深度学习为什么选择Pytorch?史上最详细Pytorch入门教程
Posted Yunlord
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习为什么选择Pytorch?史上最详细Pytorch入门教程相关的知识,希望对你有一定的参考价值。
目录
前言
工欲善其事,必先利其器。近几年深度学习飞速发展让人瞠目结舌,但它的崛起背后离不开最大的功臣——深度学习框架。如果没有这些深度学习框架,深度学习绝对不会像现在一样“平民化”,很多人可能陷入在茫茫的数学深渊中。有了便捷实用的深度学习框架,我们才可以把所有精力花在如何设计模型本身上,而不用再去关注模型优化的细节,所有的事情均由框架来负责,极大降低了深度学习使用的门槛。这也是为什么现在只要经过短期有效训练的开发工程师也可以在使用深度学习模型身上得心应手的主要原因。
一、 Pytorch介绍
1.常见的深度学习框架
深度学习框架的发展也经历了超过10年的时间,从早期比较流行的theano到现在比较火爆的框架如Pytorch, Tensorflow,经历了几个阶段的发展和迭代。

图中展示了几个比较有代表性的深度学习框架,是不同时代的产物。比如图里的Caffe来源于伯克利的一位博士生,框架本身效率高,但需要编写比较繁琐的配置文件。在配置文件中会设置网络的层次、每一层的参数等所有细节,目前在工业界仍然是一个比较受欢迎的深度学习框架。另外,Keras的使用也比较广泛。它一开始是建立在Tensorflow之上的,并封装了很多的模块,让使用者可以更低门槛地去设计深度学习模型,目前也有大量的使用者。但缺点是,由于做了进一步的封装,如果想做一些改动,灵活性上相比Tensorflow要差一些。
从这些框架中,如果让我们选择目前最火爆的,大多数人可能会毫无犹豫地选出Pytorch和TensorFlow。究其原因,还是因为它们的高效、灵活性以及低门槛的使用。Tensorflow作为Google公司一个重要的产品,在性能方面的表现也是可圈可点的。另一方面,Pytorch作为新的框架,这几年展现出了超高的人气和增长,主要源于它的低门槛且特别容易上手。
2.Pytorch框架的崛起
本节,我们主要比较TensorFlow与Pytorch两个框架的发展历史以及趋势,分别从搜索热度、学术界的欢迎度等角度来剖析。之所以选择这两个框架,一方面的原因在于确实这俩是目前最火爆的框架,另外一方面的原因是也比较适合刚步入AI领域的人士去接触和学习。
