ubuntu安装es(elesticSearch),es结构介绍,IK分词器的简单使用,es入门增删改查api,结果集高亮
Posted 好大的月亮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ubuntu安装es(elesticSearch),es结构介绍,IK分词器的简单使用,es入门增删改查api,结果集高亮相关的知识,希望对你有一定的参考价值。
1-下载安装包
大家可以自己选择一个版本安装
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-3-0
解压后再bin下启动es,然后内存不满足es的要求启动报错了
./elasticsearch
临时解决方案(重启失效),在root下
sysctl -w vm.max_map_count=262144
或者在/etc/sysctl.conf文件最后添加一行,永久生效
vm.max_map_count=262144
然后es需要启动用户的最大文件打开数量至少65536也给加上
vim /etc/security/limits.conf
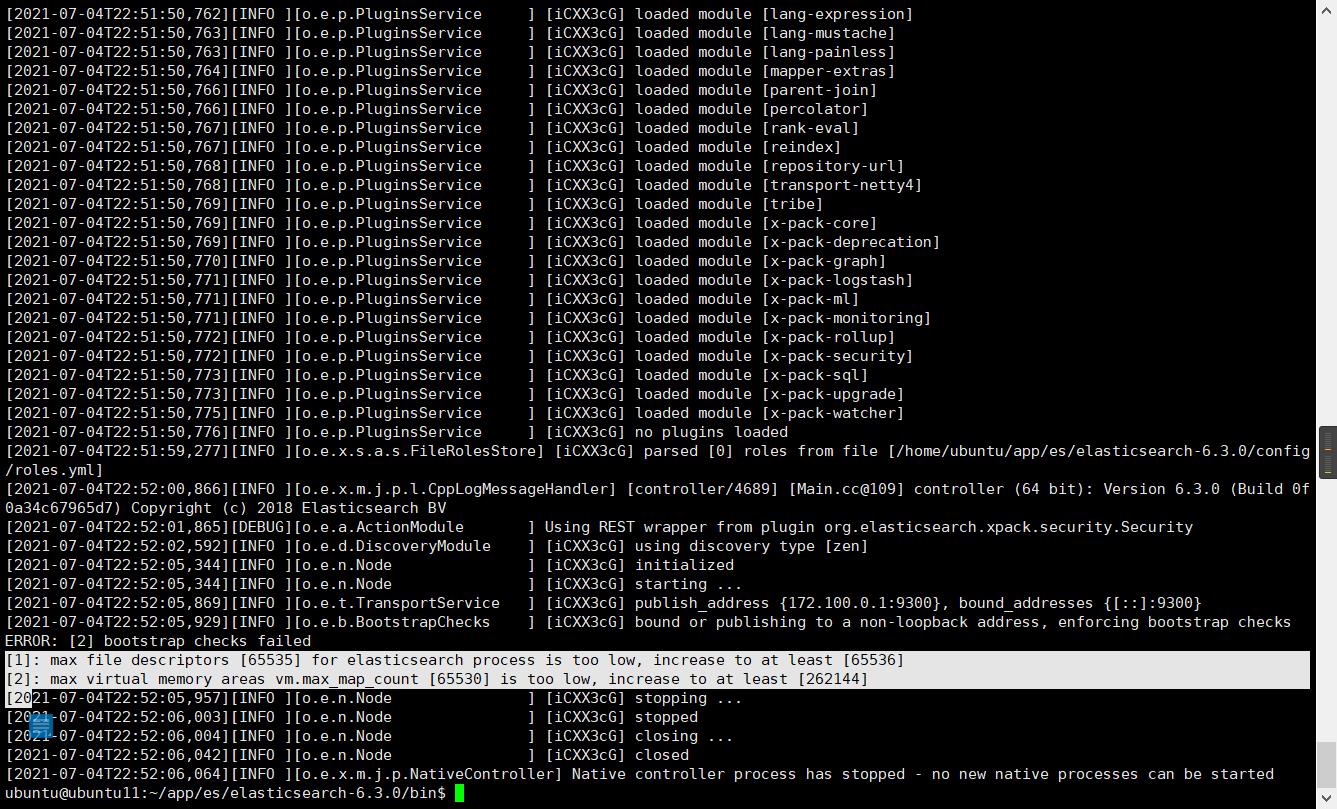
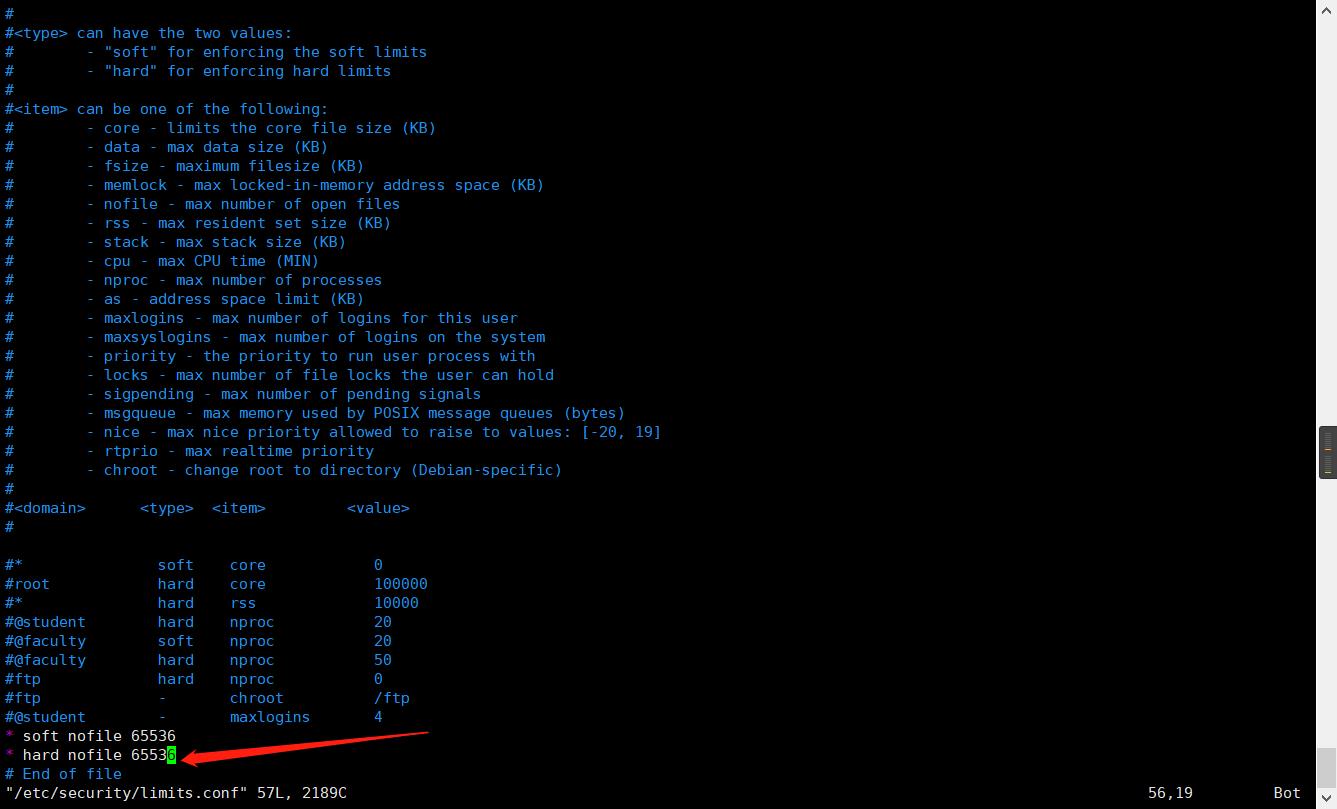
这两个搞定后就启动成功了
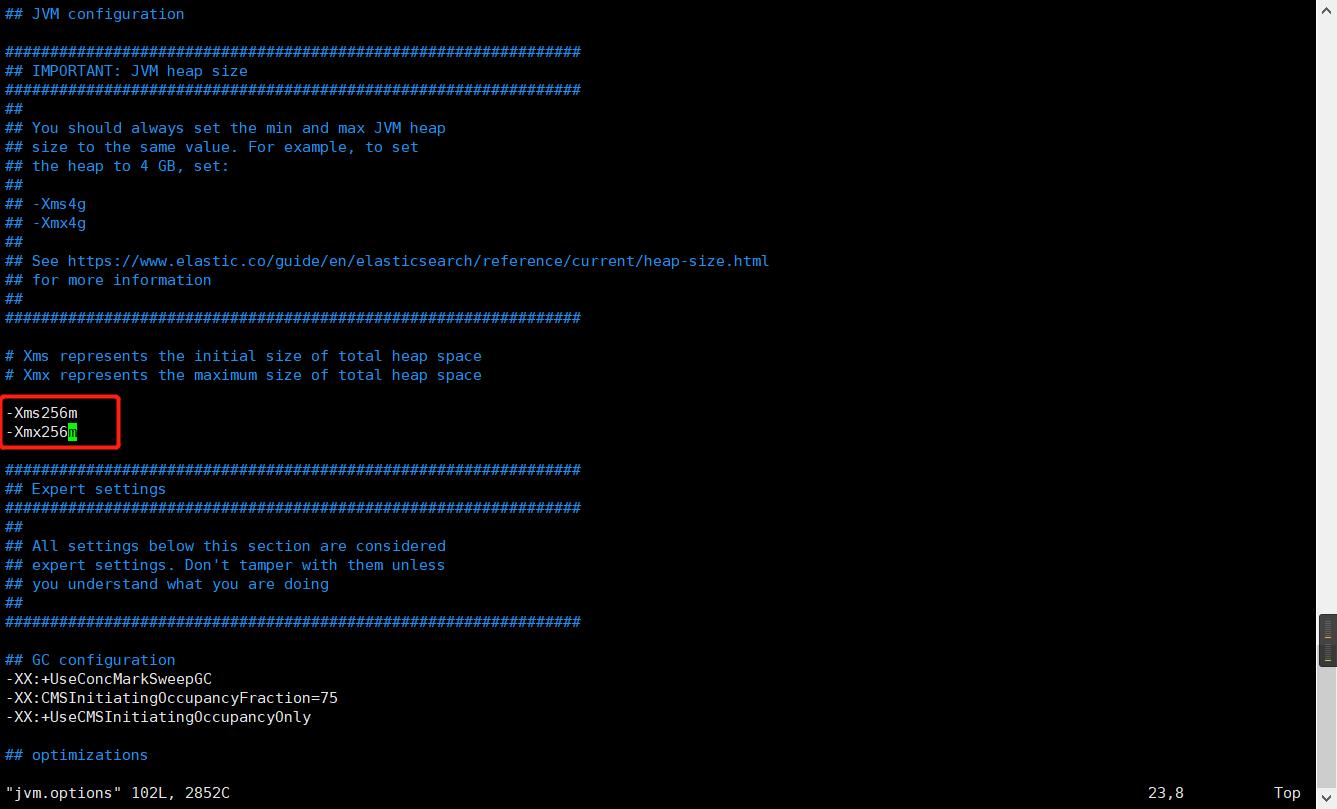
还可以根据实际服务器的情况调整es启动的时候的需要的内存参数

