《绝地求生》玩家排名预测(2万5千字~大型综合实战)
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《绝地求生》玩家排名预测(2万5千字~大型综合实战)相关的知识,希望对你有一定的参考价值。
《绝地求生》玩家排名预测
1. 项目背景

绝地求生(Player unknown’s Battlegrounds),俗称吃鸡,是一款战术竞技型射击类沙盒游戏。
这款游戏是一款大逃杀类型的游戏,每一局游戏将有最多100名玩家参与,他们将被投放在绝地岛(battlegrounds)上,在游戏的开始时所有人都一无所有。玩家需要在岛上收集各种资源,在不断缩小的安全区域内对抗其他玩家,让自己生存到最后。
该游戏拥有很高的自由度,玩家可以体验飞机跳伞、开越野车、丛林射击、抢夺战利品等玩法,小心四周埋伏的敌人,尽可能成为最后1个存活的人。

该游戏中,玩家需要在游戏地图上收集各种资源,并在不断缩小的安全区域内对抗其他玩家,让自己生存到最后。
2. 数据集介绍
本项目中,将为您提供大量匿名的《绝地求生》游戏统计数据。
其格式为每行包含一个玩家的游戏后统计数据,列为数据的特征值。
数据来自所有类型的比赛:单排,双排,四排;不保证每场比赛有100名人员,每组最多4名成员。
文件说明:
train_V2.csv - 训练集
test_V2.csv - 测试集
数据集局部图如下图所示:

数据集中字段解释:


3. 项目评估方式
3.1 评估方式
你必须创建一个模型,根据他们的最终统计数据预测玩家的排名,从1(第一名)到0(最后一名)。
最后结果通过平均绝对误差(MAE)进行评估,即通过预测的winPlacePerc和真实的winPlacePerc之间的平均绝对误差
3.2 MAE(Mean Absolute Error)介绍

4. 项目实现(数据分析+RF+lightGBM)
在接下来的分析中,我们将分析数据集,检测异常值。
然后我们通过随机森林模型对其训练,并对对该模型进行了优化。
# 导入数据基本处理阶段需要用到的api
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
4.1 获取数据、基本数据信息查看
导入数据,且查看数据的基本信息
train = pd.read_csv("./data/train_V2.csv")

train.tail()
train.describe()
train.info()

可以看到数据一共有4446966条,
train.shape
(4446966, 29)
# 查看一共有多少场比赛
np.unique(train["matchId"]).shape
(47965,)
# 查看一共有多少组
np.unique(train["groupId"]).shape
(2026745,)

4.2 数据基本处理
4.2.1 数据缺失值处理
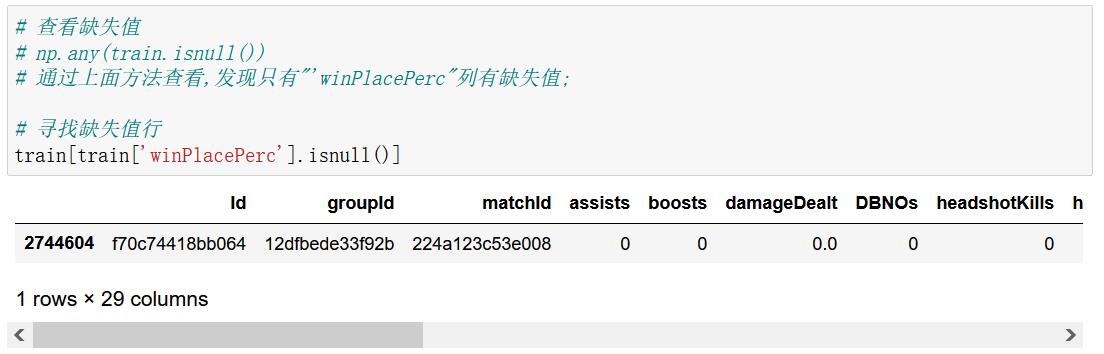
查看目标值,我们发现有一条样本,比较特殊,其“winplaceperc”的值为NaN,也就是目标值是缺失值,
因为只有一个玩家是这样,直接进行删除处理。
# 查看缺失值
# np.any(train.isnull())
# 通过上面方法查看,发现只有"'winPlacePerc"列有缺失值;
# 寻找缺失值行
train[train['winPlacePerc'].isnull()]
# 删除缺失值
train.drop(2744604, inplace=True)
train.shape

