T-SQL里数据库工程师都不知道的秘密之SQL Server自定义函数UDF
Posted ShenLiang2025
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了T-SQL里数据库工程师都不知道的秘密之SQL Server自定义函数UDF相关的知识,希望对你有一定的参考价值。
T-SQL SQL Server UDF自定义函数概念与案例实战
函数的定义
这里的函数指的是用户自定义函数(UDF)全名为(user-defined function),以下简称为函数。
它是数据库里的用户自定义程序,用户可以指定输入参数,制定计算逻辑,最终返回一个标量的值或者结果集。一般我们通过T-SQL或者CLR来定义函数,这里我们重点介绍的是T-SQL的方式。还有一类函数是系统内置的函数又称之为系统函数,我们直接调用即可。
函数的使用场景
函数可以在很多场景下使用,对一个标量和表(表变量)的字段或者计算列、检查约束里都可适用。
函数的语法限制
有些语法在函数是不支持的,详细见下:
1 用户错误异常处理,不能使用TRY CATCH、@ERROR、RAISERROR等语法
2 修改数据(DML),对表的数据进行增加、修改、删除,表变量除外。
3 使用用户自定义(DDL)即对表结构的增加、修改、删除
4 不可以调用自定义存储过程,但可以调用扩展存储过程
5 不能用临时表
6 不能用动态SQL
7 不能返回多个结果集
8 SET语句不能使用
9 不能调用系统影响型函数如NEWID、RAND
完整内容详细见官网介绍: 自定义函数的限制
函数的返回类型
函数按照返回类型可分为标量值函数、内联型函数、多语内联型函数,下文将结合案例分别介绍这些类型的函数。
标量型函数
标量型函数即是指函数返回的值是个标量(单个值)。这种类型的函数在函数体的头部需要指定返回的类型(如int、money、varchar等)。
#这里假设我们有个层次(父子)的树形员工数据,比如某个职位是HR MANAGER(HR经理)的,他下面有一些职位是HR的同事,这些职位是HR的下面是职位是HR Intern(实习HR)的同事。
DROP TABLE IF EXISTS dbo.Emp;
GO
CREATE TABLE dbo.emp
(
empid INT NOT NULL CONSTRAINT PK_emp_empid PRIMARY KEY,
mgrid INT NULL
CONSTRAINT FK_emp_empid REFERENCES dbo.emp,
empname VARCHAR(25) NOT NULL,
jobtitle VARCHAR(25) NOT NULL,
salary int NOT NULL,
CHECK (empid <> mgrid)
);
INSERT INTO dbo.emp(empid, mgrid, empname,jobtitle, salary)
VALUES(1, NULL, '张三','CEO', 10000),
(2, 1, '李四','CTO', 7000),
(3, 1, '王五','COO', 7500),
(4, 2, '刘二','Product MANAGER', 6000),
(5, 2, '马六','Program MANAGER', 5500),
(6, 2, '秦一','Test MANAGER', 4500),
(7, 3, '宋二','HR MANAGER', 5000),
(8, 4, '江五','Product', 5000),
(9, 5, '谷三','C++', 2500),
(10, 5, '谷三','Python', 2500),
(11, 5, '杨八','Java', 3000),
(12, 6, '纪一','Test', 2500),
(13, 6, '黎七','Test', 2500),
(14, 7, '管一','HR', 3000),
(15, 7, '关三','HR', 3000),
(16, 14, '孔十','HR Intern' , 2000),
(17, 15, '金三','HR Intern', 2000),
(18, 15, '钱二','HR Intern', 1500);
-- 传一个参数(员工姓名)后获取他(她)下面的员工个数。
