手写一个简易bundler打包工具带你了解Webpack原理
Posted 星期一研究室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手写一个简易bundler打包工具带你了解Webpack原理相关的知识,希望对你有一定的参考价值。

用原生js手写一个简易的打包工具bundler
🥝序言
我们都知道, webpack 是一个打包工具。在我们对它进行配置之前,它也是经过一系列的代码编写,才生成的打包工具。那这背后,又做了什么事情呢?
今天,我们就来原生 js ,来手写一个简易的打包工具 bundler ,实现对项目代码的打包。
下面开始进行本文的讲解~
🍉一、模块分析(入口文件代码分析)
1. 项目结构
下面先来看下我们的项目文件结构。请看下图👇
2. 安装第三方依赖
我们需要用到 4 个第三方依赖包,分别是:
- @babel/parser —— 帮助我们分析源代码并生成抽象语法树 (AST) ;
- @babel/traverse —— 帮助我们对抽象语法树进行遍历,并分析里语法树里面的语句;
- @babel/core —— 将原始代码打包编译成浏览器能够运行的代码;
- @babel/preset-env —— 用于在解析抽象语法树时进行配置。
下面依次给出安装这四个库的命令,分别是:
(1)@babel/parser
npm install @babel/parser --save
(2)@babel/traverse
npm install @babel/traverse --save
(3)@babel/core
npm install @balbel/core --save
(4)@babel/preset-env
npm install @babel/preset-env --save
3. 业务代码
当我们去做一个项目打包时,首先需要先对项目中的模块进行分析,现在我们先对入口文件进行分析。假设我们要实现一个业务,输出的是 hello monday 。那么我们先来编写我们的业务代码。
第一步: 编写 word.js 文件代码。具体代码如下:
export const word = 'monday';
第二步: 编写 message.js 文件代码。具体代码如下:
import { word } from './word.js';
const message = `hello ${word}`;
export default message;
第三步: 编写 index.js 文件代码。具体代码如下:
import message from "./message.js";
console.log(message);
4. 开始打包
编写完业务代码之后,现在,我们要先来对入口文件 index.js 进行打包。注意,这里除了 babel 外,我们不使用任何工具,没有 webpack 、也没有 webpack-cli 等工具。
我们在根目录下先创建一个文件,命名为 bundler.js ,用这个文件来编写我们的打包逻辑。具体代码如下:
const fs = require('fs');
const path = require('path');
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const babel = require('@babel/core');
const moduleAnalyser = (filename) => {
//1. 首先拿到文件名,拿到文件名之后我们去读取文件里面的内容
const content = fs.readFileSync(filename, 'utf-8');
//2. 借助Babel-parser,将文件里js的字符串,转化成一个js的对象->这个js对象就是我们所说的抽象语法树
const ast = parser.parse(content, {
// 3. 如果你传入的ES6的语法,那么需要设置sourceType为module
sourceType: 'module'
});
//收集入口文件中的依赖文件
const dependencies = {};
traverse(ast, {
/*4. 有了抽象语法树之后,我们需要去分析,
它里面的声明都在哪些地方,
去找到import这些语句对应的内容
5. 需要借助@babel/traverse这个工具,
这个工具表明当抽象语法树有ImportDeclaration这样的语句时,
它就会继续下面的函数*/
ImportDeclaration({ node }) {
// console.log(node);
const dirname = path.dirname(filename);
const newFile = './' + path.join(dirname, node.source.value);
// console.log(newFile);
//6. 找到import语句之后,将这些语句拼装成一个对象,放在dependencies这个变量中(以键值对的方式来进行存储)
dependencies[node.source.value] = newFile;
}
});
/*
7. 分析好了之后,对模块的源代码进行一次编译。通过使用transformFromAst,
把它从一个ES module,转换成浏览器可以执行的语法,并将其存储在code里面,
code生成的代码就是我们可以在浏览器上运行的代码*/
const { code } = babel.transformFromAst(ast, null, {
presets: ["@babel/preset-env"]
})
return {
//返回入口文件的名字
filename,
//返回入口文件中的依赖文件
dependencies,
//返回浏览器上可以运行的代码
code
}
// console.log(dependencies);
}
const moduleInfo = moduleAnalyser('./src/index.js');
console.log(moduleInfo);
通过以上代码,相信大家对打包入口文件有一个基本的了解。之后呢,在控制台运行 node bundler.js 命令,可以对打包过程中的各种分析进行查看。
下面我们继续第二块的内容~
🥑二、依赖图谱Dependencies Graph
对于上述所讲的内容,我们谈到的,只是对一个入口文件进行分析。但是呢,这还远远不够。所以,现在我们要来对整个工程文件进行分析。