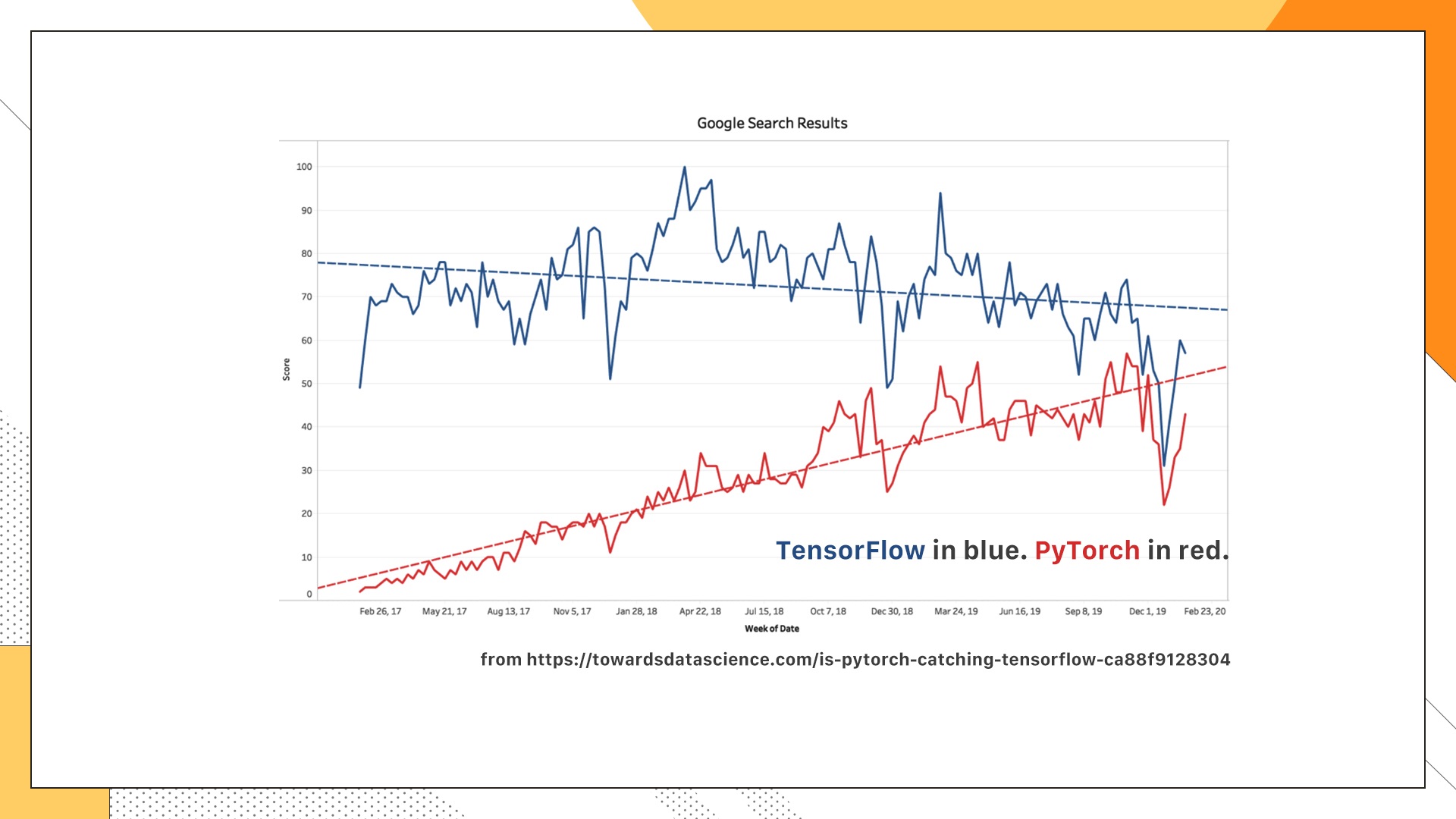
图里展示的是Google搜索引擎上的搜索热度,代表有多少人去搜索这两个框架。从图中可以很清楚地看到,17年的时候TensorFlow仍然占据着完全主导性的地位,但随着时间的推移,Pytorch的增长越来越快,到了20年初基本上逼近了Tensorflow的热度,而且这种增长趋势仍在持续。
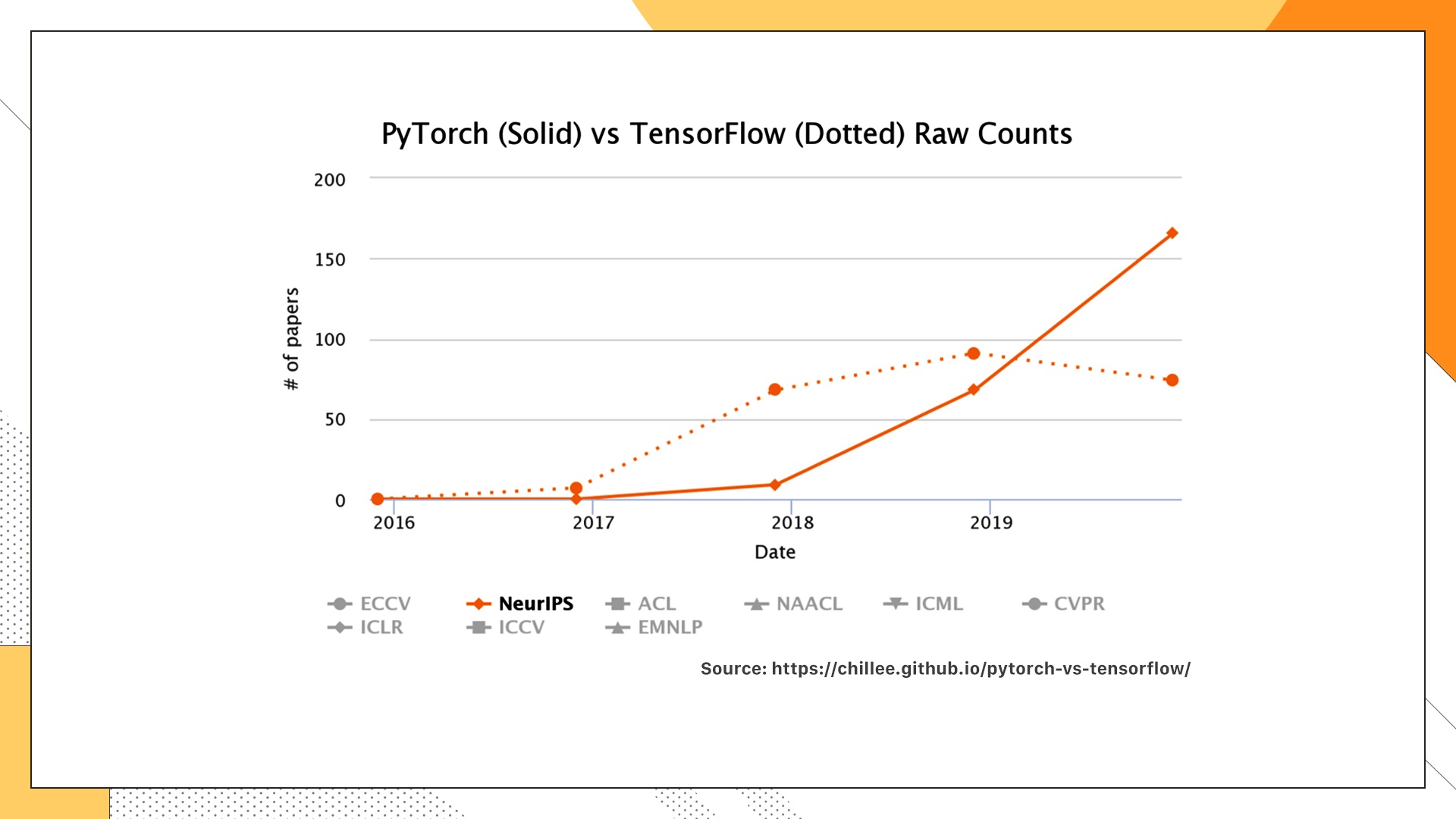
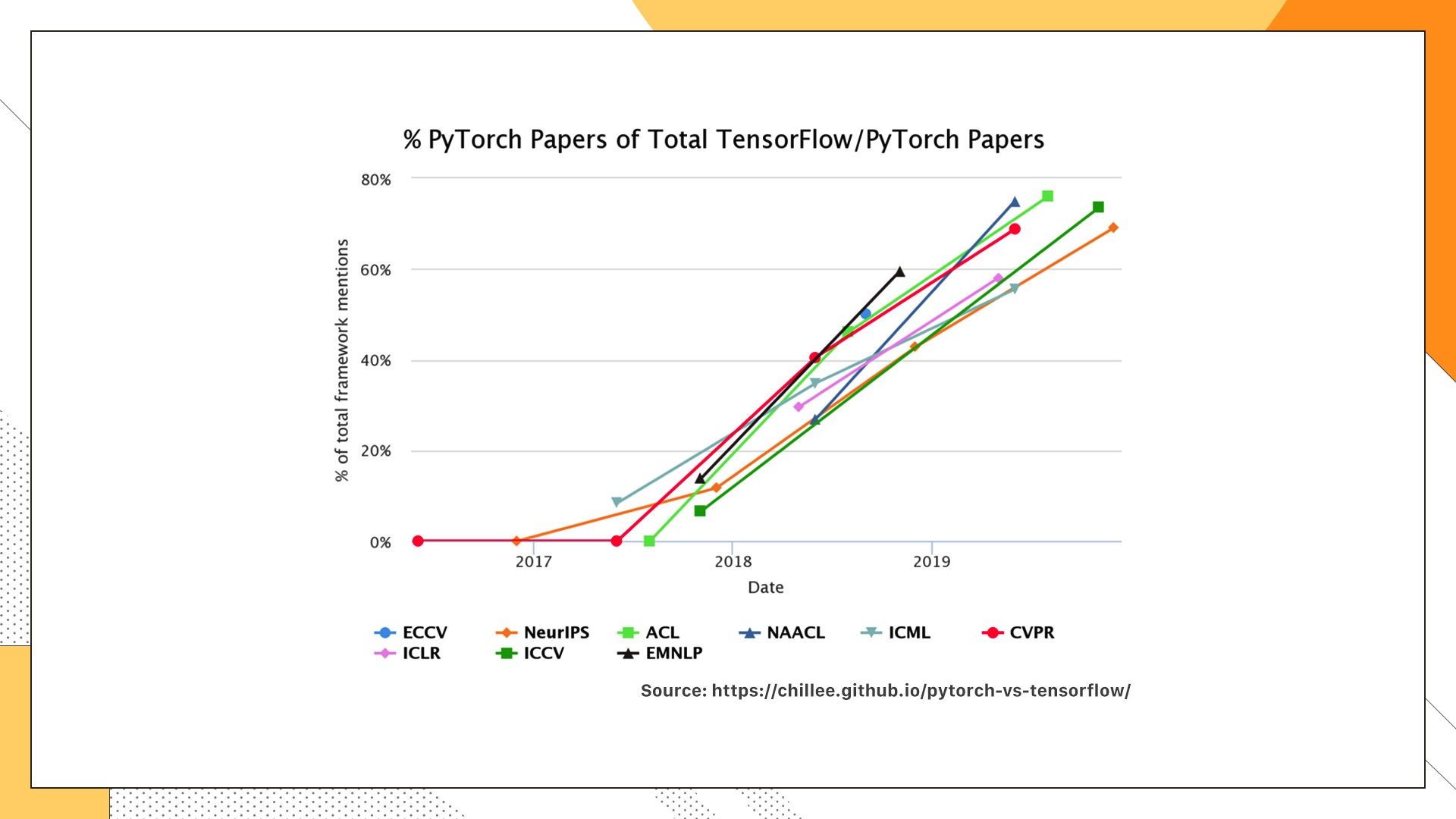
以上两幅图表示的是Pytorch和TensorFlow在学术界的使用情况,分别算出了每一年顶会中有多少篇文章的实验用这两个工具来做的。很容易发现,在学术界里Pytorch的优势更加明显,显示出强势的增长。那为什么会出现这种趋势呢? 主要还是Pytorch用起来简单,而且效率也不差。对于之前没有接触过深度学习框架的人,Pytorch无疑是首选,特别适合入门。
3.Pytorch与Tensorflow多方位比较
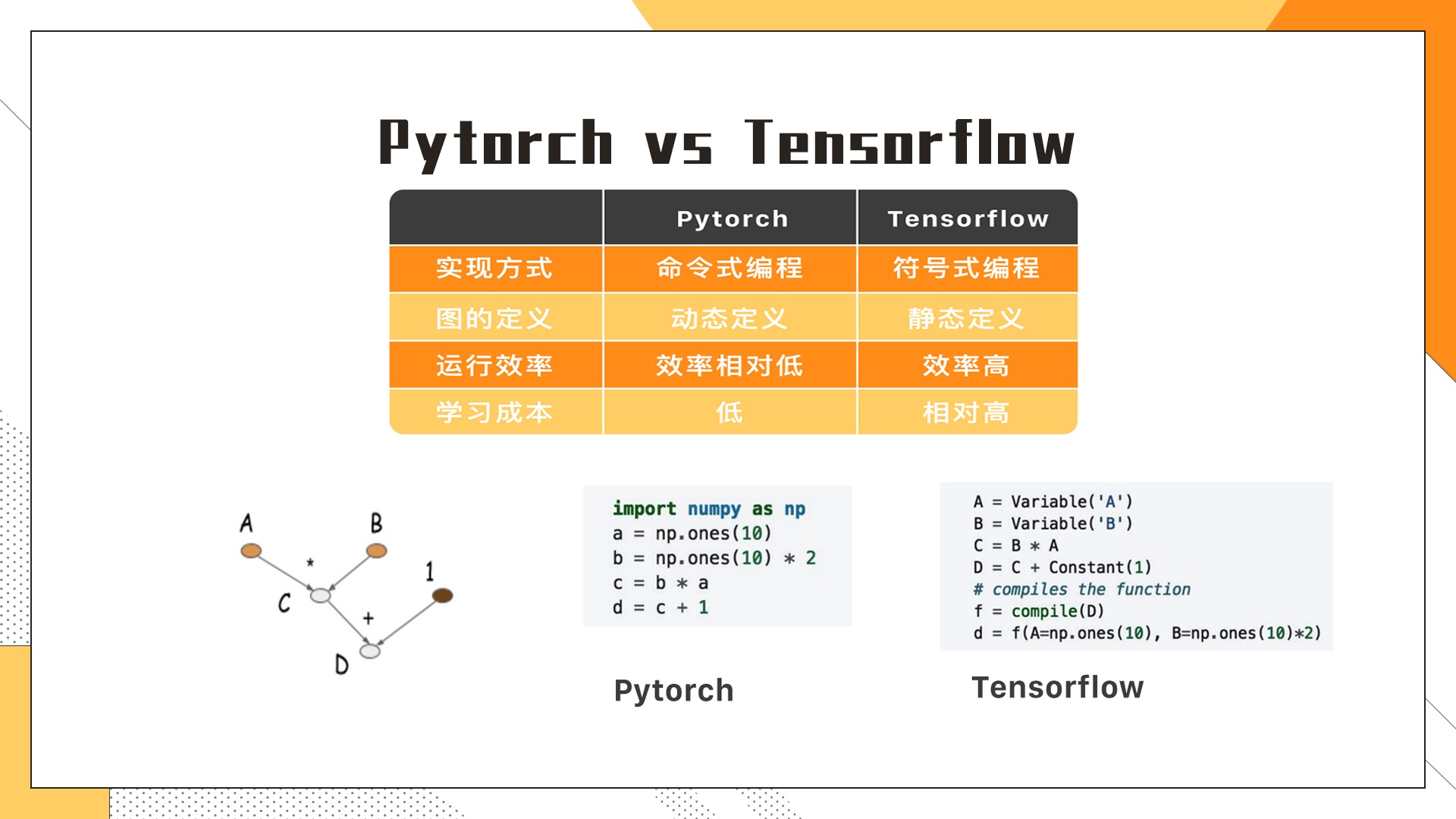
以上图中给出了两个框架之间具体的差异,其中最重要的差别在于Pytorch采用了命令式编程,TensorFlow则采用了符号式编程,实际上这是两种完全不同的编程方式。命令式编程其实就是我们最熟悉的编程方式,比如使用Python, Java等等。然而,符号式编程就不一样了,首选需要构建计算图,然后再把数据灌到图里做计算。
为了理解上述观点,简单看一下给出的几行代码。 左边展示的是Pytorch框架下的程序,跟日常编写的程序没什么差异。为了计算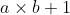 , 逐个去定义,并不断地通过演算最终得出结果。
, 逐个去定义,并不断地通过演算最终得出结果。
如果放在Tensorflow就不一样了,我们首先构造了一个静态的计算图(computation graph),然后把变量之间的关系先确定好。在这里,变量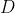 为最后的输出节点。定义好静态计算图之后,我们就可以把数据输入给计算图了。输入数据接着会通过预先定义好的步骤最后能算出结果。
为最后的输出节点。定义好静态计算图之后,我们就可以把数据输入给计算图了。输入数据接着会通过预先定义好的步骤最后能算出结果。