4.2.2 特征数据规范化处理
4.2.2.1 查看每场比赛参加的人数
处理完缺失值之后,我们看一下每场参加的人数会有多少呢,是每次都会匹配100个人,才开始游戏吗?
# 显示每场比赛参加人数
# transform的作用类似实现了一个一对多的映射功能,把统计数量映射到对应的每个样本上
count = train.groupby('matchId')['matchId'].transform('count')
train['playersJoined'] = count
count.count()
train.head()

# 通过每场参加人数进行,按值升序排列
train["playersJoined"].sort_values().head()

通过结果发现,最少的一局,竟然只有两个人,wtf!!!
# 通过绘制图像,查看每局开始人数
# 通过seaborn下的countplot方法,可以直接绘制统计过数量之后的直方图
plt.figure(figsize=(20,10))
sns.countplot(train['playersJoined'])
plt.title('playersJoined')
plt.grid()
plt.show()
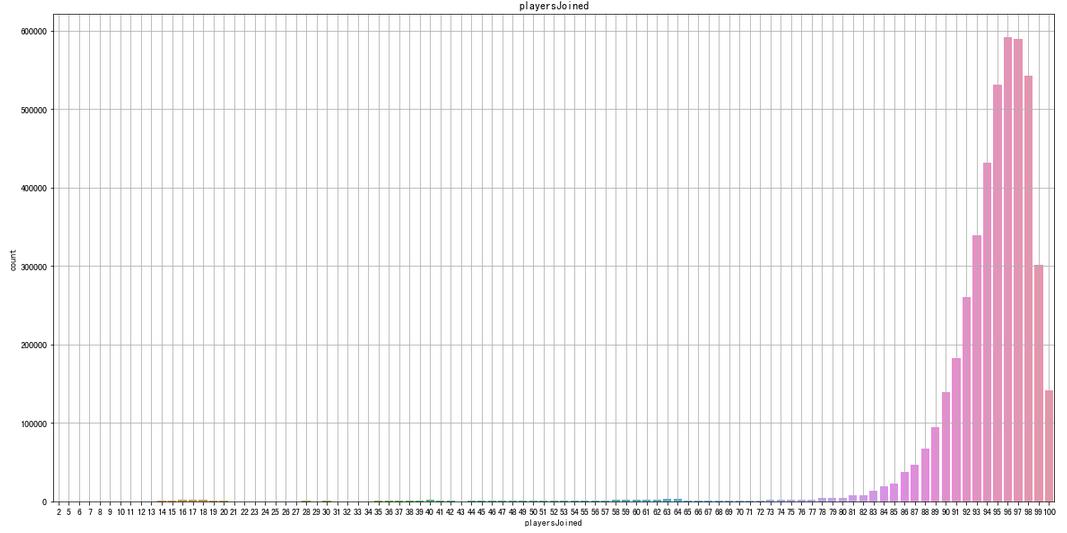
通过观察,发现一局游戏少于75个玩家,就开始的还是比较少
同时大部分游戏都是在接近100人的时候才开始
限制每局开始人数大于等于75,再进行绘制。
猜想:把这些数据在后期加入数据处理,应该会得到的结果更加准确一些
# 再次绘制每局参加人数的直方图
plt.figure(figsize=(20,10))
sns.countplot(train[train['playersJoined']>=75]['playersJoined'])
plt.title('playersJoined')
plt.grid()
plt.show()