1. 结果分析
我们先来看下上述代码中,只分析入口文件时的打印情况。具体代码如下:
{
filename: './src/index.js',
dependencies: { './message.js': './src\\\\message.js' },
code: '"use strict";\\n' +
'\\n' +
'var _message = _interopRequireDefault(require("./message.js"));\\n' +
'\\n' +
'function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { "default": obj }; }\\n' +
'\\n' +
'console.log(_message["default"]);'
}
大家可以看到,入口文件分析完了以后,还有一层一层的依赖和code。现在,我们需要去顺着这些依赖,来把整个项目的内容分析出来。
2. 分析所有模块的依赖关系
我们现在来对 bundler.js 进行升级改造,把所有模块的依赖关系给描绘出来。具体代码如下:
const fs = require('fs');
const path = require('path');
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const babel = require('@babel/core');
const moduleAnalyser = (filename) => {
//1. 首先拿到文件名,拿到文件名之后我们去读取文件里面的内容
const content = fs.readFileSync(filename, 'utf-8');
//2. 借助Babel-parser,将文件里js的字符串,转化成一个js的对象->这个js对象就是我们所说的抽象语法树
const ast = parser.parse(content, {
// 3. 如果你传入的ES6的语法,那么需要设置sourceType为module
sourceType: 'module'
});
//收集入口文件中的依赖文件
const dependencies = {};
traverse(ast, {
/*4. 有了抽象语法树之后,我们需要去分析,
它里面的声明都在哪些地方,
去找到import这些语句对应的内容
5. 需要借助@babel/traverse这个工具,
这个工具表明当抽象语法树有ImportDeclaration这样的语句时,
它就会继续下面的函数*/
ImportDeclaration({ node }) {
// console.log(node);
const dirname = path.dirname(filename);
const newFile = './' + path.join(dirname, node.source.value);
// console.log(newFile);
//6. 找到import语句之后,将这些语句拼装成一个对象,放在dependencies这个变量中(以键值对的方式来进行存储)
dependencies[node.source.value] = newFile;
}
});
/*
7. 分析好了之后,对模块的源代码进行一次编译。通过使用transformFromAst,
把它从一个ES module,转换成浏览器可以执行的语法,并将其存储在code里面,
code生成的代码就是我们可以在浏览器上运行的代码*/
const { code } = babel.transformFromAst(ast, null, {
presets: ["@babel/preset-env"]
})
return {
//返回入口文件的名字
filename,
dependencies,
code
}
// console.log(dependencies);
}
const makeDependenciesGraph = (entry) => {
//1. 对入口模块进行一次分析
const entryModule = moduleAnalyser(entry);
// console.log(entryModule);
//2. 定义一个数组,存放入口文件和依赖
const graphArray = [ entryModule ];
//3. 对graphArray进行遍历
for(i = 0; i < graphArray.length; i++){
//4. 取出graphArray中的每一项
const item = graphArray[i];
//5. 取出每一项中的依赖dependencies
const { dependencies } = item;
//6. 如果入口文件有依赖时,就对依赖进行循环
if(dependencies) {
/*7. 通过不断的循环,最终,可以把它的入口文件,以及它的依赖,
还有它的依赖的依赖,一层一层的遍历出来,并推到graphArray当中*/
for(let j in dependencies) {
/*8. 通过队列(先进先出)的方式实现递归的效果;
为什么用递归?递归地进行分析,是因为每个依赖下面有可能还有依赖*/
graphArray.push(
moduleAnalyser(dependencies[j])
)
}
}
}
//9. 处理后的graphArray是一个数组,现在需要对它进行格式上的转换
const graph = {};
graphArray.forEach(item => {
graph[item.filename] = {
dependencies: item.dependencies,
code: item.code
}
});
return graph;
}
// './src/index.js' 为入口文件
const graphInfo = makeDependenciesGraph('./src/index.js');
console.log(graphInfo);
大家可以看到,我们制造了一个新的函数 makeDependenciesGraph ,来描述所有模块的依赖关系,并在最终对它进行格式上的转换,转换成我们理想中的 js 对象。现在,我们来看下依赖关系的打印结果。打印结果如下:
{
'./src/index.js': {
dependencies: { './message.js': './src\\\\message.js' },
