大数据常用调度平台
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据常用调度平台相关的知识,希望对你有一定的参考价值。
目录
1. 项目结构
- 目标
- 理解项目中为什么需要调度平台
- 步骤
- 项目介绍
- 项目结构
1.1. 项目介绍
项目功能
- 标签创建
- 标签计算
- 标签审计
- …
如果要对标签进行计算, 就需要把标签和标签的计算都管理起来
- 创建标签时, 执行标签计算任务
- 把计算和标签关联起来, 通过标签能找到任务, 通过任务也知道它计算的是什么标签
- 标签, 年龄就是一个标签
- 计算任务, 为了计算年龄标签, 需要去读取用户数据, 计算每一个用户是哪一个标签
- 用户画像数据, 每一个用户的标签, 就是用户画像数据
- 修改标签时, 标签计算任务同步修改
- 删除标签时, 标签计算任务停止
所以, 我们的项目需要和调度平台结合起来, 不仅管理标签本身, 也需要管理标签相关联的任务, 所以需要配合调度平台来管理
1.2. 项目结构
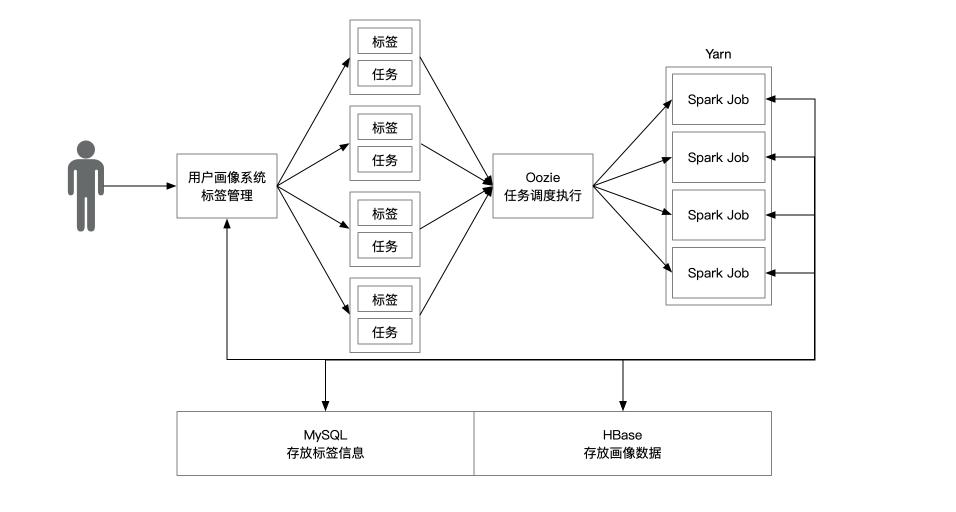
- 管理者通过画像系统添加, 修改, 删除标签
- 画像系统将标签抽象为标签和任务, 通过 Oozie 调度到 Yarn 中
- Yarn 中的 Spark 任务读取 mysql 中的标签元信息
- Spark 任务通过 HBase 读取需要计算的数据
- 计算完成后, 插入 HBase 对应的表中
2. Oozie 介绍
- 目标
- 了解 Oozie 的作用
- 步骤
- 需求
- 可选的方式
- Oozie 和同类的对比
2.1. 需求
- 现在要计算年龄标签, 有七个阶段, 50后、60后、70后、80后、90后、00后、10后、20后
- 通过 Spark 写了一个程序, 读取用户年龄, 把每个用户的年龄映射到每个阶段内
- 因为年龄标签变化的频率不高, 所以决定要一年计算一次
- 如何完成这个计算任务的调度?
