otto案例介绍 -- Otto Group Product Classification Challengexgboost实现
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了otto案例介绍 -- Otto Group Product Classification Challengexgboost实现相关的知识,希望对你有一定的参考价值。
【机器学习】otto案例介绍
1. 背景介绍
奥托集团是世界上最⼤的电⼦商务公司之⼀,在20多个国家设有⼦公司。该公司每天都在世界各地销售数百万种产品, 所以对其产品根据性能合理的分类⾮常重要。
不过,在实际⼯作中,⼯作⼈员发现,许多相同的产品得到了不同的分类。本案例要求,你对奥拓集团的产品进⾏正确的分分 类。尽可能的提供分类的准确性。
链接:https://www.kaggle.com/c/otto-group-product-classification-challenge/overview
2. 思路分析
- 1.数据获取
- 2.数据基本处理
- 2.1 截取部分数据
- 2.2 把标签纸转换为数字
- 2.3 分割数据(使⽤StratifiedShuffleSplit)
- 2.4 数据标准化
- 2.5 数据pca降维
- 3.模型训练
- 3.1 基本模型训练
- 3.2 模型调优
- 3.2.1 调优参数:
- n_estimator,
- max_depth,
- min_child_weights,
- subsamples,
- consample_bytrees,
- etas
- 3.2.2 确定最后最优参数
- 3.2.1 调优参数:
3. 代码实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
3.1 数据获取
data = pd.read_csv("./data/otto/train.csv")
data.shape
(61878, 95)
data.describe()
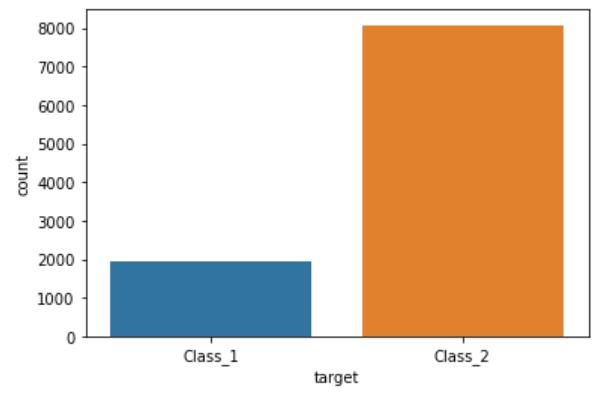
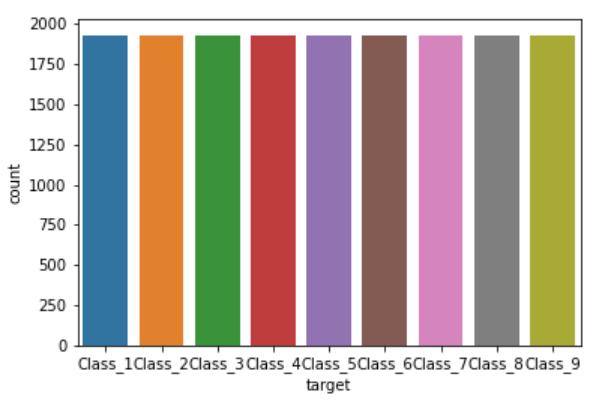
# 图形可视化,查看数据分布
import seaborn as sns
sns.countplot(data.target)
plt.show()

由上图可以看出,该数据类别不均衡,所以需要后期处理
3.2 数据基本处理
数据已经经过脱敏,不再需要特殊处理
3.2.1 截取部分数据
new1_data = data[:10000]
new1_data.shape
# 图形可视化,查看数据分布
import seaborn as sns
sns.countplot(new1_data.target)
plt.show()
使用上面方式获取数据不可行,然后使用随机欠采样获取响应的数据
# 随机欠采样获取数据
# 首先需要确定特征值\\标签值
y = data["target"]
x = data.drop(["id", "target"], axis=1)
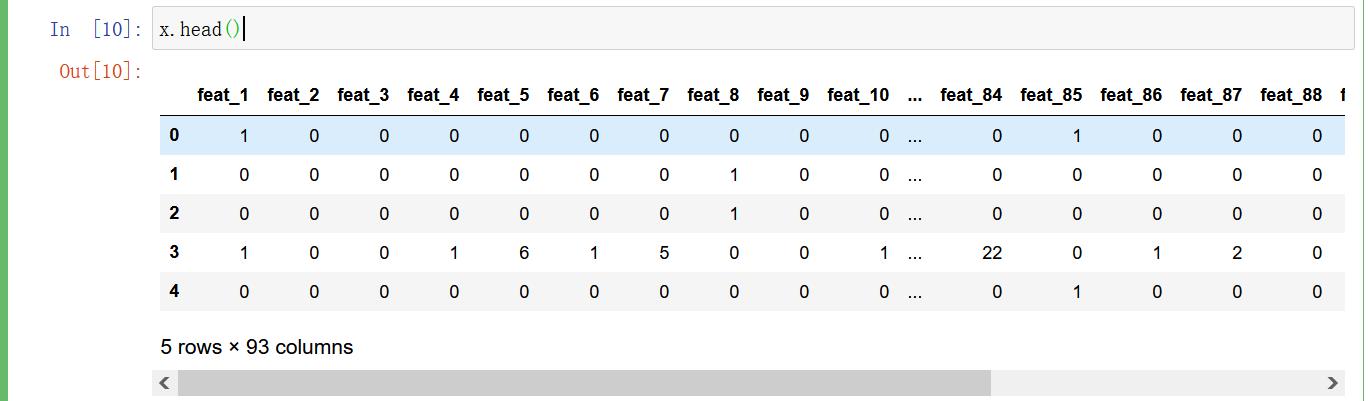
# 欠采样获取数据
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=0)
X_resampled, y_resampled = rus.fit_resample(x, y)
x.shape, y.shape
X_resampled.shape, y_resampled.shape

