吴恩达机器学习作业SVM--支持向量机
Posted 挂科难
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴恩达机器学习作业SVM--支持向量机相关的知识,希望对你有一定的参考价值。
一
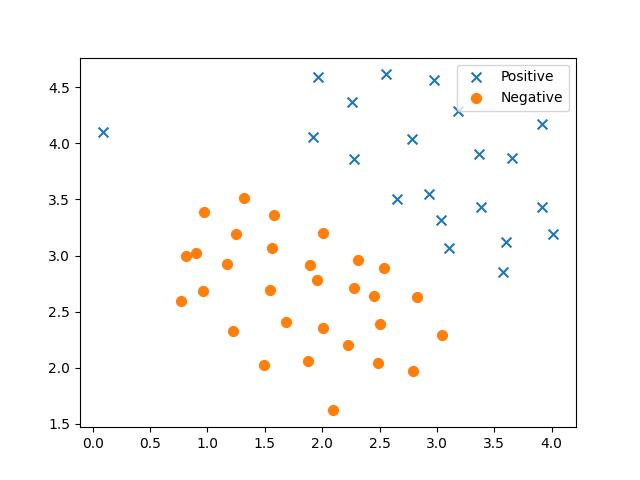
先看下数据的样子
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn import svm
raw_data = loadmat('data/ex6data1.mat')
data = pd.DataFrame(raw_data['X'], columns=['X1', 'X2'])
data['y'] = raw_data['y']
positive = data[data['y'].isin([1])]
negative = data[data['y'].isin([0])]
plt.scatter(positive['X1'], positive['X2'], s=50, marker='x', label='Positive')
plt.scatter(negative['X1'], negative['X2'], s=50, marker='o', label='Negative')
plt.legend()
plt.show()
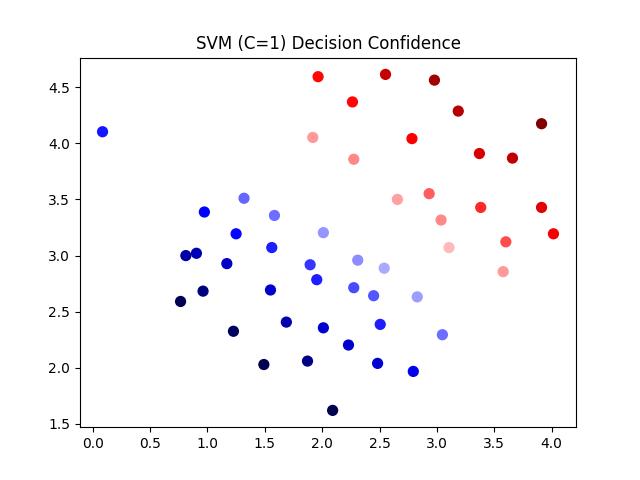
使用SVM,令C=1分类效果如图:
svc = svm.LinearSVC(C=1, loss='hinge', max_iter=1000)
svc.fit(data[['X1', 'X2']], data['y'])
svc.score(data[['X1', 'X2']], data['y'])
data['SVM 1 Confidence'] = svc.decision_function(data[['X1', 'X2']])
plt.scatter(data['X1'], data['X2'], s=50, c=data['SVM 1 Confidence'], cmap='seismic')
plt.title('SVM (C=1) Decision Confidence')
plt.show()
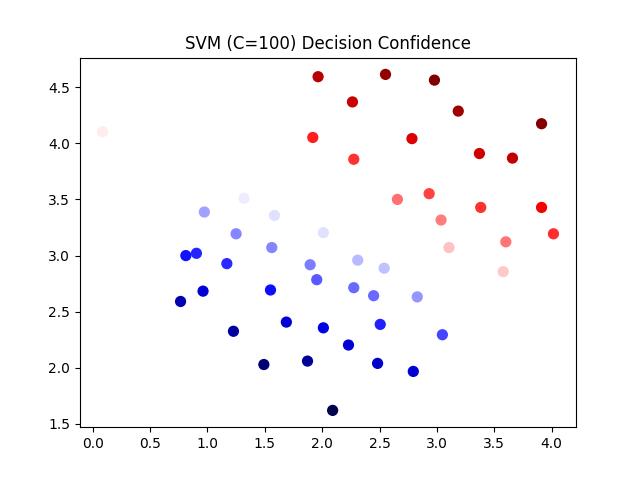
令C=100
效果如图:
svc2 = svm.LinearSVC(C=100, loss='hinge', max_iter=1000)
svc2.fit(data[['X1', 'X2']], data['y'])
svc2.score(data[['X1', 'X2']], data['y'])
data['SVM 2 Confidence'] = svc2.decision_function(data[['X1', 'X2']])
plt.scatter(data['X1'], data['X2'], s=50, c=data['SVM 2 Confidence'], cmap='seismic')
plt.title('SVM (C=100) Decision Confidence')
plt.show()
原本SVM不是很理解,想结合作业进一步加深理解,结果python都给隐藏了。。。。。
二
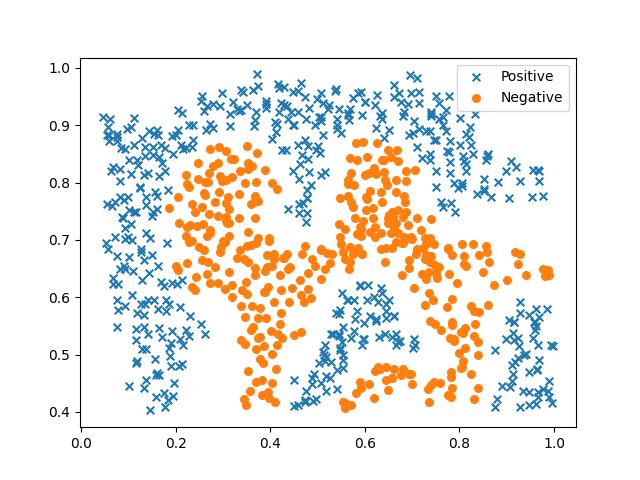
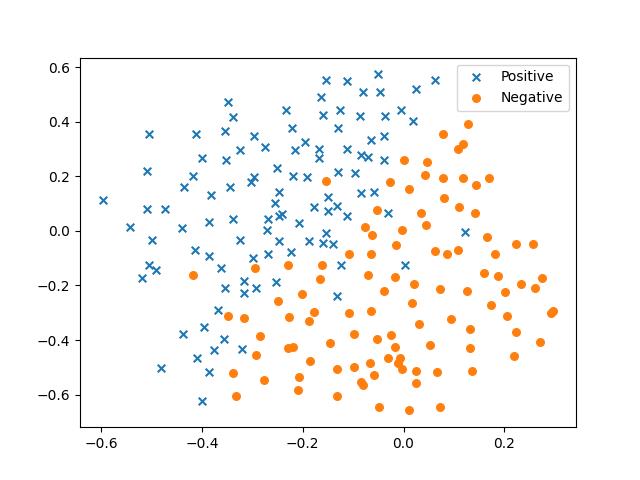
老样子,先看数据:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn import svm
raw_data = loadmat('data/ex6data2.mat')
data = pd.DataFrame(raw_data['X'], columns=['X1', 'X2'])
data['y'] = raw_data['y']
positive = data[data['y'].isin([1])]
negative = data[data['y'].isin([0])]
plt.scatter(positive['X1'], positive['X2'], s=30, marker='x', label='Positive')
plt.scatter(negative['X1'], negative['X2'], s=30, marker='o', label='Negative')