4.2.2.2 规范化输出部分数据
现在我们统计了“每局玩家数量”,那么我们就可以通过“每局玩家数量”来进一步考证其它特征,同时对其规范化设置
试想:一局只有70个玩家的杀敌数,和一局有100个玩家的杀敌数,应该是不可以同时比较的
可以考虑的特征值包括
-
1.kills(杀敌数)
-
2.damageDealt(总伤害)
-
3.maxPlace(本局最差名次)
-
4.matchDuration(比赛时长)
# 对部分特征值进行规范化
train['killsNorm'] = train['kills']*((100-train['playersJoined'])/100 + 1)
train['damageDealtNorm'] = train['damageDealt']*((100-train['playersJoined'])/100 + 1)
train['maxPlaceNorm'] = train['maxPlace']*((100-train['playersJoined'])/100 + 1)
train['matchDurationNorm'] = train['matchDuration']*((100-train['playersJoined'])/100 + 1)
# 比较经过规范化的特征值和原始特征值的值
to_show = ['Id', 'kills','killsNorm','damageDealt', 'damageDealtNorm', 'maxPlace', 'maxPlaceNorm', 'matchDuration', 'matchDurationNorm']
train[to_show][0:11]

4.2.3 部分变量合成
此处我们把特征:heals(使用治疗药品数量)和boosts(能量、道具使用数量)合并成一个新的变量,命名:”healsandboosts“, 这是一个探索性过程,最后结果不一定有用,如果没有实际用处,最后再把它删除。
# 创建新变量“healsandboosts”
train['healsandboosts'] = train['heals'] + train['boosts']
train[["heals", "boosts", "healsandboosts"]].tail()

4.2.4 异常值处理
4.2.4.1 异常值处理:删除有击杀,但是完全没有移动的玩家
异常数据处理:
一些行中的数据统计出来的结果非常反常规,那么这些玩家肯定有问题,为了训练模型的准确性,我们会把这些异常数据剔除
通过以下操作,识别出玩家在游戏中有击杀数,但是全局没有移动;
这类型玩家肯定是存在异常情况(挂**),我们把这些玩家删除。
# 创建新变量,统计玩家移动距离
train['totalDistance'] = train['rideDistance'] + train['walkDistance'] + train['swimDistance']
# 创建新变量,统计玩家是否在游戏中,有击杀,但是没有移动,如果是返回True, 否则返回false
train['killsWithoutMoving'] = ((train['kills'] > 0) & (train['totalDistance'] == 0))
train["killsWithoutMoving"].head()

train["killsWithoutMoving"].describe()

# 检查是否存在有击杀但是没有移动的数据
train[train['killsWithoutMoving'] == True].shape
(1535, 37)
train[train['killsWithoutMoving'] == True].head()

# 删除这些数据
train.drop(train[train['killsWithoutMoving'] == True].index, inplace=True)

4.2.4.2 异常值处理:删除驾车杀敌数异常的数据
# 查看载具杀敌数超过十个的玩家
train[train['roadKills'] > 10]

# 删除这些数据
train.drop(train[train['roadKills'] > 10].index, inplace=True)

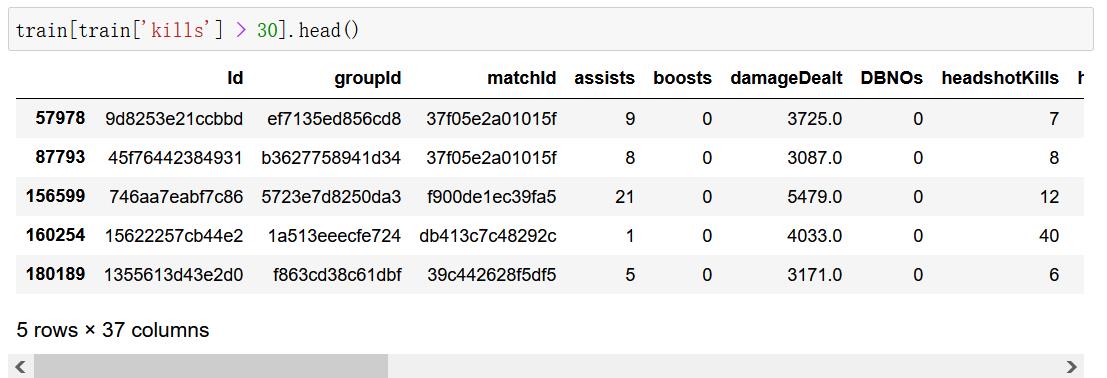
4.2.4.3 异常值处理:删除玩家在一局中杀敌数超过30人的数据
# 首先绘制玩家杀敌数的条形图
plt.figure(figsize=(10,4))
sns.countplot(train["kills"])
plt.show()

