进程线程简单了解
Posted 临风而眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了进程线程简单了解相关的知识,希望对你有一定的参考价值。
线程进程简单了解
一.进程与线程
1.进程
操作系统每次运行一个程序,都会给程序准备一块内存,该内存区域可以称为进程,进程是资源单位
打开任务管理器,我们就可以看到很多进程
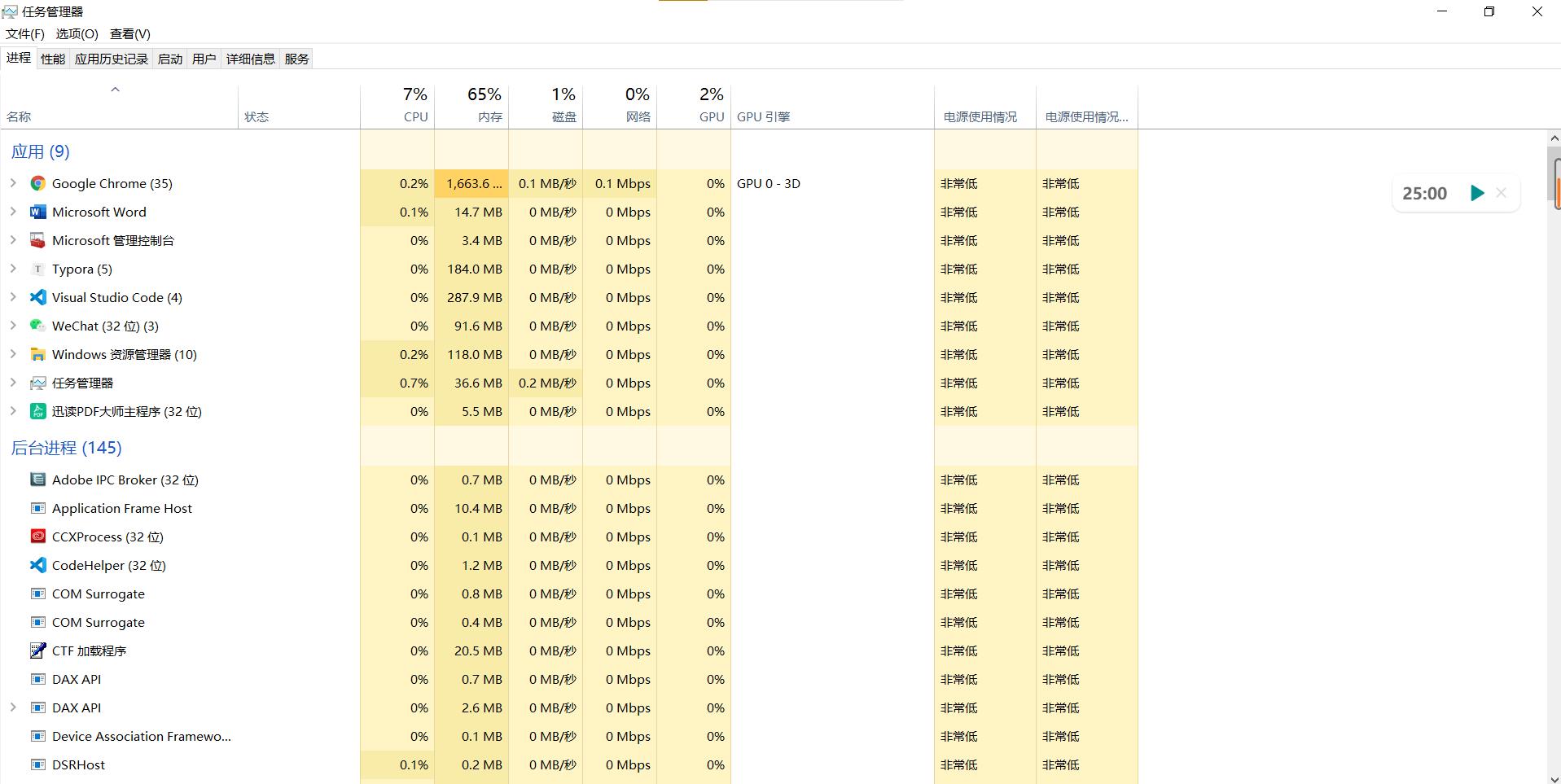
这时我们来运行输出一个经典的hello world
再次打开任务管理器,就会发现

