Python基础入门自学——20--excel与数据库联合使用——工作实践项目
Posted kaoa000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python基础入门自学——20--excel与数据库联合使用——工作实践项目相关的知识,希望对你有一定的参考价值。
先对Python操作Excel做进一步的介绍。测试表数据:
选择某一列数据:使用sheet['A:A']形式

结果如下:
(<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.A2>, <Cell 'Sheet1'.A3>, <Cell 'Sheet1'.A4>, <Cell 'Sheet1'.A5>, <Cell 'Sheet1'.A6>, <Cell 'Sheet1'.A7>, <Cell 'Sheet1'.A8>)
是一个元组,元组的元素为列中每一行的数据,是单元格对象。关注的重点是这个元组的长度,即选择数据的范围:
选择多列:ws['A:B'] 
结果为:
((<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.A2>, <Cell 'Sheet1'.A3>, <Cell 'Sheet1'.A4>, <Cell 'Sheet1'.A5>, <Cell 'Sheet1'.A6>, <Cell 'Sheet1'.A7>, <Cell 'Sheet1'.A8>), (<Cell 'Sheet1'.B1>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.B4>, <Cell 'Sheet1'.B5>, <Cell 'Sheet1'.B6>, <Cell 'Sheet1'.B7>, <Cell 'Sheet1'.B8>))
