聊聊百度搜索背后的故事
Posted 程序员鱼皮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊百度搜索背后的故事相关的知识,希望对你有一定的参考价值。
聊聊 “吴牙签” 背后的搜索引擎技术
大家好,我是鱼皮,今天分享点有趣的技术知识。
前两天,我想上网买包牙签,于是就打开了某度搜索。
结果让我懵逼,我搜到的第一条内容竟然不是拿来剔牙的工具,而是搜出了一位明星,江湖美誉 “吴牙签”。
原来是最近的一个大瓜,你看这个签它又细又扎 🎵 ~

在吃瓜的同时,问题来了:为什么搜索牙签时,最先搜出来的不是传统牙签而是老吴呢?
作为一名程序员,有必要给大家科普一下互联网 搜索引擎 的工作原理,看看它是怎么帮助我们从数亿个网站中精准地把这根牙签找出来的!
搜索引擎工作原理
内容参考百度官方的搜索引擎工作原理介绍
先放一张官方的搜索引擎工作流程图:
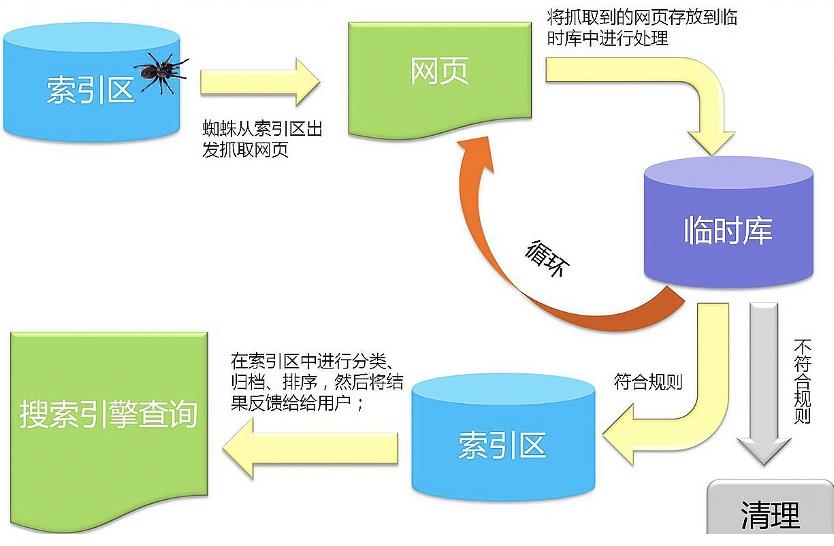
看不懂没关系,下面用实际的例子带大家理解。
数据抓取
用户搜索网站的内容归根结底是来自于存储网站的数据库的,因此,搜索引擎做的第一件事肯定是先把各个网站的数据抓到手。
当然,数据的抓取不可能全部交给人工负责,更多的是让机器(程序)自动抓取。通常,我们把负责数据抓取的工具人叫做 spider ,即网页蜘蛛。
每个搜索引擎都有自己的蜘蛛,各家的蜘蛛行为也不同,但基本原理是类似的。
整个互联网就是一张大蜘蛛网,网页中又嵌套着网页。网页蜘蛛就顺着网爬(类似有向图),从入口开始,通过页面上的超链接关系,不断发现新的网址并抓取,目标是尽最大可能抓取到更多有价值网页。
比如有位作者写了一篇 “吴牙签” 相关的文章,发到了某个写作平台,网页蜘蛛就能顺着这个写作平台将这篇文章抓到自己的网页数据库中。