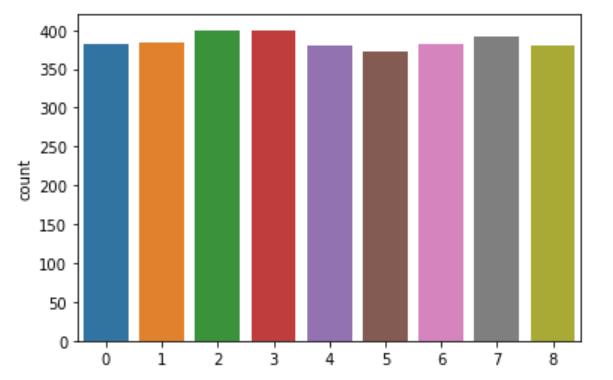
# 图形可视化,查看数据分布
import seaborn as sns
sns.countplot(y_resampled)
plt.show()
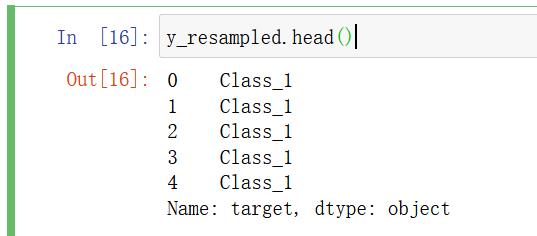
3.2.2 把标签值转换为数字
y_resampled.head()
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y_resampled = le.fit_transform(y_resampled)

3.2.3 分割数据
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X_resampled, y_resampled, test_size=0.2)
x_train.shape, y_train.shape

# 图形可视化
import seaborn as sns
sns.countplot(y_test)
plt.show()
# 通过StratifiedShuffleSplit实现数据分割
from sklearn.model_selection import StratifiedShuffleSplit
sss = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=0)
for train_index, test_index in sss.split(X_resampled.values, y_resampled):
print(len(train_index))
print(len(test_index))
x_train = X_resampled.values[train_index]
x_val = X_resampled.values[test_index]
y_train = y_resampled[train_index]
y_val = y_resampled[test_index]
13888
3473
print(x_train.shape, x_val.shape)
(13888, 93) (3473, 93)
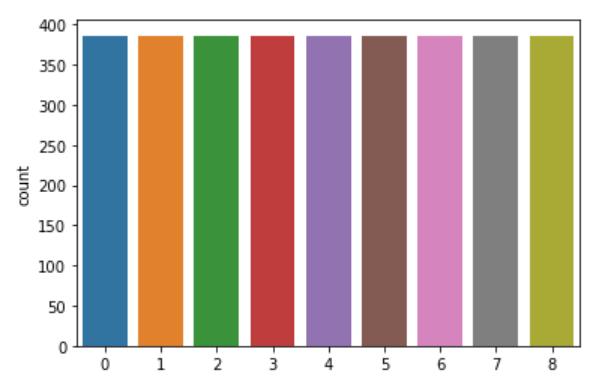
# 图形可视化
import seaborn as sns
sns.countplot(y_val)
plt.show()
3.2.4 数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(x_train)
x_train_scaled = scaler.transform(x_train)
x_val_scaled = scaler.transform(x_val)
3.2.5 数据PCA降维
x_train_scaled.shape
(13888, 93)
from sklearn.decomposition import PCA
pca = PCA(n_components=0.9)
x_train_pca = pca.fit_transform(x_train_scaled)
x_val_pca = pca.transform(x_val_scaled)
print(x_train_pca.shape, x_val_pca.shape)
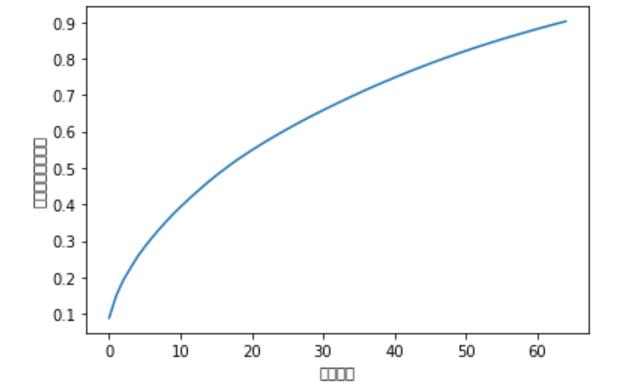
# 可视化数据降维信息变化程度
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel("元素数量")
plt.ylabel("表达信息百分占比")
plt.show()
3.3 模型训练
3.3.1 基本模型训练
from xgboost import XGBClassifier
xgb = XGBClassifier()
xgb.fit(x_train_pca, y_train)
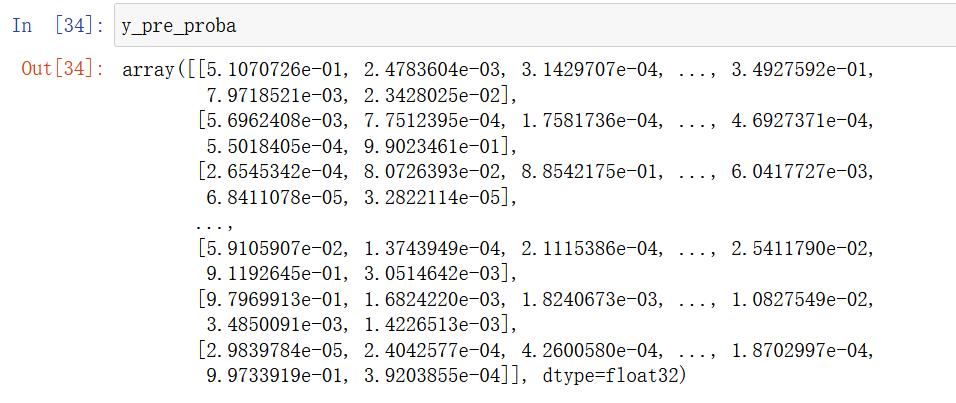
# 输出预测值,一定输出带有百分占比的预测值
y_pre_proba = xgb.predict_proba(x_val_pca)
y_pre_proba
# logloss评估
from sklearn.metrics import log_loss
log_loss(y_val, y_pre_proba, eps=1e-15, normalize=True)
0.735851001353164
xgb.get_params