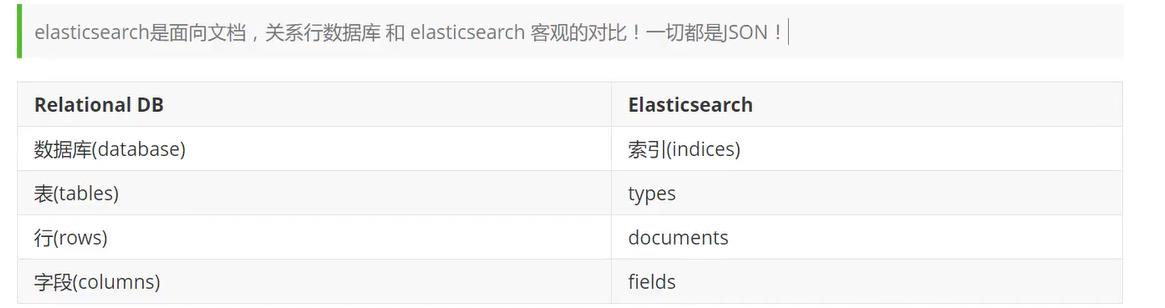
elesticSearch时候面向文档的,和传统关系型数据库的对比
es的文档
ES中的文档其实就是mysql中表里的一行数据,并且es是面向文档的,即文档是它搜索的最小单位。
文档的几个特性:
- 自我包含,一个文档(一行json数据),同时有key和value,类似mongodb里的document。因此搜索key:value的时候就可以搜索到这个文档。
- 层次性,也就是可以嵌套json对象,比如一个key的value是一个json对象。
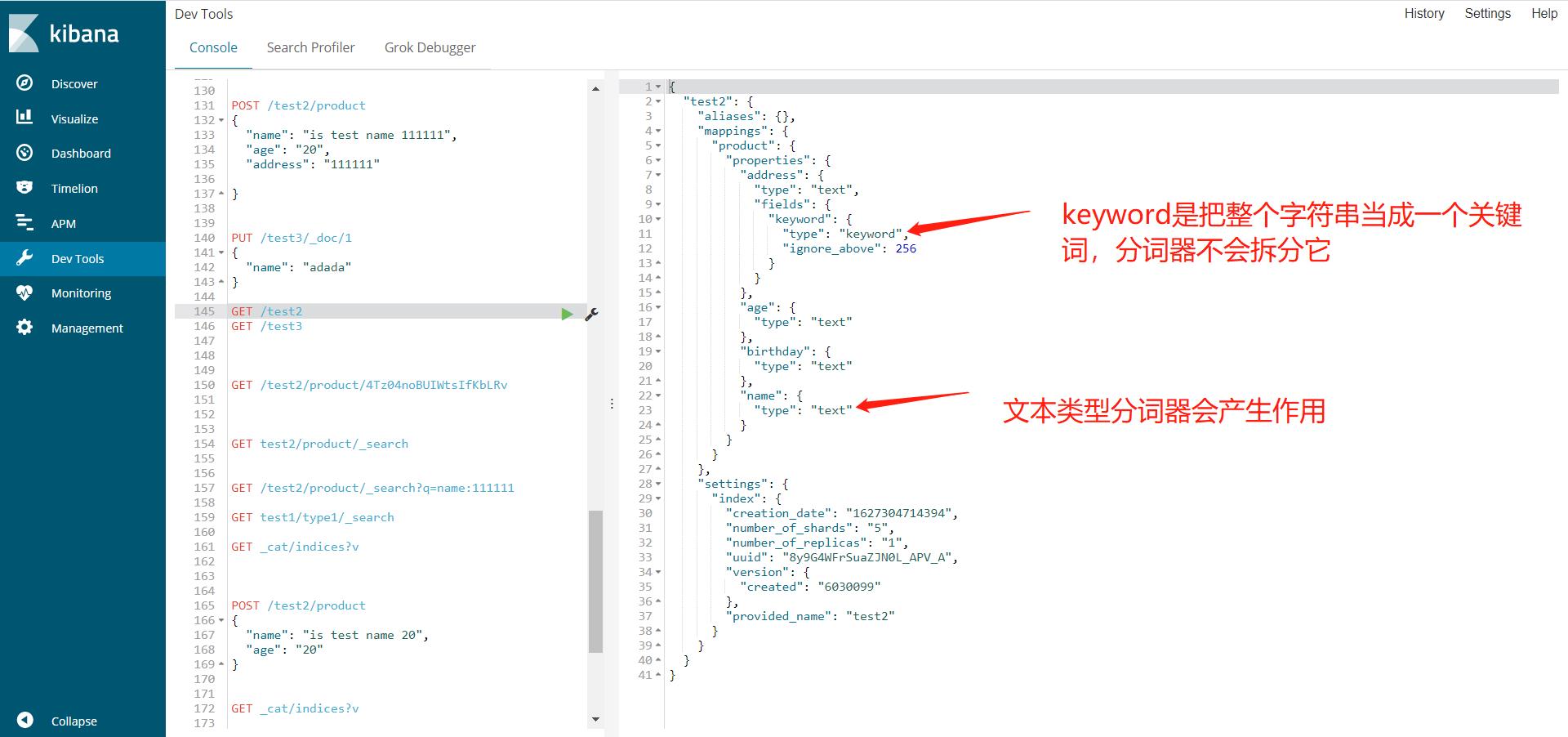
- 灵活的结构,不需要想mysql一样预先定义好字段。es可以动态的添加字段或者忽略一个字段。但是字段的类型非常的重要,es会保存字段和类型之间的映射。
ES的类型
就是类似java中的基本类型的声明,比如string在es里是text文本类型。
也类似mysql中表里的字段的类型,varchar,int,date等。
ES的索引,倒排索引
就是mysql中的数据库。
es的倒排索引采用的是Lucene的倒排索引。一个索引由文档中所有不重复的列表组成。类似mysql中每个非聚簇唯一索引都是来自表里的行中的某个字段,并且这个索引内容都没有重复。
创建倒排索引需要将每个文档拆分成独立的词,然后创建一个包含所有不重复的词条的排序列表,然后列出每次词条在哪个文档。
搜索一句话的时候会检查这句话里的词在哪个文档的命中更高,也就是权重更高。
