Go Elasticsearch CRUD 快速入门
Posted 恋喵大鲤鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Go Elasticsearch CRUD 快速入门相关的知识,希望对你有一定的参考价值。

文章目录
1.简介
Elasticsearch(ES) 是一个基于 Apache Lucene 开源的分布式、高扩展、近实时的数据搜索与分析引擎,主要用于海量数据快速存储,实时检索,高效分析的场景。通过简单易用的 RESTful API,隐藏 Lucene 的复杂性,让全文搜索变得简单。
ES 功能总结有三点:
- 分布式存储
- 分布式搜索
- 分布式分析
因为是分布式,可将海量数据分散到多台服务器上存储,检索和分析,只要是海量数据需要完成上面这三种操作的业务场景,一般都会考虑使用 ES,比如维基百科,Stack Overflow,GitHub 后台均有使用。
GitHub。
2.特点
ES 为什么这么受欢迎,得益于其相较于传统数据库所拥有的强大功能。
- ES 不是什么新技术,主要是将全文检索、数据分析以及分布式技术结合在一起,形成了独一无二的 ES;
- 数据库的功能面对很多领域是不够用的,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;ES 作为传统数据库的一个补充,提供了数据库所不不能提供的很多功能;
- 可以作为一个大型分布式集群(数百台服务器)技术,处理 PB 级数据,服务大公司;也可以运行在单机上,服务小公司;
- 对用户而言,开箱即用,非常简单,作为中小型的应用,分钟级部署,就可以作为生产环境的系统来使用了。
3 Kibana
说到 ES 必须要提一下 Kibana 。
ES 和 Logstash,Kibana 共同组成 ELK,ELK 是这三个开源项目的首字母缩写。ES 是一个搜索和分析引擎,Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 ES 等存储库中。Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
Kibana 以 Web 后台的形式提供了一个可视化操作 ES 的系统,支持根据 ES 数据绘制图表,支持 ES 查询语法自动补全等高级特性,更加方便了我们操作 ES。
4.存储结构
要想完成对 ES 的增删改查,必须先了解一下 ES 的存储结构。
大家对 mysql 的存储结构应该是很清楚的,所以咱们在学习 ES 存储结构时,同时类比 MySQL,这样理解起来会更透彻。MySQL 的数据模型由数据库、表、字段、字段类型组成,自然 ES 也有自己的一套存储结构。
ES 存储结构 与 MySQL 存储结构的对应关系。
| ES存储结构 | MySQL存储结构 |
|---|---|
| Index | 表 |
| Document | 行 |
| Field | 表字段 |
| Mapping | 表结构定义 |
index
索引(index)就像 MySQL 中的表一样,代表着文档数据的集合,文档相当于 ES 中存储的一条数据,下面会详细介绍。
type
type 为文档类型,不过在 ES 7.0 以后的版本 已经废弃文档类型了,一个 index 中只有一个默认的 type,即 _doc。在 ES 老版本中文档类型代表一类文档的集合,index 类似 MySQL 的数据库,文档类型类似 MySQL 的表。既然 ES 新版本文档类型没什么作用了,那么 index(索引)就类似 mysql 的表的概念,ES 没有数据库的概念了。
document
ES 是面向文档的数据库,文档是 ES 存储的最基本的存储单元,文档类似 MySQL 表中的一行数据。在 ES 中,文档使用 JSON 格式存储,因此存储上要比 MySQL 灵活很多,因为 ES 支持任意格式的 JSON 数据。
{
"_index" : "order",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"id" : 10000,
"status" : 0,
"total_price" : 10000,
"create_time" : "2020-09-06 17:30:22",
"user" : {
"id" : 10000,
"username" : "asong2020",
"phone" : "888888888",
"address" : "深圳人才区"
}
}
}
其中 _source 为记录的具体内容,其他字段为文档的元数据,是插入 JSON 记录时 ES 自动生成的系统字段,二者共同组成一个 document。
常用的元数据有:
- _index:代表当前文档所属索引
- _type:代表当前文档所属类型(ES 7.0 以后废弃了 type 用法,但是元数据还是可以看到的)
- _id:文档唯一 ID,如果没有为文档指定 ID 则自动生成。
- _source:文档的原始 JSON 数据
- _version:文档的版本号,每修改一次文档,字段就会加 1,这个字段新版 ES 也给取消了
- _seq_no:文档编号,每修改一次文档,字段就会加 1,替代老的 version。注意 seq_no 递增属于整个 index,而不是单个文档
- _primary_term:文档所在主分区,这个可以跟 seq_no 搭配实现乐观锁并发控制,以防止旧版本的文档覆盖较新的文档
field
文档由多个 JSON 字段,这个字段跟 MySQL 中的表的字段是类似的。ES中的字段也是有类型的,常用字段类型有:
- 数值类型(long、integer、short、byte、double、float)
- Date 日期类型
- boolean 布尔类型
- Text 支持全文搜索
- Keyword 不支持全文搜索,例如:phone这种数据,用一个整体进行匹配就ok了,也不要进行分词处理
- Geo 这里主要用于地理信息检索、多边形区域的表达。
mapping
ES 的 mapping 类似于 MySQL 的表结构体定义,每个索引都有一个映射的规则,我们可以通过定义索引的映射规则,提前定义好文档的 JSON 结构和字段类型,如果没有定义索引的映射规则,ES 会在写入数据的时候,根据我们写入的数据字段推测出对应的字段类型,相当于自动定义索引的映射规则。
注意:ES 的自动映射是很方便的,但是实际业务中,对于关键字段类型,我们都是通常预先定义好,这样可以避免 ES 自动生成字段类型不是你想要的类型。
5.重要概念
除了数据结构的相关概念,因 ES 是一个分布式支持水平扩展的数据库系统,必然少不了分布式相关的概念,这个最好也需要了解一下。
cluster
一个集群由一个或多个节点组成,它们共同持有数据,一起提供存储搜索功能。
集群由一个唯一的名字进行区分,默认为"elasticsearch",集群中的节点通过整个唯一的名字加入集群。
node
节点是 ES 集群的一部分,只要多个节点在同个网络中,节点就可以通过指定集群的名称加入某个集群,与集群中的其他节点相互感知。
和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
shards
索引可以存储大量的数据,这些数据可能超过单个节点的硬件限制,为了解决这一问题,ES 提供细分索引的能力,即分片。
ES 可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上,构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
replicas
在一个网络环境里,节点故障随时都可能发生,在某个分片/节点出现故障时,有一个备份机制是非常有用的。为此 ES 允许你为分片创建一份或多份拷贝,这些拷贝叫做副本(replicas)。
副本之所以重要,主要有两方面的原因:一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高查询效率,ES 会自动对搜索请求进行负载均衡。
总之,每个索引可以被分成多个分片。一个索引也可以被复制 0 次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片和副分片(主分片的拷贝)。分片和复本的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变副本数量,但是不能改变分片的数量。
默认情况下,ES 中的每个索引被分片 5 个主分片和 1 个副分片,不过从 7.x 版本开始,主分片由 5 改为了 1 个。如果你的集群中至少有两个节点,你的索引将会有 5 个主分片和另外 5 个副分片,这样的话每个索引总共就有 10 个分片。一个索引的多个分片可以存放在集群中的一台主机上,也可以分散存放在多台主机上,这取决于你的集群机器数量。主分片和副分片的具体位置是由 ES 内在的策略所决定的。
6.客户端库
ES 的 Go 客户端较为流行的有 Elastic 公司官方库go-elasticsearch 和第三方库 olivere/elastic,后者较为流行。
因项目中使用的是 olivere/elastic/v7,所以本文将介绍通过该库完成对 ES 的增删改查。
注意,ES 不同版本需要使用对应版本的 olivere/elastic 包,对应关系如下:
| Elasticsearch version | Elastic version | Package URL | Remarks |
|---|---|---|---|
| 7.x | 7.0 | github.com/olivere/elastic/v7 | Use Go modules |
| 6.x | 6.0 | github.com/olivere/elastic | Use a dependency manager |
| 5.x | 5.0 | gopkg.in/olivere/elastic.v5 | Actively maintained |
本次使用 ES 的 7.x 的版本,所以使用 github.com/olivere/elastic/v7 作为客户端库,使用 go.mod 来管理依赖:
require(
github.com/olivere/elastic/v7 v7.0.24
)
7.创建客户端
前面铺垫了这么多基础概念,下面正式开始 Go ES 的增删改查。
在开始实战之前,先介绍一下本文代码示例要实现的功能:
- 添加用户信息
- 更新用户信息
- 删除用户信息
- 根据电话查询指定用户
- 根据昵称、身份、籍贯查询相关用户(查找相似昵称的用户列表、身份相同的用户列表、同城的用户列表)
在进行开发之前,需要创建一个 client,用于操作 ES。这里使用单例模式来实现。示例代码如下:
// ES 客户端
var (
esOnce sync.Once
esCli *elastic.Client
)
// GetESClient 获取 ES client
func GetESClient() *elastic.Client {
if esCli != nil {
return esCli
}
esOnce.Do(func() {
