Python网络爬虫与信息提取—requests库入门
Posted 清风竹影的竹影
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python网络爬虫与信息提取—requests库入门相关的知识,希望对你有一定的参考价值。
requests的学习笔记
requests库自动爬取html页面,自动网络请求提交
此博客为中国大学MOOC北京理工大学《Python网络爬虫与信息提取》的学习笔记
requests库的安装
requests库是Python的第三方库,是目前公认的,爬取网页最好的第三方库。关于requests库的更多信息,可以在www.python-requests.org网站上获得。
安装方法:用管理员权限启动command控制台,输入 pip install requests ,按下回车;
验证方法:
启动IDLE
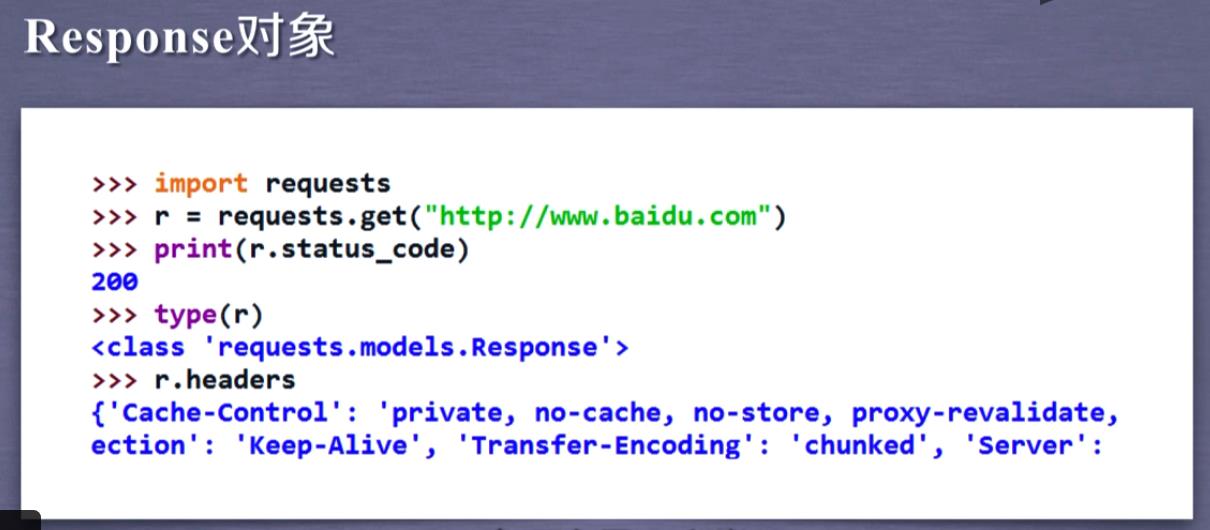
import requests
r = requests.get("http://www.baidu.com")
r.status_code
运行显示200即为成功
requests库的方法
requests库共7个主要方法

requests库的request()方法
requests.request(method,url,**kwargs)
1.method:请求方式,对应get/put/post等7种(以上图片上或http所对应的请求功能+options)
2. url: 拟获取页面的url链接
3. **kwargs:控制访问参数,均为可选项(13个)
①params:字典或字节序列,作为参数增加到url中(对url进行修改)
kv ={'key1':'value1','key2':'value2'}
r=requests.request("GET","http://python123.io/ws",params=kv)
print(r.url)
②data:字典,字节序列或文件对象,作为request的内容 向服务器提供或提交资源时使用