如果对上述概念比较难理解,你也可以想象一个这样的场景。有一家公司现在试着去构建从城市A到B的管道,用来运输一定量的石油。一种解决思路是,提前把管道全部制作完成,然后把石油输入到管道中,之后通过一系列运输过程最终可能会到达B城市。另外一种解决思路是,我们一边制作管道,一边运输石油,在这种情况下管道的设计可以动态地改变,比如我们发现某个路径不对劲,就可以换成另外一个路径。 在这里例子中,前者对应的是符号式编程,后者对应的是命令式编程。 简答来讲,前者是静态的,后者是动态的。动态的好处是灵活,但缺点是效率会低一些;相反,前者是静态的,必须要提前准备好完整的计算图(管道),之后才能使用,这种优势在于使用时的效率高,但缺点是不好理解和debug。
因此,在之后的学习中,我们将采用Pytorch框架,也建议刚步入AI领域的人士使用Pytorch,会大大降低学习成本。下面我们主要来介绍Pytorch的常见的使用方法。
二、Tensors
1.Tensor的创建
首先需要理解Tensor这个关键词,这是Pytorch中最基础的数据结构,类似于Numpy库中的array, matrix一样。但在Pytorch我们把这些统一定义为Tensor。为什么要起这个名字呢? 这一点其实之前有讲过。数据的表现形式通常为标量(scalar)、向量(vector)、矩阵(matrix)、张量(Tensor)。 其中标量可以看作是0维的张量、向量看作是1维的张量、矩阵看作是2维的张量,依次类推。所以,最终我们可以把Tensor作为这些数据结构的统称,这也是为什么像TensorFlow这种框架里包含Tensor关键词的主要原因。
在Pytorch中,Tensor的使用非常类似于Numpy的用法,但区别于Numpy的数据,Tensor数据可以用在GPU等设备上去跑,可以大大提高算法运行的效率。
Tensor库的导入
为了使用Pytorch的数据结构与功能,首先需要导入相应的库。这类似于当使用Numpy的时候导入numpy库一样。对于Pytorch,我们可以导入torch库。
import torch
import numpy as np从已有数据直接构建Tensor
第一步是构建Tensor类型的数据,其中一个方法是直接利用已有的数据来初始化Tensor,如下所示:
data = [[1,3],[3,4]]
t_data = torch.tensor(data)把Numpy数据转换成Tensor类型
如果数据已经表示为Numpy类型,我们也可以直接把它转换为Tensor类型的数据,这种操作在实际项目中非常实用。