2.2. 可选的方式
2.2.1. Crontab
-
Crontab 是 Linux 的一个调度程序, 允许我们通过一个简洁的语法表示调度周期, 在对应的时间点周期性的执行某个 Shell 脚本或者 Shell 命令
# 分 时 日 月 星期 要运行的命令 # 每1分钟执行一次myCommand * * * * * myCommand # 每小时的第3和第15分钟执行 3,15 * * * * myCommand # 在上午8点到11点的第3和第15分钟执行 3,15 8-11 * * * myCommand # 每周一上午8点到11点的第3和第15分钟执行 3,15 8-11 * * 1 myCommand -
我们可以编写一个 Shell 脚本, 其中写上
spark-submit --master yarn \\ --class xx --executor-memory 500m --executor-cores 1 --num-executors 1 xx.jar args1 -
然后再将如下的 cron 加入 crontab
0 20 * * * tag_age.shell
这样的方式有如下几个问题
- cron 任务只能通过命令来管理
crontab -e
- 如果换成如下的需求, 这个流程我们该如何控制呢?
- 把数据抽取到 HBase 中
- 同步执行如下两个任务
- 合并用户数据和订单数据, 生成宽表
- 合并用户数据和商品数据, 生成宽表
- 合并两个宽表, 计算用户标签
- 如果执行的程序出错了, 只能登录到对应的主机查看 Log
- …
2.2.2. Oozie
- 创建一个 Workflow, 表示一个任务的执行流程
- 创建一个 Coordinator, 表示任务的执行周期
- 通过 Hue 提交任务
- 通过 Hue 查看任务执行的 Log
2.3. Oozie 和竞品的对比
现在市面上比较多见的调度平台分别是 Oozie 和 Azkaban, 还有一个后起之秀 AirFlow
| Airflow | Azkaban | Oozie | |
|---|---|---|---|
| 机构 | Airbnb | Apache | |
| 社区 | Very Active | Somewhat active | Active |
| 历史 | 4年 | 7 年 | 8 年 |
| 目的 | General Purpose Batch Processing | Hadoop 作业调度 | Hadoop 作业调度 |
| 流程定义 | Python | Custom DSL | XML |
| 单节点 | 支持 | Yes | Yes |
| 快速开始 | 支持 | 支持 | 不支持 |
| 高可用 | Yes | Yes | Yes |
| 单点故障 | 是 | 是 | 不, 使用 Yarn |
| 运行模式 | Push | Push | Poll |
| Rest API 触发 | Yes | Yes | Yes |
| 外部事件触发 | Yes | No | Yes |
| Web 权限 | LDAP/Password | XML Password | Kerberos |
| 监控 | Yes | Limited | Yes |
| 可扩展性 | Depending on executor setup | Good | Very Good |
- 在对工具的支持上, Airflow 和 Oozie 都很好, 但是 Airflow 要简便一些
- 功能上, Oozie 最强大
- 稳定性上, Oozie 最稳定
- 上手速度, Azkaban 最快
- 带有个人情绪的简评, Oozie 最稳定, 也最难以驾驭, 坑多
3. Oozie 组件
- 目标
- 理解 Oozie 各个组件
- 步骤
- Workflow
- Coordinator
3.1. Workflow
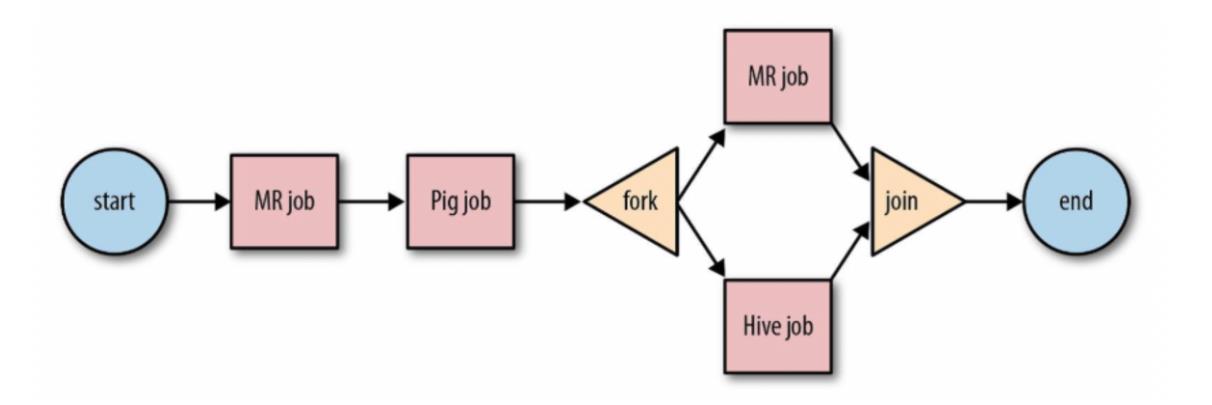
- Workflow 就是一个工作流, 从
start开始, 到end结束 - Workflow 中提供了
Fork和Join机制- Fork 可以使得多个任务并行
- Join 可以让并行的任务汇总
- Workflow 中提供了
Decision机制- 类似于 if 一样, 可以提供分支选择功能
- 在任务执行完成后, Workflow 可以以发送邮件, 短信等方式通知
- Workflow 提供了一种类似 DAG 的方式来执行一组任务
- Oozie 支持 MR, Hive, Spark, Shell 等的支持
3.2. Coordinator

- Workflow 表示了任务的实现和关系
- Oozie 提供了 Coodinator, 用来调度 Workflow
- Coordinator 在 Hue 中叫做 Scheduler
4. 调度实现
- 目标
- 实现工程中的调度功能
- 步骤
- 执行流程
- Workflow
- Coordinator
- Java 代码
- 调度 Workflow
4.1. 执行流程
- 用户在网页中添加四级标签, 因为四级标签代表标签, 五级标签代表标签值域
- 上传 Jar 包
- 提交标签
- 后端收到添加标签的请求, 存储标签信息并将 Jar 包上传到 HDFS
cn.itcast.tag.web.basictag.controller.BasicTagController#modelUpload
- 用户在网页中开启标签计算
- 后端收到请求, 联系 Oozie 开始调度
添加标签的执行流程如下
- 调用了 BasicTagController
- 在 BasicTagController 中调用了 BasicTagService
- 保存 Tag 信息, 指的就是具体的标签数据, 比如说标签叫什么, 谁创建的, 什么时候创建的, 级别…
