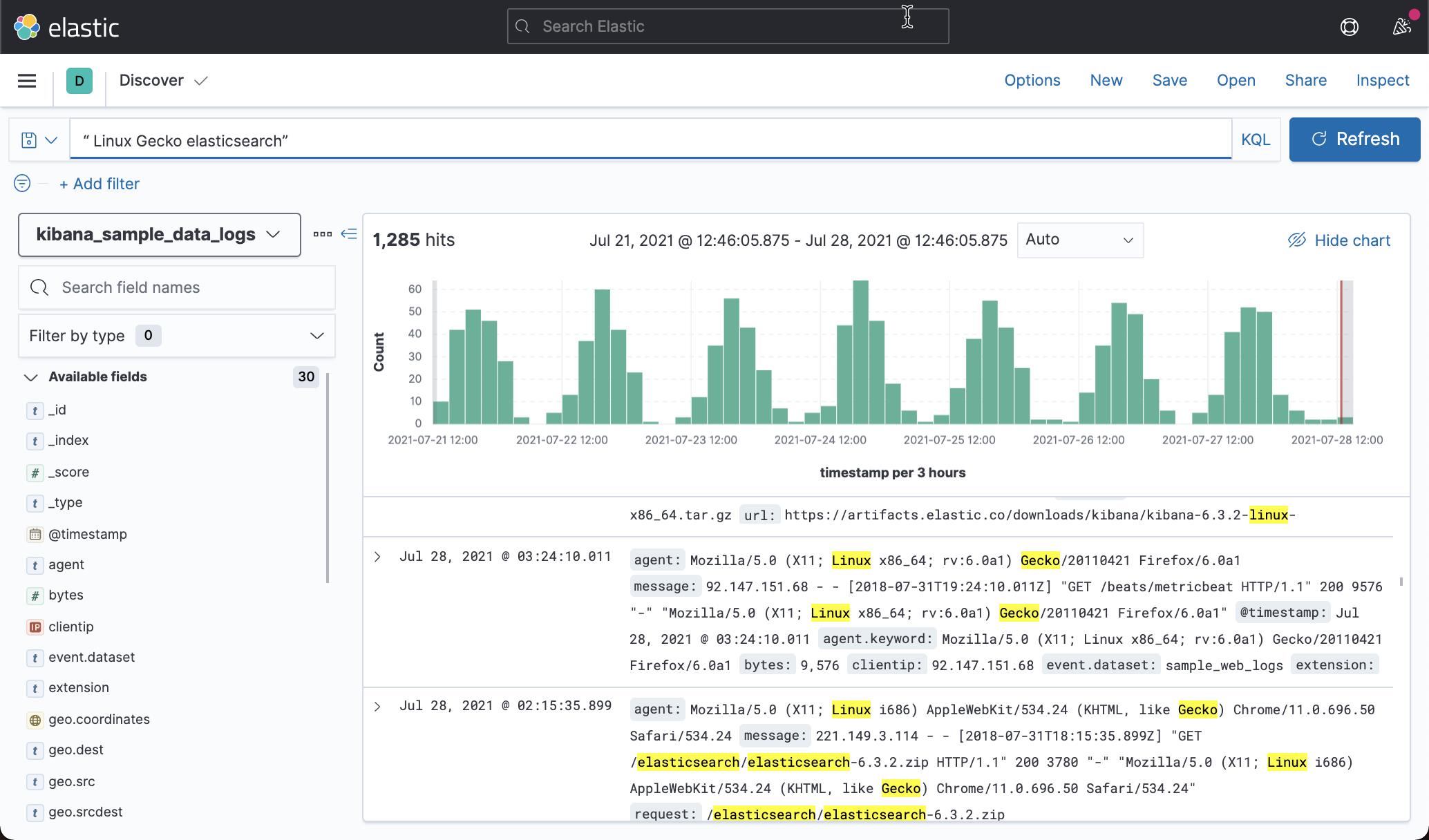
Boolean queries
KQL 支持 or、and 和 not。 默认情况下,and 的优先级高于 or。 要覆盖默认优先级,请在括号中将运算符分组。 这些运算符可以是大写或小写。
要匹配 response 为 200、或者地理位置目的地(geo.dest)为 CN. 或两者都满足的文档:
response: 200 or geo.dest: "CN"
要匹配 response 为 200 且 geo.dest 为 CN 的文档:
response: 200 and geo.dest: "CN"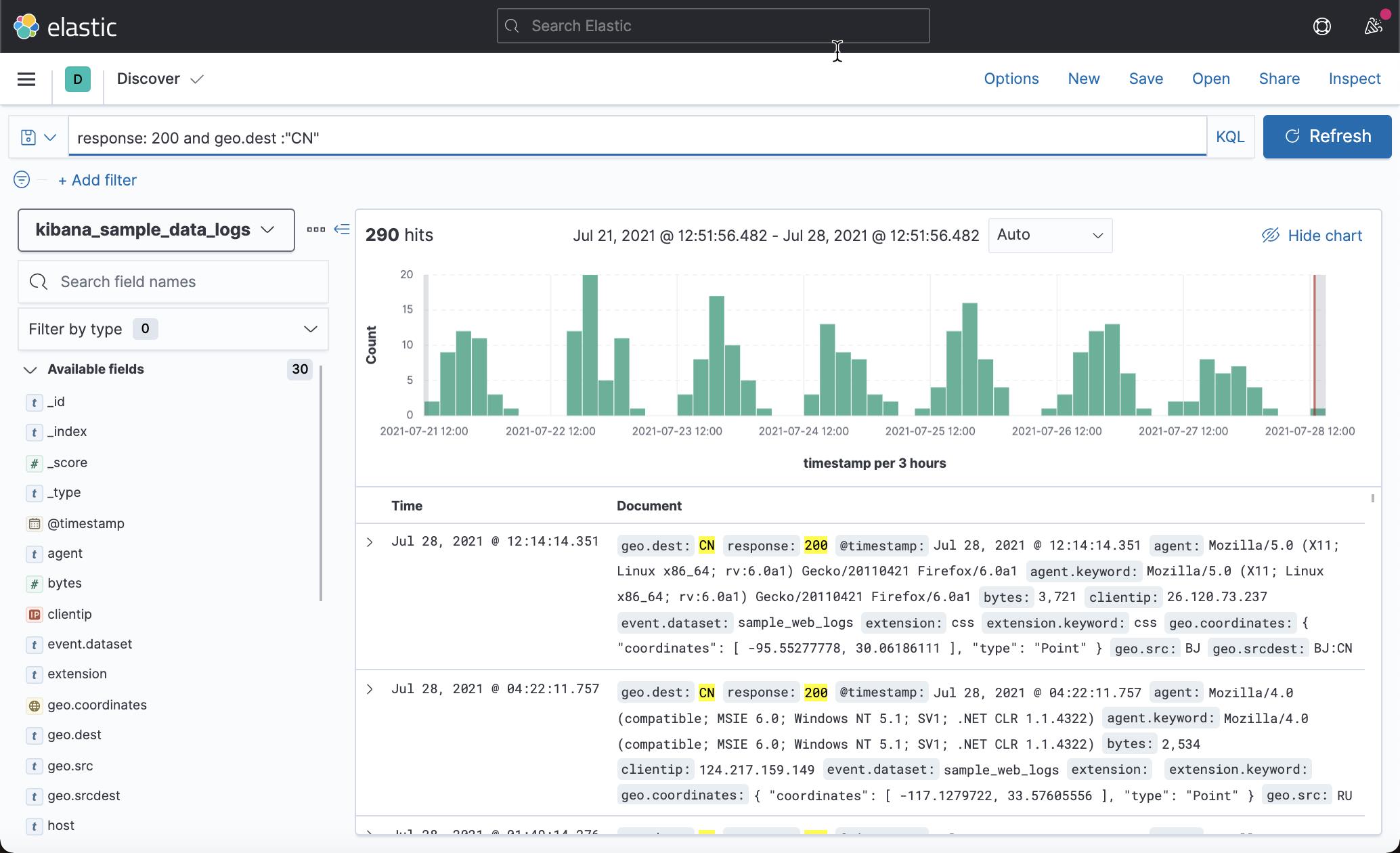
从上面,我们可以看出来,查询的结果为290,明显比上次的查询结果少。
匹配 response 为 200 或 404 的文档:
response:(200 or 404)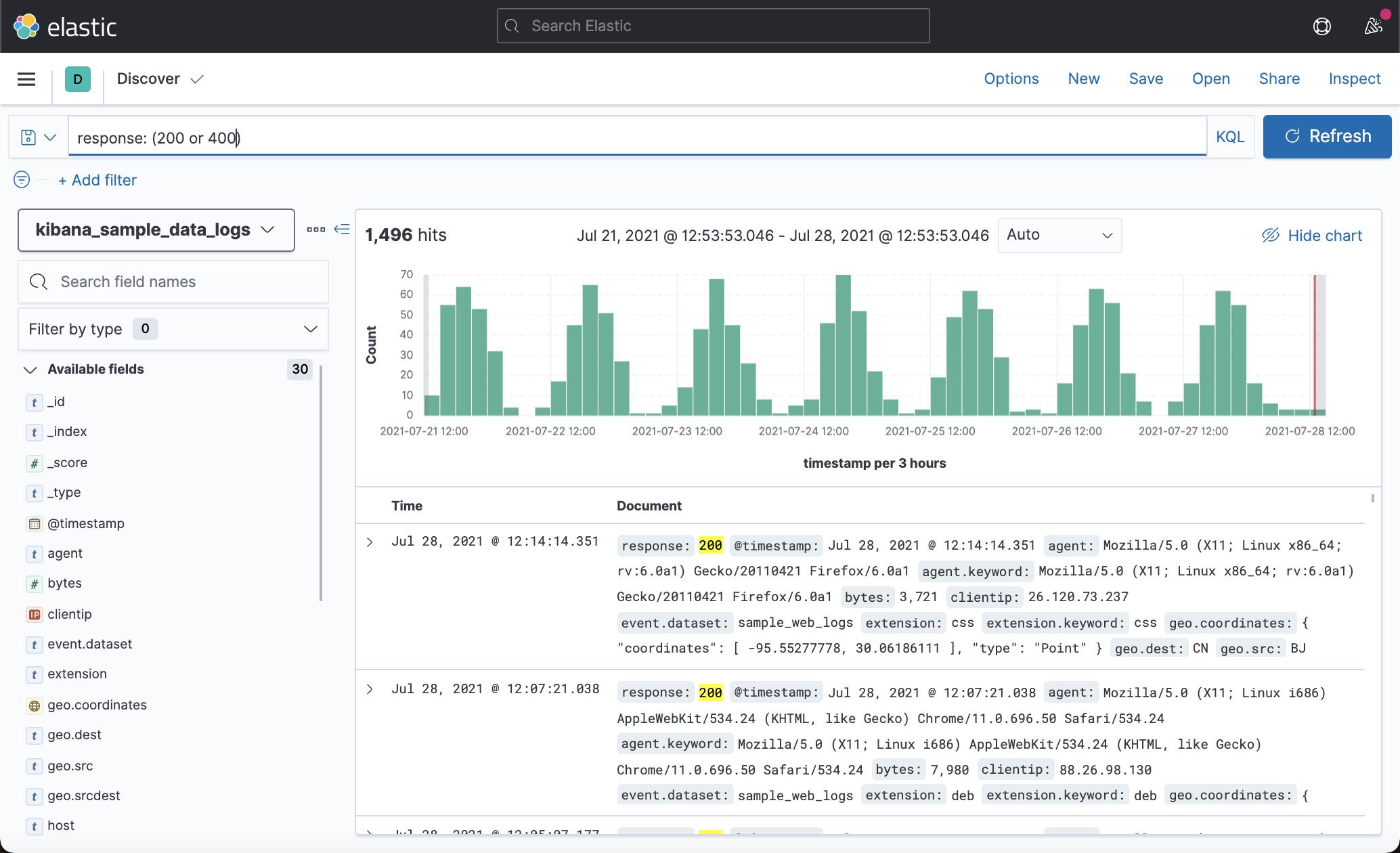