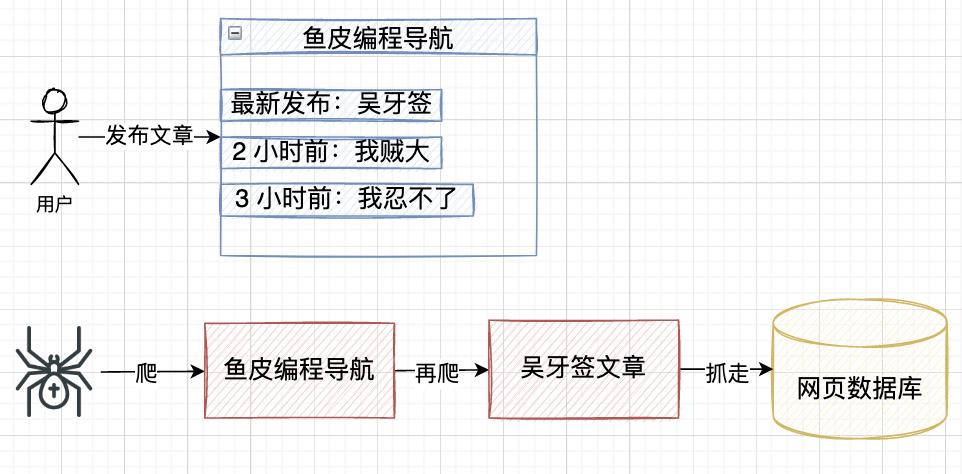
听起来好像还挺简单的,但对于亿级数据量的搜索引擎,需要有很多额外的考虑。
需关注的问题
首先是 重复和失效 问题,对于类似百度这样的大型 spider 系统,因为随时都存在网页被修改、删除、失效或出现新的超链接的可能。因此,不是把网站抓取过来就完事了,而是要维护一个网址库和页面库,保证库内网页的真实有效、不冗余。
还有其他问题比如:
- 如何保证抓取网站的质量?应拒绝垃圾广告、不良信息网站。
- 如何保证抓取友好性?应控制蜘蛛抓取的频率和深度,别蜘蛛太重把整个网搞破了。
- 如何使抓取的覆盖度更大?抓取一些原本抓不到的数据孤岛。
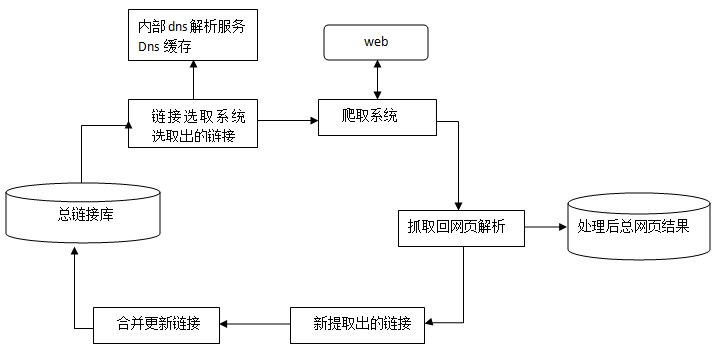
当然,问题远远不止这些,设计搜索引擎的抓取系统还是很复杂的,协议、算法、策略、原则、异常处理都要纳入考虑。以下是百度官方提供的抓取系统基本框架图,展示了抓取系统的宏观工作流程:
抓取配额
假如我们做了一个网站,肯定希望其他同学能搜到对吧。那么最关键的一点就是先让蜘蛛抓到你、并且多抓你。
通常,数据抓取系统会综合评估站点来确定抓取次数和频率。
像百度搜索引擎主要是根据 4 个指标来确定:
- 网站更新频率:更新越频繁的网站,蜘蛛抓取频率越高
- 网站更新质量:内容质量越高的网站,蜘蛛抓取的越多
- 连通度:蜘蛛要能顺利抵达该网站,且能正常访问
- 站点评价:运用算法对站点进行一个打分,也会影响收录度
数据处理
在蜘蛛抓取到网页,并存入网页数据库后,并不能把这一大坨网页数据直接拿来用。
比如我要搜索 “老吴牙签”,网页数据库中可能存储了数以亿计个网站,而且网站中又有那么多牙签,我怎么知道哪根是老吴的?