- 保存 Model 信息, 标签是需要计算的, 我们使用 Spark Job 计算, Main方法在哪个类, Jar 包的位置等…
- 在保存之前, 把 Model 对应 Jar 包上传到 HDFS 中
- 路径
/app/models/Tag_10/xx.jar
开启任务的流程如下
- 调用 TaskProcessing 中的方法
- TaskProcessing 会调用 EngineService 中的 start 方法
- 传进来了一个 标签 ID
4.2. Workflow
- Workflow 使用 XML 编写, 是一种通过配置表示过程的方式
- Workflow 中的配置无需太过认真的了解, 大致知道流程即可
- 因为一般情况下, 我们使用 Hue 或者 Ambari 的图形化方式去编辑 Workflow , 手写的可能性比较低
- Workflow 中可以使用 EL 表达式填充信息
<workflow-app name="Extra goods from hive to hbase fully" xmlns="uri:oozie:workflow:0.5">
<start to="tag-model-job"/>
<action name="tag-model-job">
<spark xmlns="uri:oozie:spark-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<master>${sparkMaster}</master>
<mode>${sparkDeployMode}</mode>
<name>${oozieWFName}</name>
<class>${sparkJobMain}</class>
<jar>${sparkJobJar}</jar>
<spark-opts>${sparkJobOpts}</spark-opts>
<arg>${sparkMainOpts}</arg>
<file>${sparkContainerCacheFiles}</file>
</spark>
<ok to="End"/>
<error to="Kill"/>
</action>
<kill name="Kill">
<message>Action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="End"/>
</workflow-app>
4.3. Coordinator
- 此处的 Coordinator 只是为了周期性调度 Workflow
- 在项目中提供的调度周期有: 日, 月, 年
<?xml version="1.0" encoding="UTF-8"?>
<coordinator-app name="cron-coordinator" frequency="${coord:days(1)}"
start="${start}" end="${end}" timezone="Asia/Shanghai" xmlns="uri:oozie:coordinator:0.5">
<action>
<workflow>
<app-path>${oozieWorkflowPath}</app-path>
</workflow>
</action>
</coordinator-app>
4.4. Java 代码
private boolean startEngineActually(EngineBean engineBean) {
ModelBean modelBean = modelMapper.get(new ModelBean(engineBean.getTagId()));
MetaDataBean metaDataBean = metaDataMapper.get(new MetaDataBean(engineBean.getTagId()));
// 1. 判断模型和元数据是否存在, 如果不存在则启动失败
HdfsUtil hdfsUtil = HdfsUtil.getInstance();
if (!hdfsUtil.exist(modelBean.getModelPath())) {
logger.error("模型包不存在, 启动失败");
return false;
}
if (StringUtils.isBlank(metaDataBean.getInType())) {
logger.error("模型元信息不存在或者缺失 InType, 启动失败");
return false;
}
// 2. 上传 Oozie 配置到 HDFS
String localOozieConfigPath = engineBean.getRemark() + oozieConfigDirName + "/";
String tagModelPath = hdfsUtil.getPath(new File(modelBean.getModelPath()).getParent());
hdfsUtil.uploadLocalFile2HDFS(localOozieConfigPath + workflowFileName, tagModelPath);
hdfsUtil.uploadLocalFile2HDFS(localOozieConfigPath + coordinatorFileName, tagModelPath);
// 3. 构建 Oozie job 参数
OozieUtil oozie = oozieUtil.build();
Properties oozieConf = oozie.getConf();
// 3.1. Workflow 部分
String separator = "/";
oozieConf.setProperty("nameNode", nameNode);
oozieConf.setProperty("sparkJobMain", modelBean.getModelMain());
