2021年大数据HBase(十六):HBase的协处理器(Coprocessor)
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据HBase(十六):HBase的协处理器(Coprocessor)相关的知识,希望对你有一定的参考价值。
全网最详细的大数据HBase文章系列,强烈建议收藏加关注!
新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。
目录
系列历史文章
2021年大数据HBase(十七):HBase的360度全面调优
2021年大数据HBase(十六):HBase的协处理器(Coprocessor)
2021年大数据HBase(十五):HBase的Bulk Load批量加载操作
2021年大数据HBase(十四):HBase的原理及其相关的工作机制
2021年大数据HBase(十三):HBase读取和存储数据的流程
2021年大数据HBase(十二):Apache Phoenix 二级索引
2021年大数据HBase(十一):Apache Phoenix的视图操作
2021年大数据HBase(十):Apache Phoenix的基本入门操作
2021年大数据HBase(九):Apache Phoenix的安装
2021年大数据HBase(八):Apache Phoenix的基本介绍
2021年大数据HBase(七):Hbase的架构!【建议收藏】
2021年大数据HBase(六):HBase的高可用!【建议收藏】
2021年大数据HBase(五):HBase的相关操作-JavaAPI方式!【建议收藏】
2021年大数据HBase(四):HBase的相关操作-客户端命令式!【建议收藏】
HBase的协处理器(Coprocessor)
一、起源
Hbase 作为列族数据库最经常被人诟病的特性包括:
- 无法轻易建立“二级索引”
- 难以执 行求和、计数、排序等操作
比如,在旧版本的(<0.92)Hbase 中,统计数据表的总行数,需要使用 Counter 方法,执行一次 MapReduce Job 才能得到。虽然 HBase 在数据存储层中集成了 MapReduce,能够有效用于数据表的分布式计算。然而在很多情况下,做一些简单的相加或者聚合计算的时候, 如果直接将计算过程放置在 server 端,能够减少通讯开销,从而获 得很好的性能提升
于是, HBase 在 0.92 之后引入了协处理器(coprocessors),实现一些激动人心的新特性:能够轻易建立二次索引、复杂过滤器(谓词下推)以及访问控制等。
二、协处理器主要的分类
- ObServer
- Endpoint
三、HBase的协处理器_ObServer
ObServer 类似于传统数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server 端调用。
ObServer Coprocessor 就是一些散布在 HBase Server 端代码中的 hook 钩子, 在固定的事件发生时被调用。
比如: put 操作之前有钩子函数 prePut,该函数在 put 操作 执行前会被 Region Server 调用;在 put 操作之后则有 postPut 钩子函数
以 Hbase2.0.0 版本为例,它提供了三种观察者接口:
- RegionObserver:提供客户端的数据操纵事件钩子: Get、 Put、 Delete、 Scan 等
- WALObserver:提供 WAL 相关操作钩子。
- MasterObserver:提供 DDL-类型的操作钩子。如创建、删除、修改数据表等。
- 到 0.96 版本又新增一个 RegionServerObserver
下面是以 RegionObserver 为例子讲解 Observer 这种协处理器的原理:

- 比如客户端发起get请求
- 该请求被分派给合适的RegionServer和Region
- coprocessorHost拦截该请求,然后在该表上登记的每个RegionObserer上调用preGet()
- 如果没有被preGet拦截,该请求继续送到Region,然后进行处理
- Region产生的结果再次被coprocessorHost拦截,调用postGet()处理
- 加入没有postGet()拦截该响应,最终结果被返回给客户端
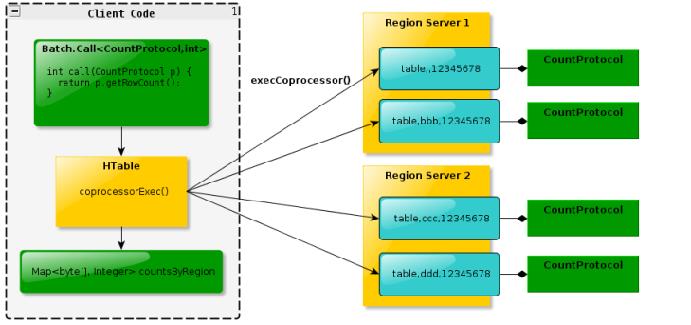
四、HBase的协处理器_Endpoint
- Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些 Endpoint 协处理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常见的用法就是进行聚集操作
- 如果没有协处理器,当用户需要找出一张表中的最大数据,即max 聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到 Client 端统一执 行,势必效率低下。
- 利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内 执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出,仅仅将该 max 值返回给客户端。在客户端进一步将多个 Region 的最大值进一步处理而找到其中的最大值。这样整体的执行效率就会提高很多
下图是 EndPoint 的工作原理:
五、概念总结
- observer 允许集群在正常的客户端操作过程中可以有不同的行为表现
- endpoint 允许扩展集群的能力,对客户端应用开放新的运算命令
- observer 类似于 RDBMS 中的触发器,主要在服务端工作
- endpoint 类似于 RDBMS 中的存储过程,主要在 服务器端、client 端工作
- observer 可以实现权限管理、优先级设置、监控、 ddl 控制、 二级索引等功能
- endpoint 可以实现 min、 max、 avg、 sum、 distinct、 group by 等功能
六、加载的方式
1、静态加载
- 通过修改 hbase-site.xml 这个文件来实现
- 启动全局 aggregation,能过操纵所有的表上的数据。只需要添加如下代码:

注意: 为所有 table 加载了一个 cp class,可以用” ,”分割加载多个 class
2、动态加载:
- 启用表 aggregation,只对特定的表生效
- 通过 HBase Shell 来实现,disable 禁用表
- 添加 aggregation , 添加后启用表即可
hbase> alter 'mytable', METHOD => 'table_att','coprocessor'=>'|org.apache.Hadoop.hbase.coprocessor.AggregateImplementation||'
七、卸载的方式
1、禁用表:
disable 'test' 2、修改表: 删除协处理器的配置信息
alter ‘test’, METHOD => 'table_att_unset', NAME => 'coprocessor$1’ 3、启动表
enable 'test'八、HBase的协处理器总结
Hbase的协处理器主要有二大类: ObServer 和 Endpoint
-
ObServer: 可以将其看做是拦截器(过滤器 触发器), 可以基于这种协处理器对Hbase相关操作进行监控(钩子 Hook)
-
例如: 监控用户插入到某个表操作, 插入之前要打印一句话
-
ObServer所提供一些类, 这些类可以监控到HBase中各种操作: 对数据的CURD 对表的CURD 对region的操作 对日志操作
-
ObServer能做什么事情?
-
1) 记录操作日志
-
2) 权限的管理
-
-
-
Endpoint: 可以看做数据库中存储过程,也可以看做在java代码中封装一个方法(功能), 将这个方法放置服务端, 让服务器进行执行操作, 客户端只需要拿到服务端执行结果即可
-
作用: 执行一些聚合操作: 求和 求差 求最大 ....
-
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于2021年大数据HBase(十六):HBase的协处理器(Coprocessor)的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据HBase:HBase数据模型!!!建议收藏
2021年大数据HBase(十三):HBase读取和存储数据的流程