虽然慢慢搜肯定能搜出结果,但别忘了用户可等不起!现在大家对网站的要求很高,几秒钟没搜出来大家可能就会怀疑网络了。因此搜索引擎必须要面临的挑战是:如何提高搜索网页的效率?最好是在毫秒级完成。
为了实现这点,搜索引擎首先会对乱七八糟的网页数据进行 页面分析 ,将原始页面的不同部分进行识别并标记。比如几个影响搜索的关键字段:网页的 title(标题)、keywords(关键词)、description(摘要)等。
<html>
<title>老吴卖牙签</title>
<meta name="keywords" content="娱乐,生活,很大">
<meta name="description" content="老吴卖牙签">
</html>
提取出这些信息后,仅通过传统的关系型数据库和顺序搜索算法是无法满足毫秒级查询的。那不妨换个思路。既然用户都是根据关键词搜索,那如果事先知道这些关键词存在于哪些页面中,不就能直接找到了么?即对内容进行 分词 ,建立 倒排索引 。
分词就是把一句话拆分成多个单词,英文分词比较简单,就根据空格来就行。但中文分词就麻烦了,传统分词方法是建立一个词典,然后线性匹配,但这种方法成本大、且精度不高。现在基本都是 NLP(自然语言处理)、AI 分词了,包括了切词、同义词转换、同义词替换等等。
以对页面标题分词为例,比如有两个网页,第一个网页的标题是 “老吴卖牙签”,其实会被分词为 “老吴”、“卖”、“牙签”。第二个网页的标题是 “老吴牙签很大”,会被分词为 “老吴”、“牙签”、“很大”。
分词后,要根据分词结果建立 倒排索引 。
如果说 正向索引 就像书的目录,帮助我们根据页码找到对应章节;那倒排索引则像是打小抄,事先记录好题目答案所在的页码,再根据页码快速找到题目答案。
对上面的两个网页建立正向索引:
| 网页 id | 标题 | 内容 |
|---|---|---|
| 1 | 老吴卖牙签 | xxx |
| 2 | 老吴牙签很大 | xxx |
建立倒排索引:
| 索引 id | 索引文本 | 存在于网页 id |
|---|---|---|
| 1 | 老吴 | 1, 2 |
| 2 | 卖 | 1 |
| 3 | 牙签 | 1, 2 |
| 4 | 很大 | 2 |
建立并存储倒排索引后,如果用户搜索关键词 “很大”,只需要从倒排索引表中找到索引文本等于 “很大” 的那一行,取出包含该词的网页 id,就可以再根据网页 id 去正向索引中找到网页全部信息了。
数据检索
光有倒排索引还不能支持用户快速搜索,在最后的数据检索环节也有大学问。
比如为什么搜索 “老吴不是牙签”,却能搜出 “吴牙签” 呢?
明明前者没有包含后者对吧,我们常用的 like、正则之类的字符串匹配算法是查询不到结果的。
下面讲讲搜索引擎的做法。
先放一张几年前由百度搜索官方提供的数据检索流程图,大致思路是没问题的,但有些步骤的细节可能早已天差地别。
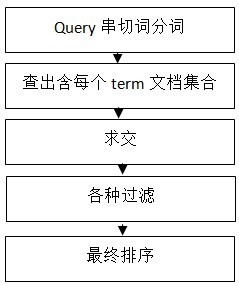
1. 分词
先像建立倒排索引一样,对用户输入的查询文本进行分词,比如搜索 “老吴不是牙签”,可能的分词为:“老吴”、“不是”、“牙签”。
2. 查询倒排索引
分别对这 3 个关键词,从事先建立好的倒排索引中查出包含网页的集合:
| 关键词 | 包含该关键词的网页 |
|---|---|
| 老吴 | 网页 1、网页 2 |
| 不是 | 网页 3 |
| 牙签 | 网页 1、网页 2 |
然后将上述查询出的网页取交集(及所有关键词都必须包含该网页,查询要求更严格)或并集(包含任一关键词即可),作为候选集合。
此处为了得到更多的结果,取并集作为候选集合,结果为:网页 1、网页 2、网页 3。
3. 相关性评价
