抛弃Python?1分钟插入10亿行数据!
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了抛弃Python?1分钟插入10亿行数据!相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :新智元
近日,一位程序员急需在一分钟之内生成十亿行的测试数据库,然而在用Python写了脚本之后发现「大失败」。怎么办?当然是用Rust了!
最近,一位程序员表示自己急需一个「也就」十亿行数据的测试数据库,并且还得在一分钟之内生成。
于是,他做了一个所有程序员都会做的事:写一个Python脚本来生成数据库。
然而,很不幸的是,这个脚本非 常 慢。
于是,他又做了一个所有程序员都会做的事:进一步学习关于SQLite、Python以及不知道为什么还有Rust的知识。
项目已开源:https://github.com/avinassh/fast-sqlite3-inserts
目标
作者需要在他2019年的MacBook Pro(2.4GHz四核i5)上,一分钟内生成一个有10亿行的SQLite数据库。

表的模式
要求:
生成的数据是随机的;
「area」列将包含六位数的地区代码(任何六位数都可以,不需要验证);
「age」列是5、10或15中的任何一个;
「active」列是0或1。
不过,作者表示,对脚本的要求也不用太高,还是可以妥协的:
如果进程崩溃,所有的数据都丢失也没有问题,再次运行脚本就可以了;
允许充分利用电脑的资源:100%的CPU,8GB的内存和剩余的SSD储存;
不需要使用真正的随机方法,来自stdlib的伪随机方法就可以。
Python原型
在最开始的脚本中,作者试图在一个for循环中逐一插入1000万条记录,而这让用时直接达到了15分钟。
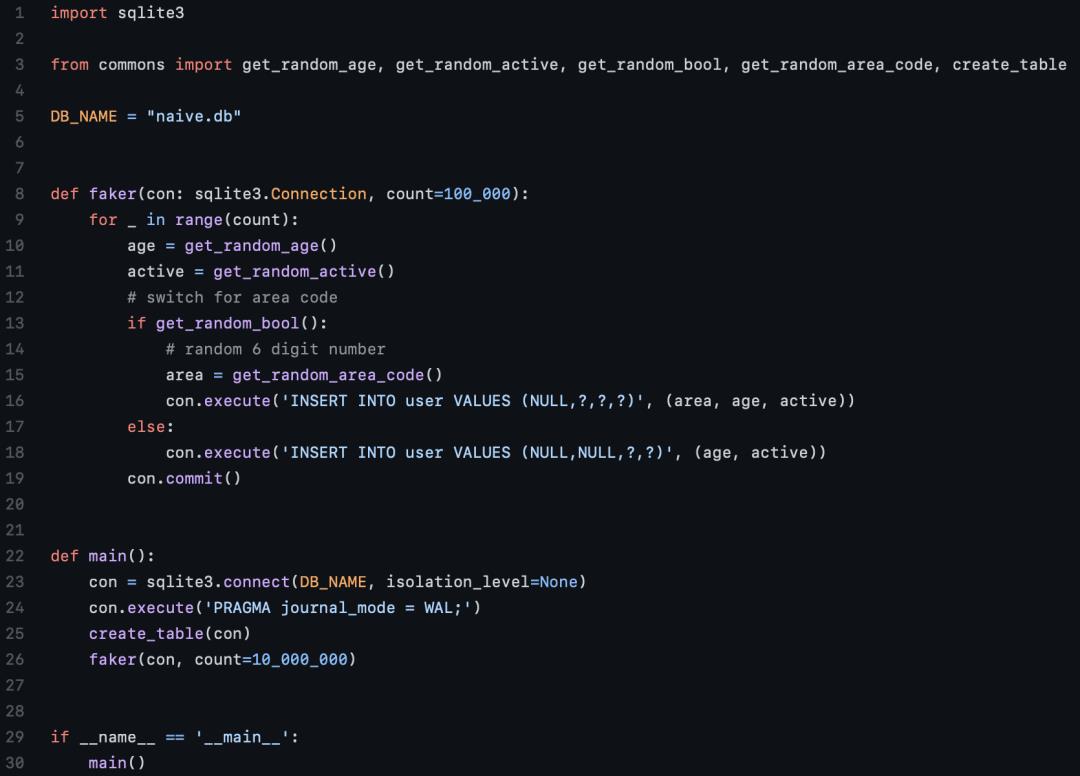
显然,这太慢了。
在SQLite中,每次插入都是一个事务,每个事务都保证它被写入磁盘,作者推断可能问题就来自这里。
于是作者开始尝试不同规模的批量插入,发现10万是一个最佳点,而运行时间减少到了10分钟。
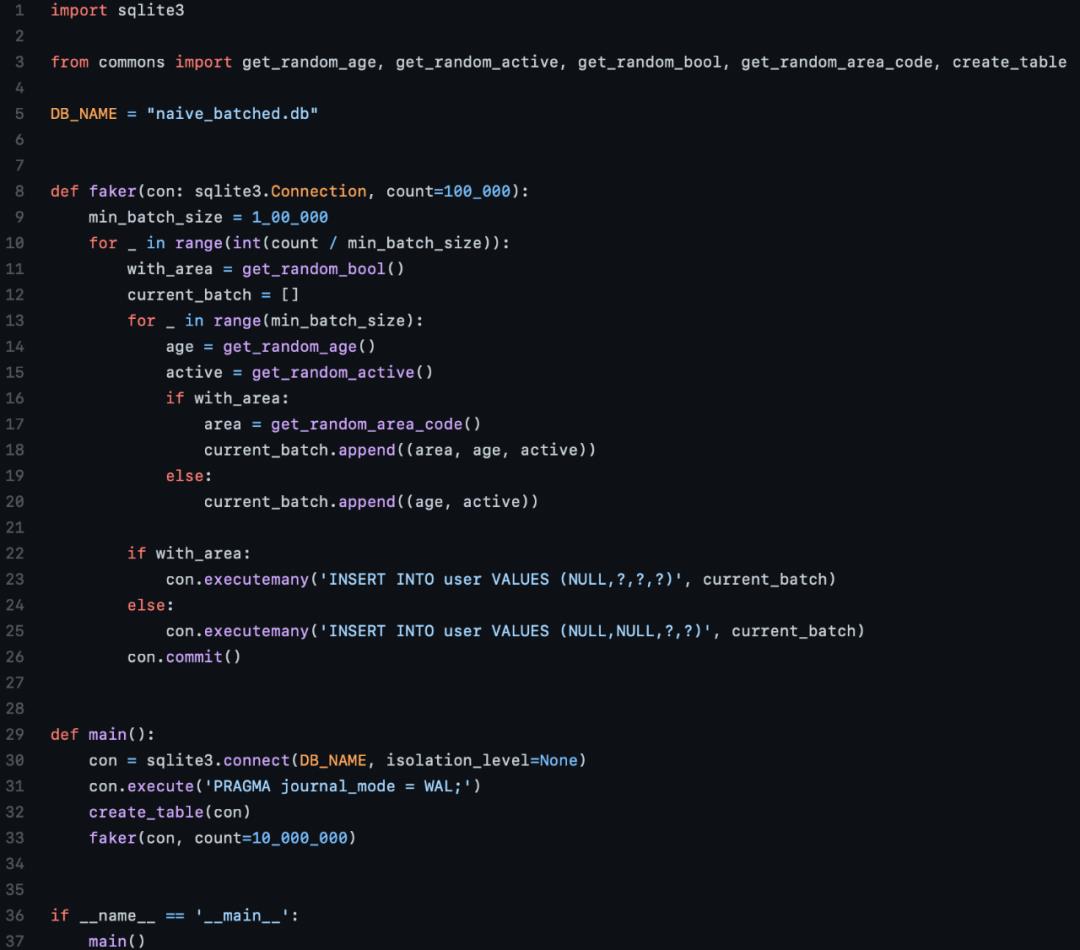
SQLite优化
作者认为自己写的代码已经很简练了,并没有什么可以优化的空间。
