hadoop常用的脚本
Posted Summer龙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop常用的脚本相关的知识,希望对你有一定的参考价值。
(1)jpsall 该脚本是用来显示集群的所有java进程状态
#!/bin/bash
#该脚本是用来显示集群的所有java进程状态
list="master node1 node2"
# 注意替换你自己的节点名称!!!!!!!!!
echo "显示集群的所有java进程状态"
for node in $list
do
echo "##### "$node"jps #####"
ssh $node $JAVA_HOME'/bin/jps'
done
echo "#####执行结束#####"
注意替换你自己节点名称
(2)批量启动/关闭集群
#!/bin/bash
if [ $# -lt 1 ]
then
echo "没有参数输入。。。。。。。"
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "参数为 [start|stop]"
;;
esac
注意替换自己路径,想要多加几个命令按照原来格式添加即可。
(3)xsync脚本:用于集群文件分发的脚本
注意:在使用该脚本时,必须保证该机器已经安装 rsync
可以使用 yum install rsync进行安装
#!/bin/sh
# 1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 主机名序列
hostlist="master node1 node2"
#3 获取文件名称
p1=$1 #$1获取第一个输入的数据
fname=`basename $p1` #basename:获取输入的数据文件自身的名称
echo fname=$fname
#4 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd` #dirname:获取文件的目录名:
echo pdir=$pdir
#5 获取当前用户名称
user=`whoami`
#6 循环分发文件
for host in $hostlist
do
echo ---------------------- $host ----------------
rsync -rvl $pdir/$fname $user@$host:$pdir
done
注意:
要修改你自己的主机名序列,在序号2
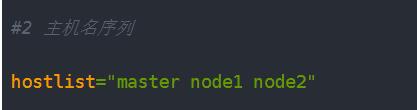
这个选项,修改成自己的主机名序列!!!!!
(4)zookeeper启动/关闭/查看状态脚本
#!/bin/bash
#该脚本是用来对zookeeper脚本进行启动/关闭/查看状态
if [ $# -lt 1 ]
then
echo "没有参数输入。。。。。。。"
exit ;
fi
zkpath='/opt/share/zookeeper-3.4.10' #配置zookeeper的安装目录
hostlist="master node1 node2" # 配置主机名队列
case $1 in
"start")
echo " =================== 启动 zk 集群 ==================="
for host in $hostlist
do
ssh $host $zkpath'/bin/zkServer.sh start'
echo $host "zookeeper已经启动"
done
;;
"stop")
echo " ===================关闭 zk 集群 ==================="
for host in $hostlist
do
ssh $host $zkpath'/bin/zkServer.sh stop'
echo $host "zookeeper已经关闭"
done
;;
"status")
echo " =================== zk 集群状态 ==================="
for host in $hostlist
do
ssh $host $zkpath'/bin/zkServer.sh status'
done
;;
*)
echo "参数为 [start|stop|status]"
;;
esac
注意:
该脚本要修改自己的zookeeper的安装目录
以及自己集群的主机名队列。

(5)上面的脚本都必须要执行的操作
#创建文件
touch xsync
#附权限
chmod +x xsync
#移动到 /usr/local/bin/ 下面
mv xsync /usr/local/bin/
以上是关于hadoop常用的脚本的主要内容,如果未能解决你的问题,请参考以下文章