code: '"use strict";\\n' +
'\\n' +
'var _message = _interopRequireDefault(require("./message.js"));\\n' +
'\\n' +
'function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { "default": obj }; }\\n' +
'\\n' +
'console.log(_message["default"]);'
},
'./src\\\\message.js': {
dependencies: { './word.js': './src\\\\word.js' },
code: '"use strict";\\n' +
'\\n' +
'Object.defineProperty(exports, "__esModule", {\\n' +
' value: true\\n' +
'});\\n' +
'exports["default"] = void 0;\\n' +
'\\n' +
'var _word = require("./word.js");\\n' +
'\\n' +
'var message = "hello ".concat(_word.word);\\n' +
'var _default = message;\\n' +
'exports["default"] = _default;'
},
'./src\\\\word.js': {
dependencies: {},
code: '"use strict";\\n' +
'\\n' +
'Object.defineProperty(exports, "__esModule", {\\n' +
' value: true\\n' +
'});\\n' +
'exports.word = void 0;\\n' +
"var word = 'monday';\\n" +
'exports.word = word;'
}
}
大家可以看到,所有模块的依赖关系都给遍历出来了。这也就说明了,我们成功进行了这一步的分析。
🍐三、生成代码
1. 逻辑编写
上面我们已经成功生成了依赖图谱,那现在,我们就来把这个依赖图谱,生成能够真正在浏览器上运行的代码。我们继续在 bundle.js 上,编写一个生成代码的逻辑。具体代码如下:
const fs = require('fs');
const path = require('path');
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const babel = require('@babel/core');
const moduleAnalyser = (filename) => {
//1. 首先拿到文件名,拿到文件名之后我们去读取文件里面的内容
const content = fs.readFileSync(filename, 'utf-8');
//2. 借助Babel-parser,将文件里js的字符串,转化成一个js的对象->这个js对象就是我们所说的抽象语法树
const ast = parser.parse(content, {
// 3. 如果你传入的ES6的语法,那么需要设置sourceType为module
sourceType: 'module'
});
//收集入口文件中的依赖文件
const dependencies = {};
traverse(ast, {
/*4. 有了抽象语法树之后,我们需要去分析,
它里面的声明都在哪些地方,
去找到import这些语句对应的内容
5. 需要借助@babel/traverse这个工具,
这个工具表明当抽象语法树有ImportDeclaration这样的语句时,
它就会继续下面的函数*/
ImportDeclaration({ node }) {
// console.log(node);
const dirname = path.dirname(filename);
const newFile = './' + path.join(dirname, node.source.value);
// console.log(newFile);
//6. 找到import语句之后,将这些语句拼装成一个对象,放在dependencies这个变量中(以键值对的方式来进行存储)
dependencies[node.source.value] = newFile;
}
});
/*
7. 分析好了之后,对模块的源代码进行一次编译。通过使用transformFromAst,
把它从一个ES module,转换成浏览器可以执行的语法,并将其存储在code里面,
code生成的代码就是我们可以在浏览器上运行的代码*/
const { code } = babel.transformFromAst(ast, null, {
presets: ["@babel/preset-env"]
})
return {
//返回入口文件的名字
filename,
dependencies,
code
}
// console.log(dependencies);
}
const makeDependenciesGraph = (entry) => {
//1. 对入口模块进行一次分析
const entryModule = moduleAnalyser(entry);
// console.log(entryModule);
//2. 定义一个数组,存放入口文件和依赖
const graphArray = [ entryModule ];
//3. 对graphArray进行遍历
for(i = 0; i < graphArray.length; i++){
//4. 取出graphArray中的每一项
const item = graphArray[i];
//5. 取出每一项中的依赖dependencies
const { dependencies } = item;
//6. 如果入口文件有依赖时,就对依赖进行循环
if(dependencies) {
/*7. 通过不断的循环,最终,可以把它的入口文件,以及它的依赖,
还有它的依赖的依赖,一层一层的遍历出来,并推到graphArray当中*/
for(let j in dependencies) {
/*8. 通过队列(先进先出)的方式实现递归的效果;
为什么用递归?递归地进行分析,是因为每个依赖下面有可能还有依赖*/