进程其实就是运行着的程序
2.线程
线程是执行单位,一个进程里面至少要有一个线程
线程由操作系统创建,每个线程对应一个代码执行的数据结构,保存了代码执行过程中的重要的状态信息(如当前代码执行到了哪个指令等等)
上面那个hello world程序,虽然没有创建线程的代码,但当Python解释器运行起来(成为一个进程),OS就自动创建一个线程,常称为主线程,在这个主线程里面执行代码指令
启动一个程序默认会有一个主线程
def func():
for i in range(1,1000):
print("fuc",i,end=' ')
if __name__=='__main__':
func()
for i in range(1000,2001):
print('main',i, end=' ')

这就是一个单线程的程序
二.多线程
上面的程序输出1到2000,看似很快,几乎一秒就解决了
那么如果要输出1到2000…00000000000000000000呢,如果只用一个线程,得等到猴年马月
(假设不需要按顺序输出)
而这时如果我们同时用100个线程,同时输出这2000......00000000000000000000个数字,那么理论上就可以减少100倍的执行时间
1.多线程写法一
将上面那个程序实现多线程
from threading import Thread # 线程类
def func():
for i in range(1, 1000):
print(" fuc:", i, end=' ')
if __name__ == '__main__':
# 创建一个新线程并给线程安排任务
t = Thread(target=func)
# 多线程状态为可以开始工作状态,具体的执行时间由CPU决定
t.start()
for i in range(1000, 2001):
print(' main:', i, end=' ')
两条线程在同时运行:
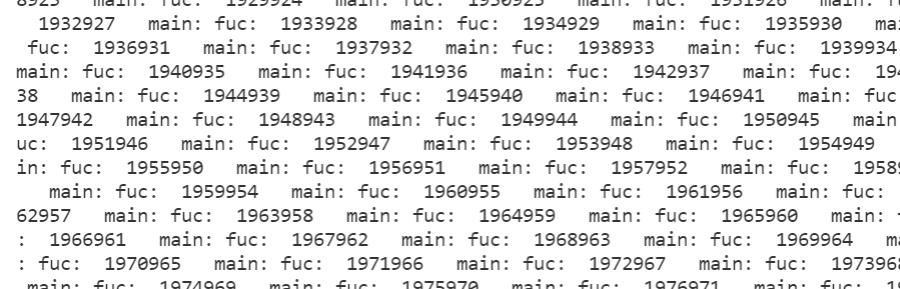
再添加一个线程,执行效率就更高了
from threading import Thread # 线程类
def func1():
for i in range(1, 500):
print(" fuc1:", i, end=' ')
def func2():
for i in range(500, 1000):
print(" fuc2:", i, end=' ')
if __name__ == '__main__':
# 创建一个新线程并给线程安排任务
t1 = Thread(target=func1)
# 多线程状态为可以开始工作状态,具体的执行时间由CPU决定
t1.start()
t2 = Thread(target=func2)
t2.start()
for i in range(1000, 2001):
print(' main:', i, end=' ')

传参
from threading import Thread # 线程类
def func(name):
for i in range(1, 500):
print(name, i)
if __name__ == '__main__':
# 创建一个新线程并给线程安排任务
t1 = Thread(target=func,args=('没空调',))
# 多线程状态为可以开始工作状态,具体的执行时间由CPU决定
t2 = Thread(target=func,args=('没电扇',))
t1.start()
t2.start()