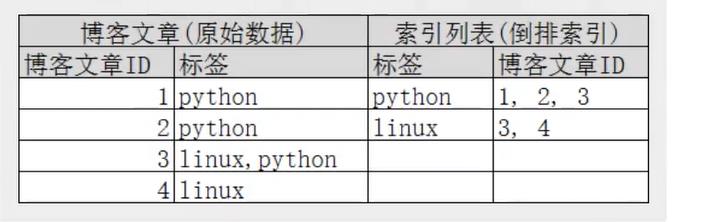
倒排索引简单来说就是把文档中的内容整合后形成的索引,搜索的时候根据这个倒排索引就可以找到es索引中的那些个记录了,有点类似,mysql中的非聚簇索引,根据索引找到id,然后就可以找到这些个id对应的整行的数据。
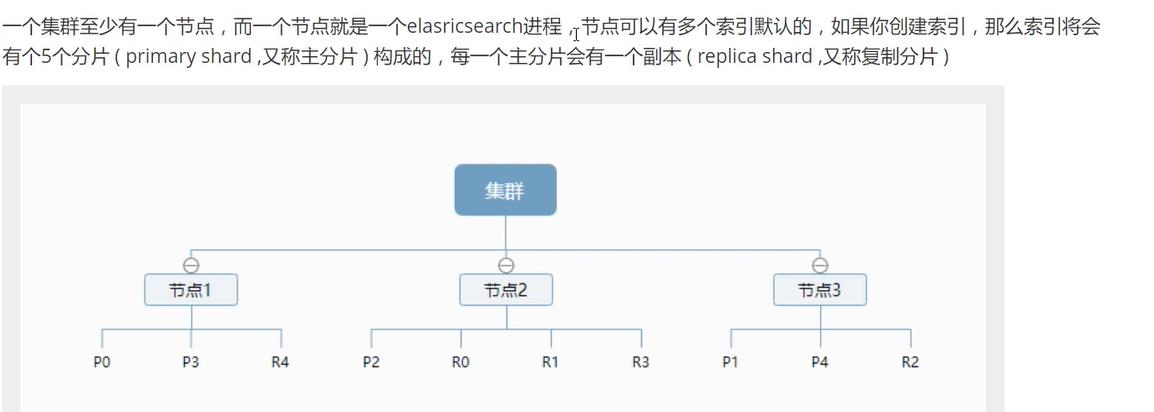
索引的分片和节点
索引的分片会分布在集群的不同节点中,防止一个节点挂掉的时候数据丢失,每个主分片都有一个复制分片,并且两者都不会在同一个节点内。
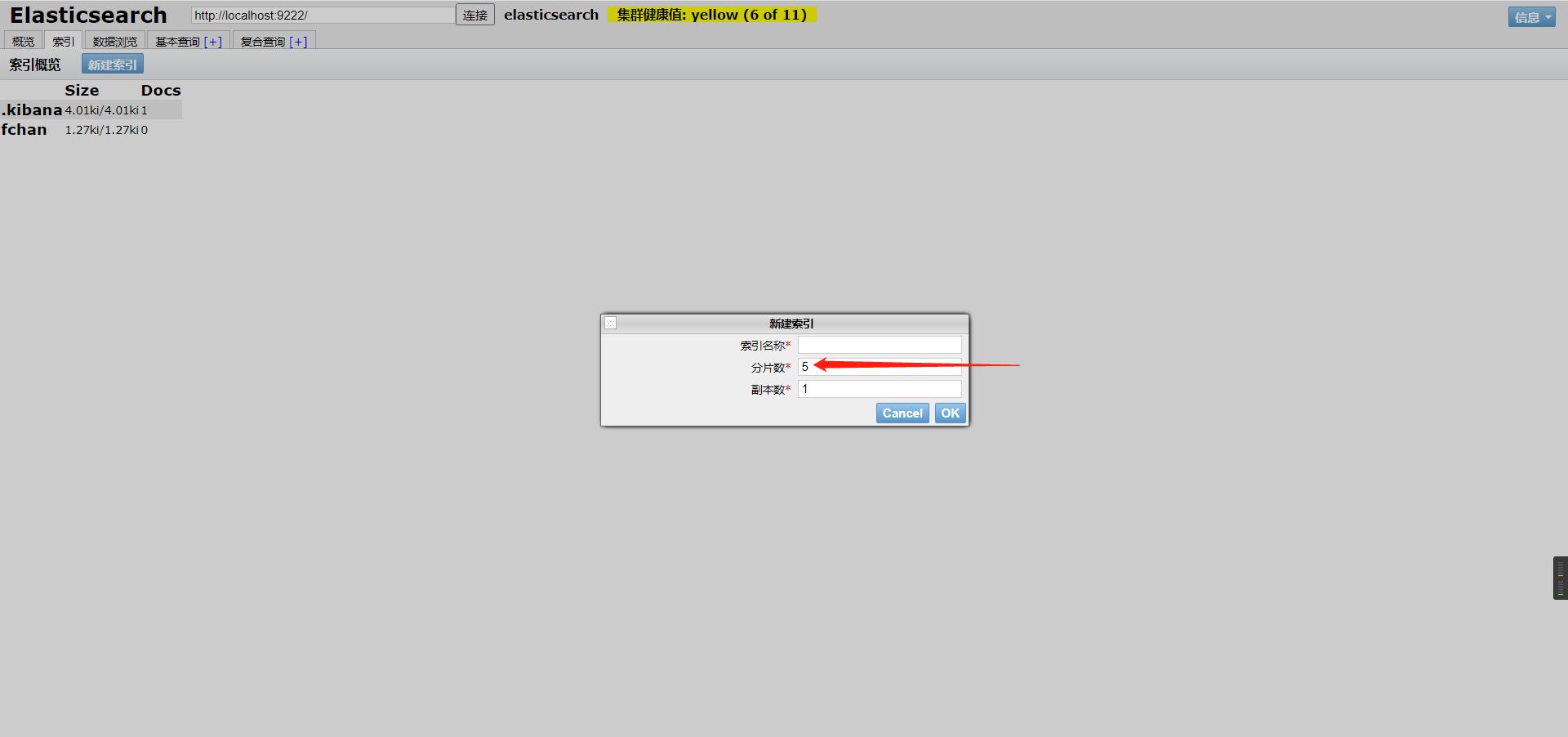
demo
举个esheade可视化界面中新建索引时的例子
IK分词器(中文分词)下载安装
即把一段中文划分成一个个关键字,默认的中文分词器会将每个字看成一个词,比如,“其味无穷二”会被分成“其”“味”“无”“穷”“二”,这显然是不对劲的,所以需要安装中文分词器来解决这个问题。其中IK分词器就是推荐的一种。
IK提供了2个分词算法:ik_smart和ik_max_word,其中ik_smark为最少切分,ik_max_word为最细粒度划分。
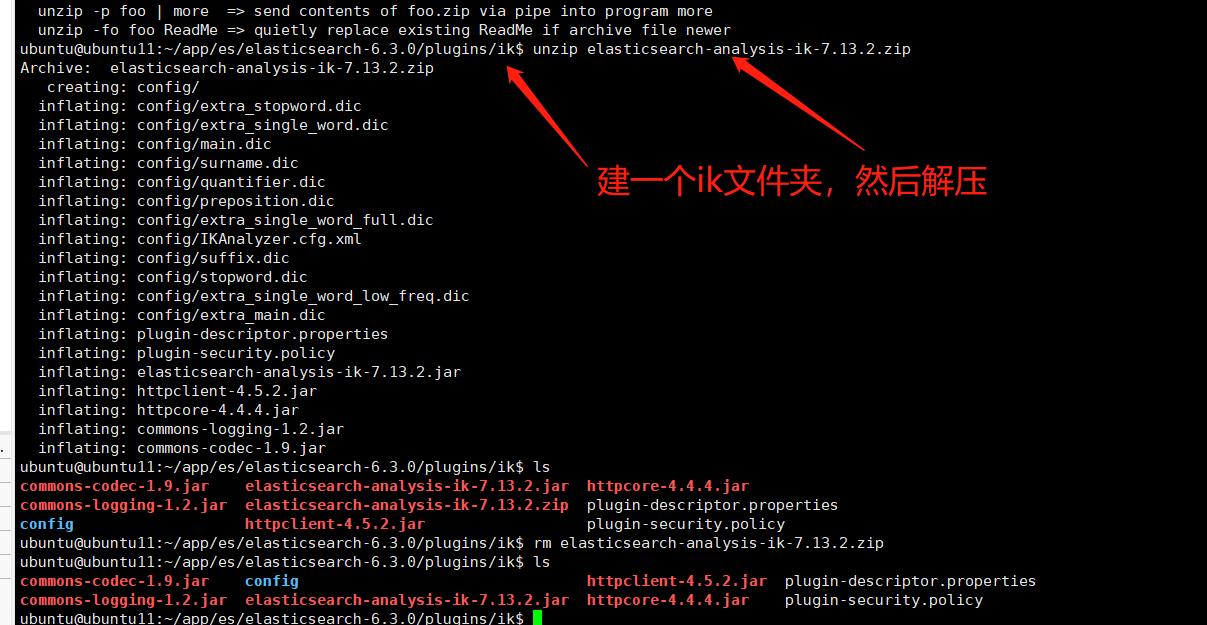
下载最新的包(注意和es的版本一致),放入elesticsearch的插件中,解压好后重启下es
https://github.com/medcl/elasticsearch-analysis-ik/releases