要匹配 response 为 200 且 extension 为 php 或 css 的文档:
response:200 and (extension:php or extension:css)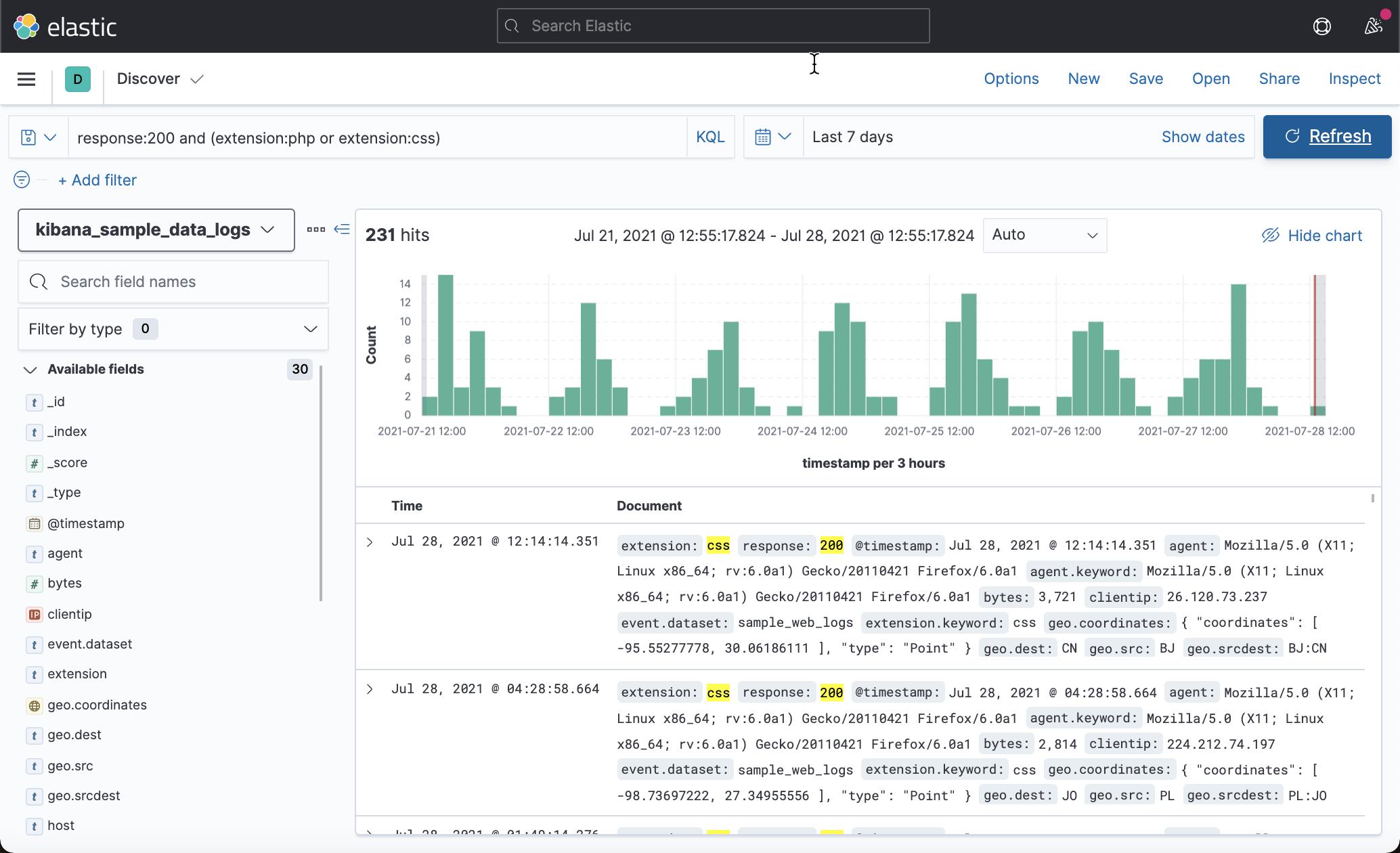
要匹配 response 为 200 且 extension 为 php 或 extension 为 css 且 response 为任何内容的文档。还记得我们之前说过的 and 的优先级比 or 要高:
response:200 and extension:php or extension:css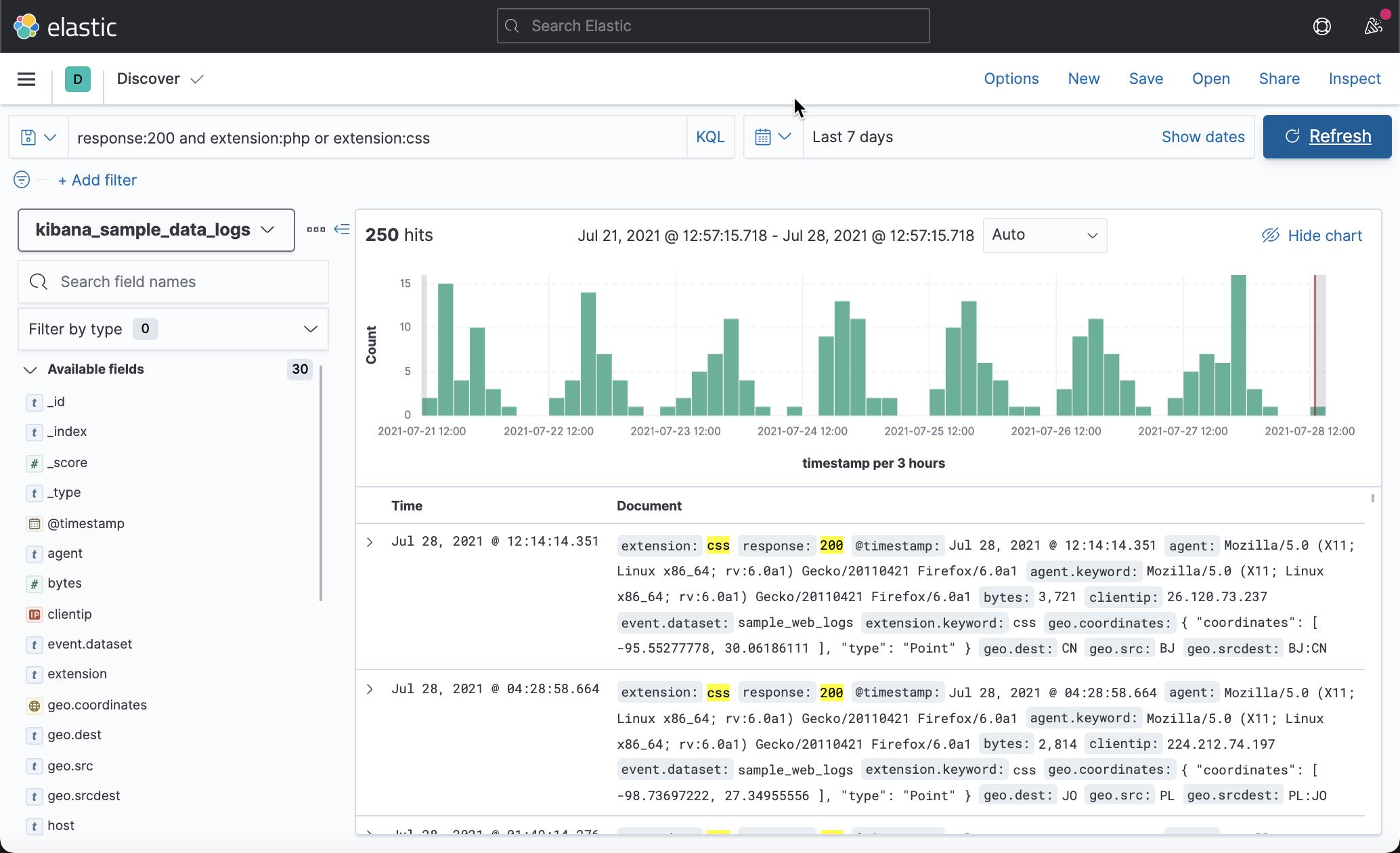
你可以理解上面的查询是这样的:
(response:200 and extension:php) or extension:css
匹配 response 不是 200 的文档:
not response:200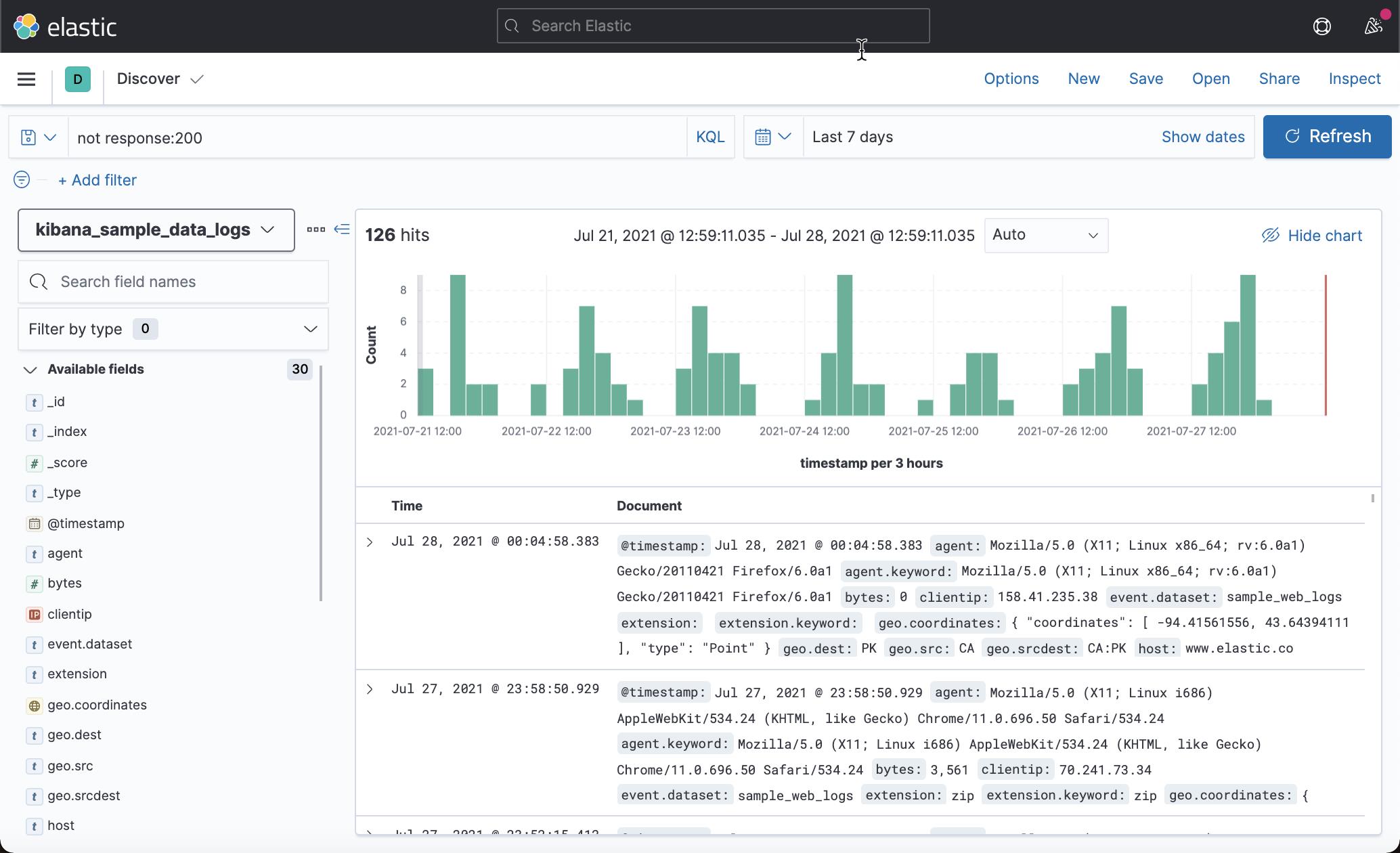