cli, err := elastic.NewSimpleClient(
elastic.SetURL("http://test.es.db"), // 服务地址
elastic.SetBasicAuth("user", "secret"), // 账号密码
elastic.SetErrorLog(log.New(os.Stderr, "", log.LstdFlags)), // 设置错误日志输出
elastic.SetInfoLog(log.New(os.Stdout, "", log.LstdFlags)), // 设置info日志输出
)
if err != nil {
panic("new es client failed, err=" + err.Error())
}
esCli = cli
})
return esCli
}
这里创建 ES client 是使用的 NewSimpleClient() 这个方法进行实现的,当然也可以使用另外两个方法:
// NewClient creates a new client to work with Elasticsearch.
func NewClient(options ...ClientOptionFunc) (*Client, error)
// NewClientFromConfig initializes a client from a configuration
func NewClientFromConfig(cfg *config.Config) (*Client, error)
创建时可以提供 ES 连接参数。上面列举的不全,下面给大家介绍一下。
elastic.SetURL(url) 用来设置ES服务地址,如果是本地,就是127.0.0.1:9200。支持多个地址,用逗号分隔即可
elastic.SetBasicAuth("user", "secret") 这个是基于http base auth 验证机制的账号密码
elastic.SetGzip(true) 启动 gzip 压缩
elastic.SetHealthcheckInterval(10*time.Second) 用来设置监控检查时间间隔
elastic.SetMaxRetries(5) 设置请求失败最大重试次数,v7 版本以后已被弃用
elastic.SetSniff(false) 设置是否定期检查集群(默认为true)
elastic.SetErrorLog(log.New(os.Stderr, " ", log.LstdFlags)) 设置错误日志输出
elastic.SetInfoLog(log.New(os.Stdout, "", log.LstdFlags)) 设置info日志输出
8.创建 index
上一步,我们创建了 client,接下来我们就要创建对应的 index 以及 对应的 mapping,mapping 用于描述 document 的 JSON 结构和字段类型。
设计一个 mapping 用来描述我们要存储的用户信息,mapping 也用一个 JSON 串来表示。
ESMapping = `{
"mappings":{
"dynamic": "strict",
"properties":{
"id": { "type": "long" },
"username": { "type": "keyword" },
"nickname": { "type": "text" },
"phone": { "type": "keyword" },
"age": { "type": "long" },
"ancestral": { "type": "text" },
"identity": { "type": "text" },
"update_time": { "type": "long" },
"create_time": { "type": "long" }
}
}
}`
一般的,mapping 可以分为动态映射(dynamic mapping)和静态(显式)映射(explicit mapping)和精确(严格)映射(strict mappings),具体由 dynamic 属性控制。
其中 "dynamic": "strict" 表示字段需要严格匹配,新增或类型不一致写入将会报错。
索引名称定义为:index = es_index_userinfo。
设计好了 index 及 mapping 后,我们开始编写代码进行创建:
// ESIndexExists 索引是否存在
func ESIndexExists(ctx context.Context, index string) (bool, error) {
return GetESClient().IndexExists(index).Do(ctx)
}
// CrtESIndex 创建 ES 索引
func CrtESIndex(ctx context.Context, index, mapping string) error {
exist, err := ESIndexExists(ctx, index)
if err != nil {
return err
}
// 已经创建
if exist {
return nil
}
// 重复创建会报错
_, err = GetESClient().CreateIndex(index).BodyString(mapping).Do(ctx)
return err
}
因为重复创建 index,ES 会报错,所以创建前先判断一下是否已经创建。
创建成功后,我们在 Kibana 上通过 Restful API 可以查看到刚刚创建的 index。