重启后发现已经被加载了
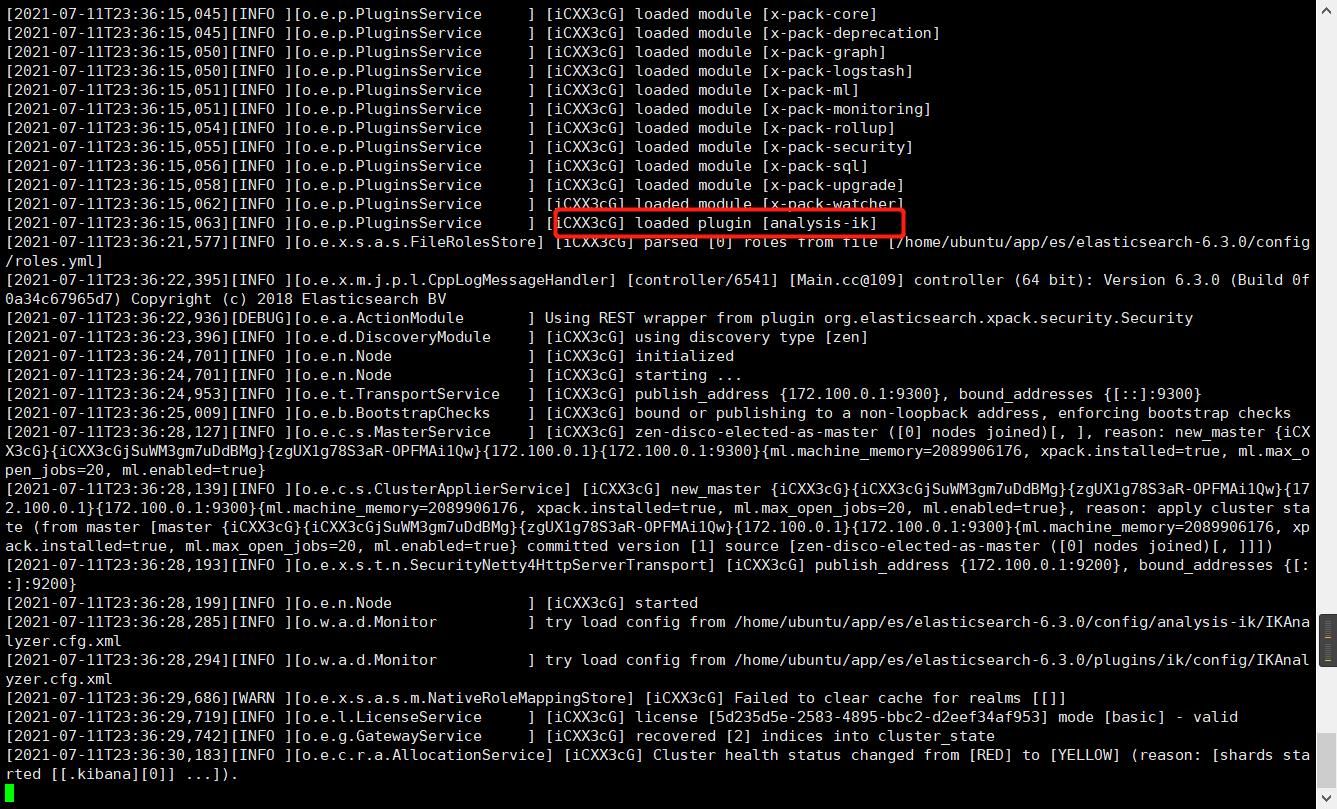
查看已经加载的所有插件
./elasticsearch-plugin list

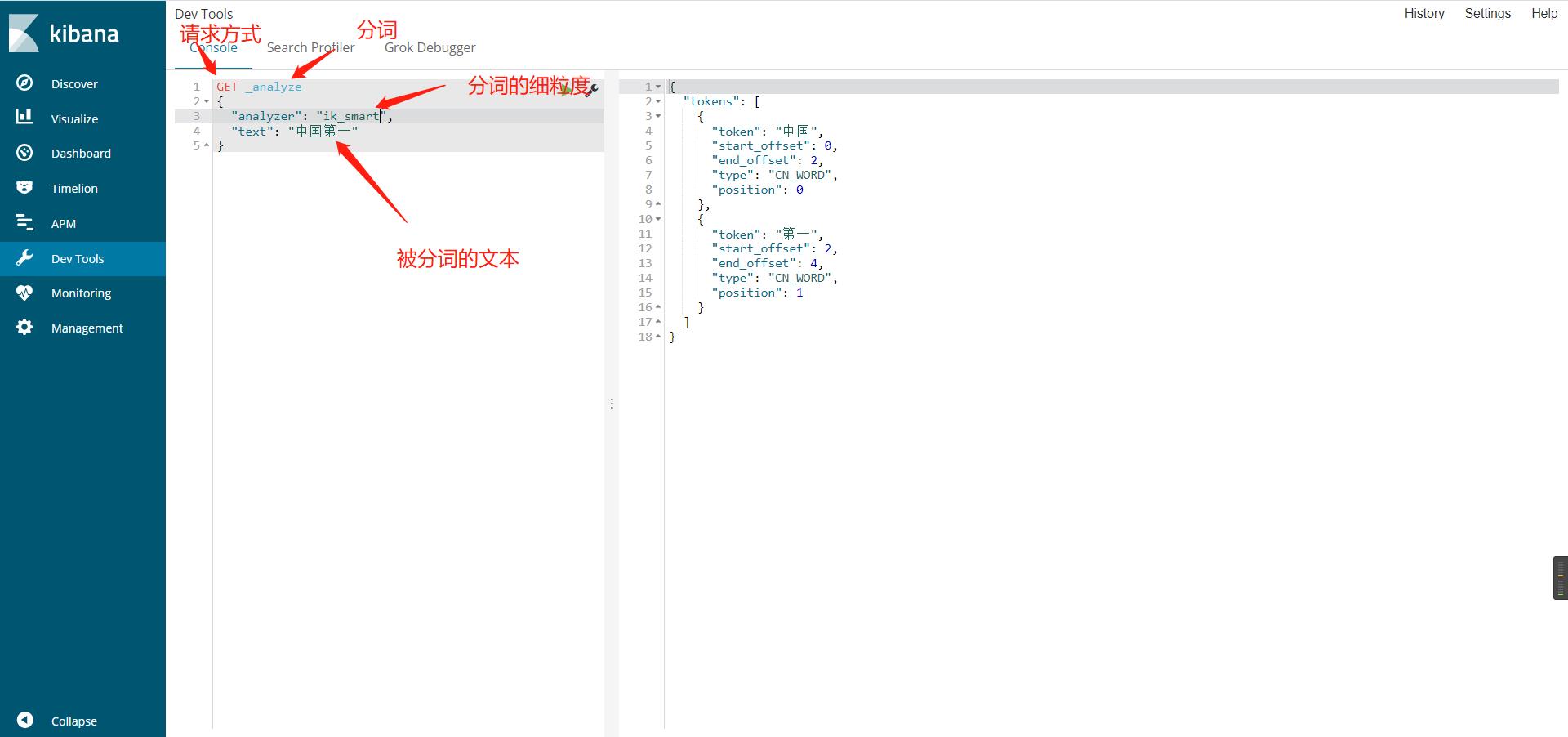
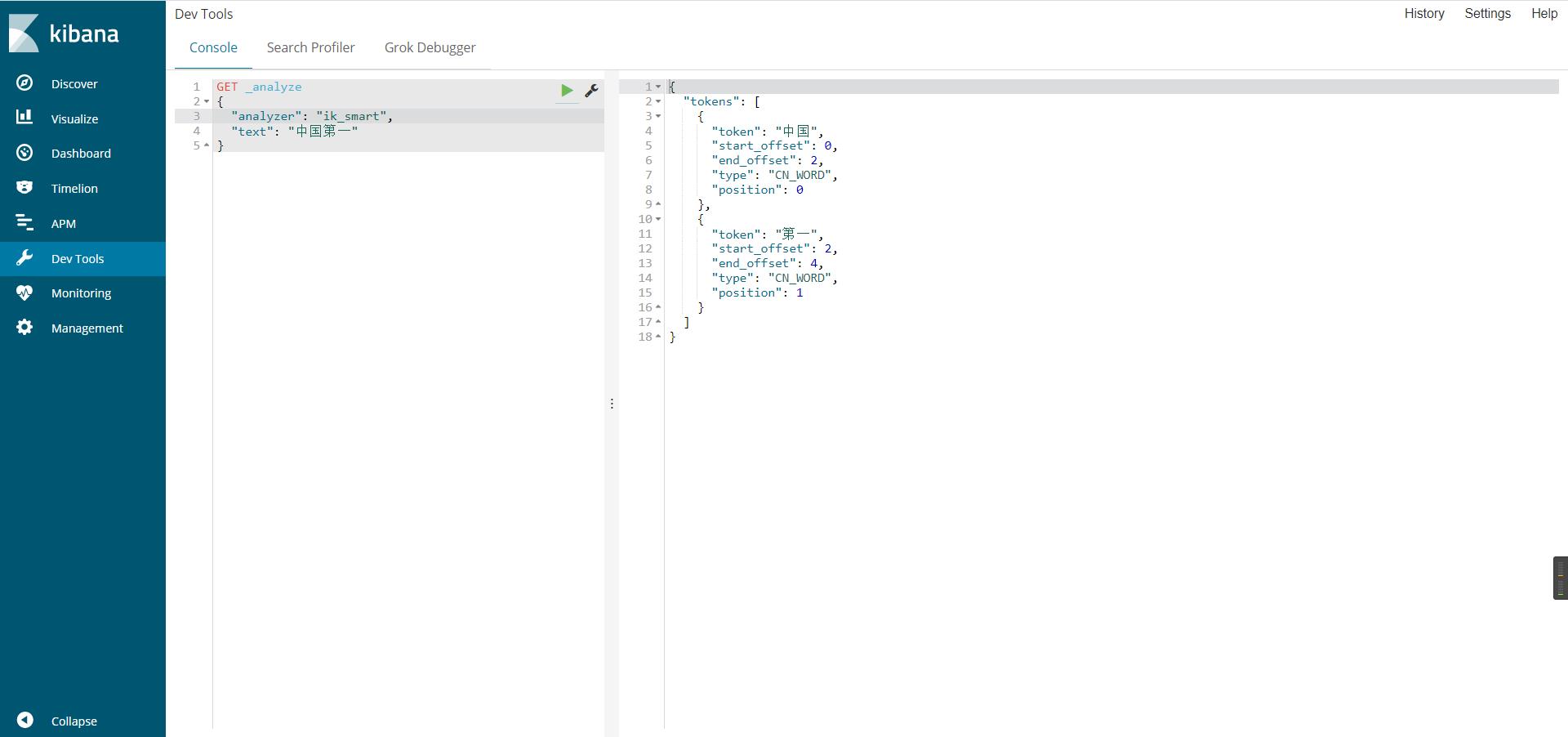
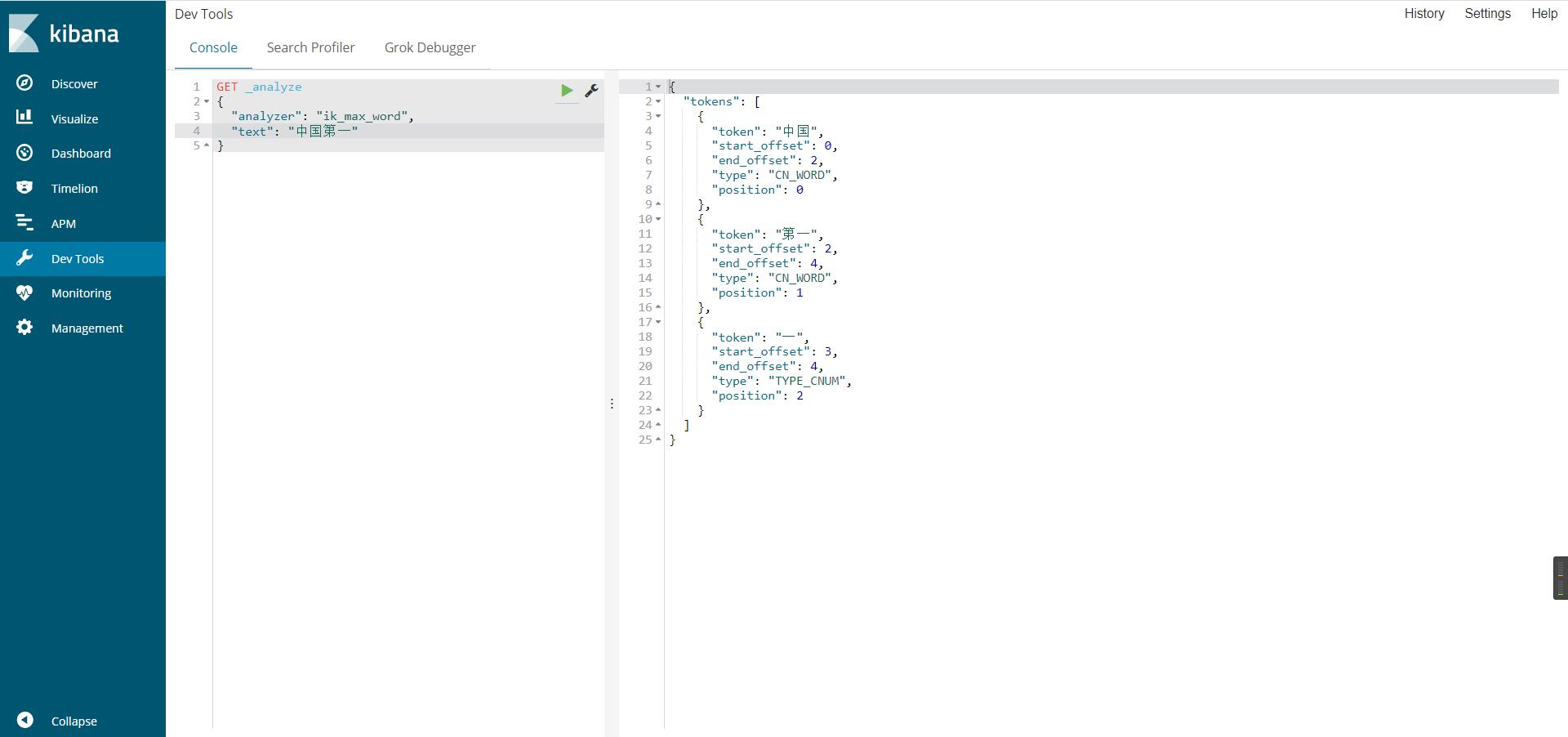
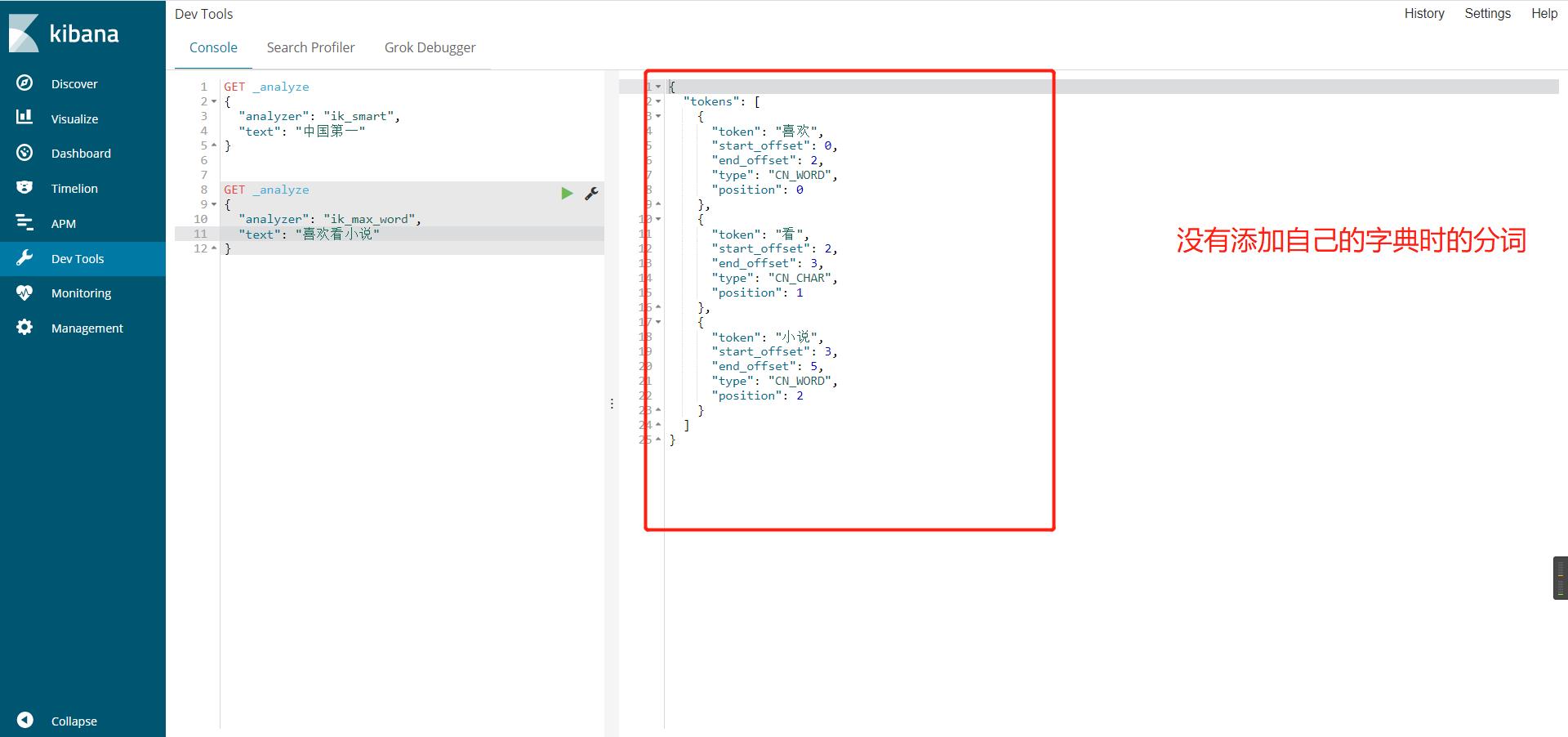
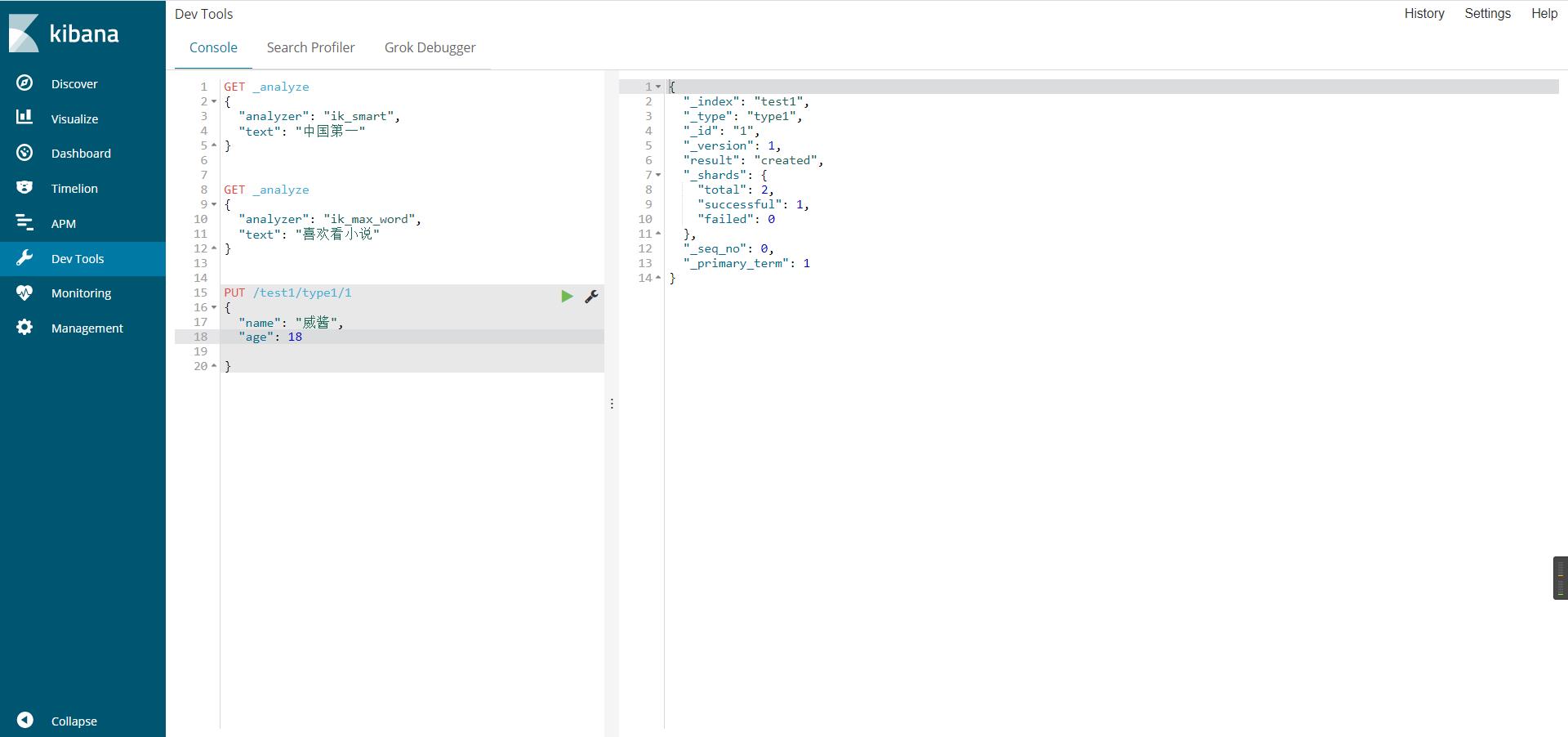
使用kibana测试ik分词器(ik_smart/ik_max_word)
ik_smart最小粒度划分,分个大概,粗略划分
ik_max_word穷尽词库(字典)的可能,分的最细
在IK分词器中添加自己的词语
因为默认的IK分词器分出来的词语不一定是自己想要的组合,这个时候就需要自己往里面添加了,添加一个自己的字典,然后设置进去IKAnalyzer.cfg.xml就可以了
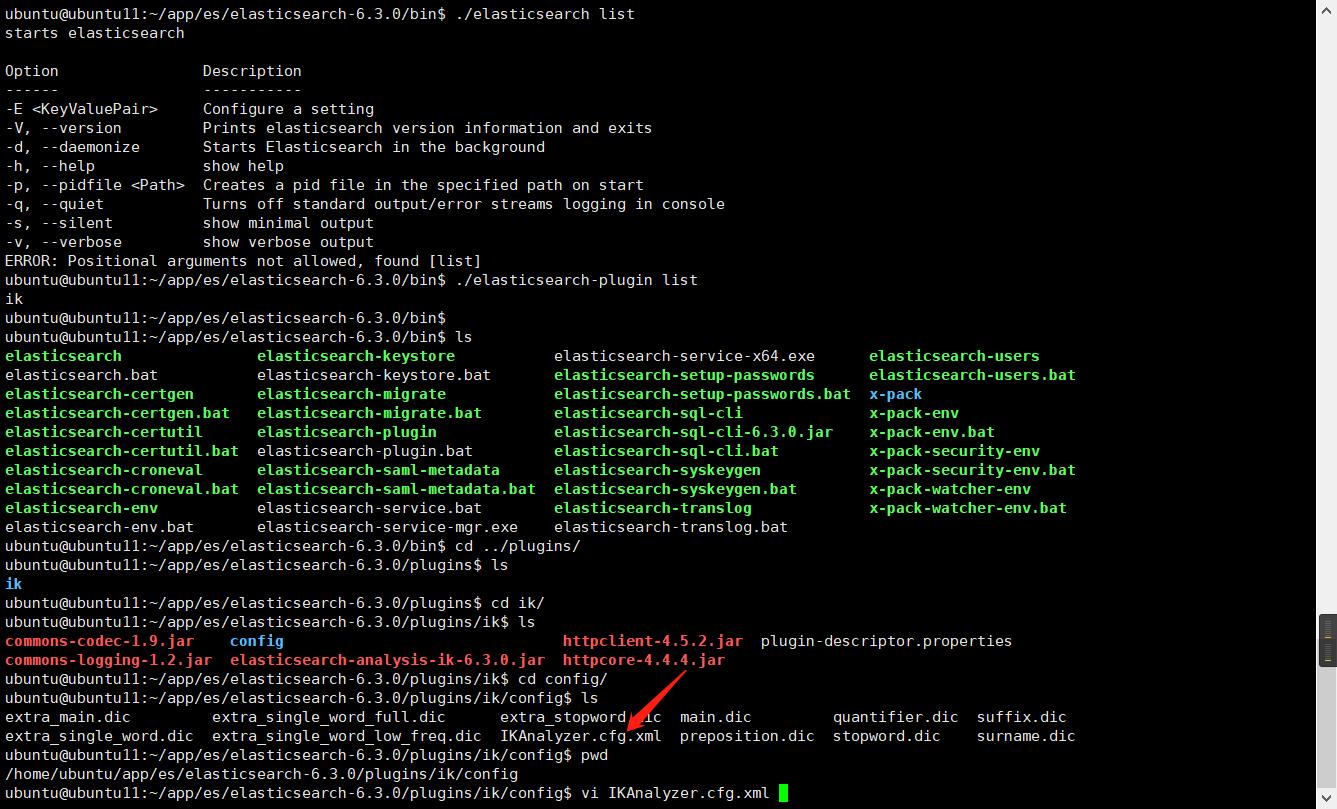
添加自己的字典

配置自己的字典到配置文件
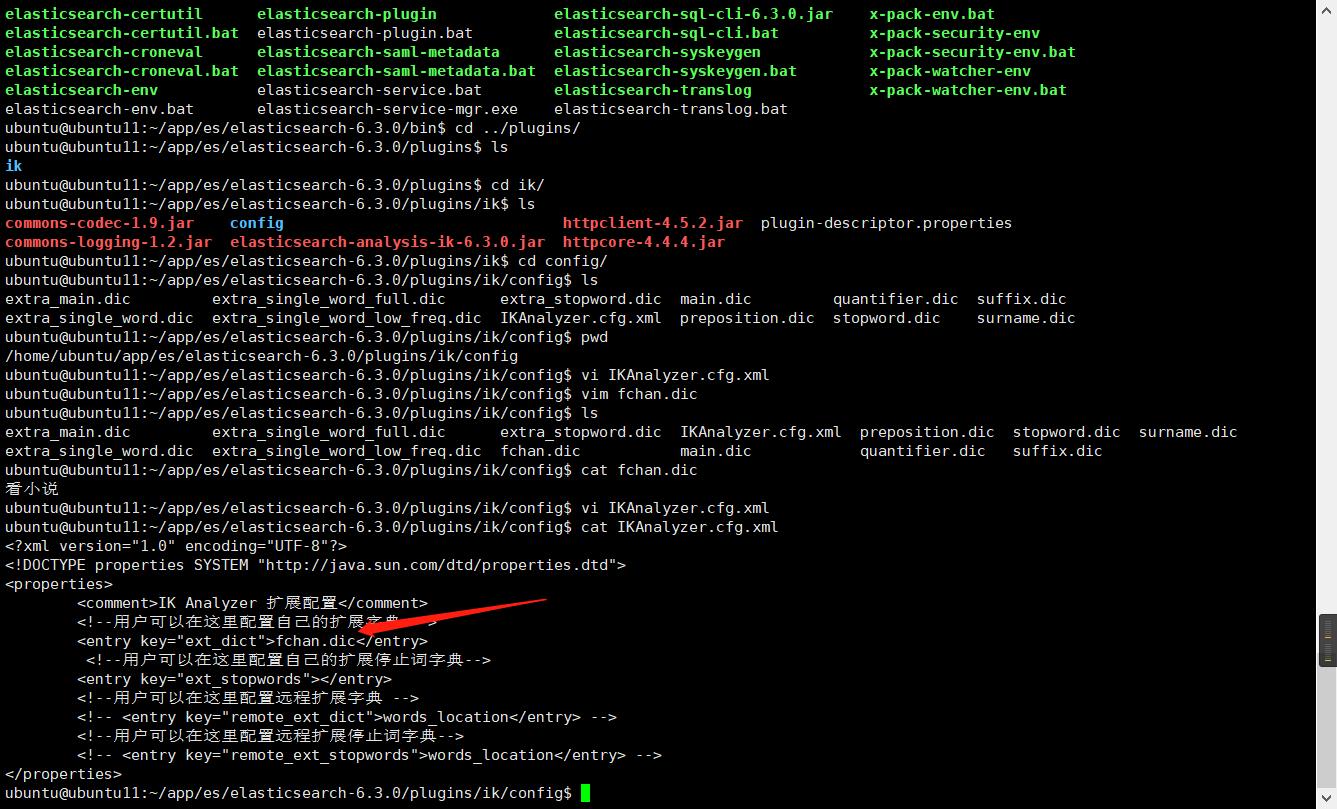
添加自己的字典前后对比

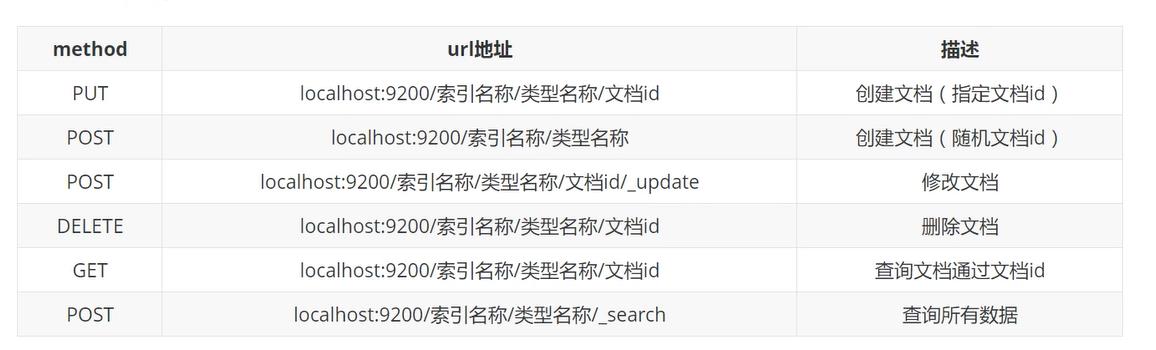