匹配 response 为 200 但 extension 不是 php 或 css 的文档:
response:200 and not (extension:php or extension:css)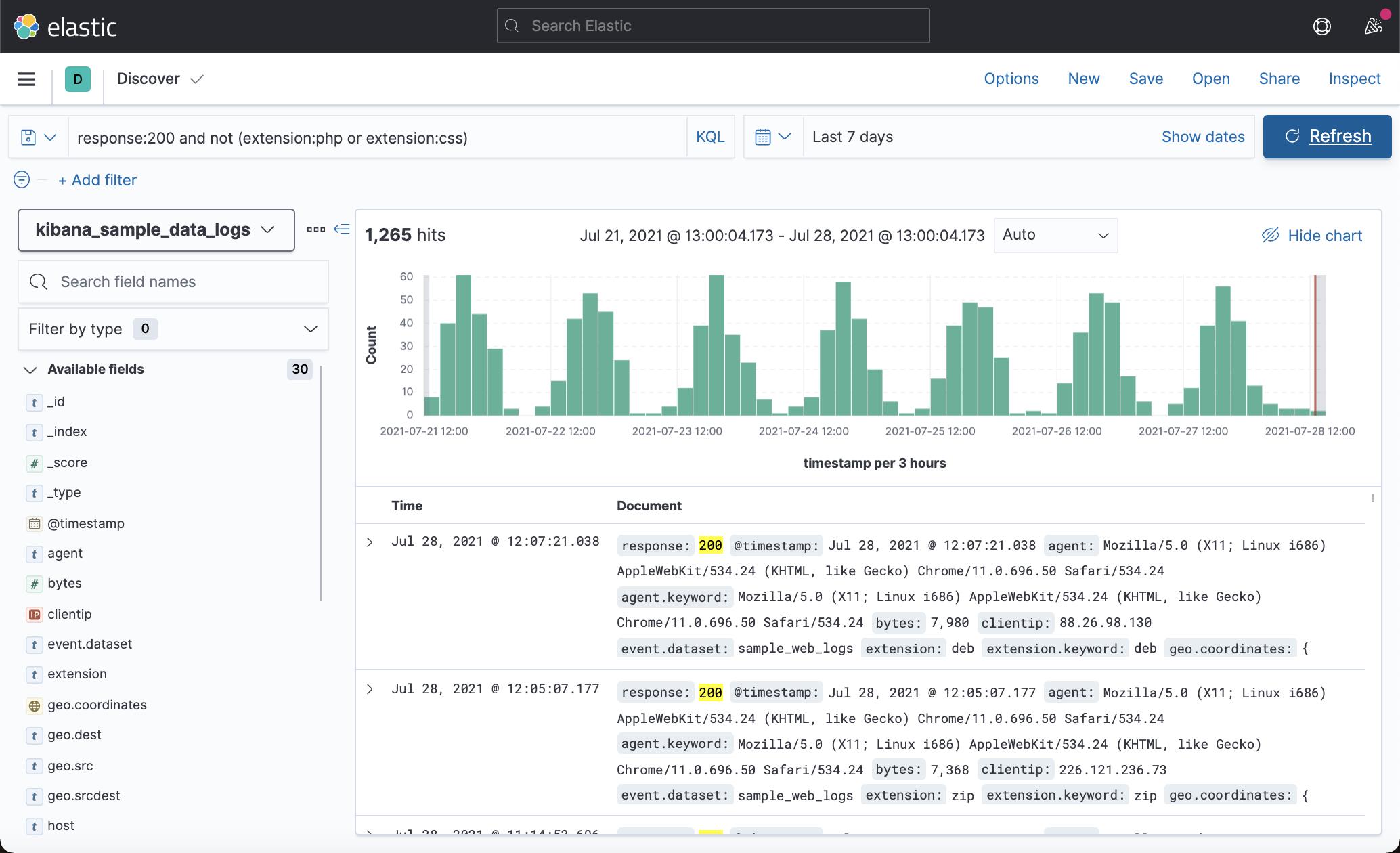
要匹配包含术语列表的多值字段:
tags:(success and info and security)Range queries
KQL 支持数字和日期类型的 >、>=、< 和 <=。
bytes > 1000 and (hour_of_day>10 and hour_of_day <14 ) 
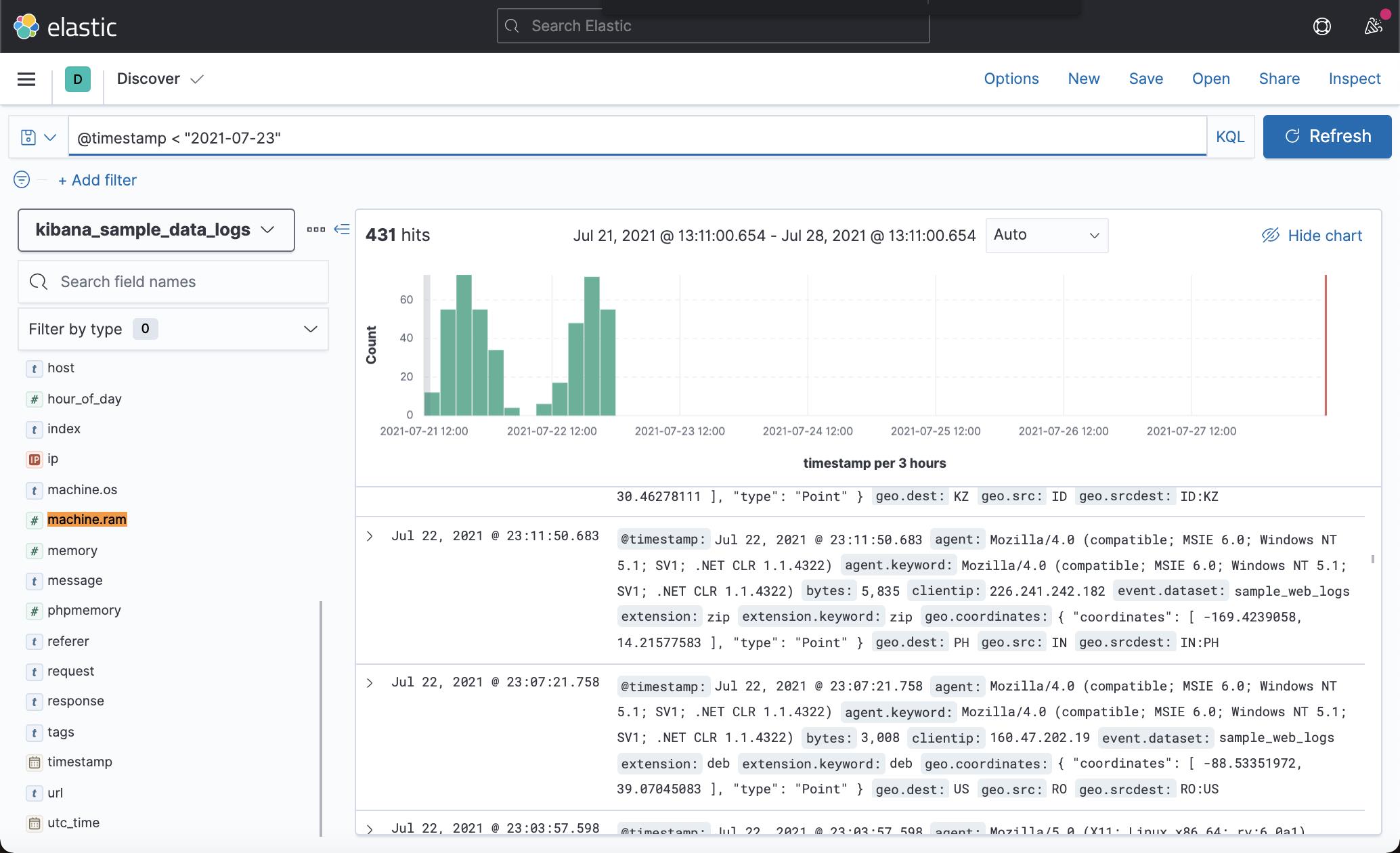
Date range queries
通常,Kibana 的时间过滤器足以设置时间范围,但在某些情况下,你可能需要搜索日期。 在引号中包含日期范围。

Exits queries
Exist 查询匹配包含任何字段值的文档,在本例中为响应:
response:*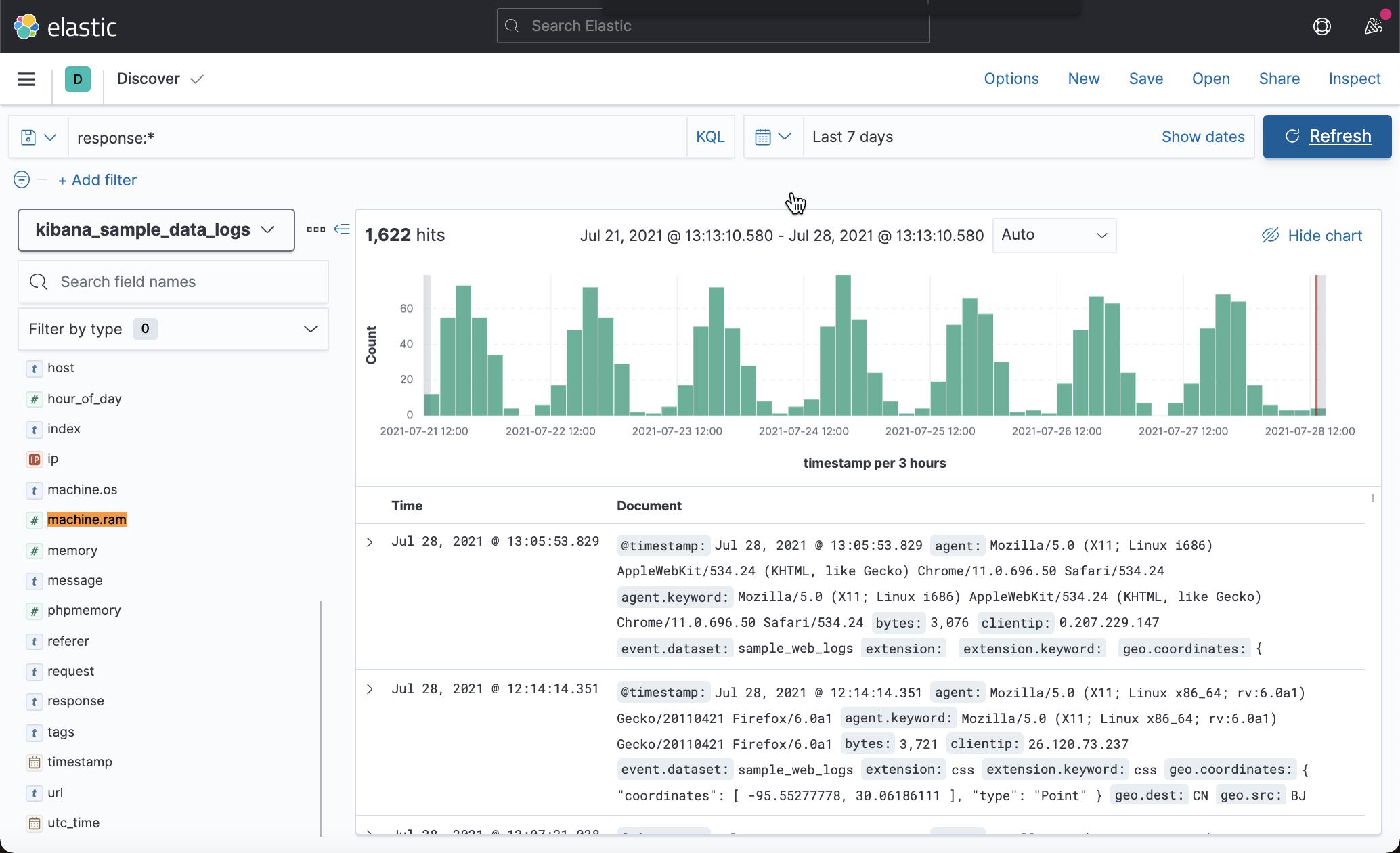
