Python爬虫:还在纠结买什么手机?pyquery库给你参考答案
Posted 李元静
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫:还在纠结买什么手机?pyquery库给你参考答案相关的知识,希望对你有一定的参考价值。

pyquery库
虽然Beautiful Soup库的功能非常强大,但CSS选择器功能有些弱,至少对于pyquery库来说是非常弱的。
而且pyquery库并不是Python的标准库,所以在使用pyquery库之前需要安装,示例命令如下所示:
pip install pyquery
安装完成之后,我们就可以愉快的玩耍pyquery库了。需要注意的是,后面的所有解析代码都是基于下面的html代码(除了实战):
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="utf-8">
<title>我是一个测试页面</title>
</head>
<body>
<ul class="ul">
<li class="li"><a href="https://liyuanjinglyj.blog.csdn.net/">我的主页</a></li>
<li class="li"><a href="https://www.csdn.net/">CSDN首页</a></li>
<li class="li"><a href="https://www.csdn.net/nav/python" class="aaa">Python板块<a>>1111</a></a>
</ul>
</body>
</html>
基本用法
在pyquery库中,有一个PyQuery类,我们获取的HTML或者说XML代码,需要通过其构造函数创建其对象实例。
示例代码(获取网页标题以及所有<a>标签的href属性值):
from pyquery import PyQuery as pq
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
doc = pq(html.strip())
print(doc('title').text())
for a in doc('a'):
print(a.get('href'), a.text)
运行之后,效果如下:

pyquery库通过get获取属性的值,用text()方法获取标签的文本信息。不过,我们这里直接加载的文档,其实pq()可以直接传入网址,它会自己获取网址代码。感兴趣的可以试试。
CSS选择器
pyquery库这些基本的属性以及标签获取方式是其最不显眼的优势,其真正的优势还是如前文所说的CSS选择器。
下面,我们举例层级访问,以及直接访问的示例:
from pyquery import PyQuery as pq
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
doc = pq(html.strip())
print("直接获取class等于aaa的标签")
print(doc('.aaa'))
print("层级获取class等于aaa的标签")
print(doc('html body .ul .li .aaa'))
运行之后,就是2个“<a href=“https://www.csdn.net/nav/python” class=“aaa”>Python板块”标签内容,这里就不展示了。
查找节点
其实学完上面这些,要爬取一个网站已经可以手到擒来了。不过,我们还是将pyquery库全部介绍一遍,这里开始讲解其节点的查找。
查找子节点
在实际的爬虫项目中,我们需要获取某个节点的子节点,那么如何操作呢?
比如,这里我们获取ul标签的所有<a>子节点,示例如下:
from pyquery import PyQuery as pq
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
doc = pq(html)
print("find")
ul = doc('.ul1')
a_list = ul.find('a')
for a in a_list:
a = str(etree.tostring(a, pretty_print=True, encoding='UTF-8'), 'UTF-8')
if a.strip() != '':
print(a)
print("children")
ul = doc('.ul1')
a_list = ul.children('a')
for a in a_list:
a = a.html()
if a.strip() != '':
print(a)
运行之后,效果如下:

可以看到,这里的find()能查找所有<a>子节点,但是children()却什么都获取不到,这是因为children获取的是直接子节点,而find()获取的是子孙节点。
查找父节点
在pyquery库中,通过parent()方法可以直接查找其父节点,而通过parents()方法可以查找所有的父节点。
这里,我们来测试查找最后一个<a>标签的所有父节点与父节点,示例如下:
from pyquery import PyQuery as pq
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
doc = pq(html)
a = doc('.aaa')
print("获取其父节点")
print(a.parent())
print("获取其所有父节点")
for parent in a.parents():
print(parent.tag)
print("-----")
运行之后,效果如下:

查找其兄弟节点
在pyquery库中,通过siblings()方法可以查找某个节点的兄弟节点,它也可以通过CSS选择器参数来查找。
我们将上面的HTML-li代码更新一下:
<li class="li1"><a href="https://liyuanjinglyj.blog.csdn.net/">我的主页</a></li>
<li class="li"><a href="https://www.csdn.net/">CSDN首页</a></li>
<li class="li"><a href="https://www.csdn.net/nav/python" class="aaa">
Python板块
<a>1111</a>
</a>
示例如下:
from pyquery import PyQuery as pq
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
doc = pq(html)
li1 = doc(".li1")
print(li1.siblings())
print('针对属性查找兄弟节点')
print(li1.siblings('.li'))
运行之后,效果如下:
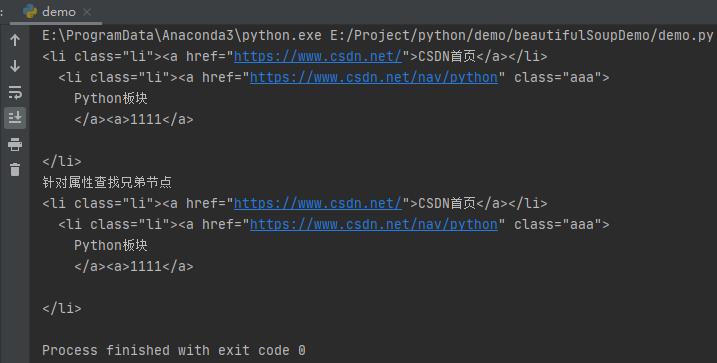
获取节点信息
节点信息包括节点的名称,属性,文本,整个节点的HTML代码以及其节点内部的HTML代码。下面,博主一一举例进行获取:
from pyquery import PyQuery as pq
from lxml import etree
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
doc = pq(html)
a = doc('.li1')
print('节点名称:', a[0].tag)
print("节点属性:", a[0].get('class'))
print("节点属性:", a.attr('class'))
print("节点文本:", a.text())
print("整个节点HTML代码:", str(etree.tostring(a[0], pretty_print=True, encoding='UTF-8'), 'UTF-8'))
print("节点内部HTML代码:", a.html())
运行之后,效果如下:

需要注意的是,如果需要获取整个节点的HTML代码,需要借助lxml库进行完成,如果获取的节点的父节点只有它一个子节点,倒是可以通过获取父节点在获取内部的HTML代码获取整个节点的HTML代码,但一般来说,一个父节点应该有很多子节点,这么做行不通,目前也没什么好的办法解决,只能借助lxml库。
修改节点
博主记得大学的时候,那时候学校网址很卡,毕业申请网页总是打不开,就算打开了根本就无法加载全部的网页信息,提交更是卡着不动。(稍微人多就崩了)
这个时候,博主取巧直接将学校提交网址的源代码下载了下来,然后将提交的信息全部写在对应的HTML标签中,然后直接提交的。
不过,当时博主是手动操作的。如果需要代码操作,可以借助pyquery库进行,比如我们可以给一个标签添加文本,属性等,对应代码如下:
from pyquery import PyQuery as pq
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
doc = pq(html)
# 添加一个标签的class属性值
li = doc('.li1')
li.add_class('li')
print(doc)
# 删除一个标签的class属性值
li.remove_class('li')
print(doc)
# 修改一个标签的class属性值
li.attr('class', 'li123')
print(doc)
# 修改一个标签的文本
a = doc('.aaa')
a.text('我是修改的值')
print(doc)
# 修改一个标签的HTML代码
a = doc('.aaa')
a.html('<a href="www.csdn.net">华为</a>')
print(doc)
# 删除一个节点
li.remove()
print(doc)
运行结果这里就不放置了,因为代码每次打印产生了大量数据,大量的图片在博文堆积,阅读体验不好,还请见谅。感兴趣的自己复制运行查看。
不过,需要特别注意一个点,text()方法是替换文本,如果替换的是HTML代码需要使用html()方法,如果text()替换html代码,会导致<变成<。
伪类选择器
pyquery库之所以CSS选择器非常强大,是因为其支持多种多样的伪类选择器。例如,选择第1个节点,最后一个节点,索引为奇数的节点,索引为偶数的节点等。
这些都可以通过pyquery库的CSS选择器直接操作。下面,我们来举例说明,示例代码如下所示:
from pyquery import PyQuery as pq
with open('demo.html', 'r', encoding='utf-8') as f:
html = f.read()
doc = pq(html)
# 获取第一个li节点
li = doc('li:first-child')
print(li.html())
# 获取最后一个li节点
li = doc('li:last-child')
print(li.html())
# 获取第2个li节点
li = doc('li:nth-child(2)')
print(li.html())
# 获取索引小于3的li节点(从0开始,0,1节点)
li = doc('li:lt(2)')
print(li)
# 获取索引大于1的li节点(从0开始,只有2节点大于0,也就是第3个li)
li = doc('li:gt(1)')
print(li)
# 选择奇数位的li节点
li = doc('li:nth-child(2n+1)')
print(li)
# 选择偶数位的li节点
li = doc('li:nth-child(2n)')
print(li)
# 选取文本内容包含CSND的所有li节点
li = doc('li:contains(CSDN)')
print(li)
# 选取文本内容包含CSND的所有节点
li = doc(':contains(CSDN)')
print(len(li))
运行结果太多,这里也不展示运行结果。具体的结果与代码注释一模一样。pyquery库到这里就已经全部讲解完成。下面,将通过pyquery库进行实战测验。
实战:抓取ZOL热门手机排行榜
首先,我们来查看其网页的源代码,看看这个榜单的内容在哪个标签中。如下图所示:

可以看到,我们的手机热榜在class等于section的div标签中,同时class等于rank-list__item clearfix才是每行的榜单内容。所以,我们可以直接获取class等于rank-list__item clearfix的所有div然后遍历。
from pyquery import PyQuery as pq
from lxml import etree
import requests
url = "https://top.zol.com.cn/compositor/57/cell_phone.html"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
result = requests.get(url=url, headers=headers)
doc = pq(result.text)
result = doc('.section')
divs = result('.rank-list__item')
接着,我们需要获取每个div榜单里面的信息,比如排名,手机名称,价位等等。我们先来看看这些数据到底在哪些标签中。

如上图所示,class=rank__number的div是其排名,class=rank__name的div下的a标签是手机的名称以及链接,class=rank__price的div是其价格。
知道了这些,我们可以直接上代码了,不过需要注意的是,第一名的排行显示的是一个皇冠,并没有排行的数字。所以获取不到排行的数字。
当然,本身列表就是顺序的,你可以自己遍历数字从1开始排即可,根本不需要获取class=rank__number的内容。不过这里我们还是获取一下,代码如下:
from pyquery import PyQuery as pq
import requests
url = "https://top.zol.com.cn/compositor/57/cell_phone.html"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
result = requests.get(url=url, headers=headers)
doc = pq(result.text)
result = doc('.section')
divs = result('.rank-list__item')
for div in divs.items():
if '' == div('.rank__number').text().strip():
print("手机排名:", 1)
else:
print("手机排名:", div('.rank__number').text())
print("手机名称:", div('.rank__name a').text())
print("手机价格:", div('.rank__price').text())
print("手机详情链接:", div('.rank__name a').attr('href'))
print()
运行之后,手机的热门榜单就完全获取到了,这样购买手机的参考也就有了,效果如下:

以上是关于Python爬虫:还在纠结买什么手机?pyquery库给你参考答案的主要内容,如果未能解决你的问题,请参考以下文章
还在纠结要不要学Python?一文看懂Python主要应用领域和就业前景
准备入手iPhone13,纠结选择买13 Pro Max还是13 Pro?