从0到1Flink的成长之路- Flink 原理探析接着干干干
Posted 熊老二-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1Flink的成长之路- Flink 原理探析接着干干干相关的知识,希望对你有一定的参考价值。
Slot Sharing
By default, Flink allows subtasks to share slots even if they are subtasks of
different tasks, so long as they are from the same job.
Slot可以被多个SubTask共享使用,需要满足一下条件:
SubTask必须是不同Task,也就是说一个Slot中的SubTask属于不同Operator操作;
SubTask属于一个Job中任务,必须是一个Job中不同SubTask。
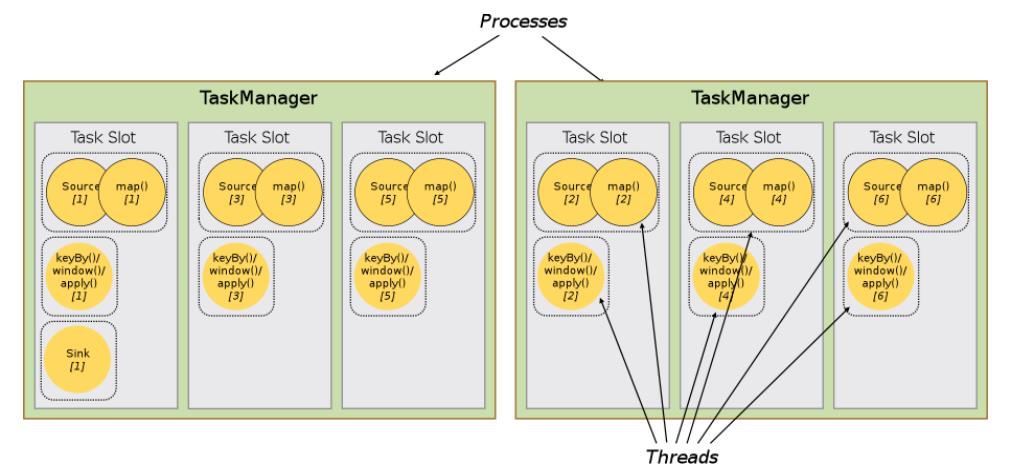
Slot共享主要的好处有以下几点:
可以起到隔离内存的作用,防止多个不同job的task竞争内存;
Slot个数就代表了一个Flink程序的最高并行度,简化了性能调优的过程;
允许多个Task共享Slot,提升了资源利用率。举一个实际的例子,kafka有3个partition,对应
flink的source有3个task,而keyBy设置的并行度为20,这个时候如果Slot不能共享的话,需要
占用23个Slot,如果允许共享的话,只需要20个Slot即可(Slot默认共享规则计算为20个);
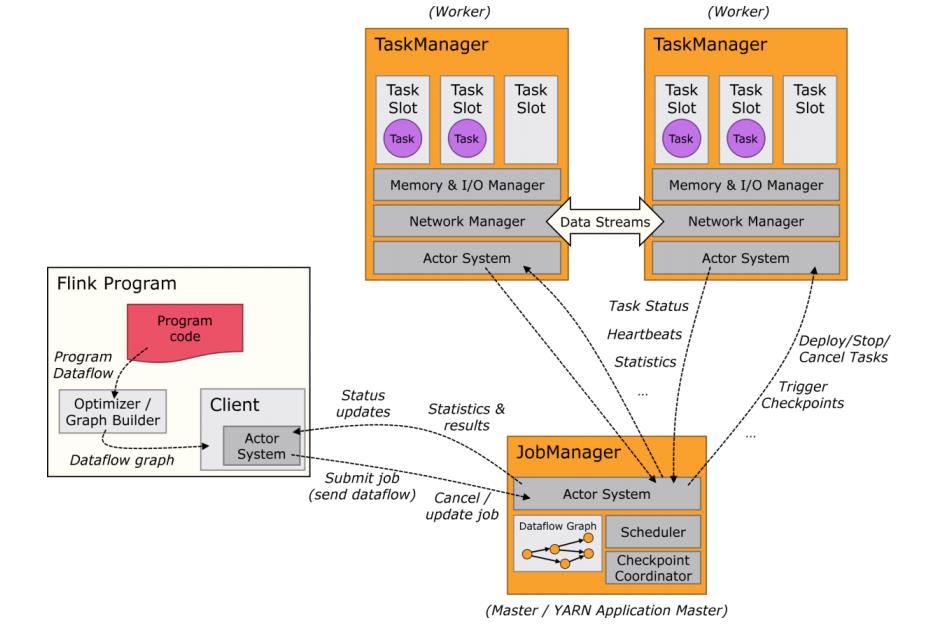
综上所述,运行Flink Job时涉及到所有核心组件,如下图所示:
Execution Graph
由Flink程序直接映射成的数据流图是StreamGraph,也被称为逻辑流图,因为它们表示的是
计算逻辑的高级视图。为了执行一个流处理程序,Flink需要将逻辑流图转换为物理数据流图(也
叫执行图),详细说明程序的执行方式。
package xx.xxxxxx.flink.concepts;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;
import java.util.Random;
import java.util.concurrent.TimeUnit;
public class StreamGraphDemo {
public static void main(String[] args) throws Exception {
// 1. 执行环境-env:本地执行环境,提供WEB UI界面,端口号8081
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(
new Configuration() );
env.setParallelism(2) ;
// 2. 数据源-source:自定义并行数据源
DataStreamSource<String> lines = env.addSource(new SourceFunction<String>() {
private boolean isRunning = true ;
@Override
public void run(SourceContext<String> ctx) throws Exception {