GET /es_index_userinfo
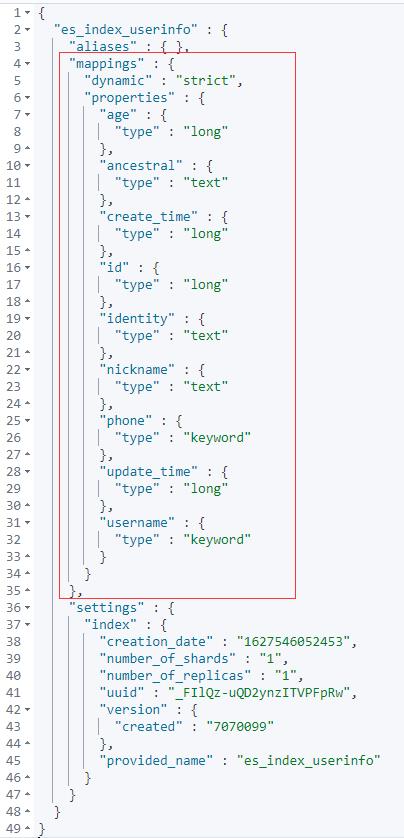
对应的 RESTful API 为:
PUT /es_index_userinfo
{
"mappings":{
"dynamic": "strict",
"properties":{
"id": { "type": "long" },
"username": { "type": "keyword" },
"nickname": { "type": "text" },
"phone": { "type": "keyword" },
"age": { "type": "long" },
"ancestral": { "type": "text" },
"identity": { "type": "text" },
"update_time": { "type": "long" },
"create_time": { "type": "long" }
}
}
}
9.增加
创建完 index,便可以向 index 中添加记录。
// Create2ES 添加记录到 ES
func Create2ES(ctx context.Context, index, id, json string) error {
_, err := GetESClient().Index().Index(index).OpType("create").Id(id).BodyJson(json).Refresh("wait_for").Do(ctx)
return err
}
index 为索引,id 唯一标识一条记录,也就是 document,json 为 JSON 格式的数据,即 document 原始 JSON 数据。“wait_for” 表示等待完成刷盘,这样写入的数据才可以搜索到。ES 自动刷新发生变更的每个索引的分片,刷新间隔为index.refresh_interval,缺省为 1 秒。
注意:重复创建会报elastic: Error 409 (Conflict)错误。
写入成功后,通过 RESTful API 在 Kibana 查看到刚刚写入的文档。
GET /es_index_userinfo/_doc/1

_doc 为文档类型,1 为文档 ID。
当然,我们也可以通过 RESTful API 写入文档。
PUT /es_index_userinfo/_doc/1
{
"id": 1,
"username": "alice",
"nickname": "cat",
"phone":18819994334,
"age": 18,
"ancestral": "安徽",
"identity":"12345678",
"update_time":1627522828,
"create_time":1627522828
}
10.删除
可以根据文档 ID 删除对应的文档。
// Delete4ES 通过 ID 删除文档
func Delete4ES(ctx context.Context, index, id string) error {
_, err := GetESClient().Delete().Index(index).Id(id).Refresh("wait_for").Do(ctx)
return err
}
注意:重复删除会报elastic: Error 404 (Not Found)错。
对应 RESTful API 为:
DELETE /es_index_userinfo/_doc/1?refresh=true
我们也可以根据条件来删除符合条件的文档,即 Delete by Query。
// DeleteByQuery4ES 根据条件删除文档
// param: index 索引; query 条件
// ret: 删除的文档数; error
func DeleteByQuery4ES(ctx context.Context, index string, query elastic.Query) (int64, error) {
rsp, err := GetESClient().DeleteByQuery(index).Query(query).Refresh("true").Do(ctx)
if err != nil {
return 0, err
}
return rsp.Deleted, nil
}
注意:Refresh 只能指定 true 或 false(缺省值),不能指定 wait_for。
比如我们删除昵称为 cat 且年龄小于等于18 的用户。
query := elastic.NewBoolQuery()
query.Filter(elastic.NewTermQuery("nickname", "cat"))
query.Filter(elastic.NewRangeQuery("age").Lte(18))
ret, err := DeleteByQuery4ES(context.Background(), index, query)
对应的 RESTful api 为:
POST /es_index_userinfo/_delete_by_query?refresh=true
{
"query":{
"bool":{
"filter":[
{"term" : {"nickname" : "cat"}},
{"range" : {"age" : {"lte" : 18}}}
]
}
}
}
11.修改
可以根据文档 ID 更新对应的文档。
// Update2ES 修改文档