train[train['kills'] > 30].shape
(95, 37)
train[train['kills'] > 30].head()
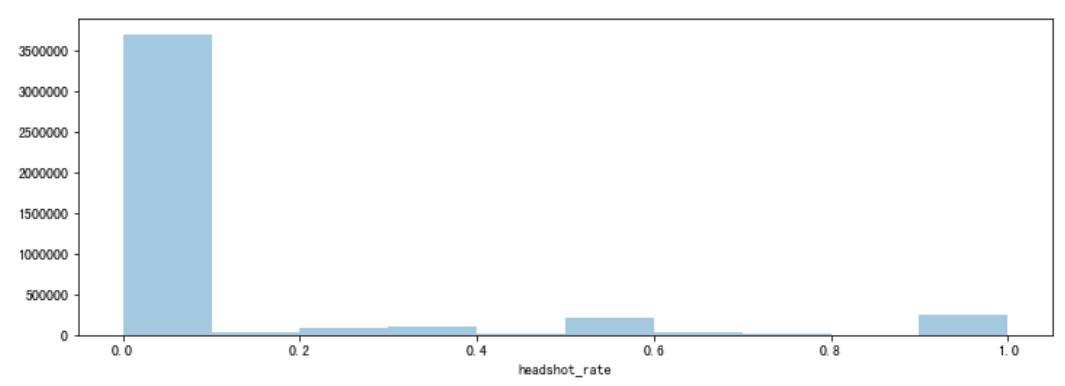
4.2.4.4 异常值处理:删除爆头率异常数据
如果一个玩家的击杀爆头率过高,也说明其有问题
# 创建变量爆头率
train['headshot_rate'] = train['headshotKills'] / train['kills']
train['headshot_rate'] = train['headshot_rate'].fillna(0)
train["headshot_rate"].tail()

# 绘制爆头率图像
plt.figure(figsize=(12,4))
sns.distplot(train['headshot_rate'], bins=10, kde=False)
plt.show()
train[(train['headshot_rate'] == 1) & (train['kills'] > 9)].shape
(24, 38)
train[(train['headshot_rate'] == 1) & (train['kills'] > 9)].head()

train.drop(train[(train['headshot_rate'] == 1) & (train['kills'] > 9)].index, inplace=True)
4.2.4.5 异常值处理:删除最远杀敌距离异常数据
# 绘制图像
plt.figure(figsize=(12,4))
sns.distplot(train['longestKill'], bins=10, kde=False)
plt.show()

# 找出最远杀敌距离大于等于1km的玩家
train[train['longestKill'] >= 1000].shape
(20, 38)
train[train['longestKill'] >= 1000]["longestKill"].head()

train.drop(train[train['longestKill'] >= 1000].index, inplace=True)
train.shape
(4445287, 38)
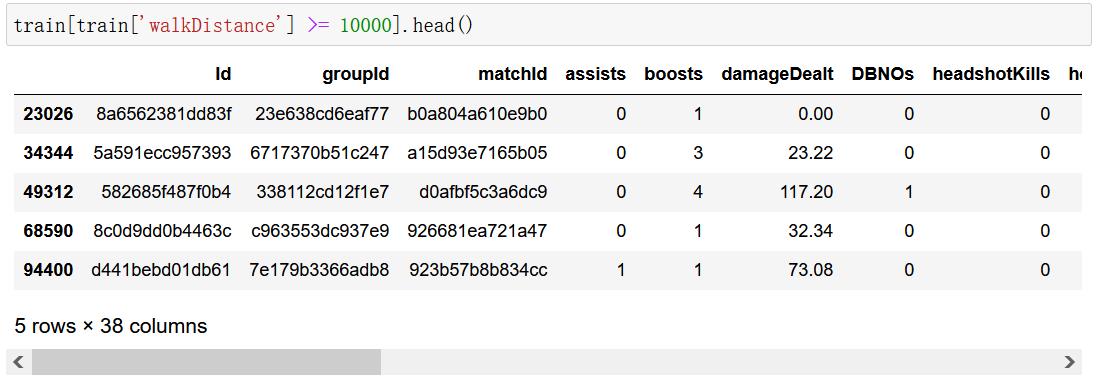
4.2.4.6 异常值处理:删除关于运动距离的异常值
# 距离整体描述
train[['walkDistance', 'rideDistance', 'swimDistance', 'totalDistance']].describe()