于是他将下一个目标转到了数据库的优化。
根据各种关于SQLite优化的建议,作者做了一些改进。
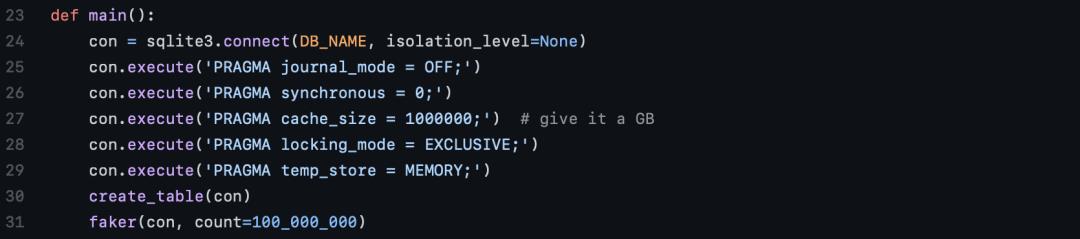
关闭「journal_mode」将禁用回滚日志,也就是说,如果任何事务失败,都无法回滚。
关闭「synchronous」,将使SQLite不再关心是否能可靠地写入磁盘,而是把这个责任交给操作系统。也就是说,可能会出现SQLite并没有成功写入磁盘的情况。
「cache_size」指定了SQLite在内存中可以保留多少个内存页。
当「locking_mode」为「EXCLUSIVE」模式时,SQLite锁住的连接将永远不会被释放。
将「temp_store」设置为「MEMORY」可以让其表现像一个内存数据库。
此处作者提醒,请不要把这些操作用到生产上去。
重新审视Python
作者再次重写了Python脚本,这次包括了微调的SQLite参数,这次带来了巨大的提升,运行时间大幅减少:
原始的for循环版本用时大约10分钟。
批处理版本用时大约8.5分钟。
PyPy
PyPy在其主页上强调它比CPython快4倍,于是作者决定尝试一下。