存在由 Elasticsearch 定义,包括所有值,包括空文本。
Wildcard queries
通配符查询可用于按术语前缀搜索或搜索多个字段。 Kibana 的默认设置出于性能原因禁止使用前导通配符,但可以通过高级设置允许。
要匹配 machine.os 以 win 开头的文档,例如 “windows 7” 和 “windows 10”:
machine.os:win*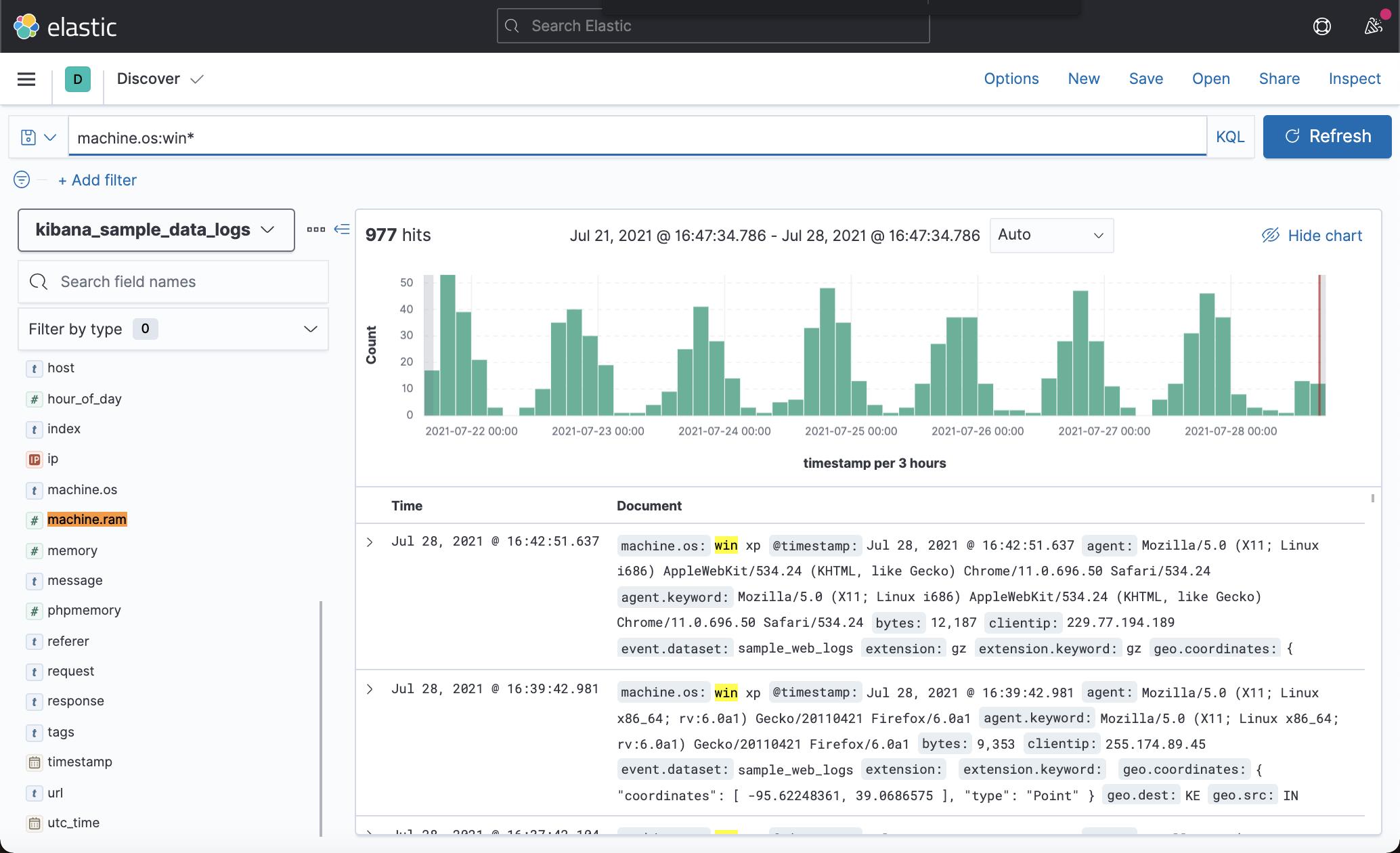
匹配多个字段:
machine.os*: win* 10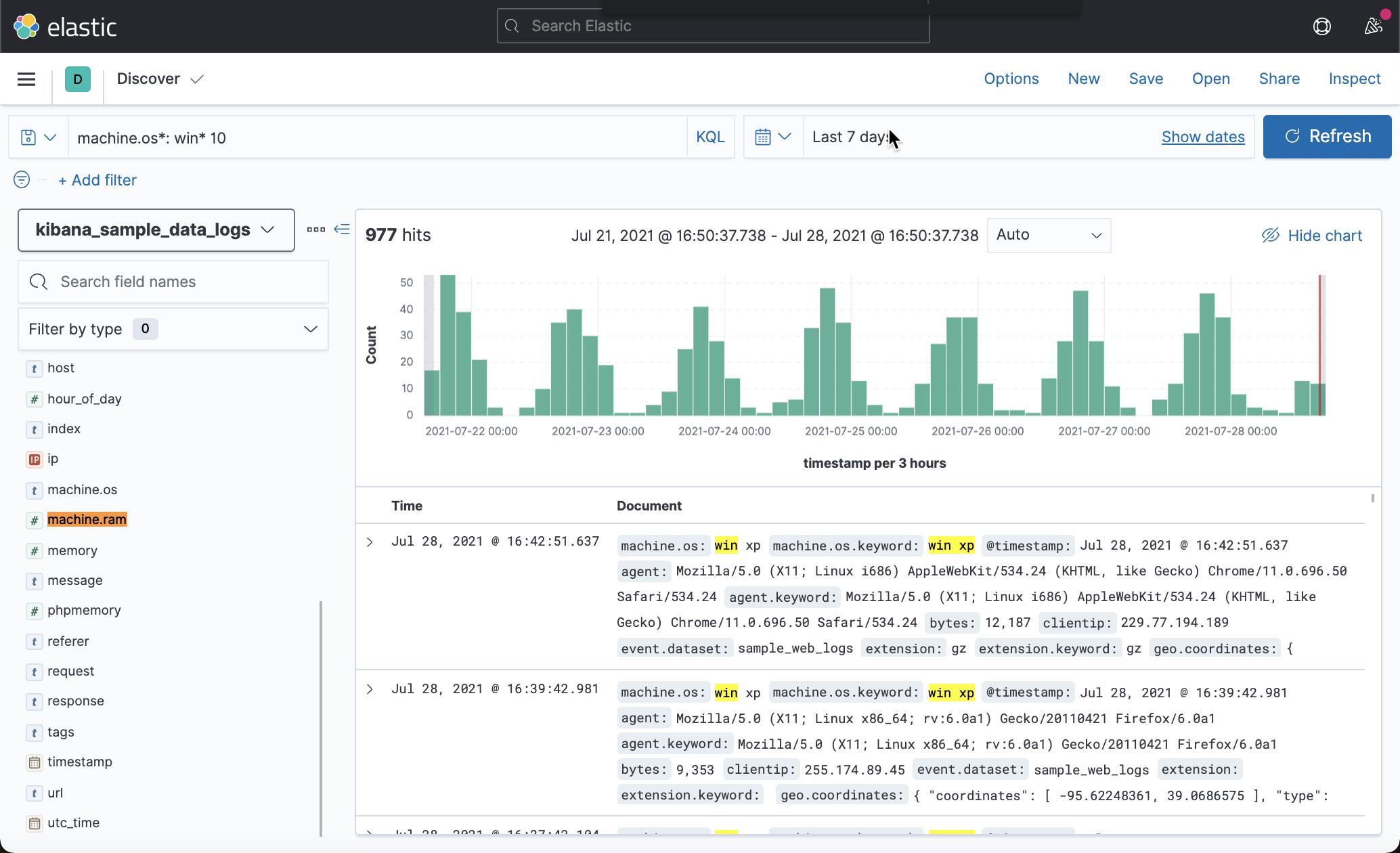
当你有字段的 text 和 keyword 版本时,此语法很方便。 该查询检查 machine.os 和 machine.os.keyword 中的术语 win 10。
Nested field queries
查询嵌套字段的一个主要考虑因素是如何将嵌套查询的部分匹配到单个嵌套文档。 你可以:
- 仅将查询的部分匹配到单个嵌套文档。 这是大多数用户在查询嵌套字段时想要的。