a)行走距离处理
train[train['walkDistance'] >= 10000].shape
(219, 38)
train[train['walkDistance'] >= 10000].head()
train.drop(train[train['walkDistance'] >= 10000].index, inplace=True)
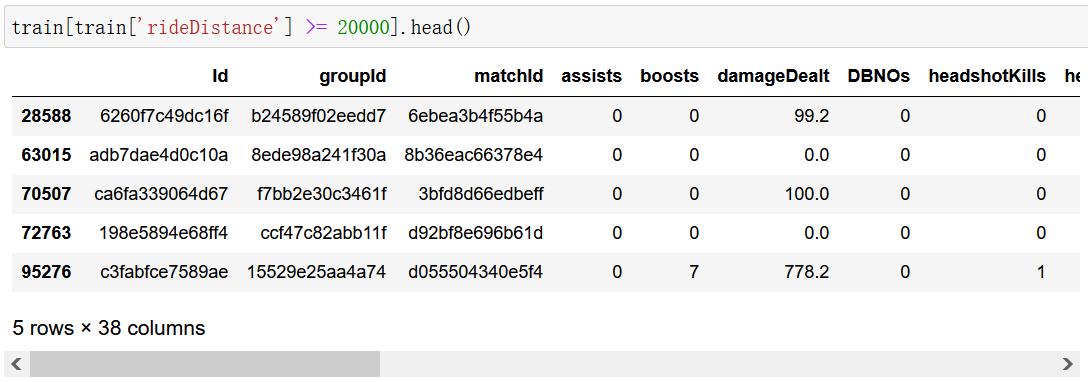
b)载具行驶距离处理
train[train['rideDistance'] >= 20000].shape
(150, 38)
train[train['rideDistance'] >= 20000].head()
train.drop(train[train['rideDistance'] >= 20000].index, inplace=True)
c)游泳距离处理
train[train['swimDistance'] >= 2000].shape
train[train['swimDistance'] >= 2000][["swimDistance"]]
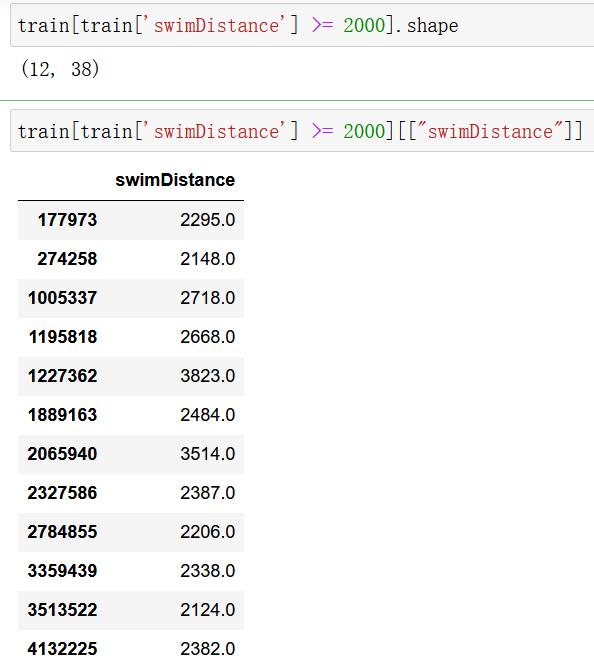
train.drop(train[train['swimDistance'] >= 2000].index, inplace=True)
4.2.4.7 异常值处理:武器收集异常值处理
train[train['weaponsAcquired'] >= 80].shape
(19, 38)
train[train['weaponsAcquired'] >= 80][['weaponsAcquired']].head()