Random random = new Random() ;
String[] words = new String[]{"spark", "flink", "flink", "hive", "kafka"};
while (isRunning){
ctx.collect(words[random.nextInt(words.length)]);
TimeUnit.MILLISECONDS.sleep(200 + random.nextInt(1000));
}
}
@Override
public void cancel() {
isRunning = false ;
}
});
// 3. 数据转换-transformation:每10秒统计最近10秒每个用户访问量(滚动时间窗口)
SingleOutputStreamOperator<Tuple2<String, Integer>> sumStream = lines
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
out.collect(Tuple2.of(value, 1));
}
})
.keyBy(0)
.sum(1);
// 4. 数据终端-sink:打印控制台
sumStream.printToErr();
// 5. 触发执行-execute
env.execute(StreamGraphDemo.class.getSimpleName());
}
}
Flink中的执行图分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
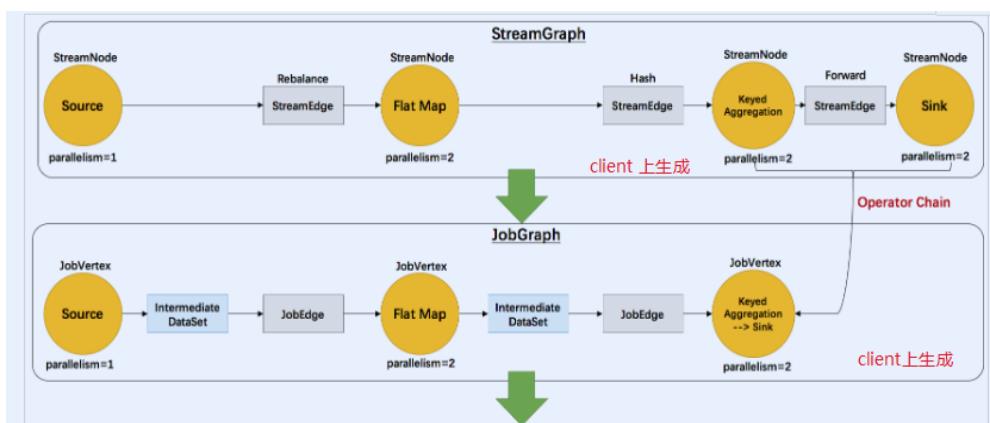

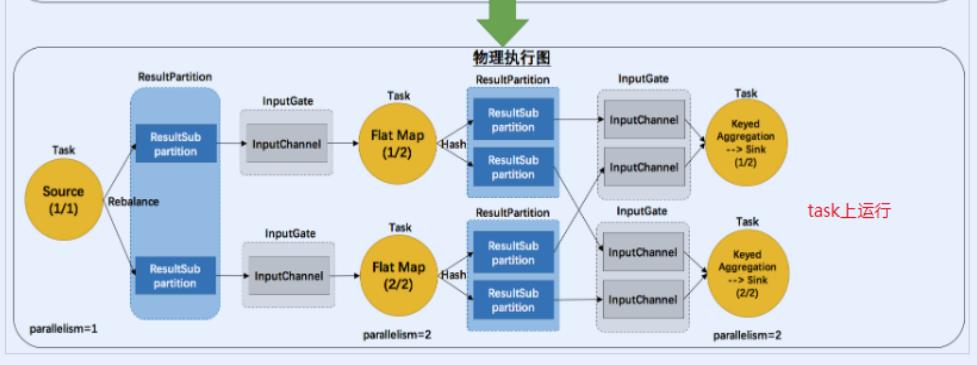
原理介绍
Flink执行executor会自动根据程序代码生成DAG数据流图
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物
理执行图。
StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。表示程
序的拓扑结构。
JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的
数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这
样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。
ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个
TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
简单理解:
StreamGraph:最初的程序执行逻辑流程,也就是算子之间的前后顺序(全部都是
Subtask)
JobGraph:将部分可以合并的Subtask合并成一个Task
ExecutionGraph:为Task赋予并行度
物理执行图:将Task赋予并行度后的执行流程,落实到具体的TaskManager上,将具体
的Task落实到具体的Slot内进行运行。
Components of a Flink Setup
Flink运行时架构主要包括四个不同的组件,它们会在运行流处理应用程序时协同工作。