-- # 这里假定员工姓名唯一,比较严谨的是通过员工编号作为参数。
CREATE OR ALTER FUNCTION dbo.fun_getEmpnumber(@empname AS VARCHAR(10))
RETURNS INT
AS
BEGIN
DECLARE @totalemp AS INT;
WITH EmpsCTE AS
(
SELECT empid,mgrid, salary,empname,jobtitle
FROM dbo.Emp
WHERE empname = @empname
UNION ALL
SELECT S.empid,S.mgrid, S.salary,S.empname,S.jobtitle
FROM EmpsCTE AS M
INNER JOIN dbo.Emp AS S
ON S.mgrid = M.empid
)
SELECT @totalemp= COUNT(empid) - 1 FROM EmpsCTE;
RETURN @totalemp;
END;
-- 调用,
-- 返回员工”宋二”下的员工数(不含自己)。
SELECT dbo.fun_getEmpnumber('宋二')
5
-- 返回员工”纪一”下的员工数(因下面没人,所以结果为0)。
SELECT dbo.fun_getEmpnumber('纪一')
0
-- 返回员工”方四”下的员工数(因没有”方四”这个人,所以结果为-1)。
SELECT dbo.fun_getEmpnumber('方四')
-1
-- 当然也可以结合字段一起使用
SELECT empid,mgrid, salary,empname,jobtitle,
dbo.fun_getEmpnumber(empname) undernum
FROM dbo.emp
WHERE empname='宋二'

确定与非确定值函数
像SYSDATETIME、 RAND(不带种子)、NEWID内置的系统函数都是不确定函数,所谓不确定函数即是每次执行时返回的结果不固定、不确定,而固定函数则是如果参数给定,那么函数的返回值必然确定。
这里对于不确定函数按照函数对SQL Server系统的影响又分为系统独立型和系统影响型,SYSDATETIME属于系统独立型,因为每次返回的时间不固定,但对下一次的执行不受上一次的影响。而RAND和NEWID则是系统影响型,即下一次的执行受上一次的影响,因为这俩函数具有唯一性,每次执行出来的结果都依赖于上一次的结果且不能和它一样。
所以SYSDATETIME可以在用户自定义函数里引用,而RAND和NEWID则不可以。示例见下:
CREATE OR ALTER FUNCTION dbo.fun_rand()
RETURNS FLOAT
AS
BEGIN
RETURN RAND();
END;
GO报错信息见下:

如果想绕过这个限制,可以将不确定值函数放置在视图里,然后通过定义函数访问该视图即可。示例脚本见下:
-- Way2 示例里引用
CREATE OR ALTER VIEW dbo.view_rand
AS
SELECT RAND() AS myrand;
GO
CREATE OR ALTER FUNCTION dbo.fun_rand()
RETURNS FLOAT
AS
BEGIN
RETURN
(SELECT myrand FROM dbo.view_rand);
END;
GO
SELECT TOP 3 empid,mgrid,empname,rand() sys_rand,
dbo.fun_rand() f_rand
FROM dbo.Emp A
-- 结果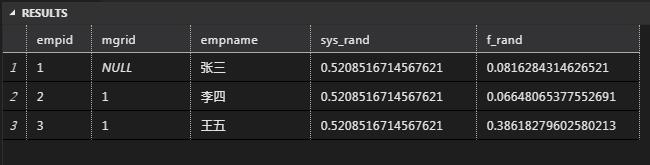
特别需要注意的是:
1 这里调用了系统内置函数rand和自定义的rand函数,系统的函数是批查询级别的(整个批查询次仅执行一次rand函数),而自定义函数是记录级别的(每条记录都执行了rand函数)。
2 仔细查看上述脚本执行结果不能得出上述结论。
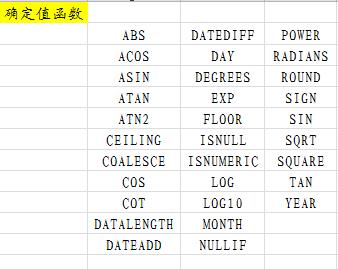
内置(非)确定值函数
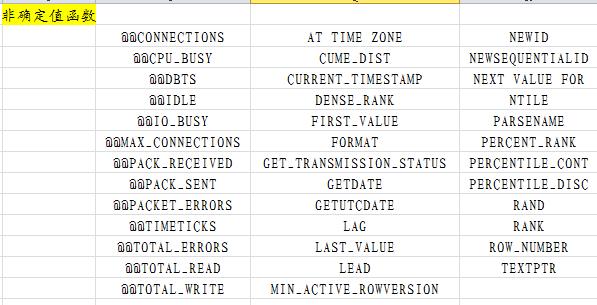

绑定模式(SCHEMABINDING)选项