ES的REST风格操作(增删改rest api)
创建一个索引
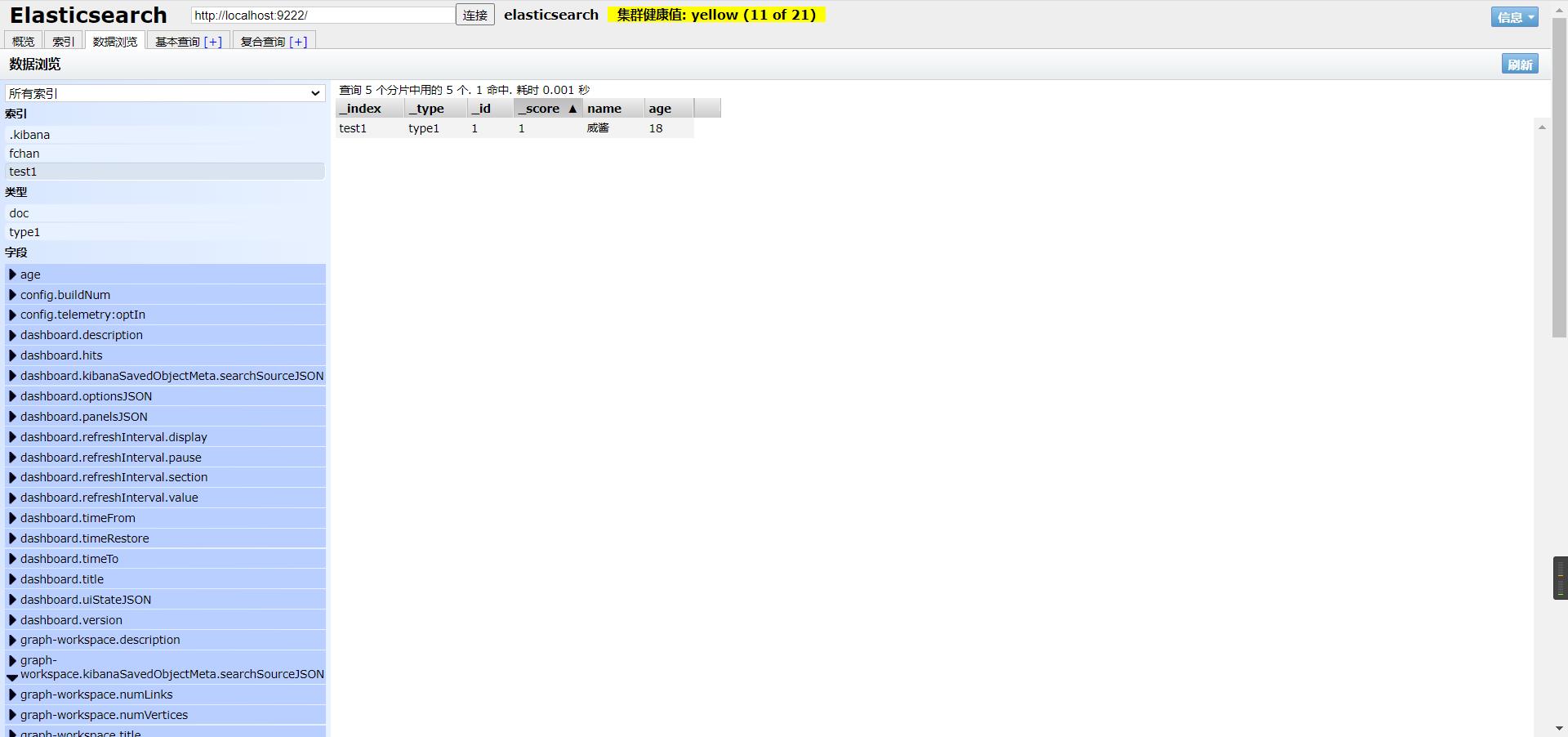
数据的基本类型
字符串中的keyword顾名思义就是关键词,是不可分割的

给自己的index的文档的field设置自定义类型,创建索引(规则)
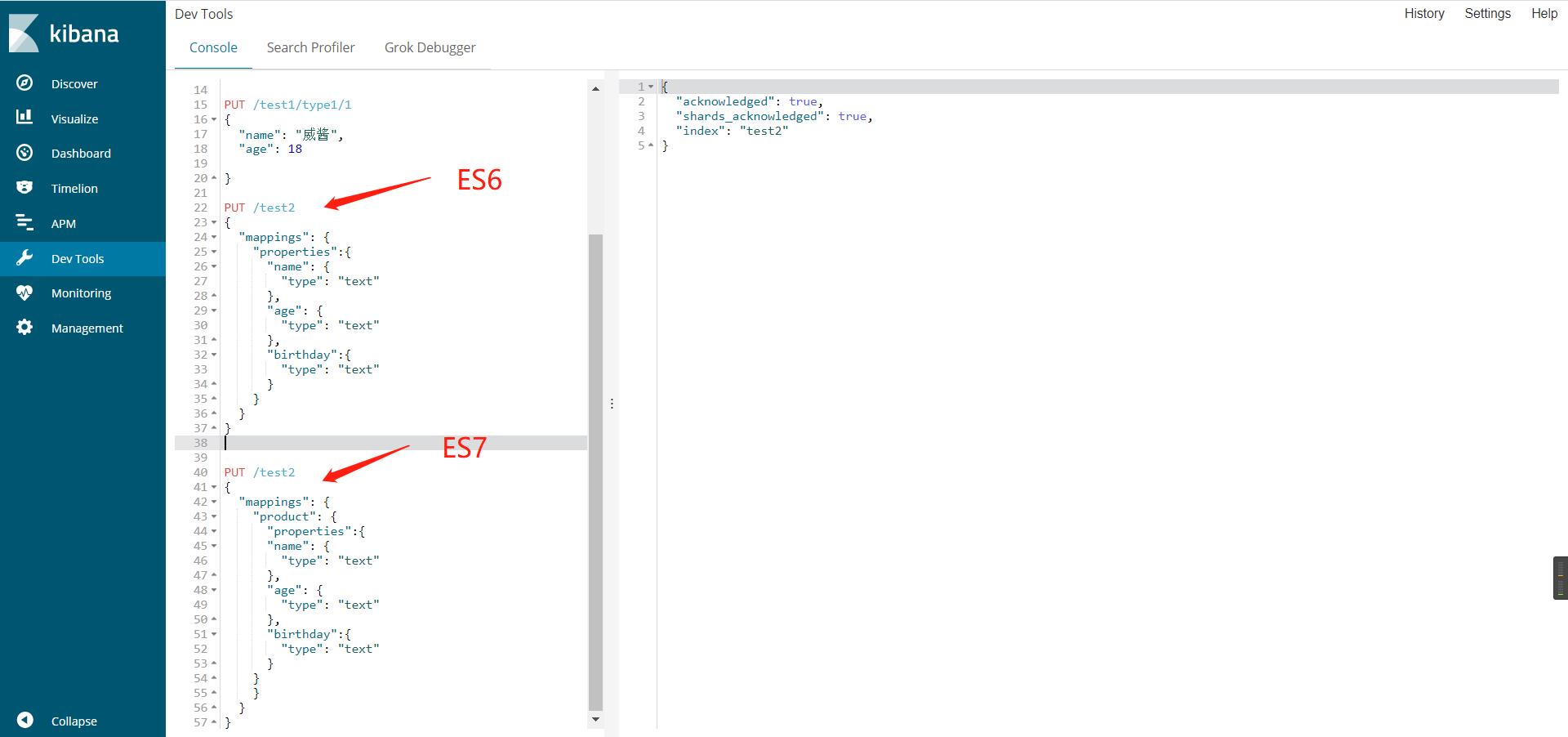
es一个index下type的数量:5.x以前的multiple types还是允许的,但是6.x里面新创建的index只允许一个type了,从7.0开始将强制只有一个type。
#ES7
PUT /test2
{
"mappings": {
"properties":{
"name": {
"type": "text"
},
"age": {
"type": "text"
},
"birthday":{
"type": "text"
}
}
}
}
#ES6老版本定义
PUT /test2
{
"mappings": {
#product->就是定义的type,es6下一个index只允许创建一个type了
"product": {
"properties":{
"name": {
"type": "text"
},
"age": {
"type": "text"
},
"birthday":{
"type": "text"
}
}
}
}
}
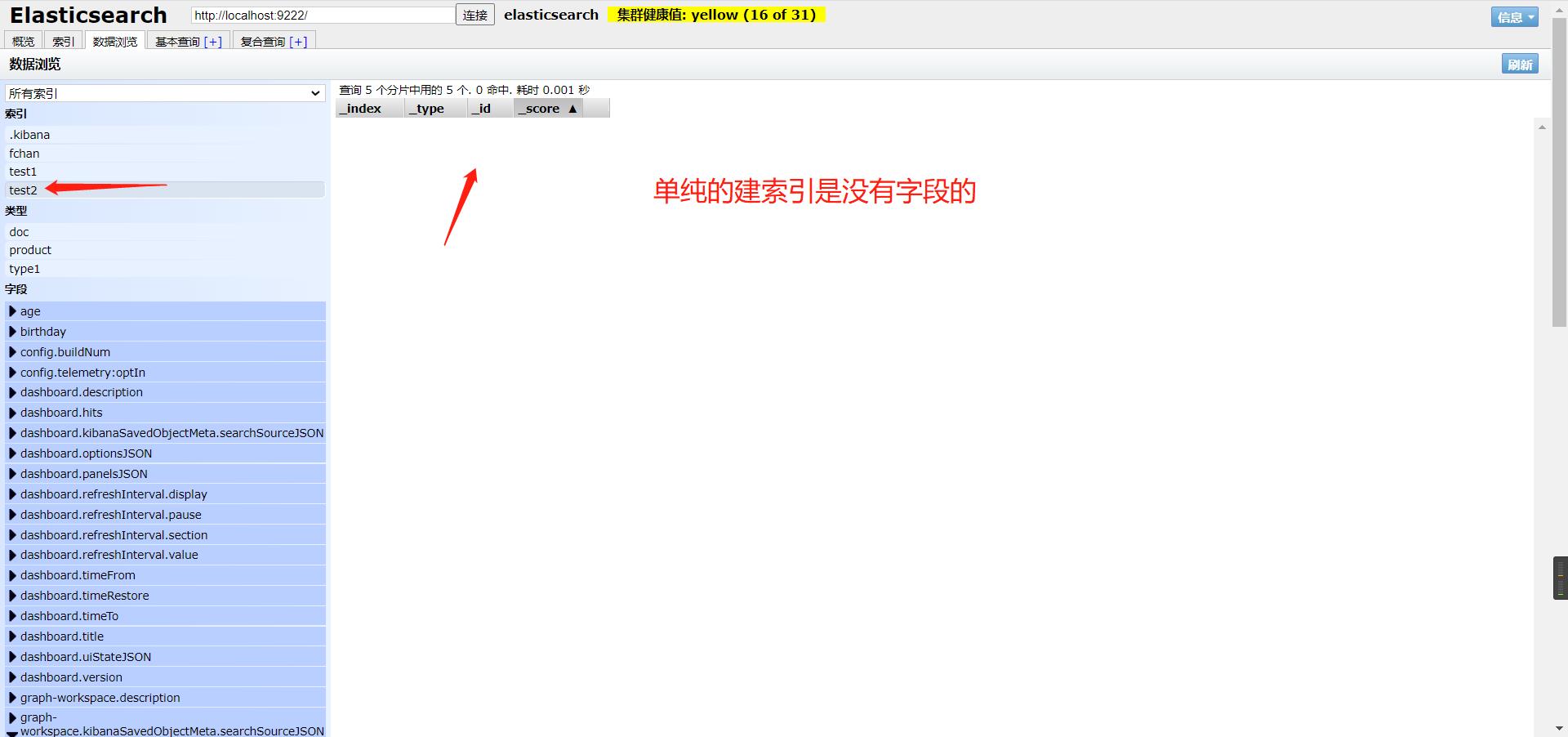
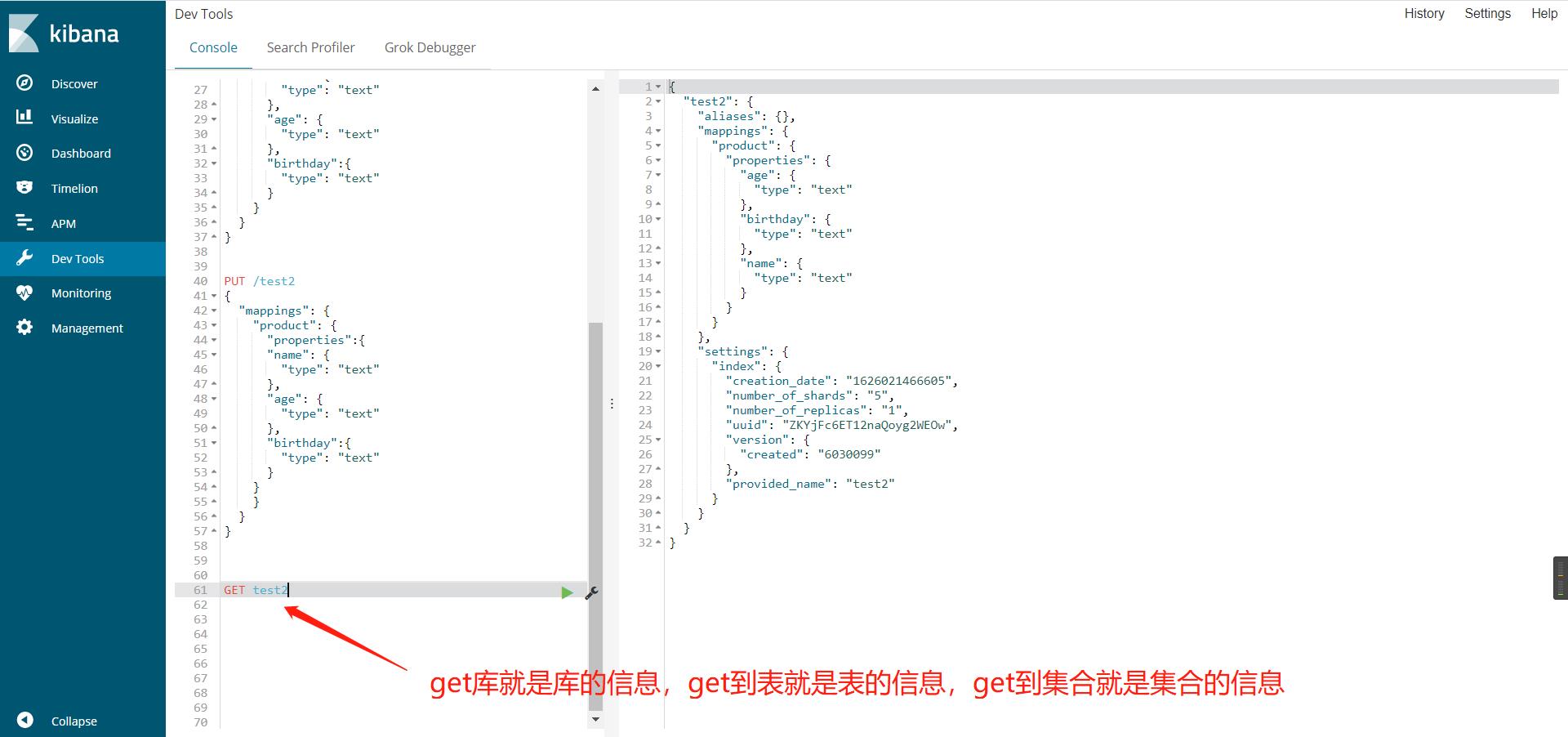