train.drop(train[train['weaponsAcquired'] >= 80].index, inplace=True)
4.2.4.8 异常值处理:删除使用治疗药品数量异常值
train[train['heals'] >= 40].shape
(135, 38)
train[train['heals'] >= 40][["heals"]].head()
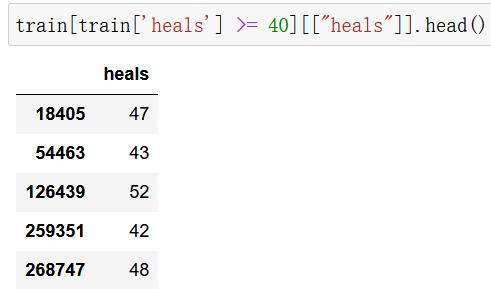
train.drop(train[train['heals'] >= 40].index, inplace=True)
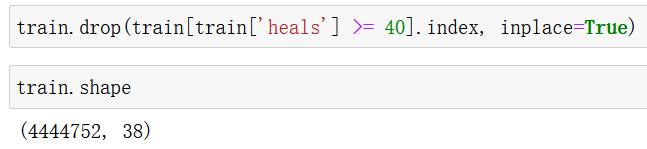
4.2.5 类别型数据处理
4.2.5.1 比赛类型one-hot处理
# 关于比赛类型,共有16种方式
train['matchType'].unique()

# 对matchType进行one_hot编码
# 通过在后面添加的方式,实现,赋值并不是替换
train = pd.get_dummies(train, columns=['matchType'])
train.shape
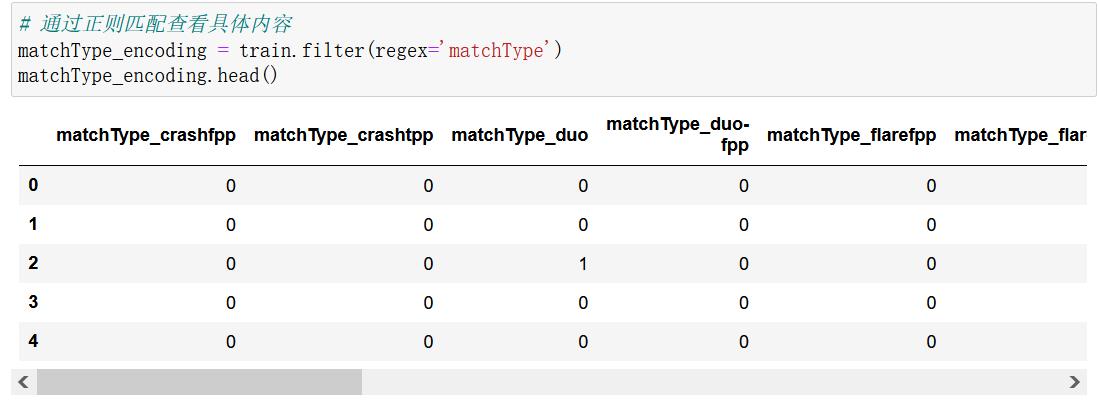
# 通过正则匹配查看具体内容
matchType_encoding = train.filter(regex='matchType')
matchType_encoding.head()
4.2.5.2 对groupId,matchId等数据进行处理
关于groupId,matchId这类型数据,也是类别型数据。但是它们的数据量特别多,如果你使用one-hot编码,无异于自杀。
在这儿我们把它们变成用数字统计的类别型数据依旧不影响我们正常使用。
# 把groupId 和 match Id 转换成类别类型 categorical types
# 就是把一堆不怎么好识别的内容转换成数字
# 转换group_id
train["groupId"].head()
train['groupId'] = train['groupId'].astype('category')

train["groupId_cat"] = train["groupId"].cat.codes
train[