元组套元组,每一列的所有单元格组成一个内层元组的元素,有几列,就有几个内层元组。
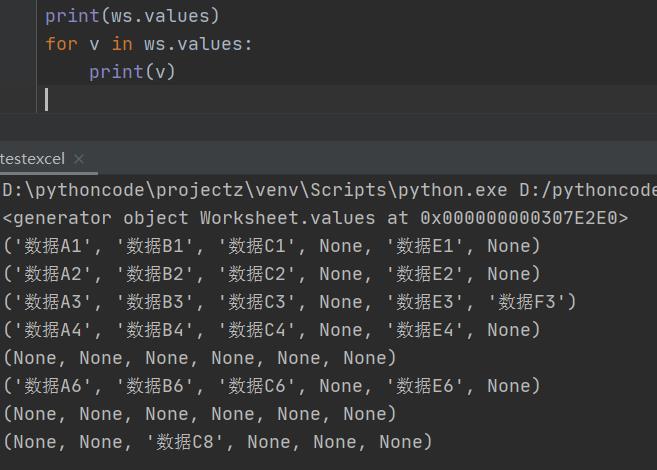
选择一个工作表的全部单元格的值:ws.values
前面学过得到一个单元格的值是先获得单元格对象,然后使用value属性,即ws['A1'].value
整个工作表的数值用:ws.values,得到一个全部值的生成器
以一行数据位一个元组,有多少行就有多少个元组。也是元组套元组。
获取所有行数据,一行的各列单元格组成一个元组,ws.rows,其与ws.values结果类似,只是这里是获得的单元格对象。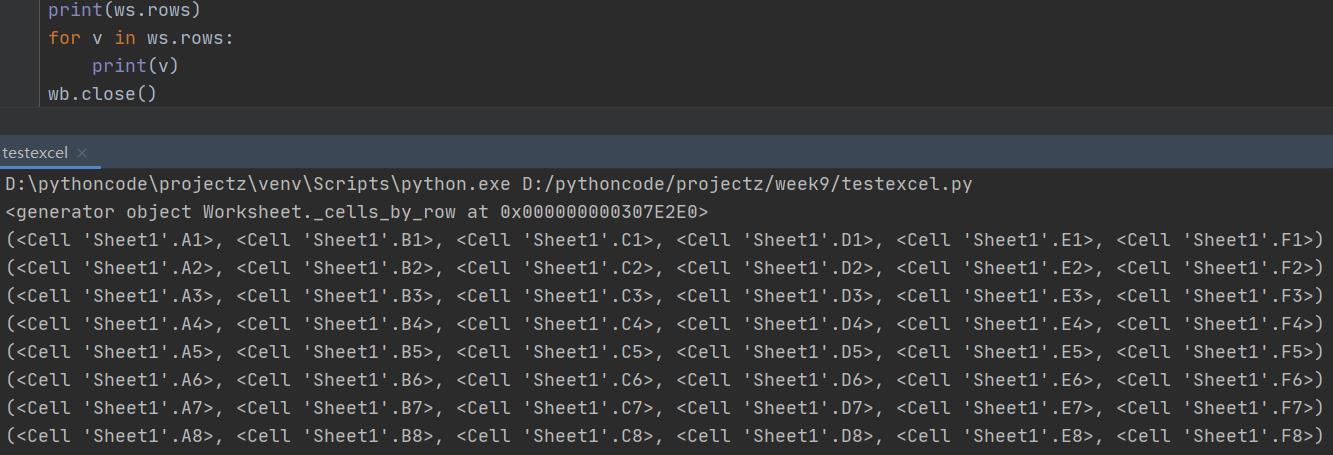
获取所有列的数据,是一列中的所有行数据组成一个元组。ws.columns
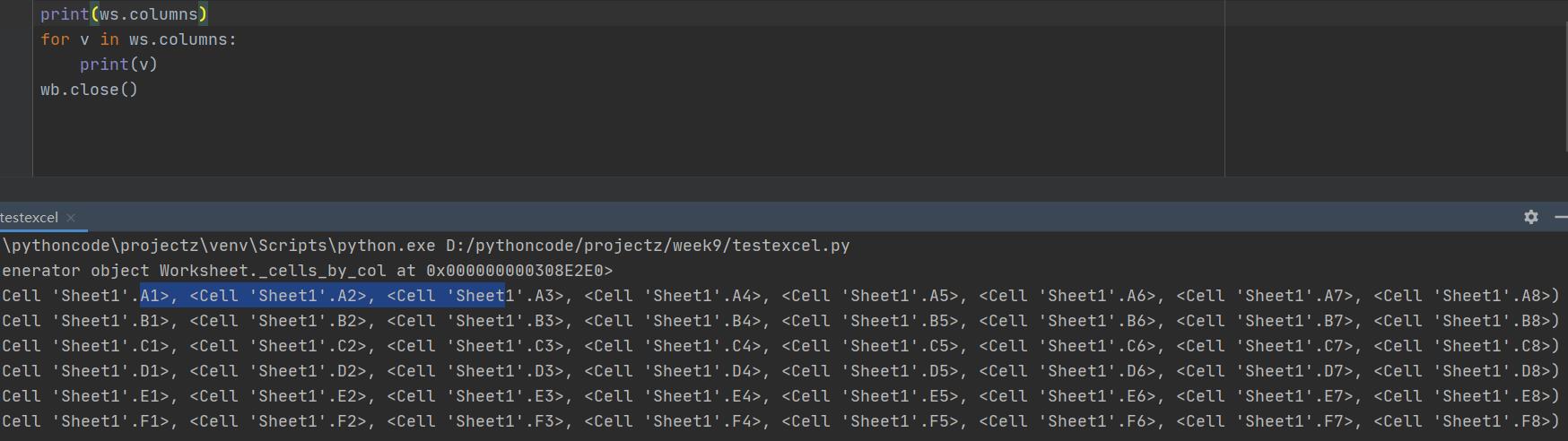
上面的都是获取全部数据单元格,如果想获取一个指定区域的单元格:
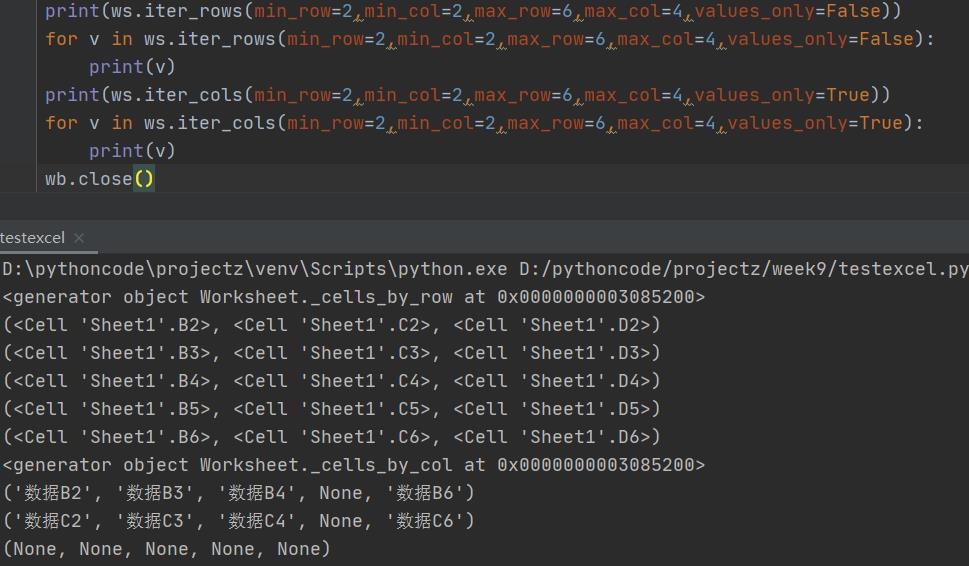
使用ws.iter_rows()返回多行
使用ws.iter_cols()返回多列
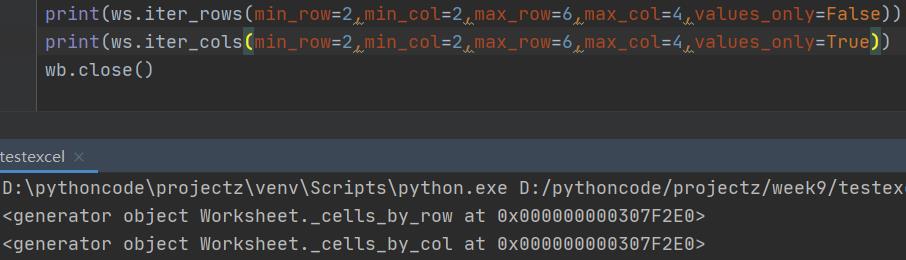
min_row,min_col确定区域的左上角单元格,max_row,max_col确定右上角,min可以不设置,缺省就是从A1开始。最关键的是value_only参数,缺省是false,即取的是单元格对象,如果设为True,就取值。

Python使用数据库,创建表:
主要是创建表的SQL语句的形成。创建表的SQL语句:
create table [schema].tablename(
column1 datatype [primary key] [not null],
...
)
tablespace tablespacename
1、直接写SQL语句执行:
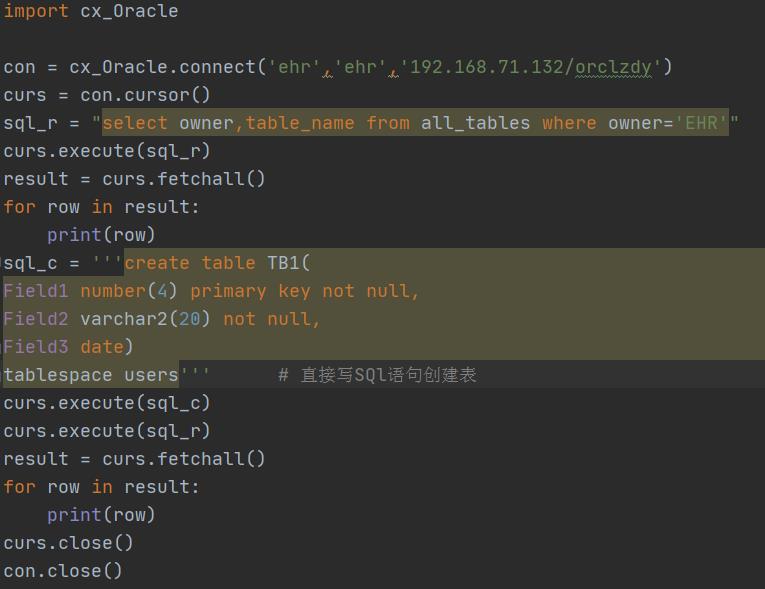
创建表的语句是直接写在程序中的。
2、拼接组合语句。
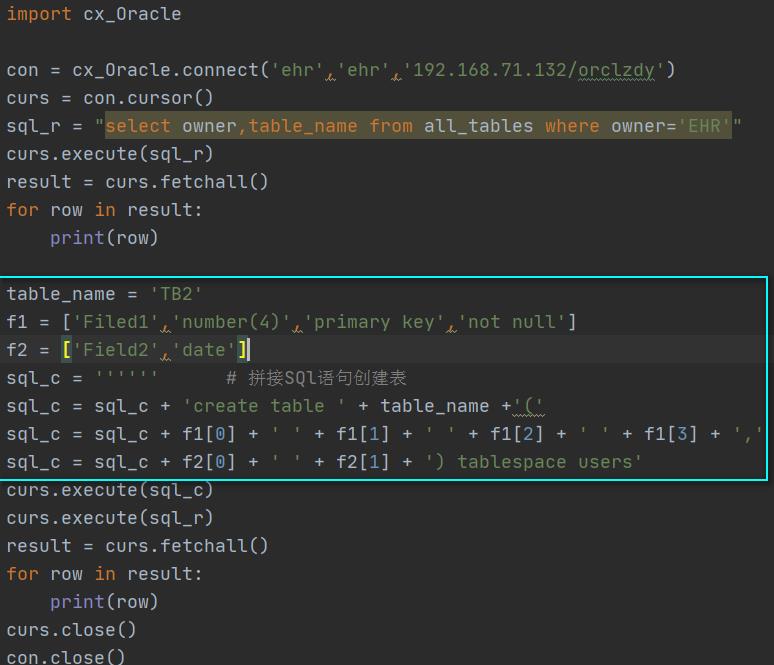
3、与Excel表结合,创建数据库表。
实践项目:
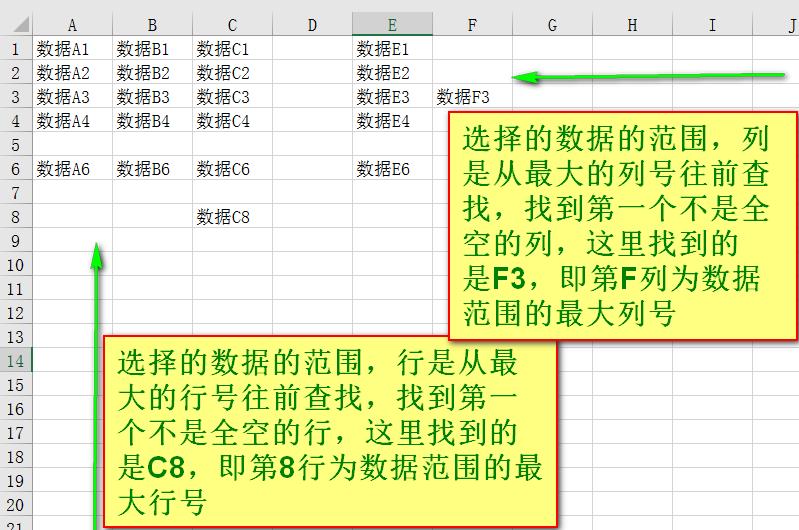
实际中使用的一个系统非常庞大复杂,其给出的查询功能只是简单的原始数据展示,现在想建一个数据库,将自己需要的一些数据导入其中,做自己想要的分析,第一步就是建立相应的数据库表。现在有这个系统的数据表的字典,格式大体如下:
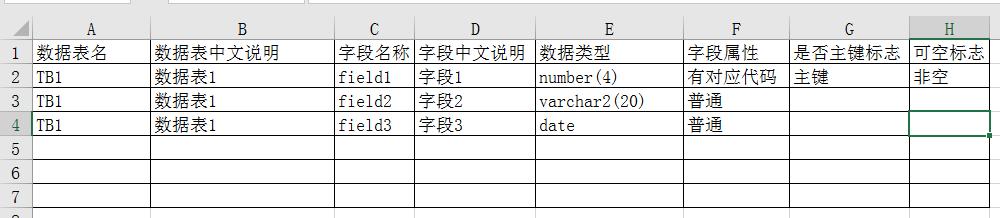
现在想根据这个表来创建数据库表。
如果只是创建几个简单的表,用不着编程实现,现在的实际情况是,这个系统的数据库表超过了2000+,表中的字段数,大体看了一下,有很多表的字段数量到了400+ ,平均字段数在三四十的样子,就是只创建二三十个表,手写SQL语句也很要命,于是编程实现。
模拟数据:将真实表的前四列做修改,做数据分析,只需要导入数据,不需要生成,字段属性一列就不处理,这应该是一个外键,不在新建的表中体现。
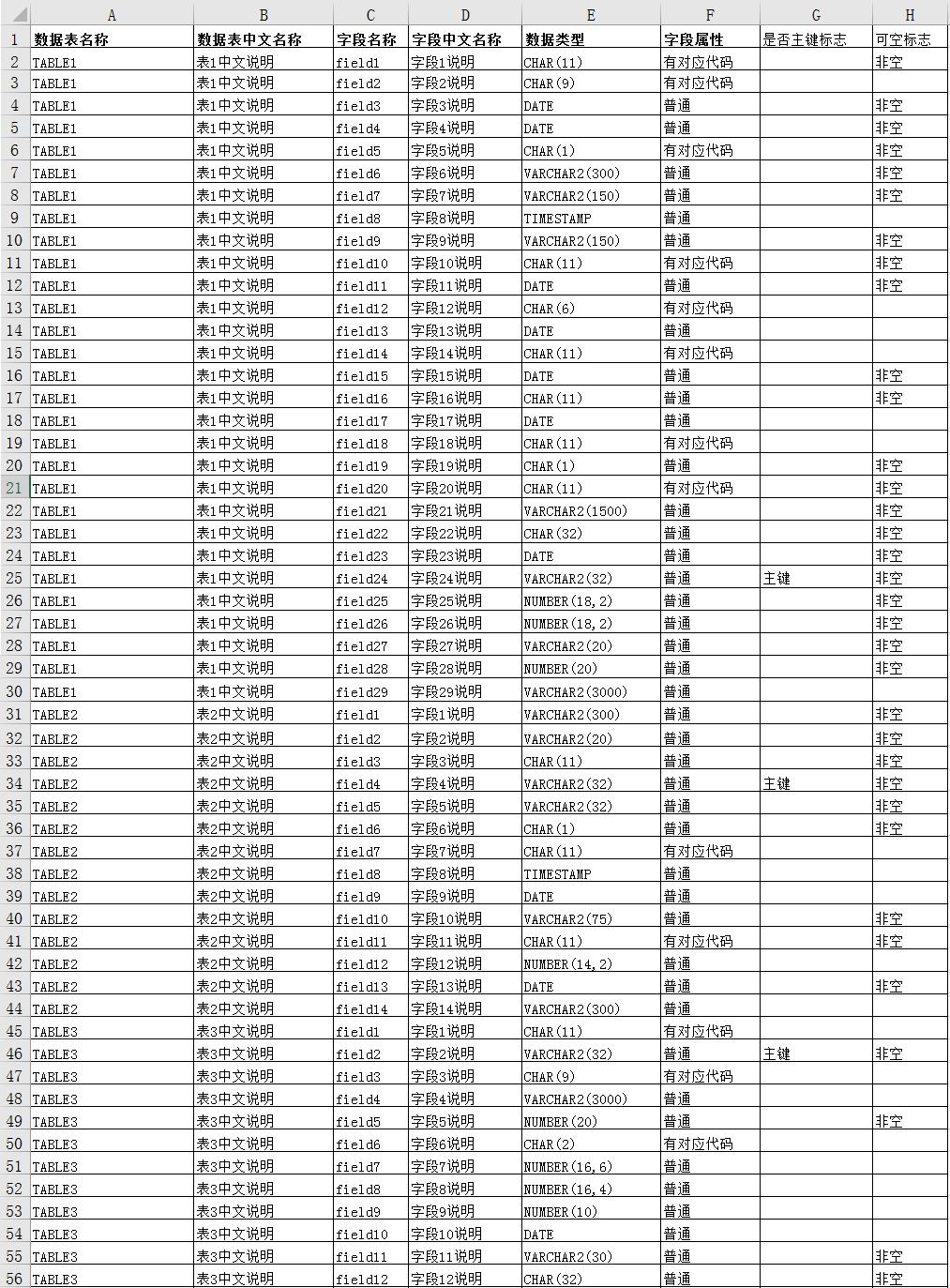
难点是怎么根据这个excel表形成一个完整准确的create table语句。
