字节跳动VQScore算法拿下ICME 2021“压缩UGC视频质量评估”比赛第一名
Posted LiveVideoStack_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字节跳动VQScore算法拿下ICME 2021“压缩UGC视频质量评估”比赛第一名相关的知识,希望对你有一定的参考价值。
在ICME 2021国际视频质量评估算法竞赛中,字节跳动拿下第一。
在多媒体领域世界顶级学术会议ICME 2021的「压缩UGC视频质量评估」比赛中,字节跳动旗下火山引擎多媒体实验室组成的“QA-FTE”队伍,凭借自研的VQScore算法,拿下了该比赛「无参考视频质量评价(NR-VQA)MOS赛道」的第一名。

与QA-FTE同场竞技的,还有另外11支来自不同国家的队伍,包括上海交通大学、深圳大学、日本东京工业大学和印度理工学院等知名院校均参加了比赛。整场竞赛包含两个赛道,分别对应VQA领域两类主流的解决方法:
无参考视频质量评价(NR-VQA)MOS赛道:在参考信息缺失的前提下对损伤视频质量进行评价;
全参考视频质量评价(FR-VQA)DMOS赛道:衡量参考视频和损伤视频之间的质量差异。
除了在无参考视频质量评价(NR-VQA)MOS赛道中包揽全部最高分之外,在全参考视频质量评价(FR-VQA)DMOS赛道,火山引擎多媒体实验室同样拿下了部分指标的最高分。
什么是「压缩UGC视频质量评估」
到底什么是「压缩UGC视频质量评估」?
视频质量评估,就是用算法模型来自动评判一段视频的质量,比如清不清晰、有没有噪点、画质好不好,给出高低不同的分数。视频质量的高低,直接影响到用户看视频的体验。
有了自动评估视频质量的算法模型,就可以在用户生产视频、系统处理视频的过程中自动的用一些手段来更好的处理视频。
比如评估发现一段视频分辨率太低让人看不清楚,就可以用超分辨率算法让它清晰起来;或者评估发现一段视频噪点太多,就可以用去噪算法减轻这些噪点。
比如发现视频本身已经很模糊了,就把转码的码率调低,节省系统带宽,也帮观看用户省点流量。
比如用户拍摄视频的时候发现当前场景是逆光的,人物五官都看不清楚,就可以提示用户:该调整下灯光和角度了。
可以理解为,视频质量评估就是一场视频们的「入学考试」,根据考试的分数,算法老师们因材施教,让每一段视频都看起来更美观。
但和传统的专业电视台拍摄的视频相比,给UGC的视频打分是更困难的一件事——毕竟在做视频这件事上,你没有办法低估网友们的脑洞。
比如UGC的视频里,包含用户拍摄的自然风景、食物、建筑、人像、动物等各种题材的内容,甚至有些不是自然拍摄,而是游戏录屏,并且还会加上五花八门的字幕。

比如有的视频本身并非竖屏视频,为了在移动端播放,就在上下加上背景填充。填充的图案其实是很清晰的色块,但中间的视频可不一定清晰,你不能因为两侧的填充图案看起来很清晰,就判断这个视频很清晰。

再比如这种大头特效,特效的部分很清晰,但特效之外的人物部分却有些模糊,这到底是算清晰还是不清晰?

