7.24的一次工作失误
Posted saynaihe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7.24的一次工作失误相关的知识,希望对你有一定的参考价值。
背景:
kubernetes集群持续升级:
持续升级过程:Kubernetes 1.16.15升级到1.17.17,Kubernetes 1.17.17升级到1.18.20,Kubernetes 1.18.20升级到1.19.12 Kubernetes 1.19.12升级到1.20.9(强调一下selfLink)
集群配置
| 主机名 | 系统 | ip |
|---|---|---|
| k8s-vip | slb | 10.0.0.37 |
| k8s-master-01 | centos7 | 10.0.0.41 |
| k8s-master-02 | centos7 | 10.0.0.34 |
| k8s-master-03 | centos7 | 10.0.0.26 |
| k8s-node-01 | centos7 | 10.0.0.36 |
| k8s-node-02 | centos7 | 10.0.0.83 |
| k8s-node-03 | centos7 | 10.0.0.40 |
| k8s-node-04 | centos7 | 10.0.0.49 |
| k8s-node-05 | centos7 | 10.0.0.45 |
| k8s-node-06 | centos7 | 10.0.0.18 |
网络插件用的flannel。kubernetes的升级还是很顺利的没有出什么大的问题.因为这些东西都是进行过多次操作的。
事故经过:
kubernetes集群的cni是flannel插件。版本有些老然后就想替换成新的版本。但是在各种环境中,并没有进行过替换删除cni的测试。也没有意识到问题的严重性和可能造成的严重后果。直接执行了kubectl delete -f kube-flannel.yaml,如下:
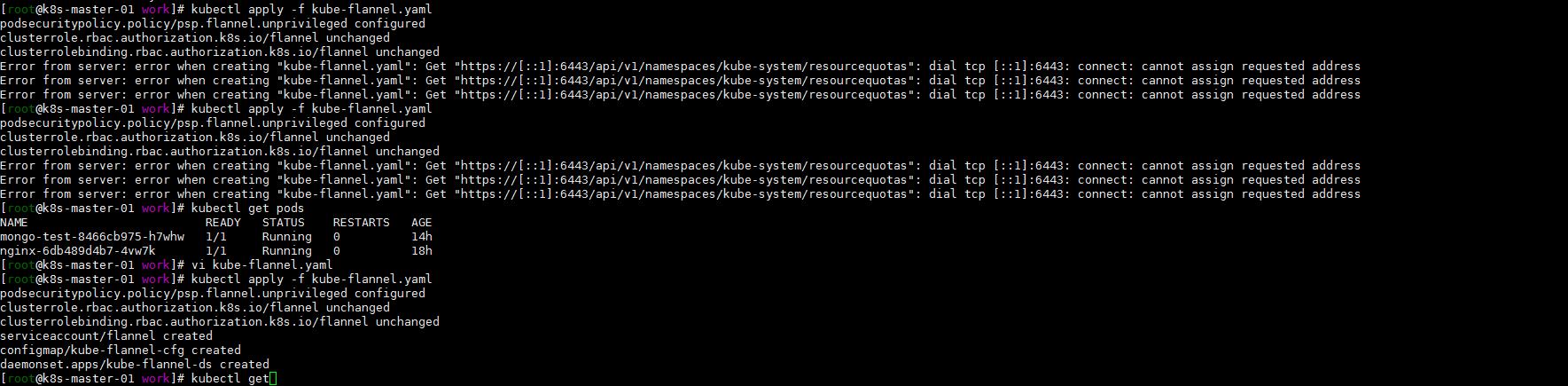
但是再执行kubectl apply -f kube-flannel.yaml(新的配置文件)就失败了。
升级中的失误
这里就犯到了以下的错误:
1. 所有的更新维护还是要走更新停服的流程。使其他部门知道,并告知可能产生的最严重后果,让负责人有所预判。
2. 同cni的升级还是apply -f去执行新的yaml文件。不能delete -f 然后apply -f
除更换cni插件或者删除应用外,应尽量减少使用kubelet delete的命令的操作使用。
3. cni的正确修改方式是要整个集群状态进入维护状态然后:
# 删除flannel的pod
# 使用一开始创建pod时同样的yaml文件
kubectl delete -f flannel.yaml
# 在集群各节点清理flannel网络的残留文件
ifconfig cni0 down
ip link delete cni0
ifconfig flannel.1 down
ip link delete flannel.1
rm -rf /var/lib/cni
rm -f /etc/cni/net.d
注:需要对所有节点执行并reboot。然后重新执行kubectl apply -f kube-flannel.yaml。这个过程是需要停服维护的。操作前个人的预判不足。
4. 关于镜像的被墙。很多images无法下载,导致同步更新镜像浪费了很多时间。以后需要对升级镜像进行复制同步到国内源。
出现故障进行重新部署过程中,系统组件images很多都无法拉取到。通过国外服务器下载镜像并同步耗费了大量的时间。
事故的反思和以后工作的思考
1. 规范化更新维护的流程,集群更新走维护申请流程,告知相关部门。
2. 更新维护演练。选择一个周期时间进行更新维护演练。发现问题。并快速响应解决问题。
3. 建立快速的恢复机制。能更快的维护线上状态。
4. 线上是否需要做主备集群。出现问题进行快速切换
以上是关于7.24的一次工作失误的主要内容,如果未能解决你的问题,请参考以下文章