np_data = np.array(data)
t_data = torch.from_numpy(np_array)直接利用Tensor库来创建Tensor数据
另外一种方式是直接使用Tensor所提供的方法来构造Tensor数据,这类似于我们调用numpy。zeors()函数来创建numpy型数据一样。请看如下几行代码:
shape = (2,3,)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)Tensor的属性(attributes)
构建好Tensor之后,我们可以查看它的一些属性如大小、类型、以及存放在cpu还是在gpu等信息。以上属性依次通过shape, dtype, device关键词来获取。
import torch
import numpy as np
data = torch.rand(3,4)
print(f"Shape of data: {data.shape}")
print(f"Datatype of data: {data.dtype}")
print(f"Device data is stored on: {data.device}")2.Tensor的操作
Tensor也像Numpy array支持各种各样的运算操作,比如矩阵乘法、加法、采样等等,而且这些运算均可以在GPU上进行。如果想把 Tensor在GPU做计算,需要把它先挪到GPU内存中,通过以下几行代码就可以实现:
if torch.cuda.is_available():
tensor = tensor.to('cuda')Tensor的索引
对于Tensor, 我们可以很方便的提取它的某一行、某一列、或者多行、多列,使用方法跟numpy几乎一模一样。
data = torch.ones(4,4)
data[:,1] = 0多个Tensor的拼接
很多时候,我们需要把多个Tensor做拼接,并转换为更大的Tensor。 这种操作可以通过自带的torch.cat()来完成,具体以哪个方向做拼接由dim参数来设定。
t1 = torch.cat([data, data, data], dim =1)Tensor的乘法
给定两个Tensor也可以方便地完成乘法运算。这里需要注意的一点是,一种乘法运算可以是我们所熟知的正常的矩阵乘法运算,另外一种乘法运算是按照每一个位置的乘法运算。
data1 = torch.ones(2,2)
data2 = torch.ones(2,2)