获取相关信息
type在后面就被废弃了,es6还在用,默认的文档类型就是_doc
更新es中索引下的数据(推荐post,put会顶掉更新字段外的其他字段)
仍旧使用put请求提交数据即可,可以看到version+1,result=updated,如果新提交的数据漏了个字段,那么这个字段就被覆盖顶掉了,就没了
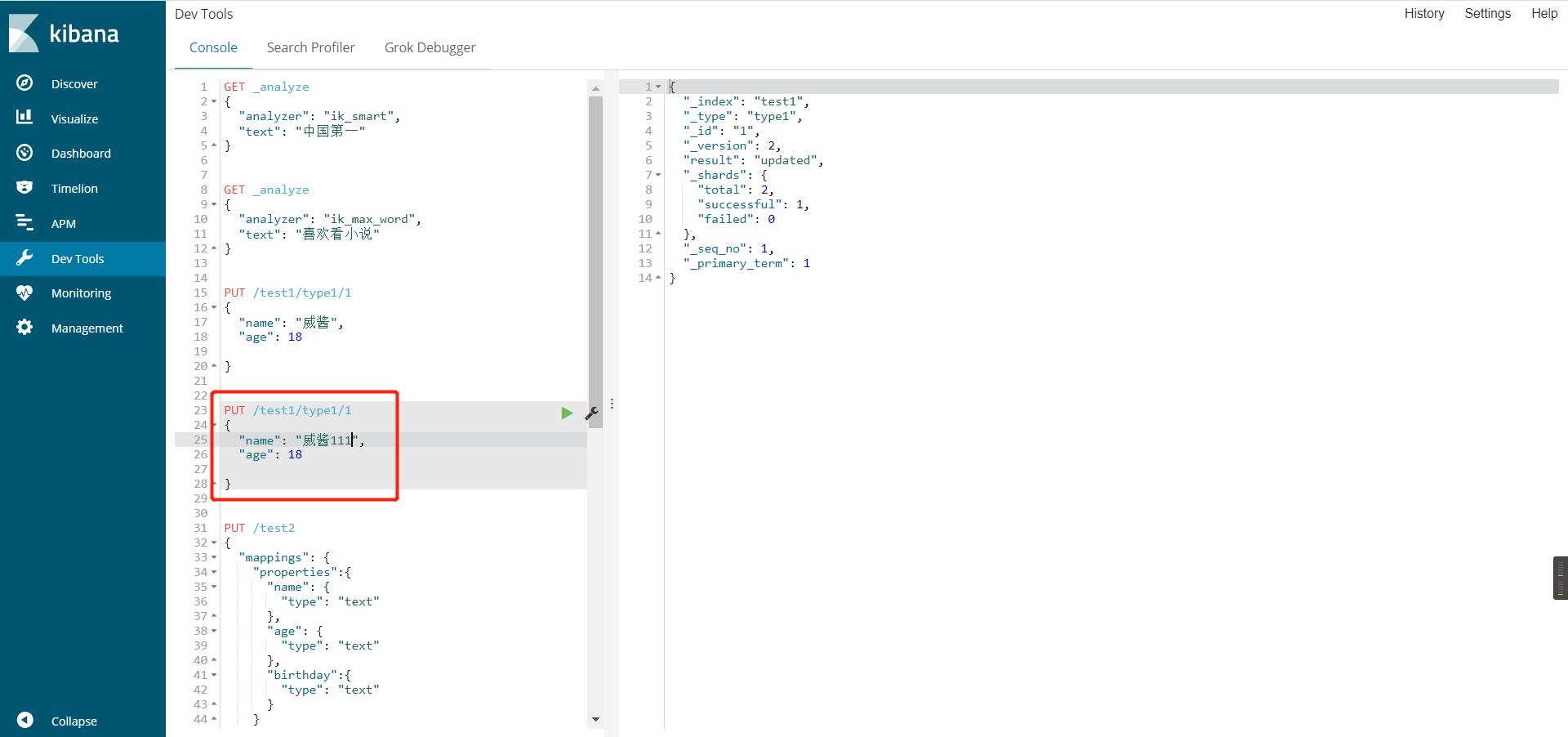
post修改数据,就不会顶掉没有更新到字段
POST /test1/type1/1/_update
{
"doc": {
"name": "威酱111"
}
}
查看,索引列表以及索引里的文档数量
GET _cat/indices?v

删除数据
写到哪删到哪,根据删除的路径来
demo删库
delete test2
查询数据
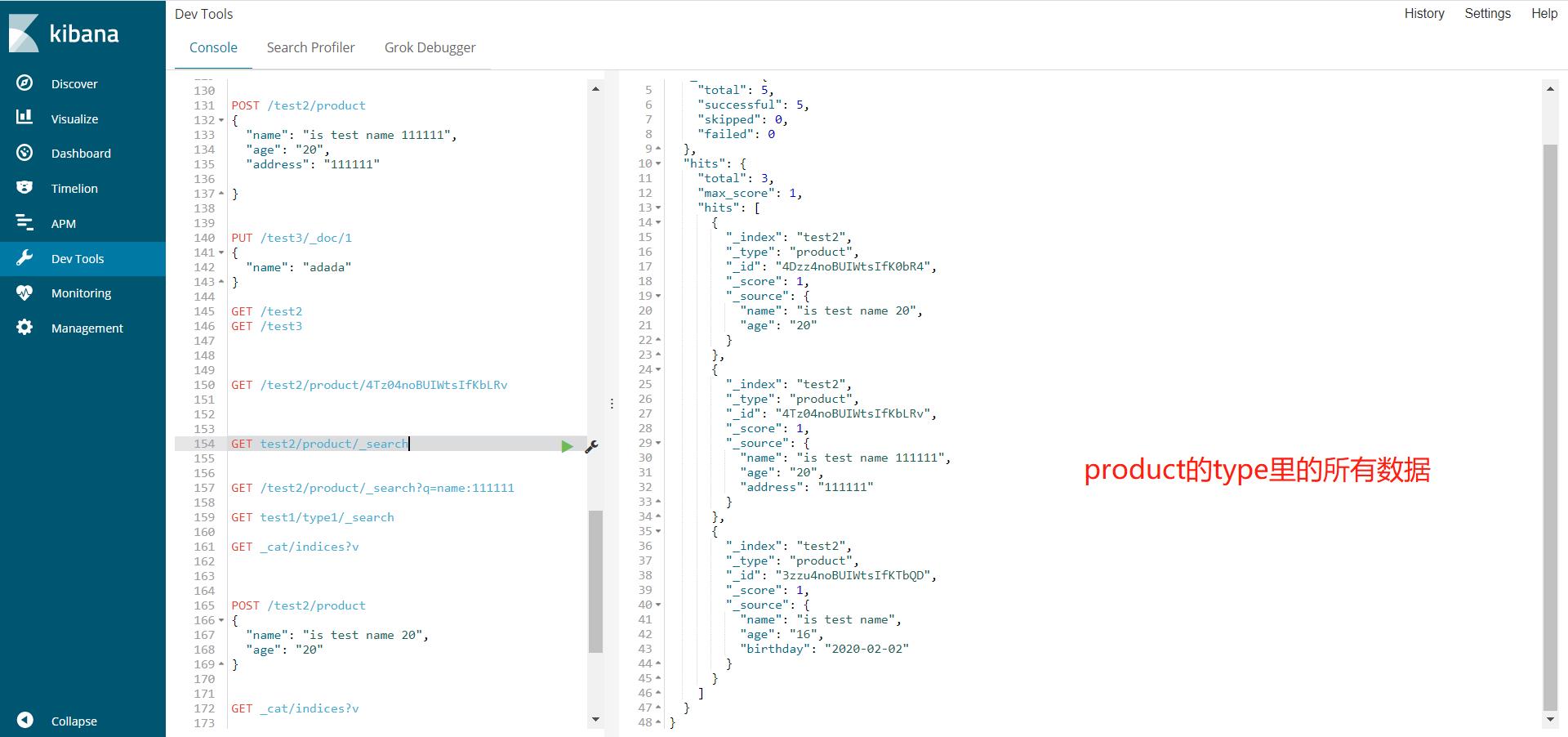
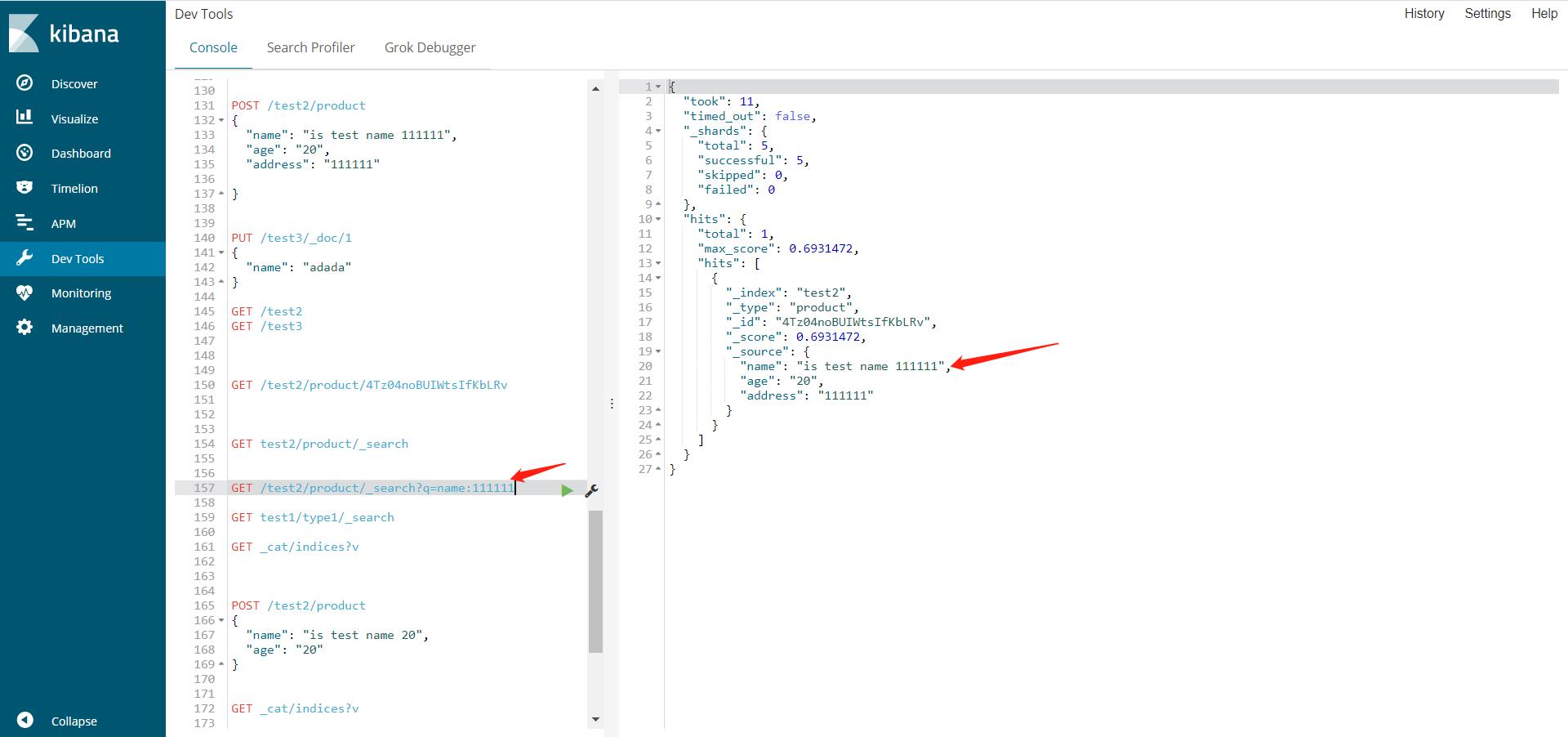
查询name里包含111111的,这里这个111111就是一个词,对于这个词是精确匹配,对于整个字符串是模糊查询
GET /test2/product/_search?q=name:111111
#或者
GET /test2/product/_search
{
"query": {
"match": {
"name": "111111"
}
}
}
查出来的多条数据中的score意思匹配度,值越高,说明搜索的匹配度越高.