graphArray.push(
moduleAnalyser(dependencies[j])
)
}
}
}
//9. 处理后的graphArray是一个数组,现在需要对它进行格式上的转换
const graph = {};
graphArray.forEach(item => {
graph[item.filename] = {
dependencies: item.dependencies,
code: item.code
}
});
return graph;
}
const generateCode = (entry) => {
//1. 将生成的依赖图谱进行格式转换
const graph = JSON.stringify(makeDependenciesGraph(entry));
/** 2. 构造require函数和exports对象,转化成浏览器认识的字符串
* return require(graph[module].dependencies[relative]) 目的是为了找到真实的路径
*/
return `
(function(graph){
function require(module){
function localRequire(relativePath) {
return require(graph[module].dependencies[relativePath])
}
var exports = {};
(function(require, exports, code){
eval(code)
})(localRequire, exports, graph[module].code);
return exports;
};
require('${entry}')
})(${graph});
`;
}
// './src/index.js' 为入口文件
const code = generateCode('./src/index.js');
console.log(code);
通过上面的代码我们可以看到,我们先将生成的依赖图谱进行格式转换,之后呢,构造 require 函数和 exports 对象,最终转换成浏览器认识的字符串。
2. 结果分析
通过上面的业务编写,我们完成了对整个项目进行打包的过程。现在,我们来看一下打印结果:
(function(graph){
function require(module){
function localRequire(relativePath) {
return require(graph[module].dependencies[relativePath])
}
var exports = {};
(function(require, exports, code){
eval(code)
})(localRequire, exports, graph[module].code);
return exports;
};
require('./src/index.js')
})({"./src/index.js":{"dependencies":{"./message.js":"./src\\\\message.js"},"code":"\\"use strict\\";\\n\\nvar _message = _interopRequireDefault(require(\\"./message.js\\"));\\n\\nfunction _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { \\"default\\": obj }; }\\n\\nconsole.log(_message[\\"default\\"]);"},"./src\\\\message.js":{"dependencies":{"./word.js":"./src\\\\word.js"},"code":"\\"use strict\\";\\n\\nObject.defineProperty(exports, \\"__esModule\\", {\\n value: true\\n});\\nexports[\\"default\\"] = void 0;\\n\\nvar _word = require(\\"./word.js\\");\\n\\nvar message = \\"hello \\".concat(_word.word);\\nvar _default = message;\\nexports[\\"default\\"] = _default;"},"./src\\\\word.js":{"dependencies":{},"code":"\\"use strict\\";\\n\\nObject.defineProperty(exports, \\"__esModule\\", {\\n value: true\\n});\\nexports.word = void 0;\\nvar word = 'monday';\\nexports.word = word;"}});
接下来,我们把这个打印结果,放到浏览器上进行检验。检验结果如下:
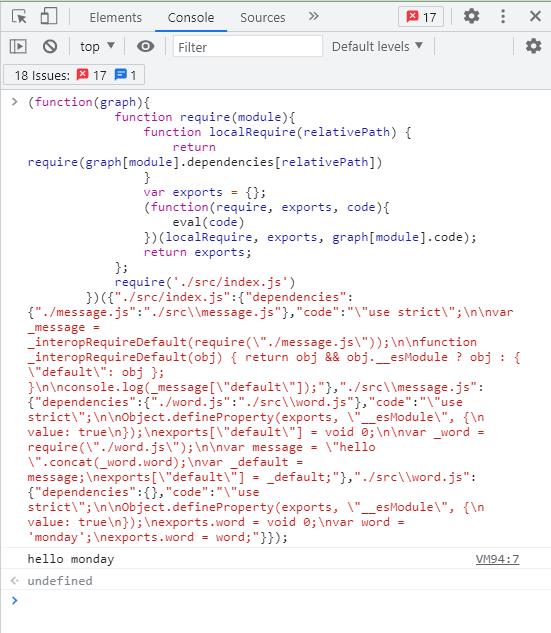
大家可以看到,打包后的结果,在浏览器上成功运行了,并显示除了 hello monday ,至此,说明我们的项目打包成功。
🍓四、结束语
在上面的这篇文章中,从模块的入口文件分析,再到依赖图谱的解析,最后到生成浏览器所认识的代码,我们了解了打包工具的整个操作流程。
到这里,关于本文的讲解就结束啦!希望对大家有帮助~
如文章有误或有不理解的地方,欢迎小伙伴们评论区留言撒~💬
🐣彩蛋 One More Thing
(:往期推荐
webpack入门核心知识👉不会webpack的前端可能是捡来的,万字总结webpack的超入门核心知识
webpack入门进阶知识👉webpack入门核心知识还看不过瘾?速来围观万字进阶知识
webpack实战案例配置👉[万字总结]webpack只会基础配置可不行!快来把实战案例配置一起打包带走
手写loader和plugin👉webpack实战之手写一个loader和plugin
(:番外篇
关注公众号星期一研究室,第一时间关注优质文章,更多精选专栏待你解锁~
如果这篇文章对你有用,记得留个脚印jio再走哦~
以上就是本文的全部内容!我们下期见!👋👋👋
以上是关于手写一个简易bundler打包工具带你了解Webpack原理的主要内容,如果未能解决你的问题,请参考以下文章