if (StringUtils.isNotBlank(modelBean.getArgs())) {
oozieConf.setProperty("sparkJobOpts", modelBean.getArgs());
}
oozieConf.setProperty("sparkJobJar", "${nameNode}" + modelBean.getModelPath());
oozieConf.setProperty("sparkContainerCacheFiles", "${nameNode}" + modelBean.getModelPath());
// 3.2. Coordinator 部分, Coordinator 中的时间格式是 UTC, 如 2018-06-019T20:01Z
oozieConf.setProperty("oozieWorkflowPath", "${nameNode}" + tagModelPath + separator);
oozieConf.setProperty("oozie.coord.application.path", "${nameNode}" + tagModelPath + separator + coordinatorFileName);
// ScheTime 的格式为 每天#2018-06-01 20::01#2018-06-01 20::01
String[] scheduleArr = modelBean.getScheTime().split("#");
String freq = scheduleArr[0];
String startDateTime = scheduleArr[1];
String endDateTime = scheduleArr[2];
// 设置频率
String freqStr = "";
switch (freq) {
case "每天":
freqStr = "day";
break;
case "每周":
freqStr = "week";
break;
case "每月":
freqStr = "month";
break;
case "每年":
freqStr = "year";
break;
}
oozieConf.setProperty("freq", freqStr);
// 设置开始时间
String[] startDateTimeArr = startDateTime.split(" ");
String startDate = startDateTimeArr[0];
String startTime = startDateTimeArr[1];
oozieConf.setProperty("start", startDate + "T" + startTime + "Z");
// 设置结束时间
String[] endDateTimeArr = endDateTime.split(" ");
String endDate = endDateTimeArr[0];
String endTime = endDateTimeArr[1];
oozieConf.setProperty("end", endDate + "T" + endTime + "Z");
logger.info(oozieConf.toString());
// 4. 提交 Oozie 任务
String jobId = oozie.start(oozieConf);
// 5. 设置监控
EngineBean mEngineBean = new EngineBean();
mEngineBean.setJobid(jobId);
mEngineBean.setTagId(engineBean.getTagId());
mEngineBean.setStatus("3");
int state = engineMapper.addMonitorInfo(mEngineBean);
return state > 0;
}
4.5. 执行流程
- 上传 Jar 包
- 创建四级标签
- 开启标签任务
- Hue 中查看
- 注意把 Filter 清空
4.5. 调度 Workflow
因为在测试阶段, 我们希望每次提交任务都立刻执行, 所以可以注释掉提交 Oozie 任务的代码, 改为直接提交 Workflow 任务
- 去掉 Coordinator 的位置, 改为 APP_PATH, 则会直接找到 Workflow 提交
private boolean startEngineActually(EngineBean engineBean) {
ModelBean modelBean = modelMapper.get(new ModelBean(engineBean.getTagId()));
MetaDataBean metaDataBean = metaDataMapper.get(new MetaDataBean(engineBean.getTagId()));
// 1. 判断模型和元数据是否存在, 如果不存在则启动失败
HdfsUtil hdfsUtil = HdfsUtil.getInstance();
if (!hdfsUtil.exist(modelBean.getModelPath())) {
logger.error("模型包不存在, 启动失败");
return false;
}
if (StringUtils.isBlank(metaDataBean.getInType())) {
logger.error("模型元信息不存在或者缺失 InType, 启动失败");
return false;
}
// 2. 上传 Oozie 配置到 HDFS
String localOozieConfigPath = engineBean.getRemark() + oozieConfigDirName + "/";