在持久化计算列里或者索引视图里的自定义函数必须是确定值的。这就要求用户自定义函数里不能调用非确定值函数并且定义时加上SCHEMABINDING选项。详见如下例子的演示。
关于计算列:计算列分为非持久化和持久化两种,非持久化的仅在查询时执行且不保存计算列结果,而持久化则可以保存计算列结果且可以建立索引。示例见下:
-- 1 创建函数
CREATE OR ALTER FUNCTION dbo.fun_endyear(@datevar AS DATE)
RETURNS DATE
WITH SCHEMABINDING
AS
BEGIN
RETURN DATEFROMPARTS(YEAR(@datevar), 12, 31);
END;
GO
-- 2 创建表并制定计算列对应的函数
CREATE TABLE dbo.test
(
id INT NOT NULL IDENTITY CONSTRAINT PK_test_id PRIMARY KEY,
insertdate DATE NOT NULL,
insertyear AS dbo.fun_endyear(insertdate) PERSISTED
);特别需要说明:
1 这里针对非确定型函数需要加WITH SCHEMABINDING选项。SCHEMABINDING选项主要应用在视图里,主要对视图依赖的表和字段起到阻止结构变化的作用。同样的在函数里指定该选项是为了阻断函数依赖的表结构的变换。
2 针对计算列定义时需要加PERSISTED关键字。
3 关于函数DATEFROMPARTS、YEAR函数使用的说明,这里针对不同的时间格式,如dmy、myd、ymd都可以提取时间。见如下示例:
SET DATEFORMAT dmy;
GO
DECLARE @datevar DATE = '27/07/2021';
SELECT @datevar,DATEFROMPARTS(YEAR(@datevar), 12, 31);
GO
SET DATEFORMAT myd;
GO
DECLARE @datevar DATE = '07/2021/27';
SELECT @datevar,DATEFROMPARTS(YEAR(@datevar), 12, 31);
GO
-- 结果均为:
/*
2021-07-27 2021-12-31
*/内联表型函数
表型函数在定义和使用上和标量值函数类似,不过这里返回的类型是表变量,即是一个结果集。针对emp员工表,按照指定的分页和页数,仅显示最后一批次的数据,详细代码见下:
-- 1 分页函数示例:
CREATE OR ALTER FUNCTION dbo.fun_GetPage(@pagenum AS BIGINT, @pagesize AS BIGINT)
RETURNS TABLE
WITH SCHEMABINDING
AS RETURN
WITH C AS
( SELECT ROW_NUMBER() OVER(ORDER BY empid) AS rownum, empid, empname,jobtitle,salary
FROM dbo.emp
)
SELECT empid, empname,jobtitle,salary
FROM C
WHERE rownum BETWEEN (@pagenum - 1) * @pagesize + 1 AND @pagenum * @pagesize;
GO
-- 2 调用示例
SELECT empid, empname,jobtitle,salary
FROM dbo.fun_GetPage(3,2)
-- 3 结果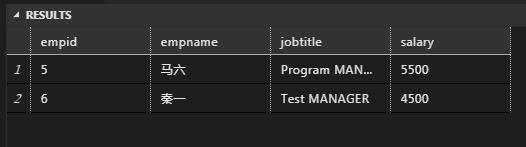
延展阅读,SQL Server 2012之后版本分页可用OFFSET FETCH语法,所以上述代码可改写为:
CREATE OR ALTER FUNCTION dbo.fun_GetPage_V2(@pagenum AS BIGINT, @pagesize AS BIGINT)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
SELECT ROW_NUMBER() OVER(ORDER BY empid) AS rownum,empid, empname,jobtitle,salary