- 将查询的部分匹配到不同的嵌套文档。 这就是常规对象字段的工作方式。 此查询通常不如匹配单个文档有用。
在以下文档中,items 是一个嵌套字段。 嵌套字段中的每个文档都包含 name、stock 和 category。
{
"grocery_name": "Elastic Eats",
"items": [
{
"name": "banana",
"stock": "12",
"category": "fruit"
},
{
"name": "peach",
"stock": "10",
"category": "fruit"
},
{
"name": "carrot",
"stock": "9",
"category": "vegetable"
},
{
"name": "broccoli",
"stock": "5",
"category": "vegetable"
}
]
}我们创建一个如下的 test 索引:
PUT test
{
"mappings": {
"properties": {
"grocery_name": {
"type": "text"
},
"items": {
"type": "nested",
"properties": {
"category": {
"type": "text"
},
"name": {
"type": "text"
},
"stock": {
"type": "integer"
}
}
}
}
}
}我们创建如下的一个文档:
PUT test/_doc/1
{
"grocery_name": "Elastic Eats",
"items": [
{
"name": "banana",
"stock": "12",
"category": "fruit"
},
{
"name": "peach",
"stock": "10",
"category": "fruit"
},
{
"name": "carrot",
"stock": "9",
"category": "vegetable"
},
{
"name": "broccoli",
"stock": "5",
"category": "vegetable"