2.多线程写法二
from threading import Thread
# 继承Thread类
class MyThread1(Thread):
# 重写run方法
def run(self): # run是固定的
for i in range(1, 500):
print(" 子线程1:", i, end=' ')
class MyThread2(Thread):
# 重写run方法
def run(self): # run方法是固定的,当线程开始执行,默认执行run()
for i in range(500, 1000):
print(" 子线程2:", i, end=' ')
if __name__ == '__main__':
t1 = MyThread1()
t2 = MyThread2()
# 开启线程
# 当线程开始执行,默认执行run()方法
t1.start()
t2.start()
for i in range(1000, 2001):
print('主线程:', i, end=' ')

传参
from threading import Thread
# 继承Thread类
class MyThread(Thread):
def __init__(self,args):
Thread.__init__(self)
self.args=args
# 重写run方法
def run(self): # run方法是固定的,当线程开始执行,默认执行run()
print(self.args)
if __name__ == '__main__':
testname=('参数1',)
#单个元素的元组要在后面加上逗号
t = MyThread(testname)
# 开启线程
# 当线程开始执行,默认执行run()方法
t.start()
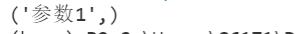
派生类中重写了父类threading.Thread的run()方法,其他方法(除了构造函数)都不应在子类中被重写,换句话说,在子类中只有*init*()和run()方法被重写
Thread 的构造方法中,还可以有其他参数,可以看这个博客
3.join方法
再看个例子
from time import sleep
from threading import Thread
print('主线程执行代码')
def threadFunc(args1, args2):
print("子线程 开始")
print(f'线程函数的参数为:{args1},{args2}')
sleep(5)
print('子线程结束')
# 创建Thread类的实例对象
# target 参数 指定 新线程要执行的函数
# 这里指定的函数对象只能写一个名字,不能后面加括号,
# 如果加括号就是直接在当前线程调用执行,而不是在新线程中执行了
thread = Thread(target=threadFunc, args=('参数1', '参数2'))
# 执行start 方法,就会创建新线程,
# 并且新线程会去执行入口函数里面的代码。
# 这时候 这个进程 有两个线程了
# target参数 是指定新线程的 入口函数, 新线程创建后就会 执行该入口函数里面的代码,
# args 指定了 传给 入口函数threadFunc 的参数。 线程入口函数 参数,必须放在一个元组里面,里面的元素依次作为入口函数的参数
thread.start()
print('主线程结束')

如果加入join方法
from time import sleep
from threading import Thread
print('主线程执行代码')
def threadFunc(args1, args2):
print("子线程 开始")
print(f'线程函数的参数为:{args1},{args2}')
sleep(5)
print('子线程结束')
# 创建Thread类的实例对象
# target 参数 指定 新线程要执行的函数
# 这里指定的函数对象只能写一个名字,不能后面加括号,
# 如果加括号就是直接在当前线程调用执行,而不是在新线程中执行了
thread = Thread(target=threadFunc, args=('参数1', '参数2'))
# 执行start 方法,就会创建新线程,
# 并且新线程会去执行入口函数里面的代码。
# 这时候 这个进程 有两个线程了
# target参数 是指定新线程的 入口函数, 新线程创建后就会 执行该入口函数里面的代码,
# args 指定了 传给 入口函数threadFunc 的参数。 线程入口函数 参数,必须放在一个元组里面,里面的元素依次作为入口函数的参数
thread.start()
# 主线程的代码执行 子线程对象的join方法,
# 就会等待子线程结束,才继续执行下面的代码
thread.join()
print('主线程结束')

三.多进程
Manager获取子进程的运算结果
from multiprocessing import Process,Manager
from time import sleep
def f(taskno,return_dict):
sleep(2)
# 存放计算结果到共享对象中
return_dict[taskno] = taskno
if __name__ == '__main__':
manager = Manager()
# 创建 类似字典的 跨进程 共享对象
return_dict = manager.dict()
plist = []
for i in range(10):
p = Process(target=f, args=(i,return_dict))
p.start()
plist.append(p)
for p in plist:
p.join()
print('get result...')
# 从共享对象中取出其他进程的计算结果
for k,v in return_dict.items():
print (k,v)
本文参考:
up主路飞学城IT的B站教程
以上是关于进程线程简单了解的主要内容,如果未能解决你的问题,请参考以下文章