// param: index 索引; id 文档ID; m 待更新的字段键值结构
func Update2ES(ctx context.Context, index, id string, m map[string]interface{}) error {
_, err := GetESClient().Update().Index(index).Id(id).Doc(m).Refresh("wait_for").Do(ctx)
return err
}
注意:修改不存在的文档将报elastic: Error 404 (Not Found)错误。
比如修改文档 ID 为 1 的用户名改为 “jack”。
err := Update2ES(context.Background(), index, "1", map[string]interface{}{"username": "jack"})
对应的 RESTful api 为:
POST /es_index_userinfo/_update/1?refresh=wait_for
{
"doc": {
"username": "jack"
}
}
我们也可以根据条件来更新符合条件的文档,即 Update by Query。
// UpdateByQuery2ES 根据条件修改文档
// param: index 索引; query 条件; script 脚本指定待更新的字段与值
func UpdateByQuery2ES(ctx context.Context, index string, query elastic.Query, script *elastic.Script) (int64, error) {
rsp, err := GetESClient().UpdateByQuery(index).Query(query).Script(script).Refresh("true").Do(ctx)
if err != nil {
return 0, err
}
return rsp.Updated, nil
}
注意:Refresh 只能指定 true 或 false(缺省值),不能指定 wait_for。
比如我将更新用户名为 alice,年龄小于等于 18 岁的用户昵称和祖籍。
query := elastic.NewBoolQuery()
query.Filter(elastic.NewTermQuery("username", "alice"))
query.Filter(elastic.NewRangeQuery("age").Lte(18))
script := elastic.NewScriptInline("ctx._source.nickname=params.nickname;ctx._source.ancestral=params.ancestral").Params(
map[string]interface{}{
"nickname": "cat",
"ancestral": "安徽",
})
ret, err := UpdateByQuery2ES(context.Background(), index, query, script)
对应的 RESTful api 为:
POST /es_index_userinfo/_update_by_query?refresh=true
{
"query":{
"bool":{
"filter":[
{"term":{"username":"alice"}},
{"range" : {"age" : {"lte" : 18}}}
]
}
},
"script": {
"source": "ctx._source['nickname'] = 'cat';ctx._source['ancestral'] ='安徽'"
}
}
12.查询
搜索是 ES 最为复杂精妙的地方,这里只示例项目中较为常用的查询。
12.1 根据ID查询
根据文档ID获取单个文档信息。
// GetByID4ES 根据ID查询单个文档
func GetByID4ES(ctx context.Context, index, id string) (string, error) {
res, err := GetESClient().Get().Index(index).Id(id).Do(ctx)
if err != nil {
return "", err
}
return string(res.Source), nil
}
注意:查询不存在的ID,回报elastic: Error 404 (Not Found)错误。
对应的 RESTful api 为:
GET /es_index_userinfo/_doc/1
12.2 分页查询
我们也可以根据条件分页查询。
ES 分页搜索一般有三种方案,from + size、search after、scroll api,这三种方案分别有自己的优缺点。
12.2.1 from + size
这是 ES 分页中最常用的一种方式,与 MySQL 类似,from 指定起始位置,size 指定返回的文档数。
这种分页方式,在分布式的环境下的深度分页是有性能问题的,一般不建议用这种方式做深度分页,可以用下面将要介绍的两种方式。
理解为什么深度分页是有问题的,假设取的页数较大时(深分页),如请求第20页,Elasticsearch不得不取出所有分片上的第1页到第20页的所有文档,并做排序,最终再取出 from 后的 size 条结果作爲最终的返回值。
<以上是关于Go Elasticsearch CRUD 快速入门的主要内容,如果未能解决你的问题,请参考以下文章