hits中的有索引,文档,结果总数等信息
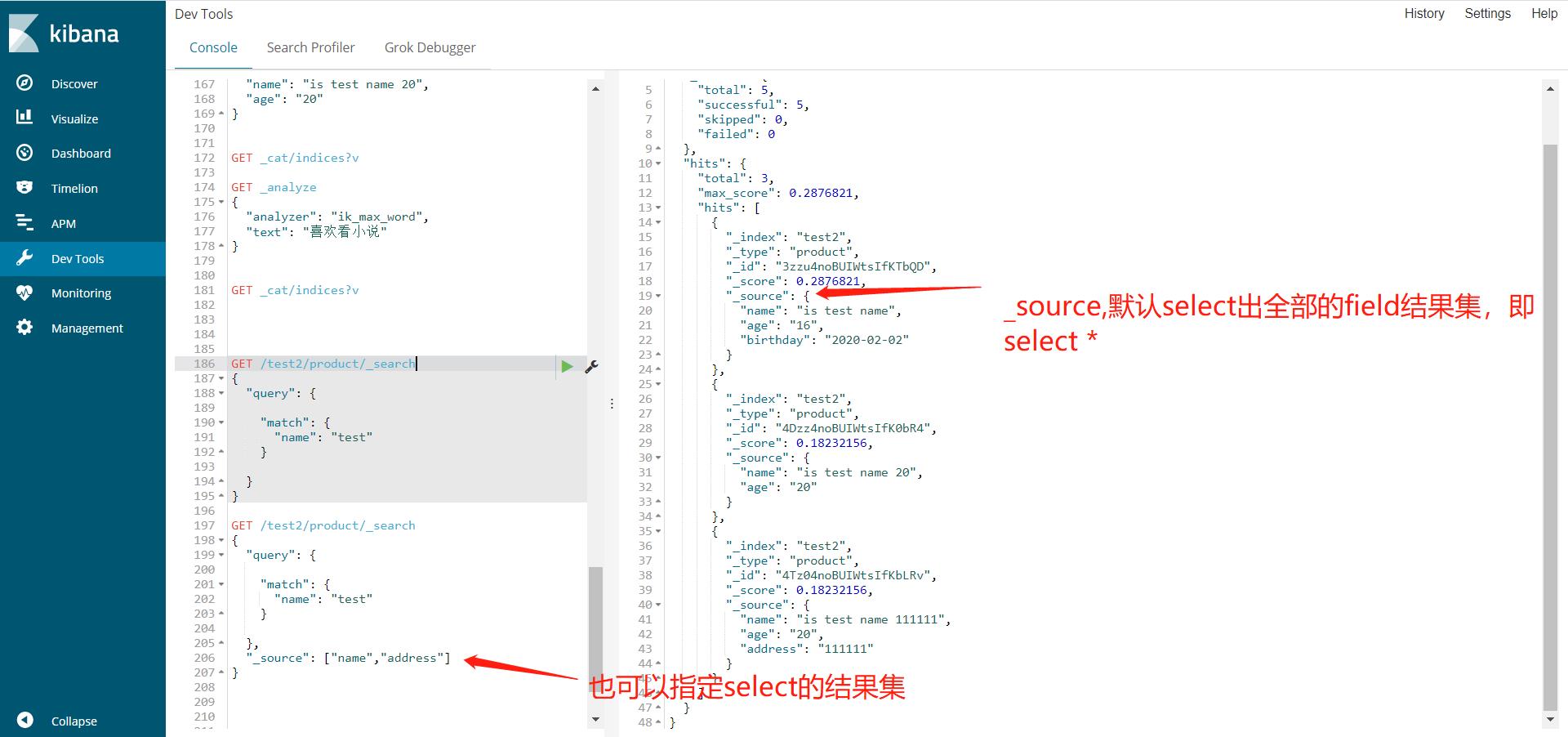
指定select出来的结果集的字段
GET /test2/product/_search
{
"query": {
"match": {
"name": "test"
}
},
"_source": ["name","address"]
}
查询后按照某个字段排序
GET /test2/product/_search
{
"query": {
"match": {
"name": "test"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
分页查询
GET /test2/product/_search
{
"query": {
"match": {
"name": "test"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
#从第几条开始
"from": 0,
#获取几条数据
"size": 2
#from + size其实就是limit from,size
}
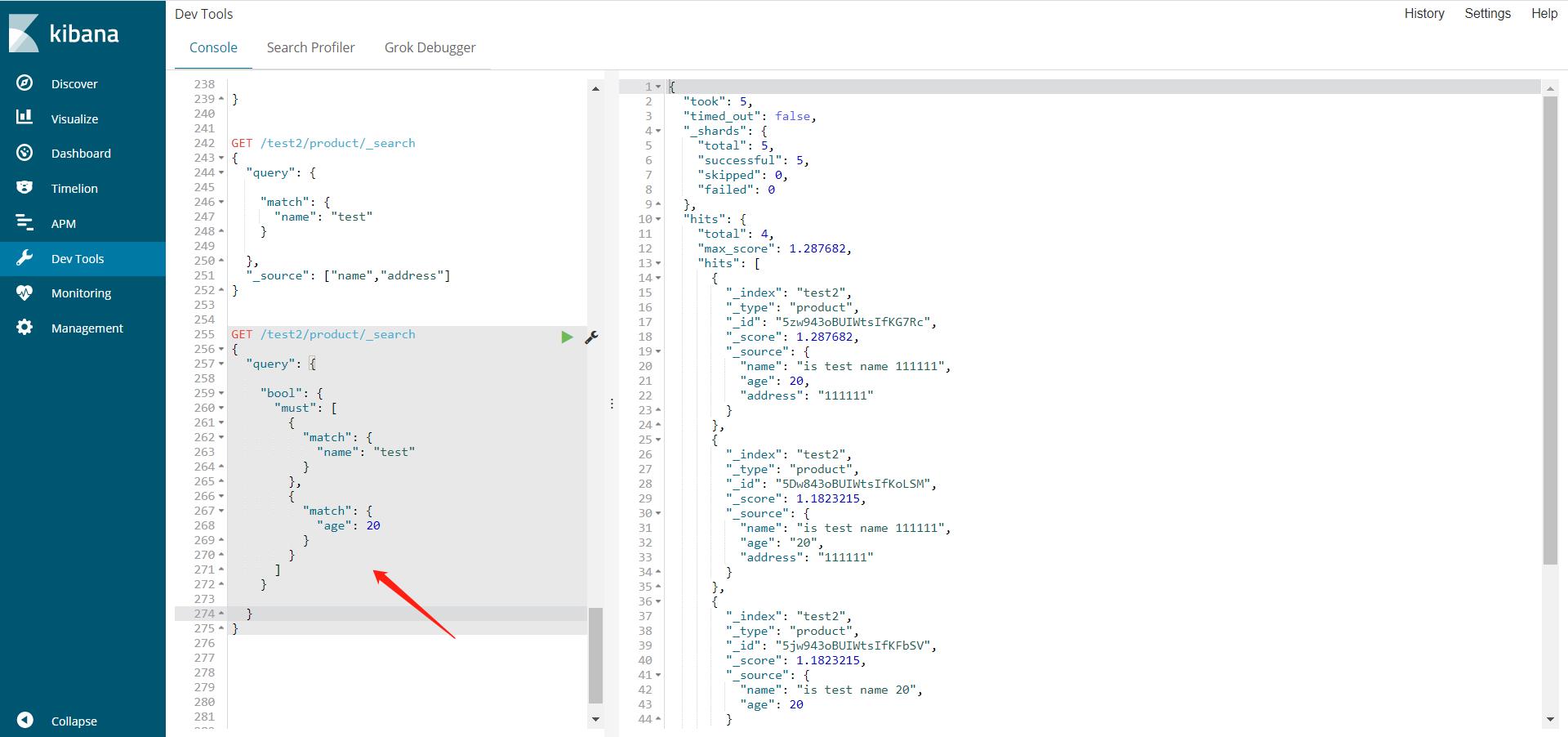
多条件查询,是否存在(返回boolean值)
GET /test2/product/_search
{
"query": {
"bool": {
#must的两个条件都必须满足,即mysql中的and
#should的两个条件至少满足一个就可以。即mysql中的or
"must": [
{
"match": {
"name": "test"
}
},
{
"match": {
"age": 20
}
}
]
}
}
}
must_not反向查找,不等于匹配值的结果集
GET /test2/product/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"age": 20
}
}
,{
"match": {
"name": "test11"
}
}
]
}
}
}
过滤(范围查询),符合条件的值查出来
GET /test2/product/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "test"
}
}
],
"filter": {
"range": {
"age": {
#gte >=
#lte <=