mul_res1 = torch.matmul(data1, data2)
mul_res2 = data1 * data23.Tensor与Numpy
从Tensor到Numpy
在CPU上,Tensor和Numpy变量可以共享一个内存空间,改变其中一个会自动改变另外一个。从Tensor到numpy类型的转化通过函数numpy()即可以实现。
t = torch.ones(5)
n = t.numpy()从Numpy到Tensor的转换
另一个方向的转换也极其简单,可通过from_numpy()函数来完成。这种情况下两个变量会共享一个内存,改变其中一个也会改变另外一个变量,这一点需要留意一下。
n = np.ones(5)
t = torch.from_numpy(n)三、Autograd的讲解
1.模型中的前向传播与反向传播
之前已经介绍过神经网络中的前向传播和反向传播的概念,在这做一个简单的回顾。对于神经网络的优化,一般分为两个步骤:第一步为前向传播,也就是给定训练数据,通过前向传播计算出模型中每个节点的输出;第二步则为反向传播,通过这一步计算出每一个参数的梯度,最后做参数的更新。实际上,Pytorch中的autograd模块可以完成这些事情。
下面,来介绍一个具体的例子。首先,导入已经训练好的restnet模型,同时也构建一个随机样本。这个样本为一张64*64的图片且每一个像素由RGB来表示,对应的标签为一个整数。
import torch, torchvision
model = torchvision.models.resnet18(pretrained=True)
data = torch.rand(1, 3, 64, 64)
labels = torch.rand(1, 1000)2.利用autograd计算梯度
对于autograd再看一个例子,用来加深对它的理解。假如有两个Tensor分别为a和b, 同时设置requires_grad=True, 这样的结果就是autograd会保存对于相应变量的操作。
import torch
a = torch.tensor(2.0, requires_grad=True)
b = torch.tensor(6.0, requires_grad=True)四、 构建神经网络模型
1.数据的构造
搭建的过程主要分为以下几步:
- 数据的构造,这部分一般需要通过一些处理,跟之前的做法没什么区别。如果有区别,就是需要把数据做成Tensor类型。