令作者有些意外的是,竟然不需要对现有的代码进行任何改动,只需要在PyPy运行就可以了。
批处理版本只需要2.5分钟,也就是速度快了接近3.5倍。
Busy Loop?
莫非是在Python的循环上耗费了太多时间?于是作者删除了SQL指令之后再次跑了一遍代码:
批处理版本在CPython中用时5.5分钟。
批处理版本在PyPy中用时1.5分钟(又是3.5倍的速度提升)。
然而用Rust重写了相同的内容之后,循环只需要17秒。
于是,作者果断抛弃Python,转投Rust的怀抱。
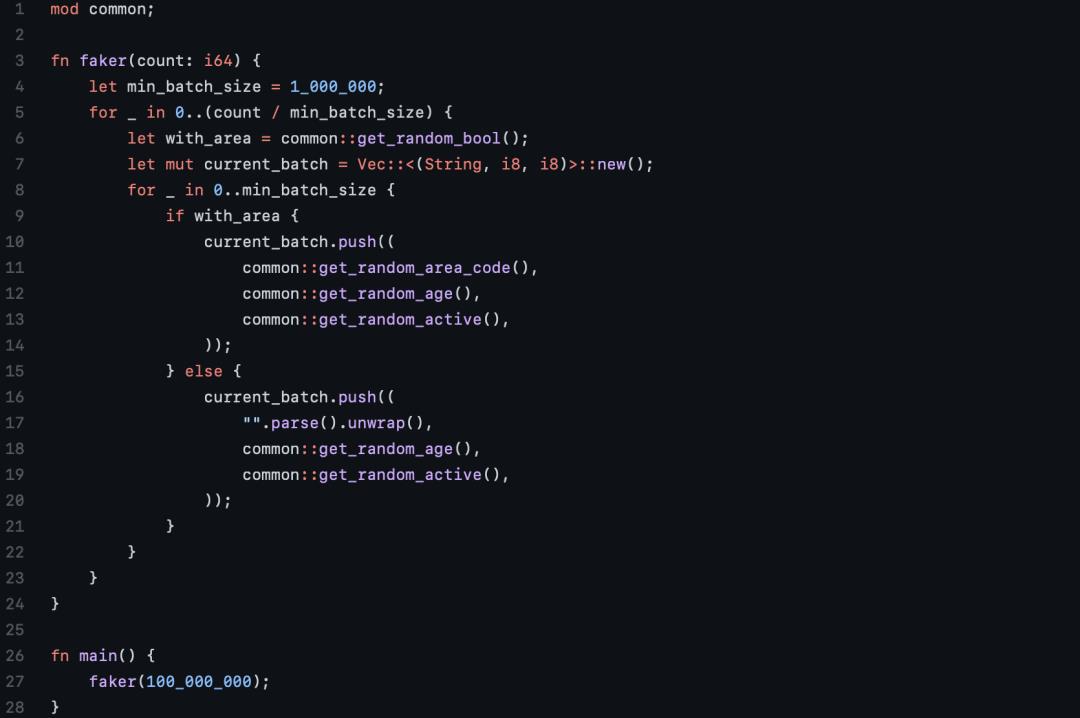
Rust
像Python一样,作者先写了一个原始的Rust版本,一个循环执行一行数据的插入。
然而,即便使用了所有SQLite的优化,也依然消耗了大约3分钟。于是作者进行了进一步的测试:
尝试把「rusqlite」换成异步运行的「sqlx」,这让用时直接被拉到了14分钟。作者表示,这比自己迄今为止写的任何一个Python迭代都要差。
在执行原始SQL语句时,使用准备好的语句。这个版本的用时只有1分钟。