String tagModelPath = hdfsUtil.getPath(new File(modelBean.getModelPath()).getParent());
hdfsUtil.uploadLocalFile2HDFS(localOozieConfigPath + workflowFileName, tagModelPath);
hdfsUtil.uploadLocalFile2HDFS(localOozieConfigPath + coordinatorFileName, tagModelPath);
// 3. 构建 Oozie job 参数
OozieUtil oozie = oozieUtil.build();
Properties oozieConf = oozie.getConf();
// 3.1. Workflow 部分
String separator = "/";
oozieConf.setProperty("nameNode", nameNode);
oozieConf.setProperty("sparkJobMain", modelBean.getModelMain());
if (StringUtils.isNotBlank(modelBean.getArgs())) {
oozieConf.setProperty("sparkJobOpts", modelBean.getArgs());
}
oozieConf.setProperty("sparkJobJar", "${nameNode}" + modelBean.getModelPath());
oozieConf.setProperty("sparkContainerCacheFiles", "${nameNode}" + modelBean.getModelPath());
oozieConf.setProperty(OozieClient.APP_PATH, "${nameNode}" + tagModelPath + separator + workflowFileName);
// 3.2. Coordinator 部分, Coordinator 中的时间格式是 UTC, 如 2018-06-019T20:01Z
// oozieConf.setProperty("oozieWorkflowPath", "${nameNode}" + tagModelPath + separator);
// oozieConf.setProperty("oozie.coord.application.path", "${nameNode}" + tagModelPath + separator + coordinatorFileName);
//
// // ScheTime 的格式为 每天#2018-06-01 20::01#2018-06-01 20::01
// String[] scheduleArr = modelBean.getScheTime().split("#");
// String freq = scheduleArr[0];
// String startDateTime = scheduleArr[1];
// String endDateTime = scheduleArr[2];
//
// // 设置频率
// String freqStr = "";
// switch (freq) {
// case "每天":
// freqStr = "day";
// break;
// case "每周":
// freqStr = "week";
// break;
// case "每月":
// freqStr = "month";
// break;
// case "每年":
// freqStr = "year";
// break;
// }
// oozieConf.setProperty("freq", freqStr);
//
// // 设置开始时间
// String[] startDateTimeArr = startDateTime.split(" ");
// String startDate = startDateTimeArr[0];
// String startTime = startDateTimeArr[1];
// oozieConf.setProperty("start", startDate + "T" + startTime + "Z");
//
// // 设置结束时间
// String[] endDateTimeArr = endDateTime.split(" ");
// String endDate = endDateTimeArr[0];
// String endTime = endDateTimeArr[1];
// oozieConf.setProperty("end", endDate + "T" + endTime + "Z");
//
// logger.info(oozieConf.toString());
// 4. 提交 Oozie 任务
String jobId = oozie.start(oozieConf);
// 5. 设置监控
EngineBean mEngineBean = new EngineBean();
mEngineBean.setJobid(jobId);
mEngineBean.setTagId(engineBean.getTagId());
mEngineBean.setStatus("3");
int state = engineMapper.addMonitorInfo(mEngineBean);
return state > 0;
}
以上是关于大数据常用调度平台的主要内容,如果未能解决你的问题,请参考以下文章