思路:要想直接通过Excel表来形成SQl语句,难度很大,我考虑很久没有好的实现方法,于是,先对Excel表进行处理,形成一个有利于SQl语句拼接的格式,我使用字典。
根据excel表,形成一个字典,字典的键就是(表名,表名说明),值是一个列表list,列表的元素是一个list。

在根据这个字典形成SQL语句。
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import openpyxl
import cx_Oracle
con = cx_Oracle.connect('ehr','ehr','192.168.71.132/orclzdy')
curs = con.cursor()
destfile = '测试表.xlsx'
wb = openpyxl.load_workbook(destfile)
ws = wb['Sheet2']
for row in ws.iter_rows(min_row=2,values_only=True): # 演示一个row的内容,不是必须的
print(row)
dict_table = {}
for row in ws.iter_rows(min_row=2,values_only=True): #从表的第2行开始取数据,一行为一个元组,每一列的值是这个元组的元素
key_tmp = tuple([row[0],row[1]]) #形成一个元组,做字典的键,如第一个表的键就是('TABLE1','表1中文说明')
if key_tmp in dict_table.keys():
dict_table[key_tmp].append([]) #如果这个键在dict_table字典中存在,说明不是表的第一个字段,
# 先在键值对的值,即[[],[]]...]形式中增加一个空列表,作为新字段的容器。
end_index = len(dict_table[key_tmp]) - 1 # 找到刚添加的空列表在外层列表的索引位置
dict_table[key_tmp][end_index].append(row[2]) # 添加字段名
dict_table[key_tmp][end_index].append(row[3]) # 添加字段说明
dict_table[key_tmp][end_index].append(row[4]) # 添加数据类型
if row[6] =='' or row == None:
dict_table[key_tmp][end_index].append('') # 如果excel第7列为空,添加‘’
else:
dict_table[key_tmp][end_index].append(' primary key') # 如果excel第7列不为空,即为主键,添加‘ primary key’
if row[7] =='' or row == None: # 同上,判断是否添加 ‘ not null',注意前面都有一个空格
dict_table[key_tmp][end_index].append('')
else:
dict_table[key_tmp][end_index].append(' not null')
continue # 处理完一个字段,继续循环下一个字段
dict_table[key_tmp] = [[row[2],row[3],row[4]],] # 如果key_tmp这个键在dict_table字典中不存在,那就是一个新表的第一个字段
# 直接在字典中添加这个键,同时要添加第一个字段的相关信息
if row[6] == '' or row == None:
dict_table[key_tmp][0].append('')
else:
dict_table[key_tmp][0].append(' primary key')
if row[7] == '' or row == None:
dict_table[key_tmp][0].append('')
else:
dict_table[key_tmp][0].append(' not null')
print(dict_table) # 看一下最后形成的字典,不是必须的
# 先查询一下当前数据库的表
curs.execute("select table_name from user_tables")
result = curs.fetchall()
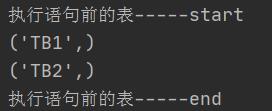
print("执行语句前的表-----start")
for row in result:
print(row)
print("执行语句前的表-----end")
# 下面遍历dict_table字典,拼接组成SQl语句,并执行
for k,v in dict_table.items():
sql = 'create table ' + k[0] + '('
i = 0
for vv in v:
i += 1
if i < len(v):
sql = sql + vv[0] + ' ' + vv[2] + vv[3] + vv[4] + ',' # 如果不是表的最后一个字段,则最后是一个逗号
else:
sql = sql + vv[0] + ' ' + vv[2] + vv[3] + vv[4] + ')' # 如果是表的最后一个字段,则最后是一个右括号
sql = sql + ' tablespace users' # 最后加上表空间
print(sql) #查看最后形成的SQL语句
curs.execute(sql) # 执行创建表的语句,在数据库中创建表
for k,v in dict_table.items():
sqlcomm_t = 'comment on table ' + k[0] + ' is ' + "'" + k[1] + "'" # 给表添加说明
print(sqlcomm_t)
curs.execute(sqlcomm_t)
for vv in v:
sqlcomm_f = 'comment on column ' + k[0] + '.' + vv[0] + ' is ' + "'" + vv[1] + "'"
print(sqlcomm_f)
curs.execute(sqlcomm_f)
curs.execute("select table_name from user_tables")
result = curs.fetchall()
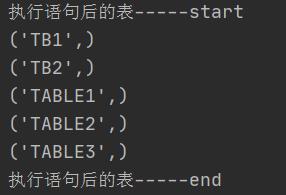
print("执行语句后的表-----start")
for row in result:
print(row)
print("执行语句后的表-----end")
wb.close()
curs.close()
con.close()最后的结果:
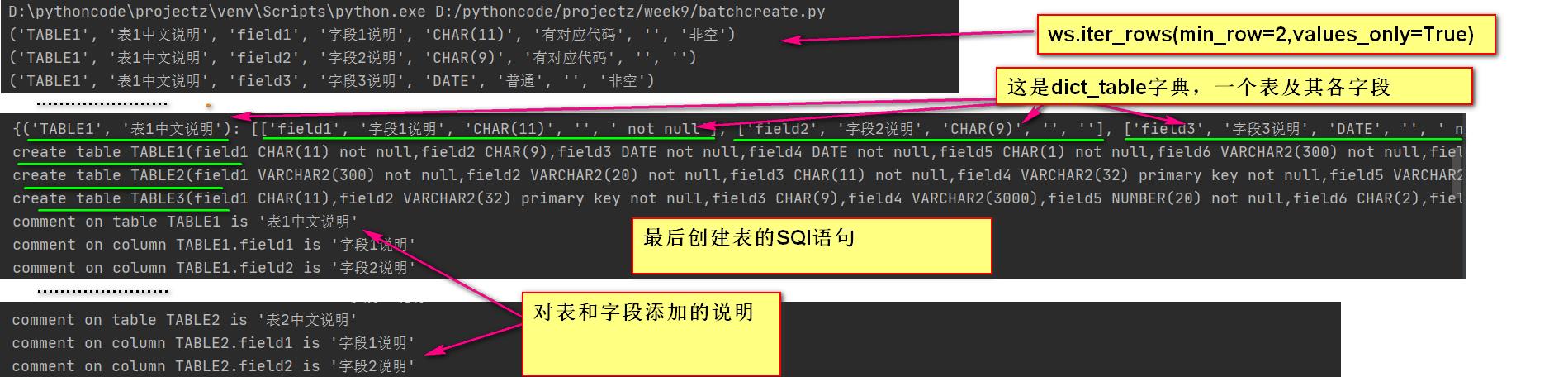
这个程序只能执行一次,第二次执行因为表已经存在会出错。可以添加一个循环,在建表前,先删除表。
以上是关于Python基础入门自学——20--excel与数据库联合使用——工作实践项目的主要内容,如果未能解决你的问题,请参考以下文章