}
]
}我们为 test 索引创建一个叫做 test* 的索引模式。
匹配单个文档
要匹配库存超过 10 个香蕉的商店:
items:{ name:banana and stock > 10 }items 是 nested path。 花括号(嵌套组)内的所有内容都必须匹配单个嵌套文档。

以下查询不返回任何匹配项,因为没有单个嵌套文档具有库存为 9 的香蕉。
items:{ name:banana and stock:9 }
匹配不同的文档
以下子查询位于单独的嵌套组中,可以匹配不同的嵌套文档:
items:{ name:banana } and items:{ stock:9 }name:banana 匹配数组中的第一个文档,而 stock:9 匹配数组中的第三个文档。

匹配单个和不同的文档
要找到一家拥有 10 多个香蕉且同时备有蔬菜的商店:
items:{ name:banana and stock > 10 } and items:{ category:vegetable }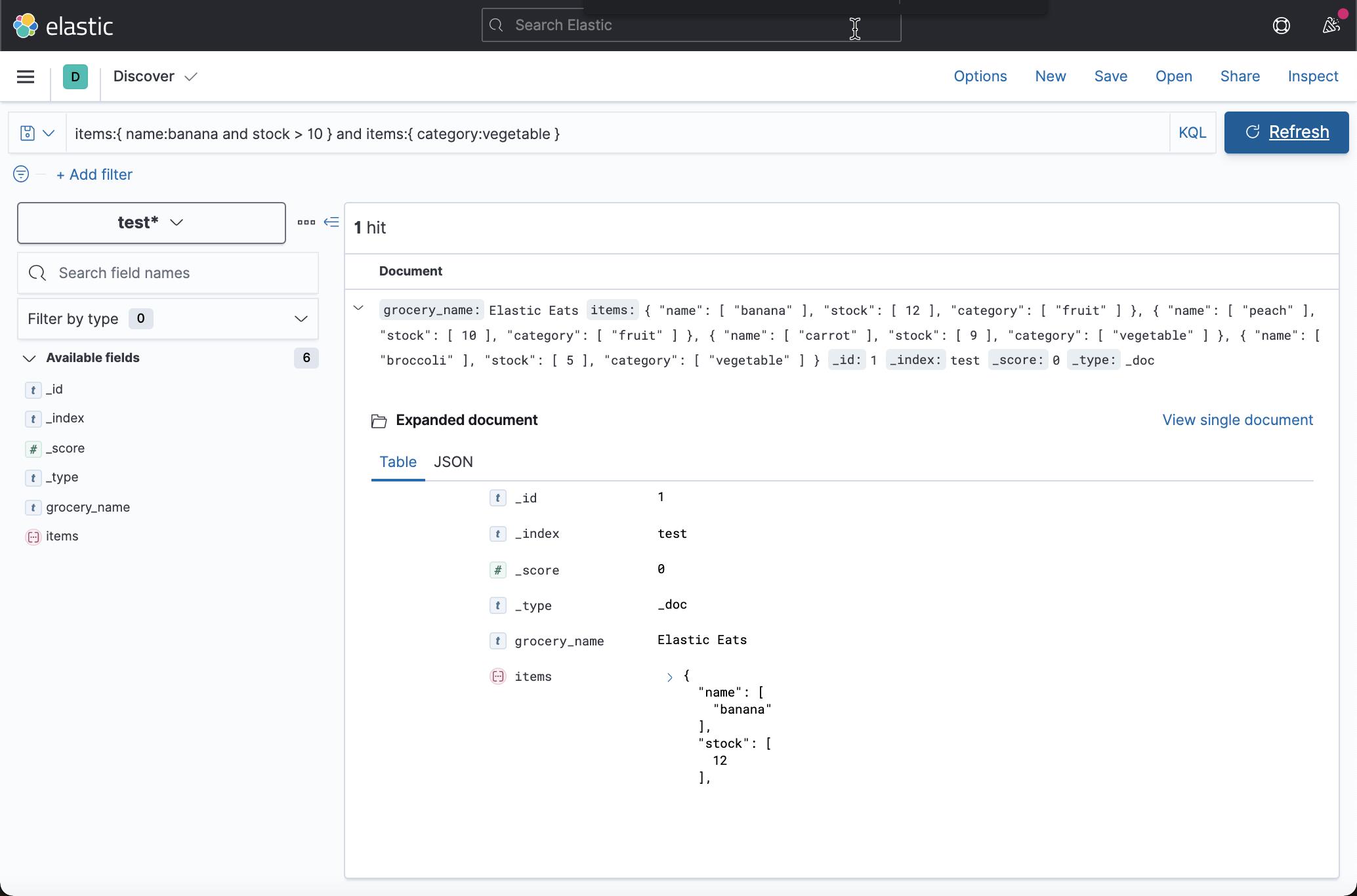
第一个嵌套组(name:banana and stock > 10)必须匹配单个文档,但是 category:vegetables 子查询可以匹配不同的嵌套文档,因为它在一个单独的组中。
其他嵌套字段内的嵌套字段
KQL 支持其他嵌套字段中的嵌套字段——你必须指定完整路径。 在本文档中,level1 和 level2 是嵌套字段:
{
"level1": [
{
"level2": [
{
"prop1": "foo",
"prop2": "bar"
},
{
"prop1": "baz",
"prop2": "qux"
}
]
}
]
}要匹配单个嵌套文档:
level1.level2:{ prop1:foo and prop2:bar }参考:
【1】https://www.elastic.co/guide/en/kibana/current/kuery-query.html
以上是关于Kibana:Kibana Query Language - KQL的主要内容,如果未能解决你的问题,请参考以下文章