#lt <
#gt >
"gte": 10,
"lte": 19
}
}
}
}
}
}

查询字段有多个值符合条件(类似mysql in)
多个条件只需要空格隔开就好
GET /test2/product/_search
{
"query": {
"match": {
"name": "test 111111"
}
}
}
term精确查找
term,直接查精确的(利用了倒排索引),会使用分词器,此时会遇到keyword类型的字段不使用分词器,只能完全匹配的情况
match,会使用分词器解析(先分析文档,再通过分析的文档进行查询),这里就是再提一下字段的类型,其中text是可以被分词器解析的,但是keyword是不能被分词器解析的。
GET test2/product/_search
{
"query": {
"term": {
"address": {
"value": "111111"
}
}
}
}
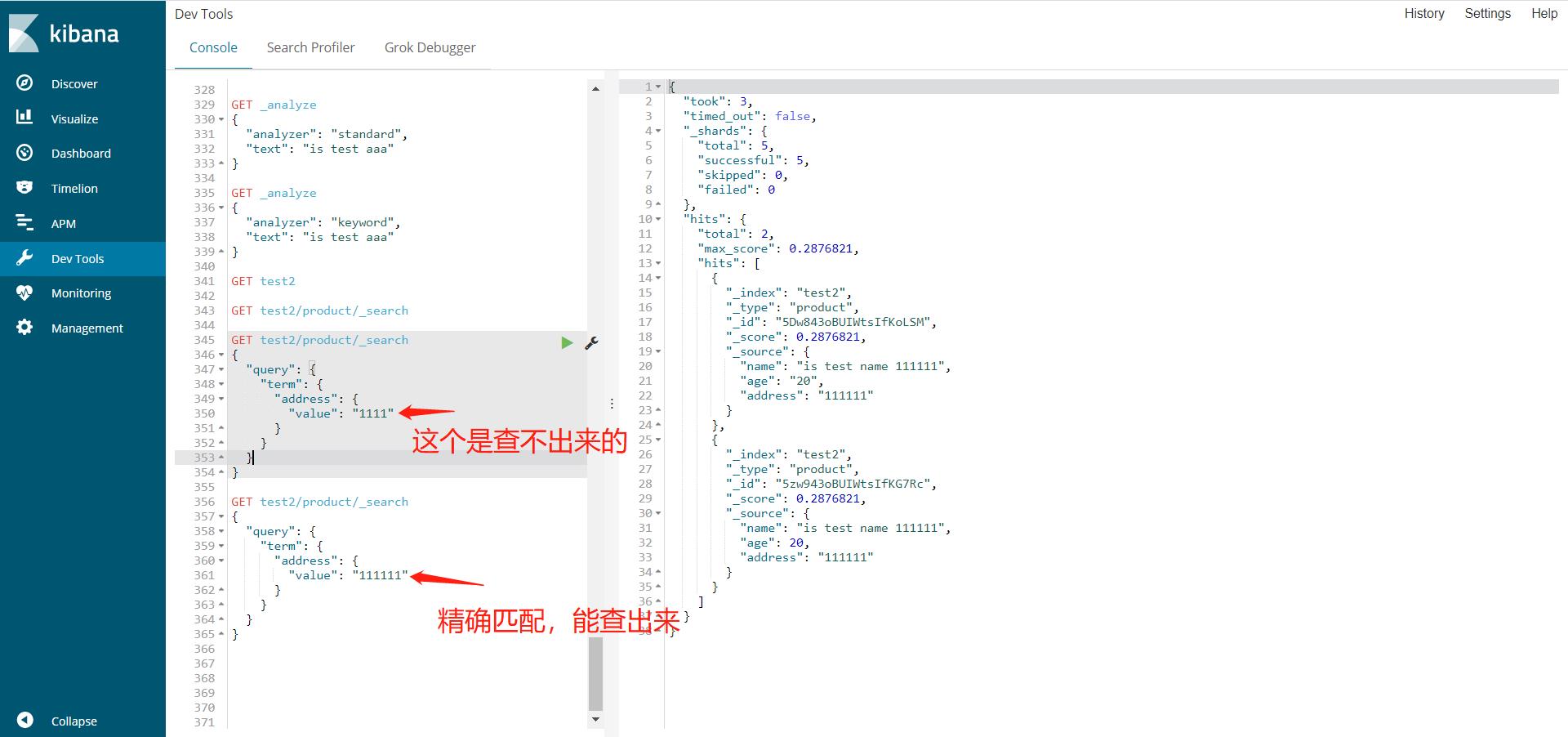
GET test2/product/_search
{
"query": {
"term": {
"name": {
"value": "test"
}
}
}
}
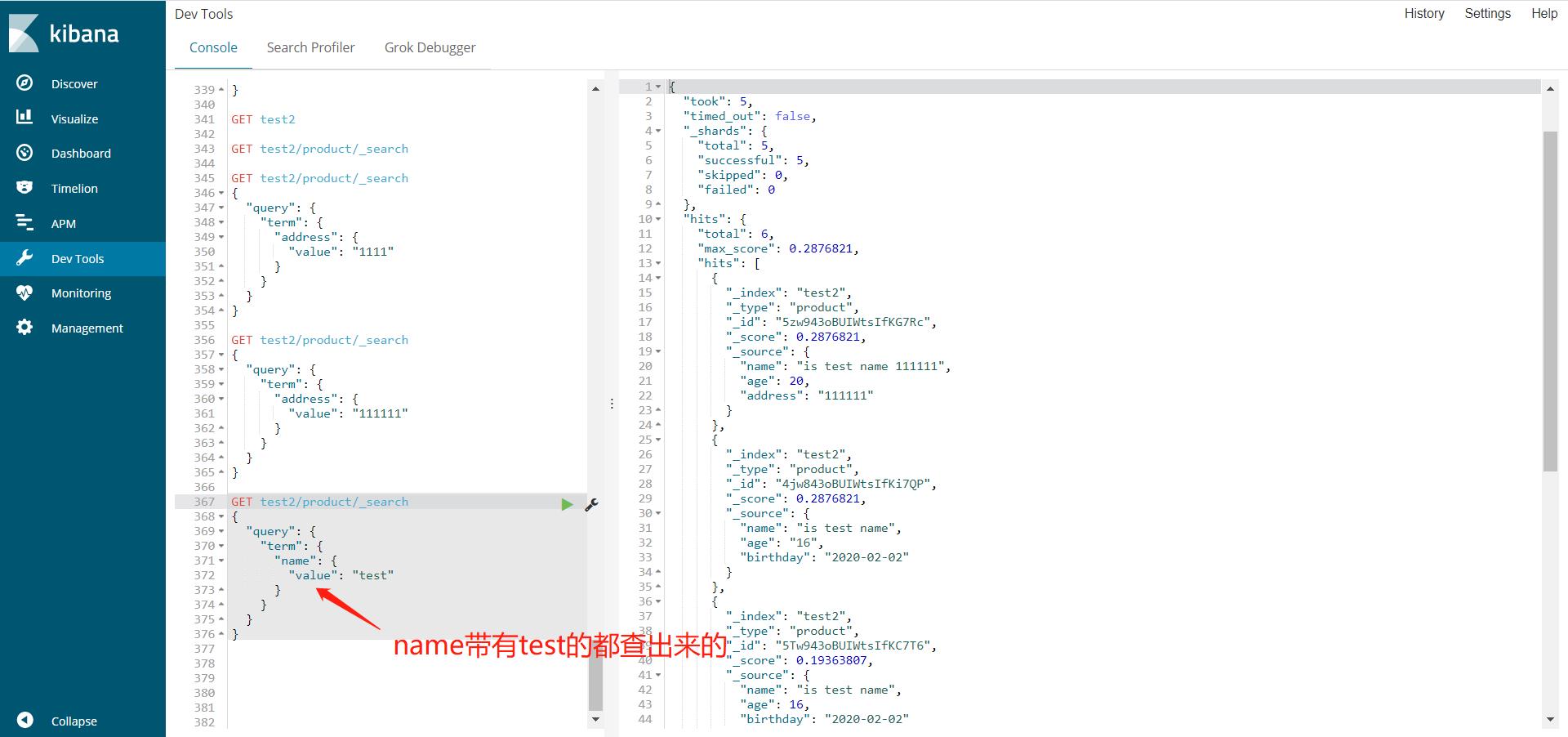
高亮查询
GET test2/product/_search
{
"query": {
"term": {
"name": {
"value": "test"
}
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
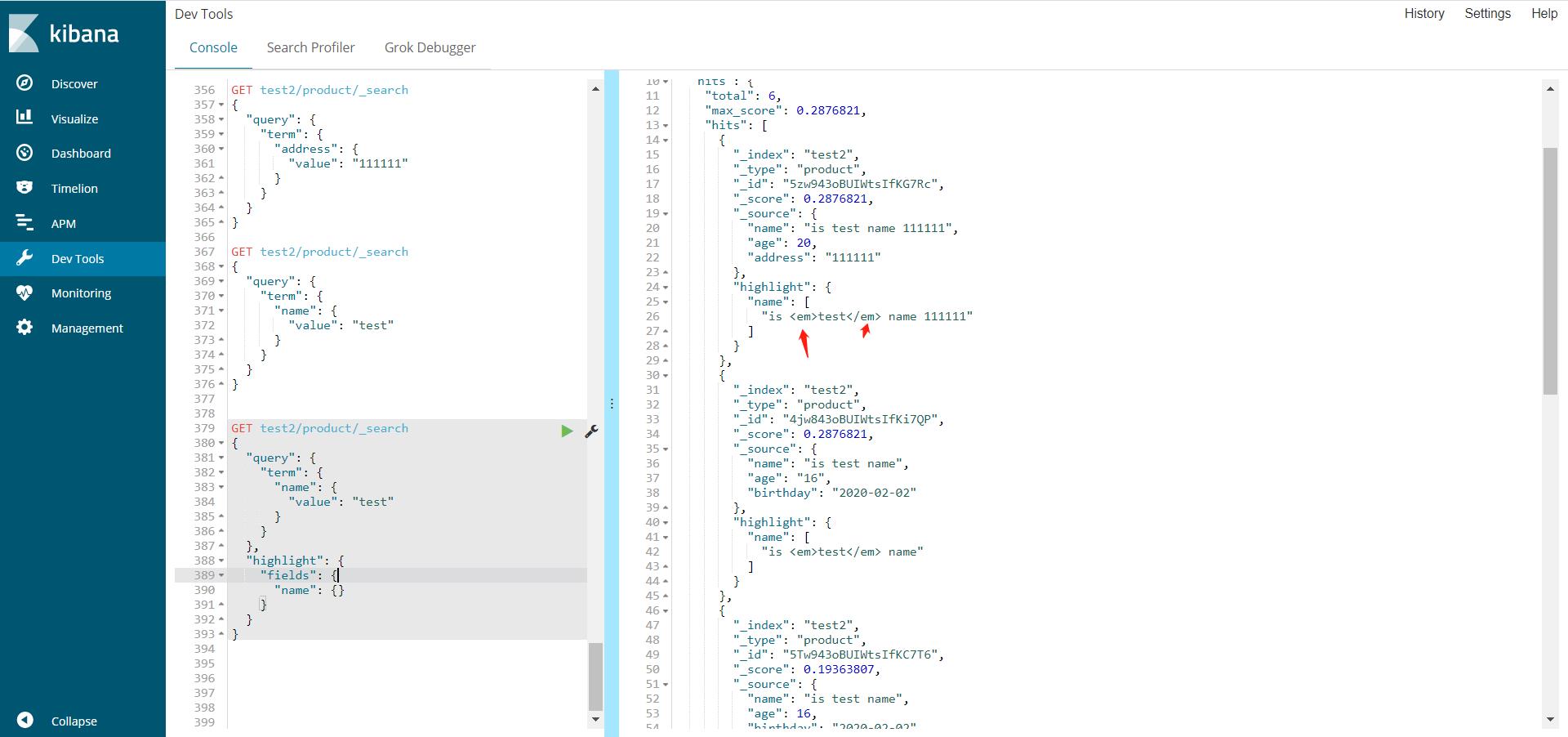
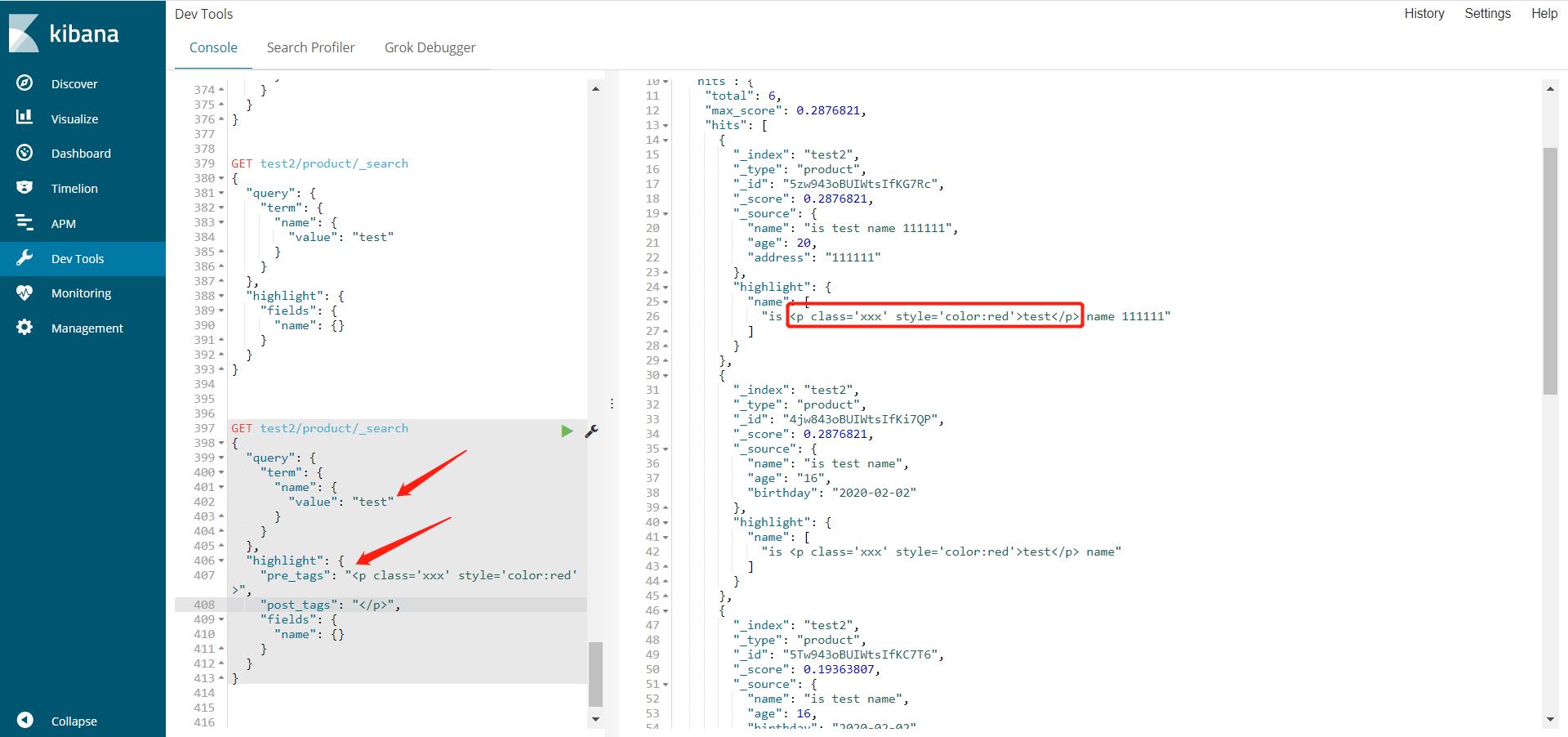
自定义高亮的样式
GET test2/product/_search
{
"query": {
"term": {
"name": {
"value": "test"
}
}
},
"highlight": {
"pre_tags": "<p class='xxx' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}
以上是关于ubuntu安装es(elesticSearch),es结构介绍,IK分词器的简单使用,es入门增删改查api,结果集高亮的主要内容,如果未能解决你的问题,请参考以下文章