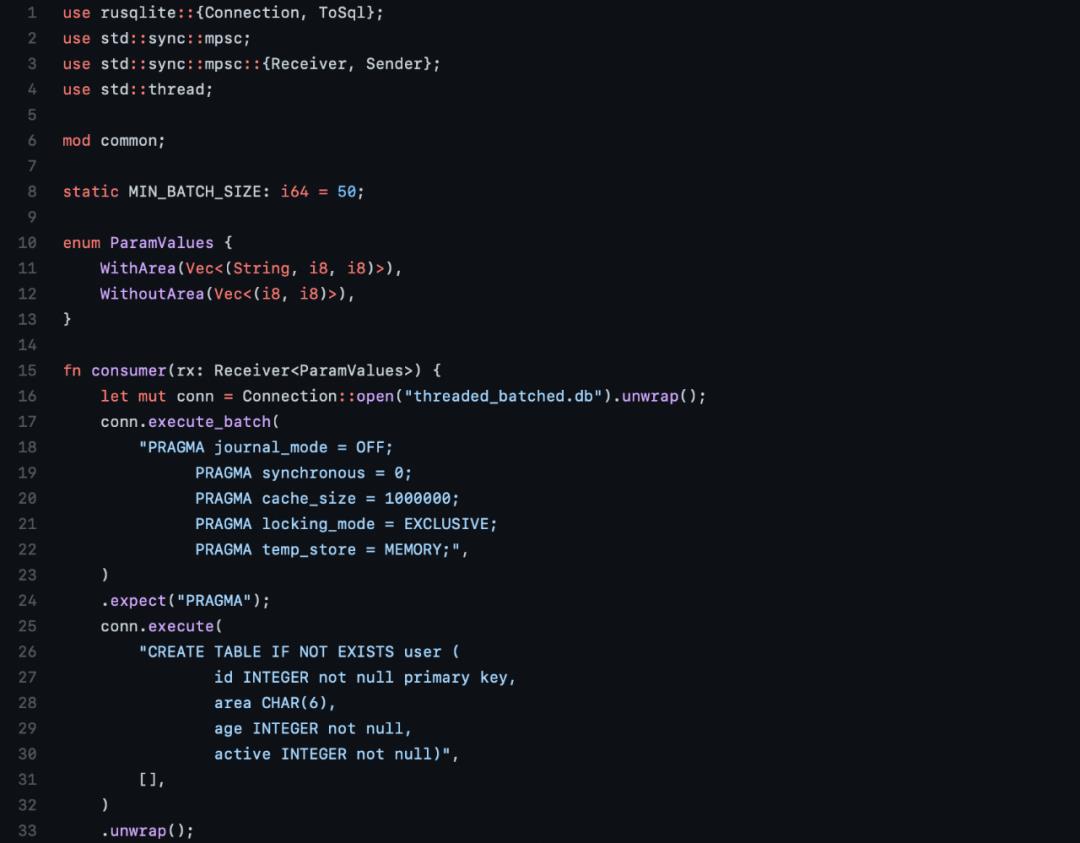
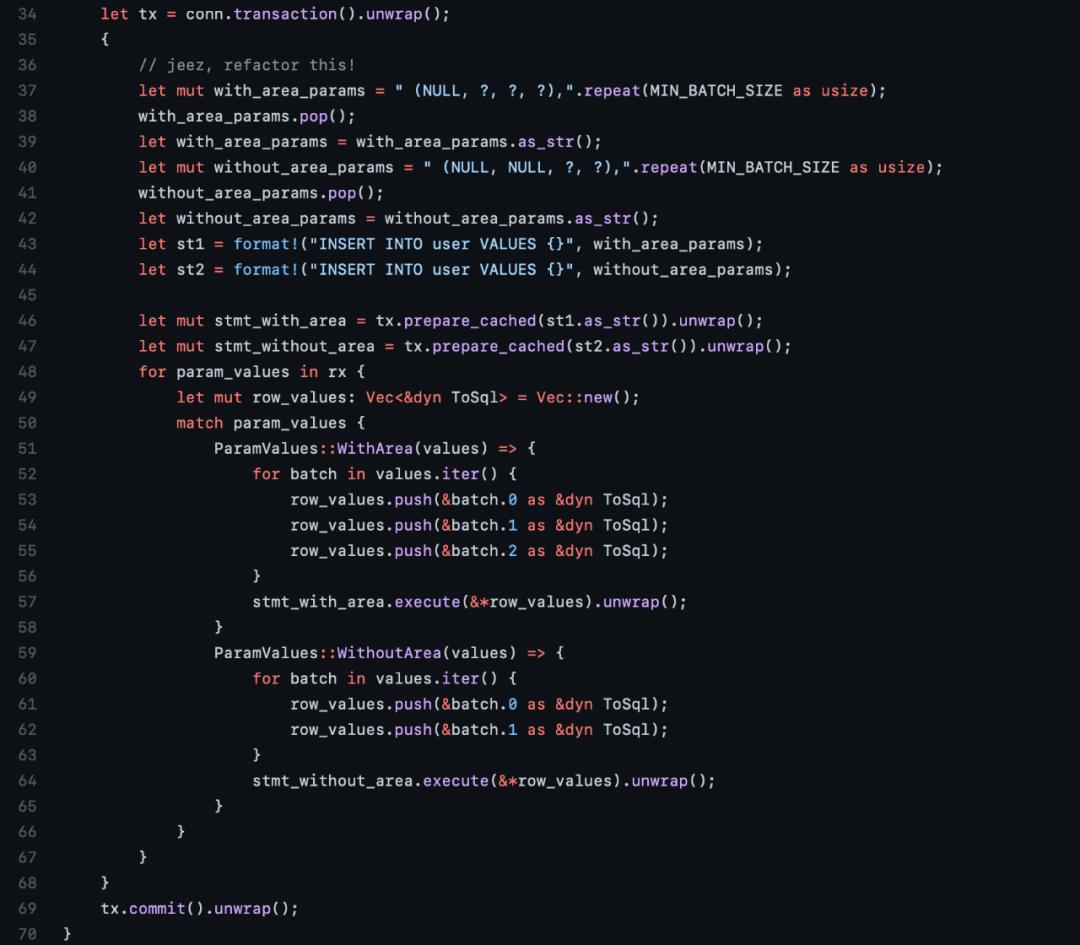
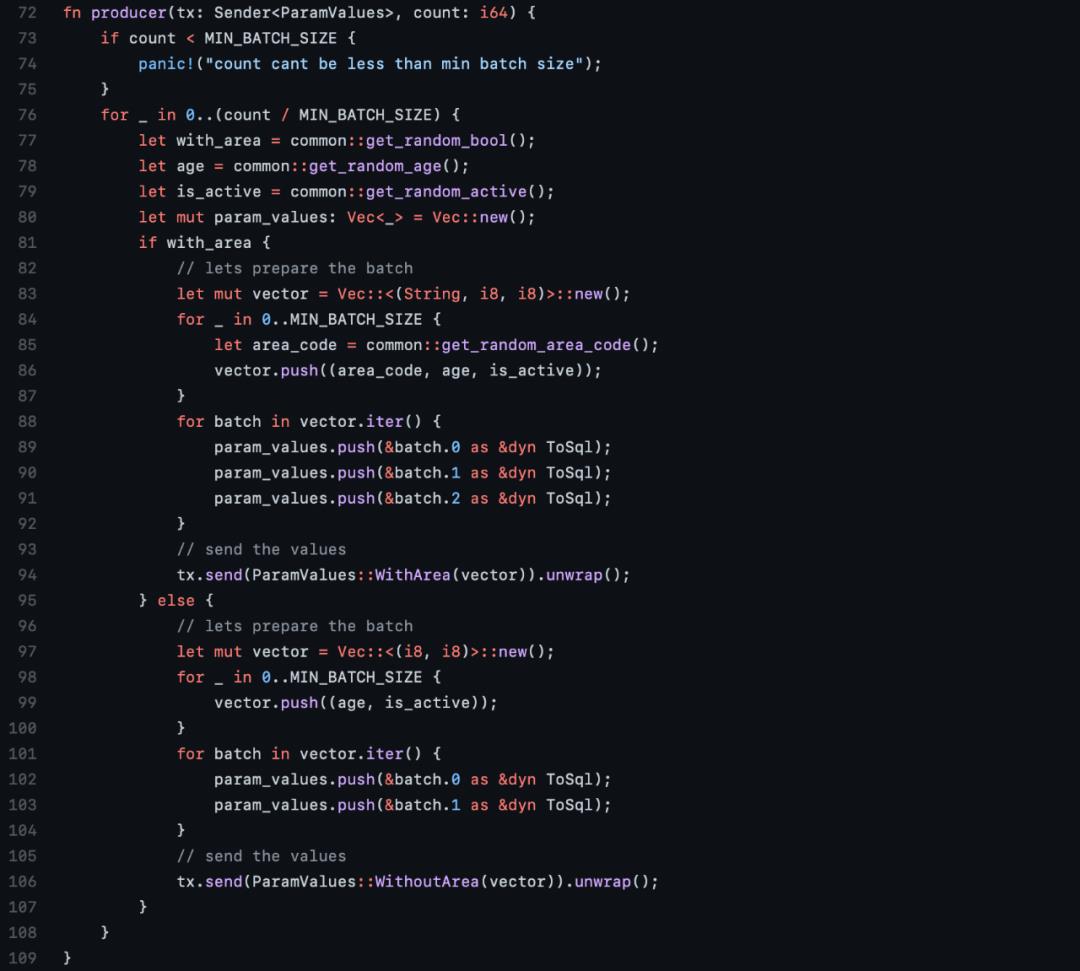
最优的版本
使用准备好的语句,以50行为一个批次插入,最终用时34.3秒。
作者又写了一个线程版本,其中一个线程从通道接收数据,还有四个线程向通道推送数据。
这个也是目前性能最好的版本,最终用时大约32.37秒。

IO时间
SQLite论坛上的网友提出了一个有趣的想法:测量内存数据库所需的时间。
于是作者又跑了一遍代码,将数据库的位置设定为「:memory:」,rust版本完成的时间少了两秒(29秒)。
也就是说将1亿条记录写入到磁盘上需要2秒,这个用时似乎也是合理的。
这也说明,可能没有更多的SQLite优化可以以更快的方式写入磁盘,因为99%的时间都花在生成和添加数据上。
排行榜
插入1亿行数据的用时:
| Rust | 33秒 |
| PyPy | 126秒 |
| CPython | 210秒 |
总结
尽可能使用SQLite PRAGMA语句
使用准备好的语句
进行分批插入
PyPy确实比CPython快4倍
异步不一定更快
目前,第二快的版本是单线程运行的,而作者的电脑有4个核心,于是他在一分钟内可以得到8亿行数据。然后再经过几秒钟的数据合并,时间仍然可以少于一分钟。
网友评论
博主的这一番研究获得了网友们的一致好评。

真的很喜欢这些观点:
学习了更多关于PRAGMA语句。
PyPy的效率和灵活性可以通过即插即用的方式体现(将来一定会给它一个机会)。
文章的排版非常简单,有适当的源代码链接。很有趣,很容易上手。
Rust高光时刻又来了!
参考资料:
https://avi.im/blag/2021/fast-sqlite-inserts/
https://github.com/avinassh/fast-sqlite3-inserts
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于抛弃Python?1分钟插入10亿行数据!的主要内容,如果未能解决你的问题,请参考以下文章
1分钟插入10亿行数据!抛弃Python,写脚本请使用Rust
如何使用 AWS 快速对 100 亿行 SQL 表进行分区?