r=requests.request("POST","http://python123.io/ws",data=kv)
body="主体内容"
r=requests.request("POST","http://python123.io/ws",data=kv)
③json:JSON格式数据,作为request的内容 向服务器提供或提交资源时使用
kv ={'key1':'value1'}
r=requests.request('POST','http://python123.io/ws',json=kv)
④headers:字典,HTTP定制头
hd={'user-agent':'Chrome/10'}
r=requests.request('POST','http://python123.io/ws',headers=hd)
⑤cookies:字典或CookieJar,request中的cookie
⑥auth:元祖,支持HTTP认证功能
⑦files:字典类型,传输文件
fs={'file':open('data.xis','rb')}
r=requests.request('POST','http://python123.io/ws',files=fs)
⑧timeout:设定超时时间,以秒为单位
r=requests.request(“GET”,‘http://www.baidu.com’,timeout=10)
⑨proxies:字典类型,设定访问代理服务器,可以增加登录认证(隐藏爬取地址)
pxs={'http':'http://user:pass@10.10.10.1:1234',
'https':'https://10.10.10.1:1234'}
r=requests.request("GET",'http://www.baidu.com',proxies=pxs)
⑩allow_redirects:True/False,默认为True,重定向开关
⑾.stream:True/False,默认为True,获取内容立即下载开关
⑿.verify:True/False,默认为True,认证SSL证书开关
⒀.cert:本地SSL证书路径
requests库的get()方法
(实际以requests库的方法来封装)