另外,因为UGC拍摄有各种情况,用户手一抖,视频就变模糊,噪点、过曝、抖动、失真,各种问题交织在一起,算法很难评价。

火山引擎多媒体实验室研究出的算法VQScore就是专门做视频质量评分的,训练这个算法的数据集都是众包用户根据自己的审美和观看感受来评分的,能够保证算法的评分契合大部分普通观众的观看体验,此前已经有了2年多的积累。
目前,VQScore系列视频质量评估算法不仅在抖音、西瓜视频等产品落地,并且已经作为火山引擎视频点播服务的一部分对外开放。
从用户出发,巧「拆」数据集
回顾整个参赛过程,火山引擎多媒体实验室的同学也曾遇到过模型分数的瓶颈,无论怎么优化,都无法提升分数。
这里需要说明,整场比赛的数据集均来自一些视频App中的真实视频,包含:
训练集:6400个训练视频片段
验证集:800个验证视频片段
测试集:800个测试视频片段,用于对参赛模型进行比较和评分,参赛者无法获取。
每个视频被H.264/AVC编码器压缩成损伤程度由弱到强的7个压缩片段,主办方通过主观测试针对每一支视频片段收集了超过50个主观MOS评分。
参赛者训练模型的数据必须来自比赛主办方的官方数据,不可以用自己的数据。数据就是训练模型的原材料,如果数据不足,那么算法工程师们常常会遇到巧妇难为无米之炊的难题,虽然不是「无米」,但「米」的数量并不够用。
怎么才能提升「米」的数量呢?
作为有丰富数据处理经验的工程师,火山引擎多媒体实验室参赛同学决定直接挨个看数据集里的视频,看了很多样本之后发现了突破口:
原本的方法里,用到了很多时域信息——通俗来讲,就是随着视频时间进度条的进展,视频的每一帧之间都是有相关性的,视频的主角完成一个动作、场景发生一点变化,前后帧之间都是有联系的。
比赛数据集中的视频,大多只在短短的10秒左右,时域信息相当稳定,画质也没有明显变化。
因为对数据和用户都有深刻的理解,根据多年处理数据的经验,工程师们意识到一件事情:
用户其实对时域并不敏感,更注重每一帧里的画面信息——也就是空域信息。
本着尊重用户体验的出发点,他们做出了一项更为务实的权衡:
把单个的视频数据集,拆成分散的帧来用。
在看重时域信息的方法中,数据集中的每个视频都被当做单独一个数据用来训练,总共6400个输入数据。但如果放弃时域信息,把每个10秒钟左右的训练视频拆成单独的帧,就可以获得300帧左右的数据,相当于训练算法的数据集增大到原来的30倍,6400个输入数据就可以变成192000个。
并且这种新的方法还获得了一个额外的好处——避免了过拟合,也就是模型死记硬背了训练集里的答案,在测试集里表现失灵的情况。“时域信息用太多会过拟合,相当于我们牺牲了一小块,保留了更大的蛋糕。”
参赛模型的技术实现
火山引擎多媒体实验室在比赛中不仅使用了较为传统的CNN(卷积神经网络),另外考虑到Transformer在NLP领域取得巨大成功,决定采用Transformer进行UGC视频的质量评估,提出了一种CNN和Transformer相结合的框架,采用CNN提取局部特征,利用Transformer结构通过自注意机制预测主观质量分数。

无参考模型框架如上图所示。
火山引擎多媒体实验室使用卷积神经网络(CNN)作为特征提取器来计算输入视频块的深度特征。提取ResNet不同层的特征,在空间维度上利用MaxPooling将这些特征降采样到相同大小,并在特征维度上进行拼接。将该特征的空间维度展平并进行Linear projection,并添加embedding作为Transformer的输入:
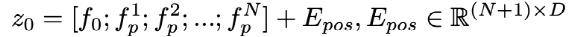
采用的Transformer架构遵循标准的Vision Transformer,包含L层多头注意力模块(MSA)和多层感知器模块(MLP)。Transformer与MLP头连接,用于回归最终的主观评分。
用于训练的损失函数均方误差l1-Loss和PLCC-Loss加权相加构成:
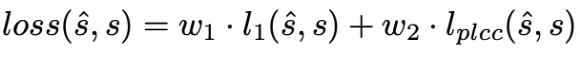
PLCC表示一个batch内预测值和groudturthlabel的相关性,其值归一化至[-1,1],PLCC值越大性能越好,因此PLCC损失表示为:

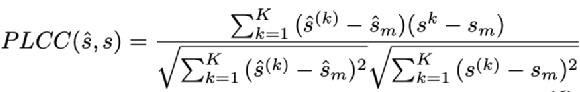
全参考模型框架如下图所示。reference patch和对应位置的distortion patch输入共享权值的孪生神经网络分别提取深度特征,并在特征空间的计算L1距离,拼接成新的特征输入回归模块映射得到主观DMOS分值。

如下图所示,在训练过程中,从压缩视频片段和相应的参考视频片段中随机裁剪出一个256×256的图像块patch(针对FR框架),然后将压缩视频的质量评分直接作为裁剪patch的训练标签。测试时,从每一帧的四个角和中心裁剪得到5个大小为256×256的patch分别计算分值(FR框架),所有patch的平均得分作为压缩视频的预测分。

在实验中,用于特征提取的ResNet18网络使用在ImageNet上预训练的用于分类任务的网络的权值进行初始化,并使用相同的学习率与框架的其他部分一起进行训练;Transformer包含2层,MSA头数为16。在加权w1=1.00, w2=0.02的条件下,利用L1损失和PLCC损失联合优化框架。
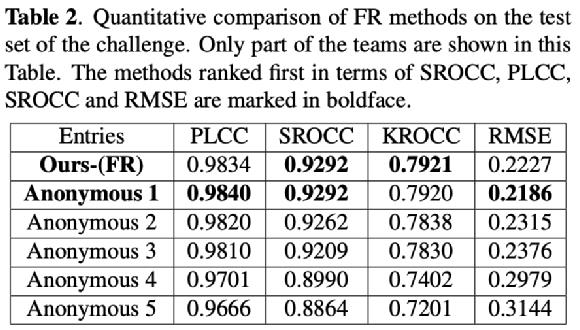
通过对比竞赛结果中的各队伍在测试集上的性能指标(PLCC/SROCC/KROCC/RMSE)以及SOTA FR/NR算法预测质量分数散点图,对提出模型的性能进行验证,其中PLCC/SRCC/KROCC越接近1越好,RMSE越接近0越好。
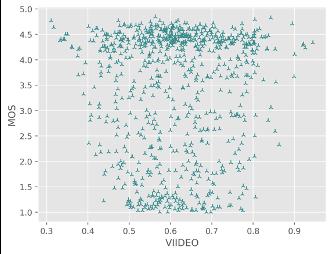
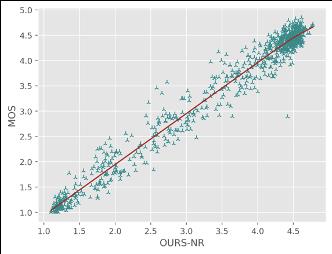
A. MOS track:
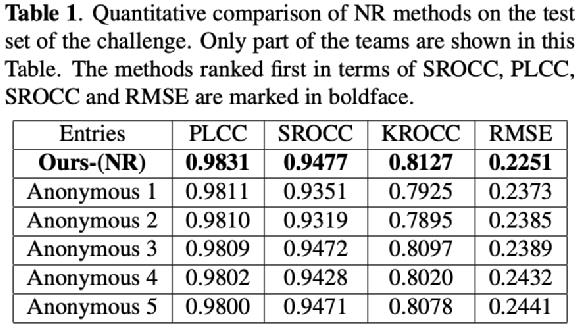
Comparing with SOTA NR-VQA metrics:

B. DMOS track:
Comparing with SOTA FR-VQA metrics:
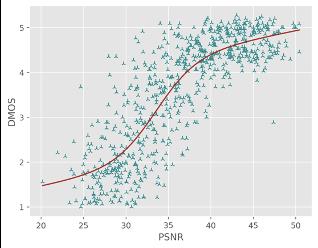
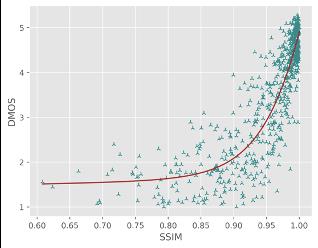
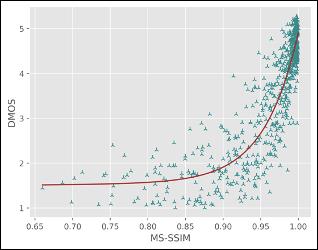
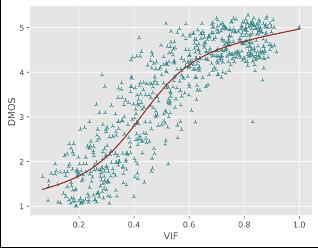
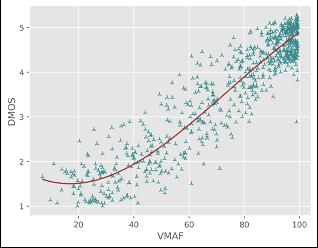
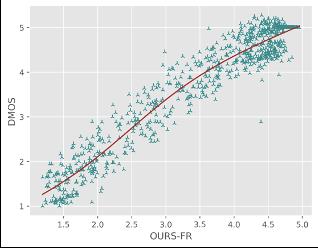
对于直接预测压缩损伤视频MOS分的NR方法,火山引擎多媒体实验室提出的NR框架在所有评价指标中排名第一;对于预测参考视频和损伤视频质量差异DMOS分值的FR方法,火山引擎多媒体实验室提出的FR框架在预测单调性(即SROCC和KROCC)方面排名第一,在预测精度(即PLCC和RMSE)方面排名第二。同时通过散点图可以看出,提出的方法与主观评分具有较高的相关性,显著超出了其他的SOTA FR/NR方法。
目前行业内,视频画质好坏直接影响实际业务QoE,已经是不争的事实,包括完播、留存、关注等。模仿人类主观感受是一件非常困难的事,受到很多因素的干扰。而用户真实感知,和学术上那些行业已有衡量体系(PSNR、SSIM、VMAF等)仍有鸿沟,包括他们彼此之间评价标准,也不完全统一。导致在视频工业生产中的需求,如扶持高清原创、打击视频劣质内容、针对画质精准匹配转码档位节省成本等,都没有很好的解决方案。
基于以上原因,字节/火山引擎花大力气研发出VQScore,寻求解决这一长期痛点,同时向工业界推出其无参考质量评价标准。
针对UGC内容的研究与实际应用场景更加贴近,UGC质量评价算法对监控视频平台整体画质、监督画质提升算法、指导压缩效率提升等场景有重要作用。据悉,火山引擎多媒体实验室提出的Transformer结构实现了算法性能的提升,对后续相关算法研究具有较强的指导意义。
字节跳动背后的音视频技术揭秘
音视频技术在近几年呈现突飞猛进的发展,一方面满足了企业对于业务高速增长需求,另一方面也为业务的发展创造了更多的可能性。在本专题中,将展示字节跳动背后的音视频技术,以及如何利用这些技术支撑业务发展并满足合作伙伴的需求。本分享将从音视频编解码开始,回顾音视频编解码技术并进行展望,介绍视频编解码的优化与评估;随后,将介绍音视频在直播方面的应用和如何通过音视频支持业务的增长;最后,将以抖音为例,介绍RTC技术是如何追求极致的体验。


详情请扫描图中的二维码或点击阅读原文报名参加专场活动。
以上是关于字节跳动VQScore算法拿下ICME 2021“压缩UGC视频质量评估”比赛第一名的主要内容,如果未能解决你的问题,请参考以下文章
我凭借这份pdf拿下了蚂蚁金服字节跳动小米等大厂的offer
外包辞职了,经历了2000小时后,走进字节跳动拿下offer