3.3.2 模型调优
3.3.2.1 确定最优的estimators
scores_ne = []
n_estimators = [100, 200, 300, 400, 500, 550, 600, 700]
for nes in n_estimators:
print("n_estimators:", nes)
xgb = XGBClassifier(max_depth=3,
learning_rate=0.1,
n_estimators=nes,
objective="multi:softprob",
n_jobs=-1,
nthread=4,
min_child_weight=1,
subsample=1,
colsample_bytree=1,
seed=42)
xgb.fit(x_train_pca, y_train)
y_pre = xgb.predict_proba(x_val_pca)
score = log_loss(y_val, y_pre)
scores_ne.append(score)
print("每次测试的logloss值是:{}".format(score))
# 图形化展示相应的logloss值
plt.plot(n_estimators, scores_ne, "o-")
plt.xlabel("n_estimators")
plt.ylabel("log_loss")
plt.show()
print("最优的n_estimators值是:{}".format(n_estimators[np.argmin(scores_ne)]))
3.3.2.2 确定最优的max_depth
scores_md = []
max_depths = [1,3,5,6,7]
for md in max_depths:
print("max_depth:", md)
xgb = XGBClassifier(max_depth=md,
learning_rate=0.1,
n_estimators=n_estimators[np.argmin(scores_ne)],
objective="multi:softprob",
n_jobs=-1,
nthread=4,
min_child_weight=1,
subsample=1,
colsample_bytree=1,
seed=42)
xgb.fit(x_train_pca, y_train)
y_pre = xgb.predict_proba(x_val_pca)
score = log_loss(y_val, y_pre)
scores_md.append(score)
print("每次测试的logloss值是:{}".format(score))
# 图形化展示相应的logloss值
plt.plot(max_depths, scores_md, "o-")
plt.xlabel("max_depths")
plt.ylabel("log_loss")
plt.show()
print("最优的max_depths值是:{}".format(max_depths[np.argmin(scores_md)]))
3.3.2.3 依据上面模式,运行调试下面参数
min_child_weights,
subsamples,
consample_bytrees,
etas
3.3.3 最优模型
xgb = XGBClassifier(learning_rate =0.1,
n_estimators=550,
max_depth=3,
min_child_weight=3,
subsample=0.7,
colsample_bytree=0.7,
nthread=4,
seed=42,
objective='multi:softprob')
xgb.fit(x_train_scaled, y_train)
y_pre = xgb.predict_proba(x_val_scaled)
print("测试数据的log_loss值为 : {}".format(log_loss(y_val, y_pre, eps=1e-15, normalize=True)))
加油!
感谢!
努力!
以上是关于otto案例介绍 -- Otto Group Product Classification Challengexgboost实现的主要内容,如果未能解决你的问题,请参考以下文章