- 模型的构造,这是核心,也是Pytorch提供给我们的便捷的地方。
- 优化相关的设置,这一块主要设置optimizer的选择以及配置等信息。
- 训练模型,这一部分需要循环我们的训练数据,并一步步通过optimizer来优化模型的参数。
数据的构造
至于数据这块,为了简单期间,先用一个模拟的数据来代替,而且这并不影响我们对后续环节的理解。
# make fake data
n_data = torch.ones(100, 2)
x0 = torch.normal(2*n_data, 1) # class0 x data (tensor), shape=(100, 2)
y0 = torch.zeros(100) # class0 y data (tensor), shape=(100, 1)
x1 = torch.normal(-2*n_data, 1) # class1 x data (tensor), shape=(100, 2)
y1 = torch.ones(100) # class1 y data (tensor), shape=(100, 1)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # shape (200, 2) FloatTensor = 32-bit floating
y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (200,) LongTensor = 64-bit integer
2.模型的构造
对于模型这部分,需要设计的是前向传播部分(forward),因为这部分其实决定了整个模型的细节,比如一个数据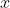 进入模型之后,如何一步步转换成最终的输出。转换细节实际上就是模型的细节。 在构建模型时,我们通常会创建一个新的类(class),并起一个合适的名字给到神经网络,之后在初始化阶段定义模型中所使用的参数和部件,接着在forward()函数中设计输入到输出中所经历的所有的过程。
进入模型之后,如何一步步转换成最终的输出。转换细节实际上就是模型的细节。 在构建模型时,我们通常会创建一个新的类(class),并起一个合适的名字给到神经网络,之后在初始化阶段定义模型中所使用的参数和部件,接着在forward()函数中设计输入到输出中所经历的所有的过程。