r = requests.get(url)
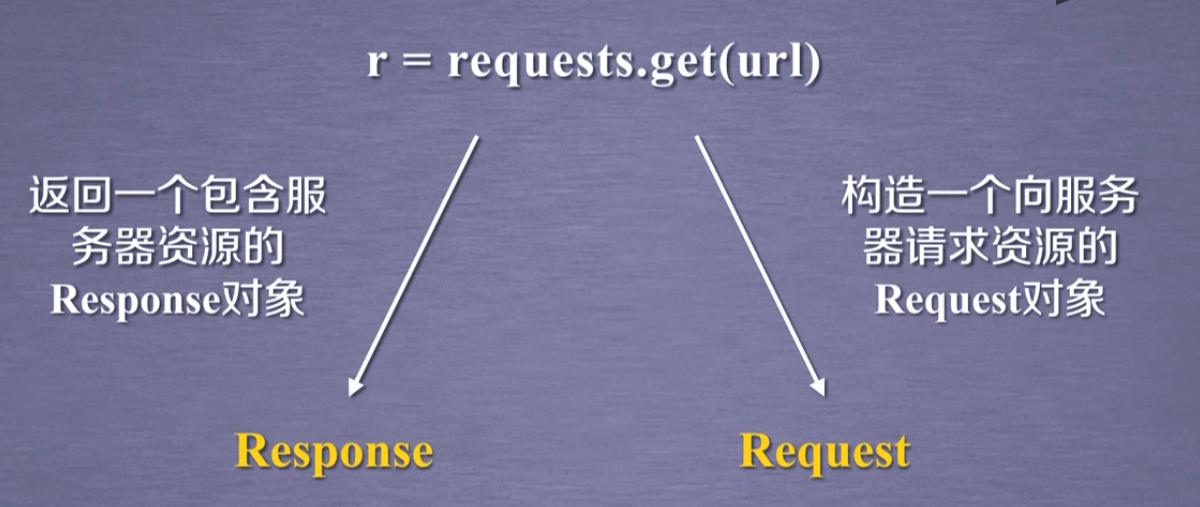
完整使用方法有三个参数
requests.get(url,params=None,**kwargs)
1.url: 拟获取页面的url链接
2.params:url中额外参数,字典或者字节流格式,可选
3.**kwargs:控制访问参数,均为可选项(13个)
Response对象包含服务器返回的所有信息,同时包含了想服务器请求的request信息
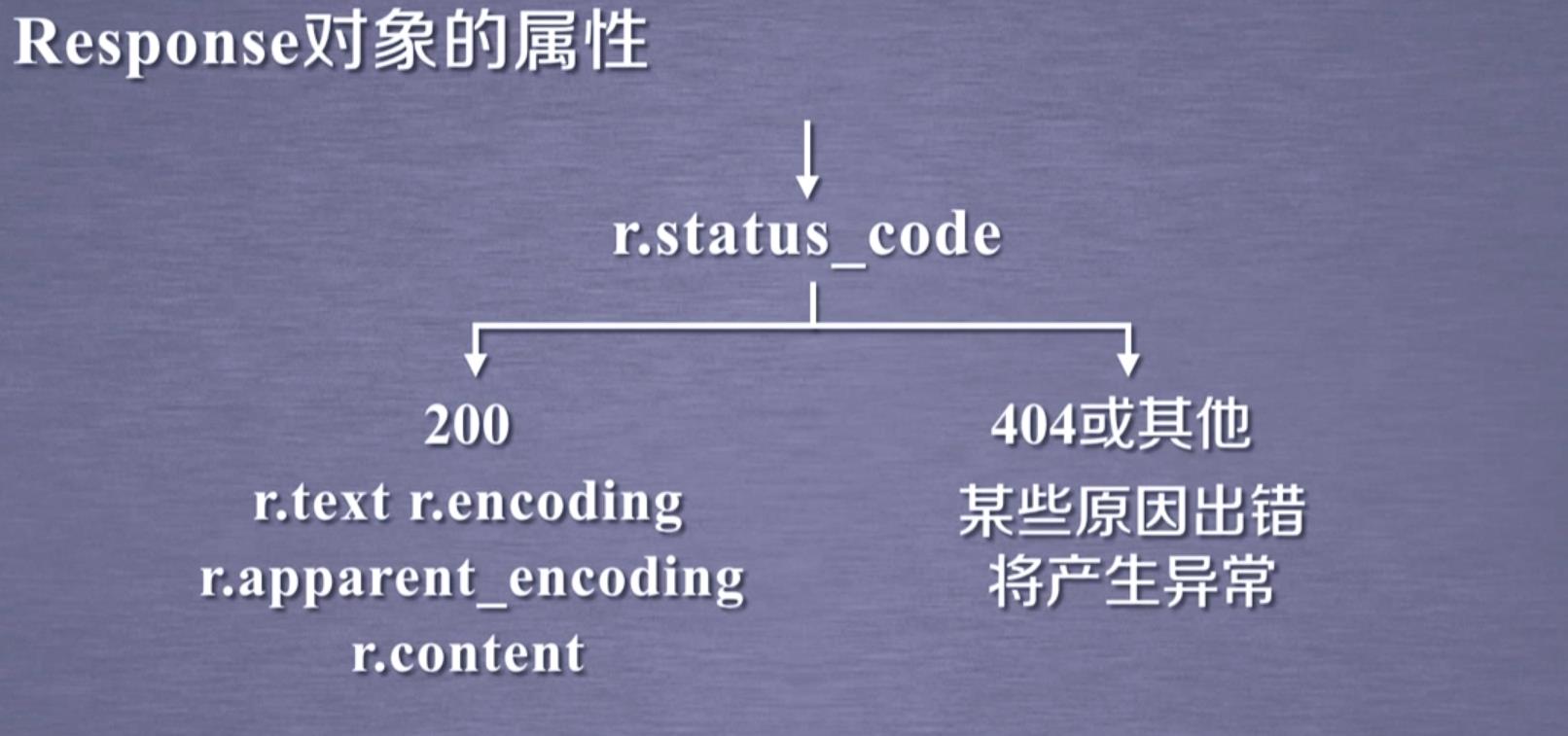
Response对象的属性

这五个属性为访问网页最必要的属性,务必牢记!
使用get方法获取网上资源的流程:
requests.head(url,**kwargs)
request.post(url,data=None,json=None,**kwargs)
data:字典、字节序列或文件,request的内容
json:JSON格式的数据,request的内容
requests.put(url,data=None,**kwargs)
requests.patch(url,data=None,**kwargs)
requests.delete(url,data=None,**kwargs)
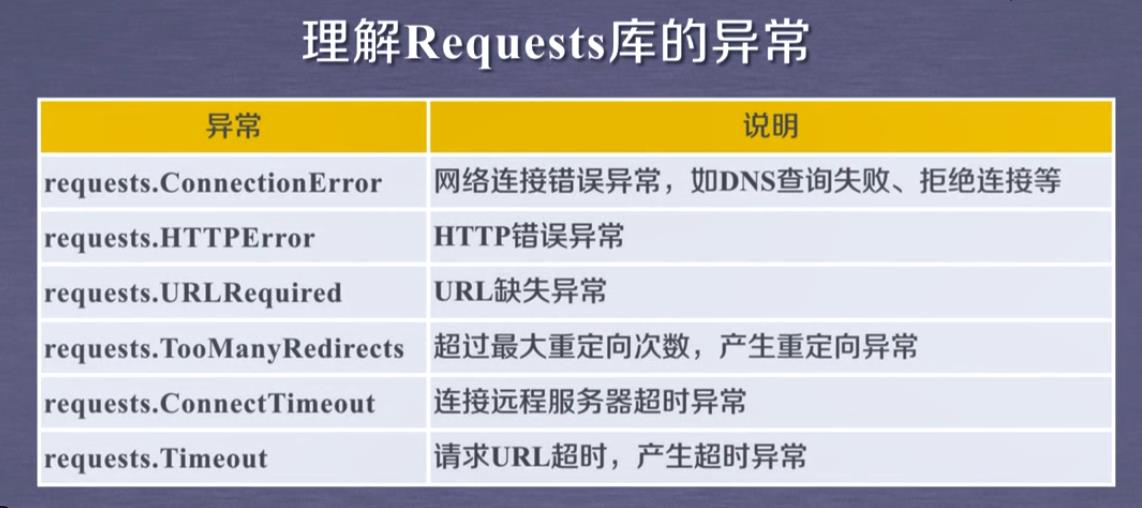
Requests库的异常
爬取网页的通用代码框架
import requests
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()#如果状态不是200,引发HTTPError的异常
r.encoding = r.apparent_encoding
return r.text
except:
return"产生异常"
if __name__=="__main__":
url = "http://www.baidu.com"
print(getHTMLText(url)
以上是关于Python网络爬虫与信息提取—requests库入门的主要内容,如果未能解决你的问题,请参考以下文章