编译原理构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 7.)(笔记)解释器 interpreter 解析器 parser 抽象语法树AST(代码片
Posted Dontla
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译原理构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 7.)(笔记)解释器 interpreter 解析器 parser 抽象语法树AST(代码片相关的知识,希望对你有一定的参考价值。
【编译原理】让我们来构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 7.)
正如我上次向您保证的那样,今天我将讨论我们将在本系列的其余部分中使用的中心数据结构之一,所以系好安全带,让我们开始吧。
到目前为止,我们将解释器(interpreter )和解析器(parser )代码混合在一起,一旦解析器识别出某种语言结构,如加法、减法、乘法或除法,解释器就会对表达式求值。这种解释器被称为语法导向解释器。它们通常对输入进行一次传递,适用于基本语言应用程序。为了分析更复杂的 Pascal 编程语言结构,我们需要构建一个中间表示( IR )。我们的解析器将负责构建一个 IR,我们的解释器将使用它来解释表示为IR的输入。
事实证明,树是非常适合IR 的数据结构。

让我们快速讨论一下树术语。
- 一个树是一种数据结构,由组织成一个层次中的一个或多个节点。
- 这棵树有一个根,它是顶部节点。
- 除了根节点之外的所有节点都有一个唯一的parent。
- 下图中标有
*的节点是父节点。标记为2和7 的节点是它的子节点;孩子们是从左到右排列的。
没有子 节点的节点称为叶节点。 - 具有一个或多个子节点且不是根的 节点称为内部节点。
- 子树也可以是完整的子树。在下图中,+节点的左子节点(标记为*) 是一个完整的子树,带有自己的子节点。
- 在计算机科学中,我们从顶部的根节点和向下生长的分支开始倒置绘制树。
- 这是表达式 2 * 7 + 3 的树,并附有说明:

我们将在整个系列中使用的IR称为抽象语法树( AST )。但在我们深入研究 AST 之前,让我们先简单地谈谈解析树。尽管我们不会在解释器和编译器中使用解析树,但它们可以通过可视化解析器的执行跟踪来帮助您了解解析器如何解释输入。我们还将它们与 AST 进行比较,以了解为什么 AST 比解析树更适合用于中间表示。
那么,什么是解析树?一个解析树(有时称为具体语法树)是表示根据我们的语法定义语言结构的句法结构树。它基本上显示了您的解析器如何识别语言结构,或者换句话说,它显示了您的语法的起始符号如何派生出编程语言中的某个字符串。
解析器的调用堆栈隐式地表示一个解析树,它会在您的解析器尝试识别特定语言结构时自动构建在内存中。
让我们看一下表达式 2 * 7 + 3 的解析树:

在上图中,您可以看到:(expr加减 -> term乘除 -> factor数)
- 解析树记录了解析器用于识别输入的一系列规则。
- 解析树的根用文法开始符号标记。
- 每个内部节点代表一个非终结符,即它代表一个文法规则应用,如我们的例子中的expr、term或factor。
- 每个叶节点代表一个标记。
正如我已经提到的,我们不会手动构建解析器树并将它们用于我们的解释器,但是解析树可以通过可视化解析器调用序列来帮助您理解解析器如何解释输入。
您可以通过试用一个名为genptdot.py的小实用程序来了解不同算术表达式的解析树的外观,我很快编写了该实用程序来帮助您将它们可视化。要使用该实用程序,您首先需要安装Graphviz包,在运行以下命令后,您可以打开生成的图像文件 parsetree.png 并查看作为命令行参数传递的表达式的解析树:(用不了不知咋回事,导不了包)

$ python genptdot.py "14 + 2 * 3 - 6 / 2" > \\
parsetree.dot && dot -Tpng -o parsetree.png parsetree.dot
这是为表达式 14 + 2 * 3 - 6 / 2 生成的图像 parsetree.png:

通过向它传递不同的算术表达式来稍微玩一下该实用程序,并查看特定表达式的解析树是什么样的。
现在,让我们谈谈抽象语法树( AST )。这是我们将在本系列的其余部分大量使用的中间表示( IR )。它是我们解释器和未来编译器项目的核心数据结构之一。
让我们通过查看表达式 2 * 7 + 3的AST和解析树来开始我们的讨论:

从上图可以看出,AST在变小的同时捕捉到了输入的本质。
以下是 AST 和解析树之间的主要区别:
- AST 使用操作符/操作作为根节点和内部节点,并使用操作数作为它们的子节点。
- 与解析树不同,AST 不使用内部节点来表示语法规则。
- AST 并不代表真实语法中的每一个细节(这就是为什么它们被称为abstract)——例如,没有规则节点和括号。
- 与相同语言构造的解析树相比,AST 是密集的。
那么,什么是抽象语法树呢?一个抽象语法树(AST)是表示一个语言结构,其中每个内部节点和根节点表示操作者的抽象句法结构的树,并且节点的子节点表示操作者的操作数。
我已经提到 AST 比解析树更紧凑。让我们看一下表达式 7 + ((2 + 3))的AST和解析树。可以看到下面的AST比解析树小很多,但还是抓住了输入的本质:

到目前为止一切顺利,但是您如何在AST 中编码运算符优先级?为了在AST 中对运算符优先级进行编码,即表示“X 发生在 Y 之前”,您只需将 X 在树中放在比 Y 低的位置。您已经在前面的图片中看到了这一点。
让我们再看一些例子。
在下图中的左侧,您可以看到表达式 2 * 7 + 3的AST。让我们通过将 7 + 3 放在括号内来更改优先级。您可以在右侧看到修改后的表达式 2 * (7 + 3)的AST是什么样的:

这是表达式 1 + 2 + 3 + 4 + 5的AST:
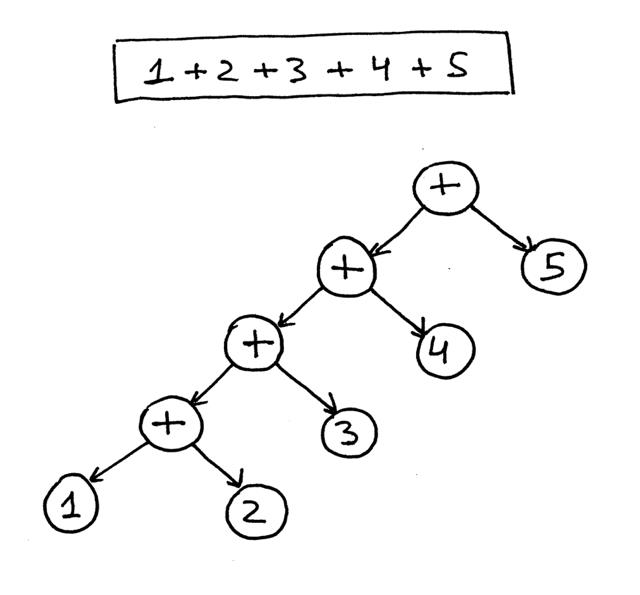
从上面的图片中,您可以看到优先级较高的运算符在树中的位置较低。
好的,让我们编写一些代码来实现不同的AST节点类型并修改我们的解析器以生成由这些节点组成的AST树。
首先,我们将创建一个名为AST的基节点类,其他类将从该类继承:
class AST(object):
pass
实际上没有多少。回想一下,AST 表示操作符-操作数模型。到目前为止,我们有四个运算符和整数操作数。运算符是加法、减法、乘法和除法。我们可以创建一个单独的类来表示每个运算符,例如 AddNode、SubNode、MulNode 和 DivNode,但是我们将只用一个BinOp类来表示所有四个二元运算符(二元运算符是对两个运算符进行运算的运算符)操作数):
class BinOp(AST):
def __init__(self, left, op, right):
self.left = left
self.token = self.op = op
self.right = right
构造函数的参数是left、op和right,其中left和right 分别指向左操作数的节点和右操作数的节点。Op持有运算符本身的标记: Token( PLUS , ‘+’) 表示加号运算符, Token( MINUS , ‘-’) 表示减号运算符,依此类推。
为了在我们的AST 中表示整数,我们将定义一个Num类,该类将保存一个INTEGER标记和标记的值:
class Num(AST):
def __init__(self, token):
self.token = token
self.value = token.value
正如您所注意到的,所有节点都存储用于创建节点的标记。这主要是为了方便,将来会派上用场。
回忆一下表达式 2 * 7 + 3的AST。我们将在该表达式的代码中手动创建它:
>>> from spi import Token, MUL, PLUS, INTEGER, Num, BinOp
>>>
>>> mul_token = Token(MUL, '*')
>>> plus_token = Token(PLUS, '+')
>>> mul_node = BinOp(
... left=Num(Token(INTEGER, 2)),
... op=mul_token,
... right=Num(Token(INTEGER, 7))
... )
>>> add_node = BinOp(
... left=mul_node,
... op=plus_token,
... right=Num(Token(INTEGER, 3))
... )
以下是定义了我们的新节点类后AST 的外观。下图也沿用了上面的手工构建过程:
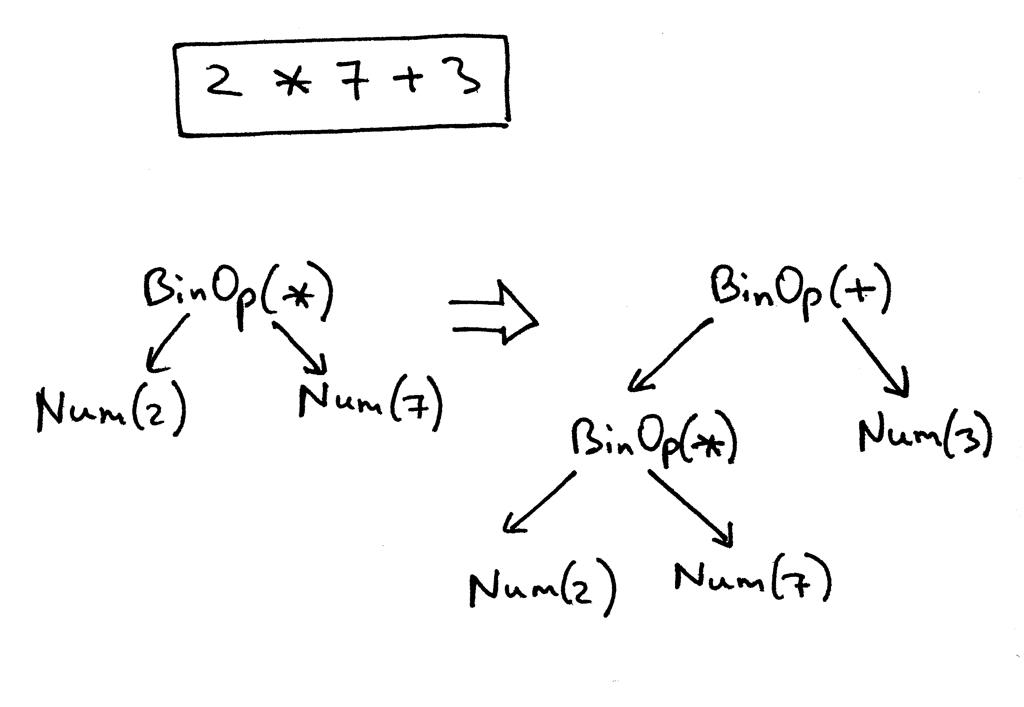
这是我们修改后的解析器代码,它构建并返回一个AST作为识别输入(算术表达式)的结果:
class AST(object):
pass
class BinOp(AST):
def __init__(self, left, op, right):
self.left = left
self.token = self.op = op
self.right = right
class Num(AST):
def __init__(self, token):
self.token = token
self.value = token.value
class Parser(object):
def __init__(self, lexer):
self.lexer = lexer
# set current token to the first token taken from the input
self.current_token = self.lexer.get_next_token()
def error(self):
raise Exception('Invalid syntax')
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.lexer.get_next_token()
else:
self.error()
def factor(self):
"""factor : INTEGER | LPAREN expr RPAREN"""
token = self.current_token
if token.type == INTEGER:
self.eat(INTEGER)
return Num(token)
elif token.type == LPAREN:
self.eat(LPAREN)
node = self.expr()
self.eat(RPAREN)
return node
def term(self):
"""term : factor ((MUL | DIV) factor)*"""
node = self.factor()
while self.current_token.type in (MUL, DIV):
token = self.current_token
if token.type == MUL:
self.eat(MUL)
elif token.type == DIV:
self.eat(DIV)
node = BinOp(left=node, op=token, right=self.factor())
return node
def expr(self):
"""
expr : term ((PLUS | MINUS) term)*
term : factor ((MUL | DIV) factor)*
factor : INTEGER | LPAREN expr RPAREN
"""
node = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
elif token.type == MINUS:
self.eat(MINUS)
node = BinOp(left=node, op=token, right=self.term())
return node
def parse(self):
return self.expr()
让我们回顾一下一些算术表达式的AST构造过程。
如果你看一下解析器代码上面你可以看到它的方式构建了一个节点AST是每个BinOp节点采用的当前值节点变量作为它的左子和呼叫到一个结果项或因素作为其右孩子,所以它有效地将节点向左下推,下面的表达式 1 +2 + 3 + 4 + 5 的树就是一个很好的例子。这是解析器如何逐渐为表达式 1 + 2 + 3 + 4 + 5构建AST的直观表示:

为了帮助您可视化不同算术表达式的 AST,我编写了一个小实用程序,它将算术表达式作为其第一个参数,并生成一个DOT文件,然后由dot实用程序处理该文件以实际为您绘制AST(dot是运行dot命令需要安装的Graphviz包)。这是一个命令和为表达式 7 + 3 * (10 / (12 / (3 + 1) - 1))生成的AST图像:
$ python genastdot.py "7 + 3 * (10 / (12 / (3 + 1) - 1))" > \\
ast.dot && dot -Tpng -o ast.png ast.dot

编写一些算术表达式,手动绘制表达式的 AST,然后通过使用genastdot.py工具为相同的表达式生成AST图像来验证它们是值得的。这将帮助您更好地理解解析器如何为不同的算术表达式构造 AST。
好的,这是表达式 2 * 7 + 3的AST:
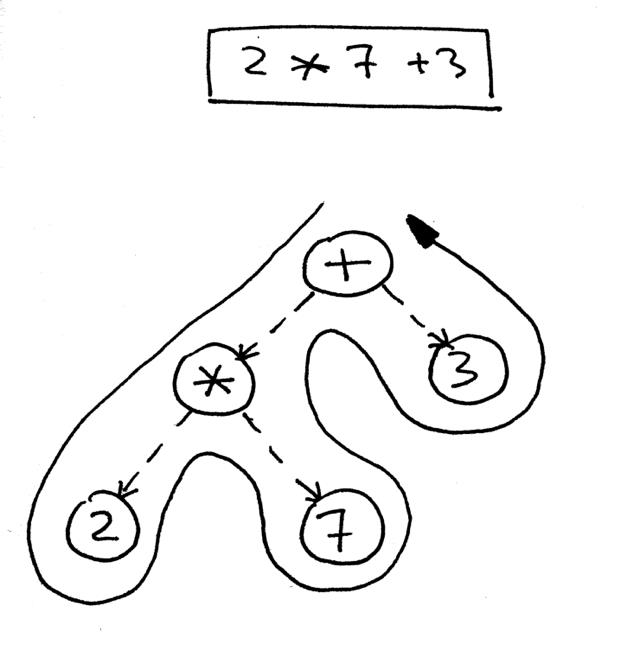
您如何遍历树以正确评估该树表示的表达式?您可以通过使用后序遍历(深度优先遍历的一种特殊情况)来实现这一点,它从根节点开始并从左到右递归访问每个节点的子节点。后序遍历尽可能快地访问远离根的节点。
这是后序遍历的伪代码,其中<>是BinOp节点的加法、减法、乘法或除法等操作的占位符,或者是返回Num 节点的整数值等更简单的操作:

我们要为解释器使用后序遍历的原因是,首先,我们需要评估树中较低的内部节点,因为它们代表具有更高优先级的运算符;其次,我们需要在应用运算符之前评估运算符的操作数到那些操作数。在下图中,您可以看到,通过后序遍历,我们首先评估表达式 2 * 7,然后才评估 14 + 3,这给出了正确的结果,17:

为了完整起见,我将提到深度优先遍历的三种类型:前序遍历、中序遍历和后序遍历。遍历方法的名字来自你在访问代码中放置动作的地方:

有时您可能必须在所有这些点(前序、中序和后序)执行某些操作。您将在本文的源代码存储库中看到一些示例。
好的,让我们编写一些代码来访问和解释由我们的解析器构建的抽象语法树,好吗?
这是实现访问者模式的源代码:
class NodeVisitor(object):
def visit(self, node):
method_name = 'visit_' + type(node).__name__
visitor = getattr(self, method_name, self.generic_visit)
return visitor(node)
def generic_visit(self, node):
raise Exception('No visit_{} method'.format(type(node).__name__))
这是我们的Interpreter类的源代码,它继承自NodeVisitor类并实现了不同的方法,这些方法的形式为visit_NodeType,其中NodeType被替换为节点的类名,如BinOp、Num等:
class Interpreter(NodeVisitor):
def __init__(self, parser):
self.parser = parser
def visit_BinOp(self, node):
if node.op.type == PLUS:
return self.visit(node.left) + self.visit(node.right)
elif node.op.type == MINUS:
return self.visit(node.left) - self.visit(node.right)
elif node.op.type == MUL:
return self.visit(node.left) * self.visit(node.right)
elif node.op.type == DIV:
return self.visit(node.left) / self.visit(node.right)
def visit_Num(self, node):
return node.value
这段代码有两个有趣的地方值得一提:首先,操作AST节点的访问者代码与AST节点本身是解耦的。您可以看到任何AST节点类(BinOp 和 Num)都没有提供任何代码来操作存储在这些节点中的数据。该逻辑封装在实现NodeVisitor 类的Interpreter类中。
其次,而不是像这样在 NodeVisitor 的访问方法中使用一个巨大的if语句:
def visit(node):
node_type = type(node).__name__
if node_type == 'BinOp':
return self.visit_BinOp(node)
elif node_type == 'Num':
return self.visit_Num(node)
elif ...
# ...
或者像这样:
def visit(node):
if isinstance(node, BinOp):
return self.visit_BinOp(node)
elif isinstance(node, Num):
return self.visit_Num(node)
elif ...
NodeVisitor 的访问方法非常通用,它根据传递给它的节点类型将调用分派到适当的方法。正如我之前提到的,为了使用它,我们的解释器从NodeVisitor类继承并实现了必要的方法。所以如果传递给visit方法的节点类型是BinOp,那么visit方法会将调用分派到visit_BinOp方法;如果节点类型是Num,那么visit方法会将调用分派到visit_Num方法, 等等。
花一些时间研究这种方法(标准 Python 模块ast使用相同的节点遍历机制),因为将来我们将使用许多新的visit_NodeType方法扩展我们的解释器。
该generic_visit方法是抛出一个异常,表明它遇到的实现类没有相应的节点的后备visit_NodeType方法。
现在,让我们为表达式 2 * 7 + 3手动构建一个AST,并将其传递给我们的解释器,以查看访问方法的作用,以评估表达式。以下是从 Python shell 执行此操作的方法:
>>> from spi import Token, MUL, PLUS, INTEGER, Num, BinOp
>>>
>>> mul_token = Token(MUL, '*')
>>> plus_token = Token(PLUS, '+')
>>> mul_node = BinOp(
... left=Num(Token(INTEGER, 2)),
... op=mul_token,
... right=Num(Token(INTEGER, 7))
... )
>>> add_node = BinOp(
... left=mul_node,
... op=plus_token,
... right=Num(Token(INTEGER, 3))
... )
>>> from spi import Interpreter
>>> inter = Interpreter(None)
>>> inter.visit(add_node)
17
如您所见,我将表达式树的根传递给了访问方法,并通过将调用分派到解释器类的正确方法(visit_BinOp和visit_Num)并生成结果来触发树的遍历。
好的,为了您的方便,这是我们新解释器的完整代码:
python代码
运行结果:
""" SPI - Simple Pascal Interpreter """
###############################################################################
# #
# LEXER #
# #
###############################################################################
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, MINUS, MUL, DIV, LPAREN, RPAREN, EOF = (
'INTEGER', 'PLUS', 'MINUS', 'MUL', 'DIV', '(', ')', 'EOF'
)
class Token(object):
def __init__(self, type, value):
self.type = type
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS, '+')
Token(MUL, '*')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Lexer(object):
def __init__(self, text):
# client string input, e.g. "4 + 2 * 3 - 6 / 2"
self.text = text
# self.pos is an index into self.text
self.pos = 0
self.current_char = self.text[self.pos]
def error(self):
raise Exception('Invalid character')
def advance(self):
"""Advance the `pos` pointer and set the `current_char` variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
if self.current_char == '*':
self.advance()
return Token(MUL, '*')
if self.current_char == '/':
self.advance()
return Token(DIV, '/')
if self.current_char == '(':
self.advance()
return Token(LPAREN, '(')
if self.current_char == ')':
self.advance()
return Token(RPAREN, ')')
self.error()
return Token(EOF, None)
###############################################################################
# #
# PARSER #
# #
###############################################################################
class AST