plt.legend()
plt.show()
使用SVM:
svc = svm.SVC(C=100, gamma=10, probability=True)
svc.fit(data[['X1', 'X2']], data['y'])
svc.score(data[['X1', 'X2']], data['y'])
data['Probability'] = svc.predict_proba(data[['X1', 'X2']])[:,0]
plt.scatter(data['X1'], data['X2'], s=30, c=data['Probability'], cmap='Reds')
plt.show()
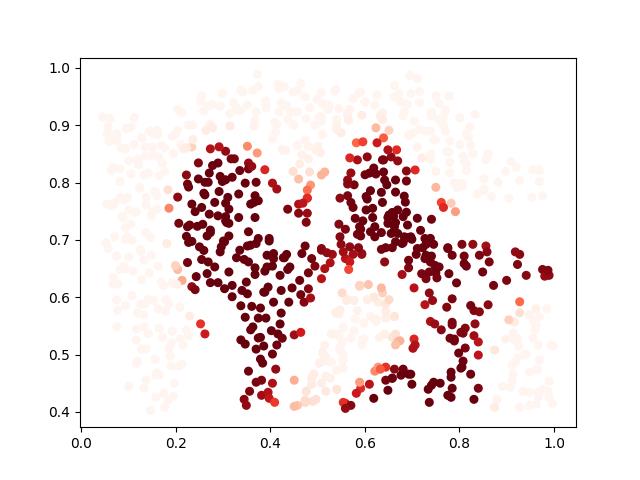 看着效果还可以
看着效果还可以
三
先看数据:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn import svm
raw_data = loadmat('data/ex6data3.mat')
data = pd.DataFrame(raw_data['X'], columns=['X1', 'X2'])
data['y'] = raw_data['y']
positive = data[data['y'].isin([1])]
negative = data[data['y'].isin([0])]
plt.scatter(positive['X1'], positive['X2'], s=30, marker='x', label='Positive')
plt.scatter(negative['X1'], negative['X2'], s=30, marker='o', label='Negative')
plt.legend()
plt.show()
我们的任务是找到最佳的C与ganma值,本着练习的目的采用for循环
X = raw_data['X']
Xval = raw_data['Xval']
y = raw_data['y']
yval = raw_data['yval']
C_values = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
gamma_values = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
best_score = 0
best_params = {'C': None, 'gamma': None}
for C in C_values:
for gamma in gamma_values:
svc = svm.SVC(C=C, gamma=gamma)
svc.fit(X, y)
score = svc.score(Xval, yval)
if score > best_score:
best_score = score
best_params['C'] = C
best_params['gamma'] = gamma
best_params:{‘C’: 0.3, ‘gamma’: 100}
四,垃圾邮件分类
一般思路:
1,将邮件内容全部转为小写
2,用“httpaddr”代替邮件中出现的网址
3,用“emailaddr”代替邮件地址
4,使用“number”代替出现的数字
5,“$”替换为“dollar”,同理“¥”替换为“RMB”
6,同义词替换
7,删除非单词内容,或非文字内容
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn import svm
spam_train = loadmat('data/spamTrain.mat')
spam_test = loadmat('data/spamTest.mat')
X = spam_train['X']
Xtest = spam_test['Xtest']
y = spam_train['y']
ytest = spam_test['ytest']
svc = svm.SVC()
svc.fit(X, y)
print('Test accuracy = {0}%'.format(np.round(svc.score(Xtest, ytest) * 100)),2) # np.round()四舍五入,此处保留两位小数
以上是关于吴恩达机器学习作业SVM--支持向量机的主要内容,如果未能解决你的问题,请参考以下文章