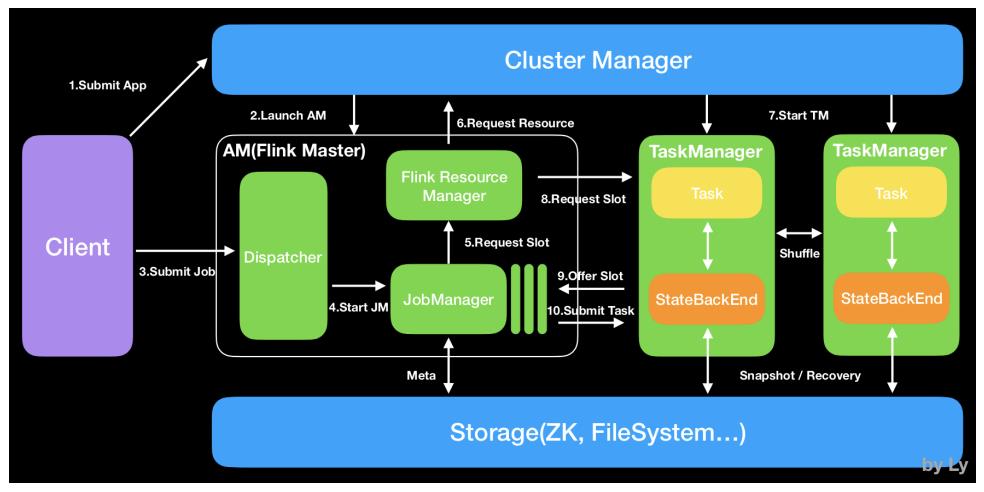
每个组件的职责如下:
作业管理器(JobManager)
控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的
JobManager 所控制执行。
JobManager 会先接收到要执行的应用程序,这个应用程序会包括:作业图
(JobGraph)、逻辑数据流图(logical dataflow graph)和打包了所有的类、库和其它
资源的JAR包。
JobManager 会把JobGraph转换成一个物理层面的数据流图,这个图被叫做“执行图”
(ExecutionGraph),包含了所有可以并发执行的任务。
JobManager 会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是
任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执
行图分发到真正运行它们的TaskManager上。而在运行过程中,JobManager会负责所有
需要中央协调的操作,比如说检查点(checkpoints)的协调。
任务管理器(TaskManager)
Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每1个TaskManager都包
含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。
启动之后,TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,
TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向
插槽分配任务(tasks)来执行了。
在执行过程中,1个TaskManager可以跟其它运行同一应用程序TaskManager交换数据。
资源管理器(ResourceManager)
主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger 插槽是Flink中
定义的处理资源单元。
Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、Mesos、K8s,
以及standalone部署。
当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分
配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,
它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。
分发器(Dispatcher)
可以跨作业运行,它为应用提交提供了REST接口。
当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。
Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。
Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
以上是关于从0到1Flink的成长之路- Flink 原理探析接着干干干的主要内容,如果未能解决你的问题,请参考以下文章