其实就是给候选集合中的网页打分,根据上一步的索引查询结果,来计算用户的搜索和网页实际内容到底有多像。
一种很常见的打分算法是 TF-IDF ,是搜索引擎技术 Elasticsearch 和 Lucene 最主流的打分机制。在 Elasticsearch 中,将该打分算法结合向量空间模型、协调因子、词语权重提升等,组成了 实用评分函数,提高搜索的有效性。
TF 是 词频 ,就是关键词在网页中出现的频度是多少。频度越高,权重越高。出现 5 次 “牙签” 关键词的网页在该词的权重显然比只出现 1 次要高。
公式如下:
// 该词在文档中出现次数的平方根
tf(t in d) = √frequency
IDF 是 逆向文档频率 ,即关键词在集合所有网页中出现的频率是多少。物以稀为贵,越冷门的词,权重反而越高。
上面的例子中显然 “不是” 这个词最稀有,所以 “网页 3” 在这个词的分数会更高。
公式如下:
// 索引中文档数量除以所有包含该词的文档数,然后求其对数
idf(t) = 1 + log ( numDocs / (docFreq + 1))
此外,还有一个因素是 norm(字段长度归一值)。假设同一个网页的标题和内容都包含了 “牙签”,而标题很短,内容很长,那么在标题中出现 “牙签” 会有更高的权重。
// 字段中词数平方根的倒数
norm(d) = 1 / √numTerms
用户搜索文本中的 每一个 关键词都要结合这些因素进行打分,最后再结合每个词的权重将分数进行累加,计算出每个候选网页的最终得分。
最终公式如下:

有兴趣的朋友可以阅读《Elasticsearch:权威指南》的相关度评分章节。
地址:https://www.elastic.co/guide/cn/elasticsearch/guide/current/scoring-theory.html
在上面的例子中,计算分数后,得到的集合如下:
| 网页 | 标题 | 分数 |
|---|---|---|
| 网页 1 | 老吴卖牙签 | 0.9 |
| 网页 2 | 老吴牙签很大 | 0.8 |
| 网页 3 | 不是吧 | 0.7 |
网页 1 比网页 2 虽然都匹配到了两个关键词,但前者更短,所以分数略高一筹。
4. 过滤
上面的步骤只是计算了候选网页的得分,但并不是这些网页都能被搜出来,还要经过各种过滤,比如过滤掉死链(失效网站)、重复数据、各种 “你懂的” 网站等。

5. 排序
经过上面的步骤,我们最后得到了 3 个网页,但到底该把哪个网页放到第一位呢?
回到开头的问题:为什么搜索牙签时,最先搜出来的不是传统牙签而是老吴呢?
这个问题取决于 最终排序 ,现在一般都使用机器学习算法,结合一些信息,比如上面提到的相关度、网站的质量、热度、时效性等等,将最能满足用户需求的结果排序在最前。
而老吴是近期的爆款内容,在热度、时效性、搜索相关度上都很有优势,而且不排除有人工或推广来动态操作权重的可能。
相信讲到这里,大家也都能理解为什么搜索牙签时, “吴牙签” 被顶到首页了吧~

搜索引擎优化
那假如说你做了一个网站,肯定希望不仅其他用户能搜到,而且是要在第一条对吧。
要做到这点,首先要让蜘蛛抓到你的网页,还要重点研究搜索结果的排序机制。这些内容结合起来,就是我们常说的 SEO(搜索引擎优化)。
这一块学问很大,我自己的编程导航网站目前也做到了各搜索引擎的 排名第一 ,送给大家一些 SEO 视频教程吧。在我的博客回复 seo 即可。
后面我会再结合实际具体讲讲我做 SEO 的小技巧。
以上就是本期分享。我是鱼皮,欢迎阅读 我从 0 自学进入腾讯的编程学习、求职、考证、写书经历,不再迷茫!
点赞 还是要求一下的,祝大家都能心想事成、发大财、行大运。

以上是关于聊聊百度搜索背后的故事的主要内容,如果未能解决你的问题,请参考以下文章