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer
self.out = torch.nn.Linear(n_hidden, n_output) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.out(x)
return x
net = Net(n_feature=2, n_hidden=10, n_output=2) # define the network3.优化器选择和配置
设计好了模型之后,剩下的工作就是设计loss和配置优化器。在模型中我们定义了forward()函数内容,通过这个函数就可以得到对于输入的预测。有了预测就可以跟真实值做比较来计算损失了。所以首先要定义损失函数的形态,是使用MSE还是交叉熵损失,还是Hinge Loss? 当然,这些取决于问题本身。在上述例子中,由于问题是二分类问题,我们决定选择交叉熵损失(entropy loss)。
loss_func = torch.nn.CrossEntropyLoss() # the target label is NOT an one-hotted4.主函数
完成了所有上述步骤之后,剩下的就是主函数部分了。在这里需要定义要循环多少次(epoch),如何保存中间结果,如何输出准确率等内容。
for t in range(50):
out = net(x)
loss = loss_func(out, y)
optimizer.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if t % 2 == 0:
prediction = torch.max(out, 1)[1]
pred_y = prediction.data.numpy()
target_y = y.data.numpy()
accuracy = float((pred_y == target_y).astype(int).sum()) / float(target_y.size)
print ('Accuracy=%.2f' % accuracy)
plt.pause(0.1)参考:
贪心学院nlp
以上是关于深度学习为什么选择Pytorch?史上最详细Pytorch入门教程的主要内容,如果未能解决你的问题,请参考以下文章
重磅!Uber发布史上最简单的深度学习框架Ludwig!不懂编程也能玩转人工智能
本科生学深度学习-史上最容易懂的RNN文章,小白也能看得懂,评论继续送书