FROM dbo.emp
ORDER BY empid
OFFSET (@pagenum - 1) * @pagesize ROWS FETCH NEXT @pagesize ROWS ONLY;
GO 多语句内联表函数
多语句内联表函数是内联表函数的延展。内联表一般是单个查询,而多语句内联表函数在头部定义表变量后可在函数体内执行多语句对表变量进行处理((WHILE循环、插入、更新、删除等),最终返回该表变量。
多语句内联表应用在父子查询时比较方便,因为我们可以方便的控制父节点。同时它可以有自己复杂的业务逻辑,而相比较而言内联表函数只能返回一个查询。
-- 1 多语句内联函数(获取级联子节点)定义
DROP FUNCTION IF EXISTS dbo.func_GetChildtree;
GO
CREATE FUNCTION dbo.func_GetChildtree (@mgrid AS INT, @maxlevels AS INT = NULL)
RETURNS @Tree TABLE -- 定义表变量以接收处理结果
(
empid INT NOT NULL PRIMARY KEY,
mgrid INT NULL,
empname VARCHAR(25) NOT NULL,
jobtitle VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
lvl INT NOT NULL,
sortpath VARCHAR(892) NOT NULL ,
INDEX idx_lvl_empid_sortpath NONCLUSTERED(lvl, empid, sortpath)
)
WITH SCHEMABINDING -- 绑定选项,阻止表表结构变化
AS
BEGIN
DECLARE @lvl AS INT = 0;
-- 初始化@Tree里根节点数据(参数@mgrid对应的那条数据)。
INSERT INTO @Tree(empid, mgrid, empname,jobtitle, salary, lvl, sortpath)
SELECT empid, NULL AS mgrid, empname,jobtitle, salary, @lvl AS lvl, '.' AS sortpath
FROM dbo.Emp
WHERE empid = @mgrid;
-- UPDATE @Tree SET empname='五王2' WHERE mgrid IS NULL; -- 演示更新
-- 借助系统变量@@ROWCOUNT(影响的行)和@maxlevels参数进入循环寻找子节点
WHILE @@ROWCOUNT > 0 AND (@lvl < @maxlevels OR @maxlevels IS NULL)
BEGIN
SET @lvl += 1;
-- 通过父子关联插入子节点数据到@Tree表
INSERT INTO @Tree(empid, mgrid, empname,jobtitle ,salary, lvl, sortpath)
SELECT S.empid, S.mgrid, S.empname,S.jobtitle, S.salary, @lvl AS lvl,
M.sortpath + CAST(S.empid AS VARCHAR(10)) + '.' AS sortpath
FROM dbo.Emp AS S
INNER JOIN @Tree AS M
ON S.mgrid = M.empid AND M.lvl = @lvl - 1;
END;
RETURN; -- 返回,这里即对应开头的定义,返回@Tree
END;
GO
-- 2 执行
SELECT empid, REPLICATE(' | ', lvl) + empname AS empname, mgrid, salary, lvl, sortpath FROM dbo.func_GetChildtree(3, NULL) AS T ORDER BY sortpath;
-- 3 结果
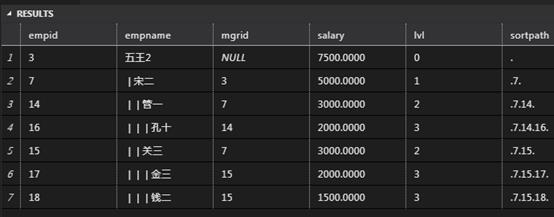
以上是关于T-SQL里数据库工程师都不知道的秘密之SQL Server自定义函数UDF的主要内容,如果未能解决你的问题,请参考以下文章